项目介绍:仿黑马旅游网,项目不是用maven构建的项目,数据库连接池使用的是c3p0不是druid,操作操作sql用的不是jdbcTemplate而是Apache的DBUtlis工具,json工具用的是阿里的fastjson,redis并没有用到,后期学习了但是,确实不错!后期对项目进行了完善,其实只要认真学完了黑马教程的这期案例,尽管黑马教程后面没有完善,但是自己实现并不困难,后期所有的分析设计都和前面的大同小异。
我的完善:
index.html
人气旅游最新旅游主题旅游的完善

国内游(境外游差别不大没有展示)
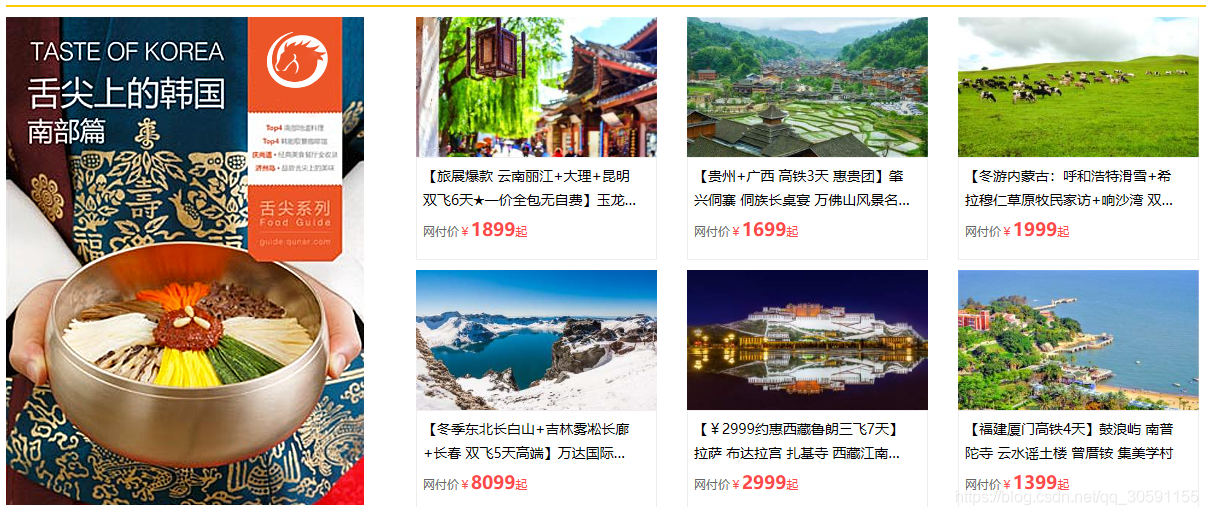
对导航栏下的出境游、抱团定制、全球自由行进行了数据的填充
( 这些数据的来源都是利用python爬虫从第三方网站爬取所获得的,非手动写入数据库而来的。)
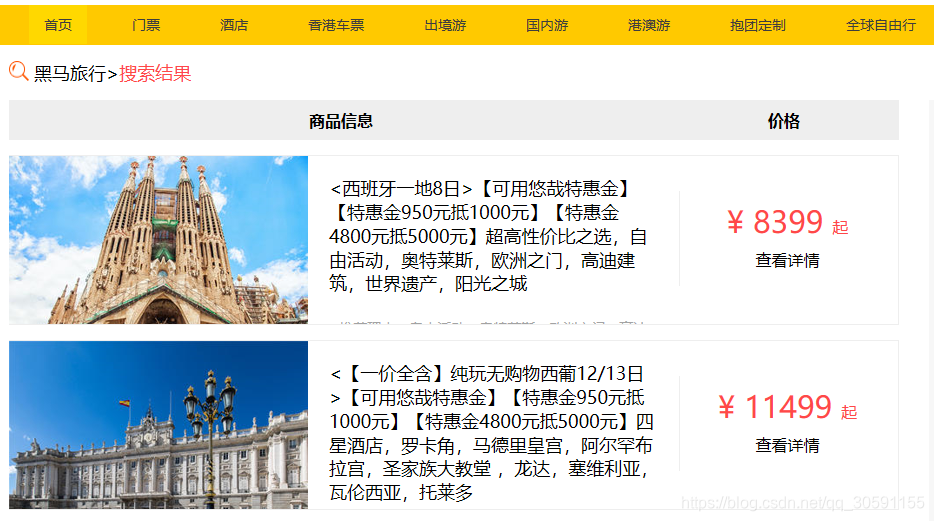

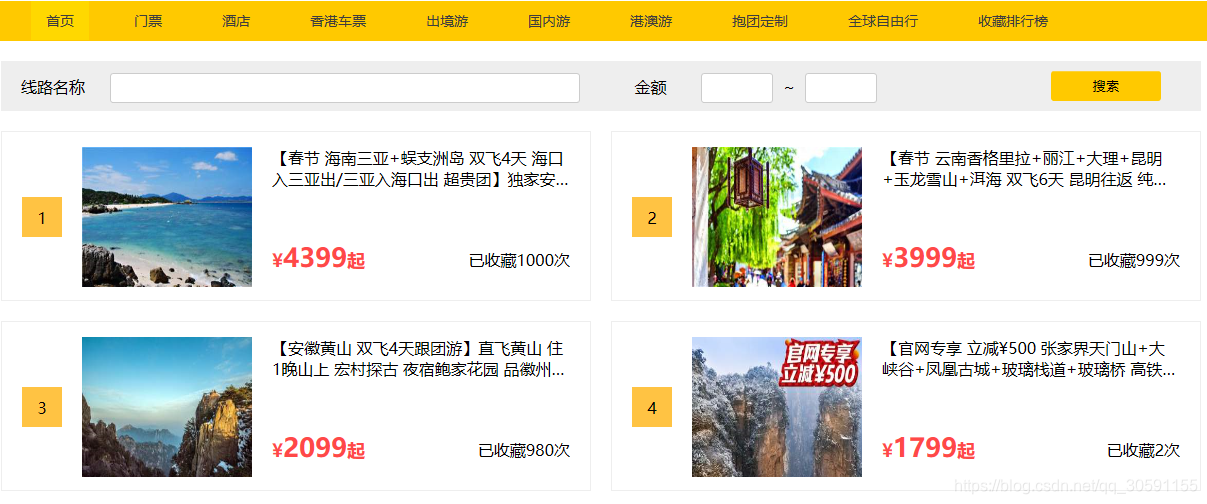
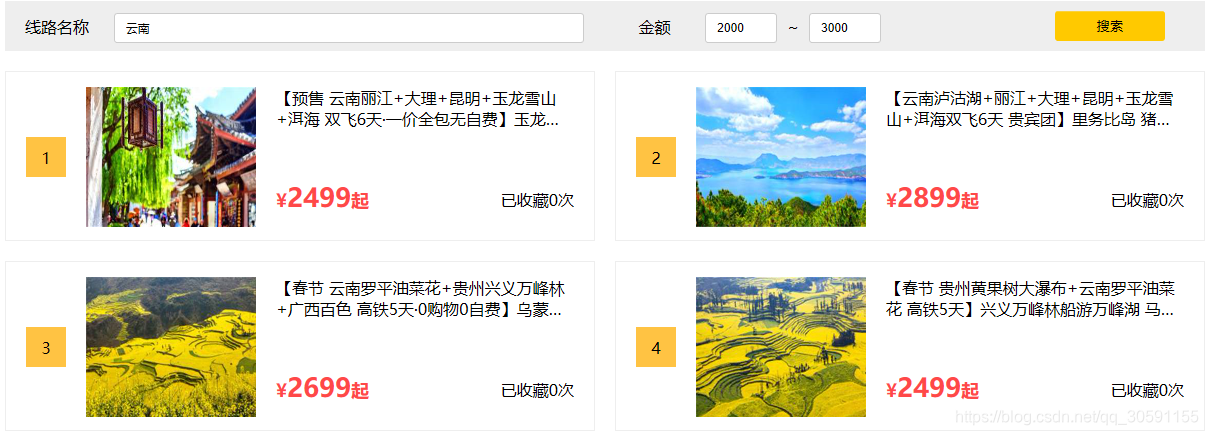
收藏排行榜、收藏排行榜下的线路名称、金额搜索特定功能的实现
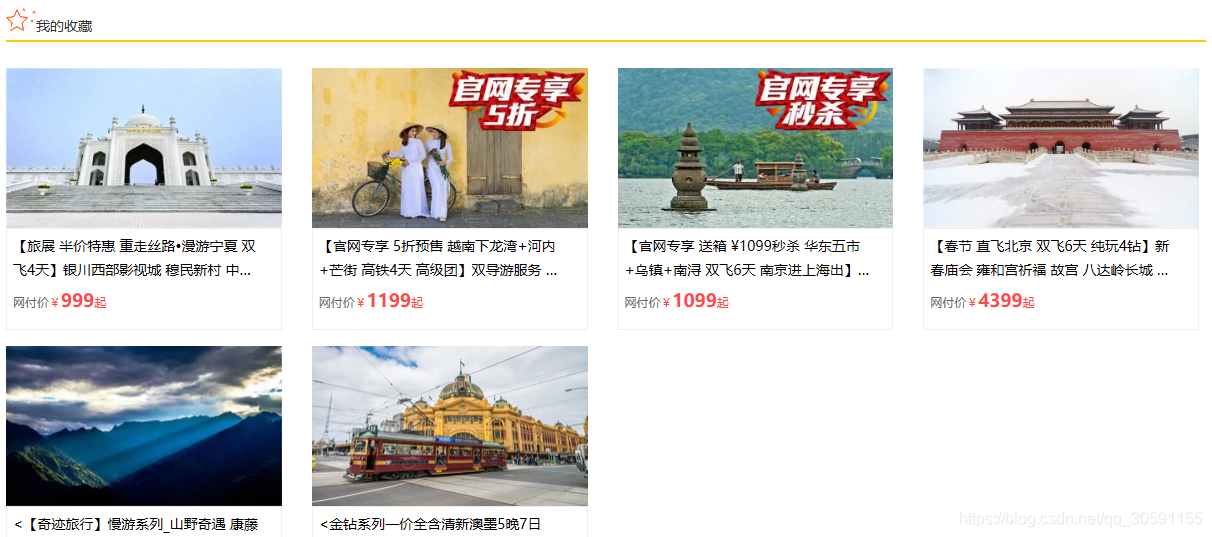
我的收藏
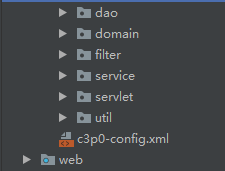
项目总结
设计模式
- 三层架构
前端 html 后台servlet 前端和后台的交互ajax异步技术
视图层(web层) 业务逻辑层(service层) 访问层(dao层)
注册模块
-
前端完成表单格式的校验,利用Regexp进行格式的校验比如用户名长度特殊字符邮箱的命名格式等,并且为每个input组件绑定onblur监听事件若格式不合法及时提示,序列化表单进行ajax异步提交。
-
序列化$(form).serialize():input组件必须要有name属性,序列化实质是将表单转化为形似json格式的数据,后台提取的时候也很方便利用request.getParameterMap Map<String, String[]>然后教程里面用的BeanUtils.populate(Bean,HashMap)进行的封装。
-
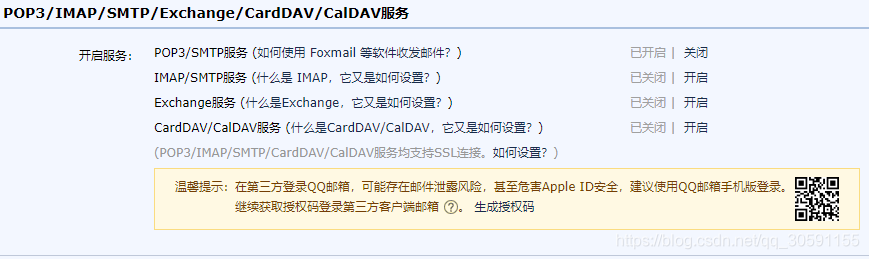
激活邮件发送的实现:qq邮箱授权码的获取 进入个人QQ邮箱首页选择设置—账户

- 开启账户下的pop3和smtp服务,需要用手机发送一条信息到指定的号码之后就可以获取到授权码。
Filter实现用户自动登录(AutoLoginFilter)
private IUserDao userDao = null;
public void destroy() {
}
public void doFilter(ServletRequest req, ServletResponse resp, FilterChain chain) throws ServletException, IOException {
HttpServletRequest request = (HttpServletRequest) req;
