认真学习,不断提高自己。
目录
1.hadoop 生态圈的组件及描述
1)Zookeeper:是一个开源的分布式应用程序协调服务,基于 zookeeper 可以实现同步服务, 配置维护,命名服务。
2)Flume:一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统。
3)Hbase:是一个分布式的、面向列的开源数据库, 利用 Hadoop HDFS 作为其存储系统。
4)Hive:基于 Hadoop 的一个数据仓库工具,可以将结构化的数据档映射为一张数据库表, 并提供简单的 sql 查询功能,可以将 sql 语句转换为 MapReduce 任务进行运行。
5)Sqoop:将一个关系型数据库中的数据导进到 Hadoop 的 HDFS 中,也可以将 HDFS 的数据导进到关系型数据库中。
2.Hadoop 的几个默认端口及其含义
1)dfs.namenode.http-address:50070
2)SecondaryNameNode 辅助名称节点端口号:50090
3)dfs.datanode.address:50010
4)fs.defaultFS:8020 或 者 9000
5)yarn.resourcemanager.webapp.address:8088
3.hdfs的工作机制
HDFS是一套分布式软件系统,里面有很多服务角色:namenode、datanode、secondary namenode、客户端;
文件在HDFS中分块存储的,一个文件会被分成多个块(按照128M分块),每个块“随机”存储在集群中的某些datanode上;
每个块都有一个唯一的块ID;
每个块在HDFS中可以存储多个副本!(默认3个副本);
namenode负责管理元数据(hdfs系统的目录树,每个文件的具体路径、块信息、物理存储位置、副本数量),并为客户端提供查询服务;
datanode负责管理文件块(帮客户端存储块,帮客户端取块)
4.hdfs的优缺点
优点:
高容错性:
数据自动保存多个副本:副本丢失后,自动恢复
合适批处理:移动计算而非数据
适合大数据处理:GB、TB、PB级数据,百万以上的文件数量规模,10K+节点规模
缺点:
读写模式:一个文件只能有一个写者,仅支持append,不能随机修改
不适合低延迟访问:多轮RPC调用
小文件:
元数据信息存储在NameNode内存中
一个block meta data大约150byte内存,存储1亿block大约需要20GB
如果一个文件10K,1亿个文件大小仅为1TB
一个NameNode节点的内存是有限的
争取大量小文件消耗大量的寻道时间
拷贝大量小文件vs拷贝一个大文件
5.hdfs数据的上传和下载流程
略
6.checkpoint机制
- 因为namenode本身的任务就非常重,为了不再给namenode压力,日志合并到fsimage就引入了另一个角色secondarynamenode。secondarynamenode负责定期把editslog合并到fsimage,“定期”是namenode向secondarynamenode发送RPC请求的,是按时间或者日志记录条数为“间隔”的,这样即不会浪费合并操作又不会造成fsimage和内存元数据有很大的差距。因为元数据的改变频率是不固定的。
- 第一次进行checjpoint操作时,会由secondary namenode将namenode上积累的所有edits和一个最新的fsimage下载到本地,并加载到内存进行merge(这个过程称为checkpoint)。
1)namenode向secondarynamenode发送RPC请求,请求checkpoint操作,将editslog合并到fsimage。
2)secondarynamenode收到请求后从namenode上读取(通过http服务)editslog(多个,滚动日志文件)和fsimage文件。
3)secondarynamenode会根据拿到的editslog合并到fsimage。形成最新的fsimage文件。(中间有很多步骤,把文件加载到内存,还原成元数据结构,合并,再生成文件,新生成的文件名为fsimage.checkpoint)。
4)secondarynamenode通过http服务把fsimage.checkpoint文件上传到namenode,并且通过RPC调用把文件改名为fsimage。
namenode和secondary namenode的工作目录存储结构完全相同,所以,当namenode故障退出需要重新恢复时,可以从secondary namenode的工作目录中将fsimage拷贝到namenode的工作目录,以恢复namenode的元数据。
7.HDFS安装目录中的logs中看日志
我们分别在master、slave1以及slave2上安装了HDFS,只是每台机器上安装的角色不一样而已。
在master安装的是NameNode和SecondaryNameNode,对应的日志为:
## 这个是NameNode对应的日志
/home/hadoop-twq/bigdata/hadoop-2.7.5/logs/hadoop-hadoop-twq-namenode-master.log
## 这个是SecondaryNameNode对应的日志
/home/hadoop-twq/bigdata/hadoop-2.7.5/logs/hadoop-hadoop-twq-secondarynamenode-master.log
在slave1和slave2上安装的都是DataNode的角色,DataNode对应的日志文件为:
## slave1上的DataNode的日志文件
/home/hadoop-twq/bigdata/hadoop-2.7.5/logs/hadoop-hadoop-twq-datanode-slave1.log
