SuperPoint: Self-Supervised Interest Point Detection and Description
摘要
本文提出了一种自我监督的框架,用于训练感兴趣点检测器和描述符,适用于计算机视觉中的大量多视图几何问题。与基于补丁的神经网络相反,我们的完全卷积模型在全尺寸图像上运行,并在一个正向通道中联合计算像素级兴趣点位置和相关描述符。我们介绍了Homographic Adaptation,这是一种多尺度,多种多样的方法,用于提高兴趣点检测的可重复性和执行跨域自适应(例如,合成到实际)。我们的模型在使用Homographic Adaptation对MS-COCO通用图像数据集进行训练时,能够重复检测比初始预适应深度模型和任何其他传统角点检测器更丰富的兴趣点集。与LIFT,SIFT和ORB相比,最终系统在HPatches上产生了最先进的单应性估计结果。
1. 介绍
几何计算机视觉任务的第一步是从图像中提取感兴趣点,例如同步定位和映射(SLAM)、运动结构(SFM)、摄像机标定和图像匹配。兴趣点是图像中的2D位置,其从不同的照明条件和视点是稳定和可重复的。然而,大多数真实世界计算机视觉系统的输入都是原始图像,而不是理想化的点位置.
本文提出了一种基于自我训练的自我监督解决方案,而不是利用人工监督来定义确定真实图像中的兴趣点。在我们的方法中,我们在真实图像中创建一个大的伪地面真实兴趣点位置数据集,由兴趣点检测器本身监督,而不是大规模的人类注释努力。

为了生成伪地真实兴趣点,我们首先在我们创建的称为合成形状的合成数据集的数百万个示例中训练一个完全卷积神经网络(参见图2a)。我们称之为训练有素的探测器MagicPoint,然而,当与各种图像纹理和图案集上的经典兴趣点检测器相比时,MagicPoint错过了许多潜在的兴趣点位置。为了弥合真实图像上的性能差距,我们开发了一种多尺度,多变换技术 - Homographic Adaptation
Homographic Adaptation是为了使兴趣点检测器的自监督训练成为可能。它多次扭曲输入图像以帮助兴趣点检测器从许多不同的角度和尺度看到场景(参见第5节)。我们使用Homographic Adaptation结合魔点检测器来提高检测器的性能,并生成伪地面真相感兴趣点(见图2b)。由此产生的检测结果在更大范围的刺激上更容易重复和激发,因此我们命名了由此产生的检测器超点。
在检测出鲁棒性和可重复感兴趣点之后,最常见的步骤是在每个点上附加一个固定的维描述符向量,用于更高层次的语义任务,例如图像匹配。因此,最后,我们将SuperPoint与描述符子网络组合在一起(参见图2c)。由于超点体系结构由一组深层次的卷积层组成,这些层提取多尺度特征,因此很容易将兴趣点网络与计算兴趣点描述符的附加子网络结合起来(参见第3节)。结果的系统如图1所示。

2. 相关工作
与之前的方法进行对比,从兴趣点、描述符、完整图像输入和实时进行对比。

3. 超点结构
我们设计了一种完全卷积的神经网络体系结构,称为Superpoint,它操作于一幅完整的图像上,并在一次前向传递中产生兴趣点检测和固定长度描述符(见图3)。该模型有一个单一的共享编码器来处理和降低输入图像的维数。编码后,该结构分成两个译码器“头”,分别学习任务特定的权重–一个用于兴趣点检测,另一个用于兴趣点描述。网络的大部分参数是在两个任务之间共享的,这与传统的先检测兴趣点,然后计算描述符的系统不同,缺乏跨两个任务共享计算和表示的能力。

3.1. 共享编码器
我们的超点结构使用vgg风格的编码器来降低图像的维数。编码器由卷积层、空间下采样池和非线性激活函数组成.我们的编码器使用三个最大池层,为图像大小为H×W的图像定义HC=H/8和WC=W/8。
3.2. 兴趣点解码器
对于兴趣点检测,输出的每个像素对应于输入中该像素的“点-度”的概率。用于稠密预测的标准网络设计涉及编码器-解码器对,其中空间分辨率通过池或跨区卷积降低,然后通过上卷积操作(如在SegNet[1]中所做的)上采样返回到完全分辨率。不幸的是,上采样层往往会增加大量的计算量,并且可以引入不必要的棋盘伪影[18],因此,我们设计了具有显式Decoder1的兴趣点检测头,以减少模型的计算。
3.3. 描述符解码器

3.4. 损失函数
最后的损失是两个中间损失的总和:一个用于兴趣点检测器Lp,另一个用于描述符Ld。我们使用综合扭曲的图像,它们同时具有(A)伪地面真值感兴趣点位置和(B)与这两幅图像相关的随机生成的同形H的地面真值对应。这允许我们同时优化这两个损失,给定一对图像,如图2c所示。我们使用λ来平衡最后的损失:


4. 合成预训练
在本节中,我们描述了我们训练一个基本检测器的方法(如图2a所示),它被称为魔点,它与 Homographic Adaptation 相结合,以自我监督的方式为未标记的图像生成伪地面真实感兴趣点标签。
4.1. 合成形状