HttpSession session = request.getSession();
UserBean user = (UserBean) session.getAttribute("user");
Cookie cookie = null;
if (user == null) {
Cookie[] cookies = request.getCookies();
if (cookies != null && cookies.length > 0) {
for (Cookie c : cookies) {
if (c.getName().equals("AUTO_LOGIN")) {
cookie = c;
}
}
}
}
if (cookie != null) {
String[] userInfo = cookie.getValue().split("-");
UserBean u = userDao.findByUserNameAndPwd(userInfo[0], userInfo[1]);
if (u != null) {
session.setAttribute("user", u);
}
}
chain.doFilter(request, resp);
}
public void init(FilterConfig config) throws ServletException {
userDao = new UserDaoImpl();
}
注意点:session一次会话有效,一次会话指的是从浏览器的打开到关闭,自动登录逻辑就是利用客户端浏览器可以存放cookie的这一特性;首先判断当前session中是否有user,如果有说明用户已经登录用户的信息可以直接从session中获取;如果没有那么cookie就发挥作用了,判断本地cookie是否保存了用户的信息,如果保存了,利用dao层的相关方法对用户名密码进行判断,合法后存入session,自动登录完成。
chain.doFilter()请求和响应的分界线,doFilter之前可以对请求进行处理,之后可以对响应进行处理
分页功能的实现(仿百度前五后四)
// 1.1 处理页码 先处理两端然后再处理中间
var pn = '<li><a href="javascript:load(1)">首页</a></li>\n';
if (curPage - 1 < 1) {
pn += '<li οnclick="javascript:load(1)" class="threeword"><a href="javascript:;">上一页</a></li>';
} else {
pn += '<li οnclick="javascript:load('+(curPage-1)+')" class="threeword"><a href="javascript:;">上一页</a></li>';
}
// 1.2 前五后四 页面逻辑
var begin;
var end;
if (data.totalPage < 10) {
begin=1;
end = data.totalPage;
} else {
begin = data.currentPage - 5;
end = data.currentPage + 4;