## slave2上的DataNode的日志文件
/home/hadoop-twq/bigdata/hadoop-2.7.5/logs/hadoop-hadoop-twq-datanode-slave2.log
可以通过下面的配置来修改日志的存放目录:
## 将日志都放在/home/hadoop-twq/hadoop/cus/logs这个文件目录下
export HADOOP_LOG_DIR=/home/hadoop-twq/hadoop/cus/logs
HDFS WEB UI上查看日志
这种方式只能查看HDFS的NameNode和SecondaryNameNode的日志
我们可以通过http://master:50070来访问HDFS集群。然后点击如下图

然后我们进入到下图

- 第1处是HDFS的NameNode的日志
- 第2处是HDFS的SecondaryNameNode的日志
- 第3处是Yarn的ResourceManager的日志,这个你如果现在看不懂没关系的
当我们点击第1处的时候,可以看到下图:

这个就是NameNode的日志
8.使用hdfs可能会产生的问题
8.1 HA场景下,启动时出现两个NN都为standby
症状1:HDFS HA场景下,启动时出现两个NN都为standby
Namenode日志中提示:
WARN org.apache.hadoop.hdfs.server.namenode.ha.EditLogTailer: Unable to trigger a roll of the active NN
org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.ipc.StandbyException): Operation category JOURNAL is not supported in state standby
at org.apache.hadoop.hdfs.server.namenode.ha.StandbyState.checkOperation(StandbyState.java:87)
at org.apache.hadoop.hdfs.server.namenode.NameNode
Server.call(RPC.java:1026)
Failover Controller日志中提示:
WARN org.apache.hadoop.ha.ActiveStandbyElector: Exception handling the winning of election
java.lang.IllegalArgumentException: Unable to determine service address for namenode ‘namenode123’
at org.apache.hadoop.hdfs.tools.NNHAServiceTarget.(NNHAServiceTarget.java:76)
at org.apache.hadoop.hdfs.tools.DFSZKFailoverController.dataToTarget(DFSZKFailoverController.java:69)
…
at org.apache.zookeeper.ClientCnxn$EventThread.run(ClientCnxn.java:498)
版本:2.5.0+cdh5.2.0
原因分析:
此类问题一般是由ZKFC引起。此时ZK将会有一个ZNode:/hadoop-ha/${dfs.nameservices}/ActiveBreadCrumb,查看其内容应该会发现namenode123关键字。这表明ZKFC在寻找nameservice ID为namenode123的NN,但是本次启动时NN的nameservice ID却不是namenode123(本次nameservice ID可在hdfs-site.xml中看到)。暂不清楚ZKFC为何会检测一个旧的nameservice ID。
解决办法:
在ZK中初始化HA状态,可通过CM界面操作,或者执行sudo -u hdfs hdfs zkfc -formatZK,然后重启HDFS即可。
8.2 NN异常的接收到SIGNAL 15,从而进程退出
症状2:NN异常的接收到SIGNAL 15,从而进程退出
Namenode日志中除了如下提示之外,别无异常:
ERROR org.apache.hadoop.hdfs.server.namenode.NameNode: RECEIVED SIGNAL 15: SIGTERM
该问题出现了多次,并且都出现在同一个时间点。
版本:2.5.0+cdh5.2.0
原因分析:
因为多次出现在同一个时间点,怀疑与定时任务相关。查看系统日志/var/log/messages时,在问题出现的时间点发现了如下类似的提示:
Jan 7 14:00:01 host1 ntpd[32101]: ntpd exiting on signal 15
Jan 7 13:59:59 host1 ntpd[44764]: ntpd [email protected] Fri Feb 22 11:23:27 UTC 2013 (1)
Jan 7 13:59:59 host1 ntpd[44765]: precision = 0.143 usec
Jan 7 13:59:59 host1 ntpd[44765]: Listening on interface #0 wildcard, 0.0.0.0#123 Disabled
Jan 7 13:59:59 host1 ntpd[44765]: Listening on interface #1 wildcard, ::#123 Disabled
…
看来是ntpd服务停止时发送了signal 15,但是NN进程为何会接收到该信号呢?