目前还没有大型的兴趣点标记图像数据库。因此,为了引导我们的深度兴趣点检测器,我们首先创建一个大规模的合成数据集,称为合成形状,它由简化的二维几何组成,通过四边形、三角形、直线和椭圆的合成数据绘制。这些形状的例子如图4所示。在这个数据集中,我们可以通过用简单的Y-连接、L-连接、T-连接以及微小椭圆和线段端点的中心来建模兴趣点,从而消除标签的歧义。
4.2. 魔点

我们很惊讶地发现MagicPoint表现得很好,真实的世界图像,尤其是在强大的场景中角状结构,例如桌子、椅子和窗户。不幸的是,在所有自然图像的空间中,与相同的经典探测器相比,它表现不佳。在视点变化下的可重复性。这激发了我们关于真实世界图像训练的自监督方法我们称之为Homographic Adaptation。
5. Homographic Adaptation

单应性给出了相机运动的精确或几乎精确的图像转换,其中仅围绕相机中心旋转,具有与对象的距离大的场景,以及平面场景。此外,由于世界上大多数都是合理的平面,所以从不同的观点看,同一3D点的情况下,单应性是很好的模型。因为单应性不需要3D信息,所以它们可以被随机采样并容易地应用于任何2D图像,涉及很少的双线性内插。出于这些原因,同系物是我们自我监督的方法的核心。让f(·)表示我们希望适应的初始兴趣点函数,i输入图像,x表示所得到的兴趣点和h的随机同描记法,以便:

实际上,检测器不会是完全协变的–等式9中不同的同音图将导致不同的兴趣点X。同音适配的基本思想是在足够大的随机h样本上执行经验求和(见图5)。因此,对样本的聚合产生了一种新的、改进的超点检测器f^(·):
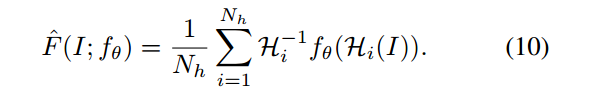
5.2. 选择同形

5.3. Iterative Homographic Adaptation

6. 实验细节
在本节中,我们将提供一些实现细节,用于培训魔点和超点模型。这个编码器有一个类似vgg的[27]结构,有8个3x3卷积层,大小为64-64-64-64-128-128-128。每两层有一个2x2的max池化层。每个解码器头具有单个3x3卷积层(256单元),其次是1x1卷积层(65个单元)和256单元(兴趣点检测器和描述符)。网络中的所有卷积层都遵循重线性激活和批归一化。对MagicPoint模型进行了200,000次合成数据迭代的培训。我们使用MSCOCO2014[13]培训数据集拆分生成伪地面真实标签,该数据集具有8,000个图像和MagicPoint基础检测器。这些图像的尺寸被确定为240*320的分辨率并且被转换为灰度。根据第5.2节的结果,使用NH=100的Homographic Adaptation 生成标签。所有实验中使用的描述符大小为d=256。我们使用λd=250的加权项来保持描述符学习的平衡。广义铰链损耗采用正裕度MP=1,负裕度Mn=0.2,我们采用λ=0.0001的因子来平衡这两种损失。所有培训均采用具有最小批量大小为3219]和具有Lr=0.001和Lr=(0.9;0.999)的默认参数的ADAM解算器完成。我们还使用标准数据增强技术,如随机高斯噪声、运动模糊、亮度水平变化来改善网络对照明和视点变化的鲁棒性
7. 实验
在这一部分,我们给出了本文提出的方法的定量结果。兴趣点和描述符的评估是一个研究较多的课题,因此我们遵循Mikołajczyk等人的评估协议。[16]。有关我们的评估指标的更多细节,请参见附录A。
7.1. 运行时间
我们使用Titan X GPU和Caffe[11]深度学习库提供的定时工具来测量超点体系结构的运行时间。该模型的一个前向通过在大约11.15ms内运行,输入大小为480×640,从而产生点检测位置和半密度描述符图。要从半密度描述符中以更高的480×640分辨率对描述符进行采样,不需要创建整个密集描述符映射-我们只需从1000个检测到的位置进行采样,这大约需要1.5ms的CPU实现双立方插值,然后进行L2归一化。因此,我们估计GPU上系统的总运行时间约为13ms或70FPS。
7.2. HPathces 可重复性

7.3. HPatches Homography Estimation
为了评估SuperPoint兴趣点检测器和描述符网络的性能,我们比较了HPATCHES数据集上的匹配能力。我们用三个著名的探测器和广义系统来评估SuperPoint:Lift[32],SIFT[15]和ORB[22]。


8. 总结
提出了一种基于自监督域自适应框架的兴趣点检测和描述的全卷积神经网络结构。实验证明:(1)将知识从合成数据集转移到真实图像上是可行的;(2)稀疏兴趣点检测和描述可以转化为一个单一、高效的卷积神经网络;(3)该系统适用于几何计算机视觉匹配任务,如同形估计。
今后的工作将研究同音适应是否能提高模型的性能,例如用于语义分割(例如SegNet[1])和目标检测(例如SSD[14])的模型。它还将仔细研究兴趣点检测和描述(以及潜在的其他任务)相互受益的方式。
最后,我们相信我们的超级网络可以用来解决像SLAM和SFM这样的3D计算机视觉问题中的所有视觉数据关联,而基于学习的视觉SLAM前端将在机器人和增强现实中提供更强大的应用。