if (begin < 1) {
begin = 1;
end = begin + 9;
} else if (end > data.totalPage) {
end = data.totalPage;
begin = end - 9;
}
}
for (var i = begin; i <= end; i++) {
if (i == data.currentPage)
pn += '<li class="curPage" οnclick="javascript:load('+(i)+')"><a href="javascript:;">'+i+'</a></li>';
else
pn += '<li οnclick="javascript:load('+(i)+')"><a href="javascript:;">'+i+'</a></li>';
}
if (curPage + 1 > data.totalPage) {
pn += '<li οnclick="javascript:load('+(data.totalPage)+')" class="threeword"><a href="javascript:;">下一页</a></li>';
} else {
pn += '<li οnclick="javascript:load('+(curPage+1)+')" class="threeword"><a href="javascript:;">下一页</a></li>';
}
pn += '<li οnclick="javascript:load('+(data.totalPage)+')"><a href="javascript:;">末页</a></li>';
$("#pageNum").html(pn);
// 2 数据展示
servlet优化之BaseServlet
随着后期代码的编写,每个功能都对应一个servlet都要有doGet和doPost方法。比如login和logout功能,它是和用户相关联,可不可以把所以和用户相关联的功能封装到一个servlet里面,以后所有和用户相关的请求都分发给UserServlet下的方法,所以可以编写一个Servlet重写service服务,利用反射动态处理请求分发,这就是一种java设计模式(类似模板设计模式回头要重新学习下java设计模式)BaseServlet就像相当于一个中转站实现请求的分发。
// 教程
protected void service(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
super.service(req, resp);
String URI = req.getRequestURI();
String methodName = URI.substring(URI.lastIndexOf("/")+1);
/* 反射 由于请求的URI method不是固定的,是变化的,不能提前new对象来调用方法
最好的方法是通过反射来生成对象调用其中的方法
this 对象是属于UserServlet,因为UserServlet extend BaseServlet