后来发现了一个CentOs的bug,和我们的场景非常相似。虽然该问题的根本原因,目前还没有水落石出,但是我本人倾向于CentOS bug的说法。
解决办法:
ntpd服务停止命令是采用ntpdate方式同步时间时加入的,抛弃这种时间同步方式,采用ntpd同步方式即可。这两种同步时间方式的区别大家可以百度一下“ntpdate和nptd的区别”。
8.3报错信息“提示找不到或无法加载主类”
解决步骤:
(1)检查函数中有无main方法;
(2)检查用java 命令 时输入的类名是否正确;
(3)检查classpath设置是否正确;
(4) 类是否是在某一个包下面(即类文件中有package person;类似的内容);如果有得话,千万不要在命令行窗口中进到person这个包的目录下,去编译运行 java类, 而要到 包所在的目录中去编译运行,即在person所在的包,而不是person包里面,去编译运行。
像这样的问题,一般都是包得问题引起的,源文件中不要使用package语句,如果使用了,编译时,则要用“javac -d . 类名.java”,然后使用"java 包名.类名"。
8.4hadoop中用create()API在HDFS中创建目录没报错,但是却没看到创建的目录
解决步骤:(1)检查conf文件是否正确,是否设置fs.default.name;如
core-site.xml文件中配置是:
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
还有hdfs-site.xml、mapred-site.xml,自行设置好。
(2)检查这些配置文件是否在classpath下,如果不在,添加进去即拷贝到存放类文件的目录;
(3)或者在new Configuration()之后,调用set(“fs.default.name”,“hdfs://localhost:9000”)(根据情况设置)等。
8.5 报错信息“Unable to load native-hadoop library for your platform”
解决步骤:
(1)检查Hadoop本地库的实际路径,一般是$HADOOP_HOME/lib/native/Linux-amd64-64/
(2)在启动JVM时,在java命令中添加java.library.path属性即可,如下:
-Djava.library.path=$HADOOP_HOME/lib/native/Linux-amd64-64/
(3)或者使用LD_LIBRARY_PATH系统变量也能解决此问题,如下:
export LD_LIBRARY_PATH=$HADOOP_HOME/lib/native/Linux-amd64-64/
8.5格式化只能进行一次
-
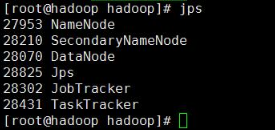
Hadoop环境搭建成功后,一般会运行一个小例子,这时候就涉及到了对HDFS文件系统的操作,对于刚开始学习Hadoop的初学者一般会多次的进行name节点的格式化操作,最后导致上传文件会抛出异常,通过jps命令查看会发现除了DataNode进程外其他进程都在正常运行,所以格式化只能进行一次,后续的集群启动或者操作均不需要格式化操作,具体解决方法如下:
-
首先保证没有重要数据的情况下彻底删除定义好的hadoop工作目录下的dfs、data、mapred这三个目录,删除之后重新格式化.
hadoop namenode -format
然后分别执行stop-all.sh、start-all.sh重启集群即可,这个时候对HDFS文件系统的操作就正常了,运行jps可以查看到DataNode进程正常运行
另外还有修改节点id的方法来配置出问题的机器节点,操作比较复杂,适用于生产环境中节点问题的解决
8.6HDFS性能问题排查
HDFS刚上线没有任何问题。就最近现网读写HDFS时,阶段性比较慢,也不是一直都比较慢,慢的时候读取一次需要20秒左右,一般毫秒级就可以返回。
注入性工具,性能问题第一想到的就是strace,查看一下系统调用,时间到底耗在哪儿了。strace的简单使用实例如下:
strace -o sshd.strace -fT -p 5352
strace -o ssh.strace -fT ssh 10.71.171.142
在文件中打印出来的系统调用比较多,虽然只是一个简单的数据读取。因为最后一列是时间,那么我就从一秒到十秒搜索一下吧,最后就发现了一个频繁5秒的调用,当前是timeout。那么通过上下文,发现前面有多次sendto进行重试,内容尽然是http://hadoop.hadoop.com,认证的时候使用了user/[email protected],域名解析的大致步骤是hosts->本地的域名服务器->指向的外面的域名服务器。那我们就在hosts中先加hadoop.hadoop.com域名吧。重启进程解决。