this对象属于谁调用的就是谁的
*/
Class<? extends BaseServlet> cls = this.getClass();
try {
Method method = cls.getMethod(methodName, HttpServletRequest.class, HttpServletResponse.class);
method.invoke(this, req, resp);
} catch (NoSuchMethodException | InvocationTargetException | IllegalAccessException e) {
e.printStackTrace();
}
/* 自己写的 后期扩展代码量也会增多 写法不好
Object obj = null;
UserServlet userServlet = null;
CategoryServlet categoryServlet = null;
RouteServlet routeServlet = null;
try {
obj = cls.newInstance();
} catch (InstantiationException | IllegalAccessException e) {
e.printStackTrace();
}
if (obj instanceof UserServlet) {
System.out.println("obj is userServlet");
userServlet = (UserServlet)obj;
} else if (obj instanceof CategoryServlet) {
System.out.println("obj is category");
categoryServlet = (CategoryServlet) obj;
} else if (obj instanceof RouteServlet) {
System.out.println("obj is route");
routeServlet = (RouteServlet) obj;
}
switch (methodName) {
case "login" :
userServlet.login(req, resp);
break;
case "logout" :
userServlet.logout(req, resp);
break;
case "active_user" :
userServlet.active_user(req, resp);
break;
case "register" :
userServlet.register(req, resp);
break;
case "show_username" :
userServlet.show_username(req, resp);
break;
case "findAll" :
categoryServlet.findAll(req, resp);
break;
case "pageQuery" :
routeServlet.pageQuery(req, resp);
break;
case "findOne" :
routeServlet.findOne(req, resp);
break;
case "isFavorite" :
routeServlet.isFavorite(req, resp);
break;
case "addFavorite" :
routeServlet.addFavorite(req, resp);
break;
case "findSpecific" :
routeServlet.findSpecific(req, resp);
break;
case "findRoutesByCid" :
routeServlet.findRoutesByCid(req, resp);
break;
}*/
domain层的总结
外键转实体
数据库中tab_favorite

java实体中的字段

数据库中rid和uid在java实体favorite中并没有单单定义为两个普通字段,而是分别对应route和user实体,为什么要这样?实际应用中我发现一个好处就是方便、更容易切合我要实现的功能(比如数据展示和提取)
public class PageBean<T> {
private int totalCount; // 总记录数
private int totalPage; // 总页面数
private int currentPage;// 当前页面
private int pageSize; // 每页展示记录条数
private List<T> list; // 每页展示的数据集合
public int getTotalCount() {
return totalCount;
}
public void setTotalCount(int totalCount) {
this.totalCount = totalCount;
}
public int getTotalPage() {
return totalPage;
}
public void setTotalPage(int totalPage) {
this.totalPage = totalPage;
}
public int getCurrentPage() {
return currentPage;
}
public void setCurrentPage(int currentPage) {
this.currentPage = currentPage;
}
public int getPageSize() {
return pageSize;
}
public void setPageSize(int pageSize) {
this.pageSize = pageSize;
}
public List<T> getList() {
return list;
}
public void setList(List<T> list) {
this.list = list;
}
}
pageBean:这个bean可以说凡涉及到分页都发挥了举足轻重的作用;泛型可以更好的扩展,教程中PageBean中列出了对Route进行了封装,比如我在实现扩展功能的时候,我可以利用泛型对favorite做封装。
dao层总结
sql的拼接
第一次接触,见识太少了(只怪自己才疏学浅啊!)记录下来吧!
实现sql拼接的基础 省去where 1=1 试试能实现么,会乱套。

String sqlTemplate = "select count(*) from tab_route where 1=1 "
// 查找数据库route线路记录总数
public int findTotalCount(int cid, String rname, String searchName, int upBound, int lowBound, int uid) {
QueryRunner runner = new QueryRunner(C3p0Util.getDataSource());
String sqlTemplate = "select count(*) from tab_route where 1=1 ";
StringBuilder sb = new StringBuilder(sqlTemplate);
List params = new ArrayList();
if (cid != 0) {
sb.append(" and cid=? ");
params.add(cid);
}
if (rname != null && rname.length() > 0 && !"null".equals(rname)) {
sb.append(" and rname like ? ");
params.add("%"+rname+"%");
}
if (searchName != null && searchName.length() > 0 && !"null".equals(searchName)) {
sb.append(" and rname like ? ");
params.add("%"+searchName+"%");
}
if (upBound != 0 && lowBound != 0) {
sb.append(" and price > ? and price < ? ");
params.add(lowBound);
params.add(upBound);
}
if (uid != 0) {
sb.append(" and rid in (select rid from tab_favorite where uid = ?) ");
params.add(uid);
}
long count = 0;
try {
count = runner.query(sb.toString(), new ScalarHandler<>("count(*)"), params.toArray());
} catch (SQLException e) {
e.printStackTrace();
}
return (int)count;
}
python爬取http://search.uzai.com/相关旅游信息
实现思路:根据数据库route_img表和route表的关系,一对多的关系分析明白后爬取图片构造图片存入数据库后的命名也就轻而易举了
# rname! price! routeIntroduce rflag! rdate isThemeTour! count cid! rimage sid! sourceId
# !标志必填字段
# img/product/small/m3f9cb1c7e3488f60e3b3da09b8700df5d.jpg
# 爬取各种数据 需要手动更改的字段(当然可以用程序实现)
# 页码 rid sourceId cid
import time
import requests
import pymysql
from lxml import etree
# http://search.uzai.com/%E8%B7%9F%E5%9B%A2%E6%B8%B8/2/0/0/s0-pCOTT001237/
headers={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWe\
bKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36"
}
conn=pymysql.connect(host="127.0.0.1",
user="root",
password="root",
database="travel",charset="utf8")
cursor=conn.cursor()
# url="https://search.uzai.com/%E8%B7%9F%E5%9B%A2%E6%B8%B8/2/1/2/s0/"
# url="https://search.uzai.com/%E8%B7%9F%E5%9B%A2%E6%B8%B8/2/0/0/s0-pCOTT001237/" 跟团游
# url="https://search.uzai.com/all/2/2/2/s0/" # 自由行
url="https://search.uzai.com/aodaliya/" # 出境游
text=requests.get(url, headers=headers, verify=False).text
html=etree.HTML(text)
detailUrl=html.xpath('//div[@class="main_left1"]/a/@href')
# 每页列表展示的图片 list
imgurl=html.xpath('//div[@class="imageWarp"]/img[@class="left lazy"]/@data-original')
# 缩略图 第一次请求 得到 详细页面的url 再次请求获得 详细页的所需信息
# rname list
rname=html.xpath('//div[@class="main_left1_rl"]/h2/@title')
# rprice list
rprice=html.xpath('//div[@class="price"]/b')
print(len(detailUrl))
index=0
rid=645
for i in detailUrl:
i="https:"+i
detailText=requests.get(i, headers=headers, verify=False).text
detailHtml=etree.HTML(detailText)
introduce=detailHtml.xpath('//div[@class="main2_right_m2_m"]//p')[-1].text
smallImageUrl=detailHtml.xpath('//div[@class="main_left_rotater"]/div/img[@class="img lazy"]/@data-original')
# route_list 页面处理
ticksBig=str(time.time()).replace(".","")+".jpg"
try:
bdata=requests.get(imgurl[index]).content
except Exception as e:
index += 1
continue
with open(r'F:\IntellijIDEA\mytravel\web\img\product\small\\'+ticksBig, 'wb') as fp:
fp.write(bdata)
# print(rname[index],rprice[index].text,introduce)
ttime=time.strftime("%Y-%m-%d %H:%M:%S", time.localtime());
sourceId=str((index+63))
sql="insert tab_route(rname,price,routeIntroduce,rflag,rdate,isThemeTour,count,cid,rimage,sid,sourceId)\
values('%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s')"\
%(rname[index],rprice[index].text,introduce,1,ttime,0,0,4,"img/product/small/"+ticksBig,1,sourceId)
cursor.execute(sql)
conn.commit()
index += 1
print(rid)
# 详细页面处理 route_detail(按照黑马逻辑)
for j in smallImageUrl:
bigUrl=j.replace("w/182","w/550").replace("h/137","h/413")
bigData=requests.get(bigUrl).content
smallData=requests.get(j).content
ticks=str(time.time()).replace(".","")+".jpg"
with open(r'F:\IntellijIDEA\mytravel\web\img\product\size4\\'+ticks, 'wb') as fp:
fp.write(bigData)
with open(r'F:\IntellijIDEA\mytravel\web\img\product\size2\\'+ticks, 'wb') as fp:
fp.write(smallData)
print(rid)
sql="insert into tab_route_img(rid,bigPic,smallPic)\
values('%s','%s','%s')"\
%(rid,"img/product/size4/"+ticks, "img/product/size2/"+ticks)
cursor.execute(sql)
conn.commit()
rid += 1
