论文: https://ieeexplore.ieee.org/document/8217759 或者 https://pan.baidu.com/s/1yzpzZQ9718lAYYWO5K9_Uw
机构: 北京理工大学
启发:
模型的思路是根据医生诊断疾病的过程来设计的,通过与病人具有相似疾病或症状的其它病人,来预测该病人的疾病。如果以前出现过类似情况的病人,那医生的诊断概率就比较高了。
This framework is motived by the working process of human doctors, i.e., after reviewing or recalling the diagnosed patients with similar diseases or symptoms, the doctors then carefully make decision. If doctors can find similar patients, the probability of successfully curing this patient may improve a lot.
global models VS personalized models
以往的预测模型,通过在所有训练数据上训练一个模型,来对测试数据进行预测。
然而,个体往往具有特殊性。
所以,可以先找到与所预测个体相似的群体,然后建立个性化模型来进行预测。
A conventional approach of disease prediction is the one-size-fit-all model. That is, using all available training data to build a global model, and then with this model, predicting the risk of diseases for each patient. The benefit of applying a one-size-fit-all model is that it captures the overall information of the entire training population.
However, patients may have different phenotypes, different medical conditions, etc. Using a global model may miss some specific information that is important for individual patients. Thus, building a targeted, patient-specific model for each individual patient is urgent and important for personalized medicine.
Personalized predictive modeling, which focuses on building specific models for individual patients, has shown its advantages on utilizing heterogeneous health data compared to global models trained on the entire population.
过程:
In this paper, we propose a time-fusion CNN based framework to pairwise measure patient similarity, and use three ways to perform personalized disease prediction.
1. 相似度学习 Similarity Learning
一个端到端的框架,是基于成对训练的CNN模型的相似度学习
end-to-end framework of similarity learning based on pairwise training CNN
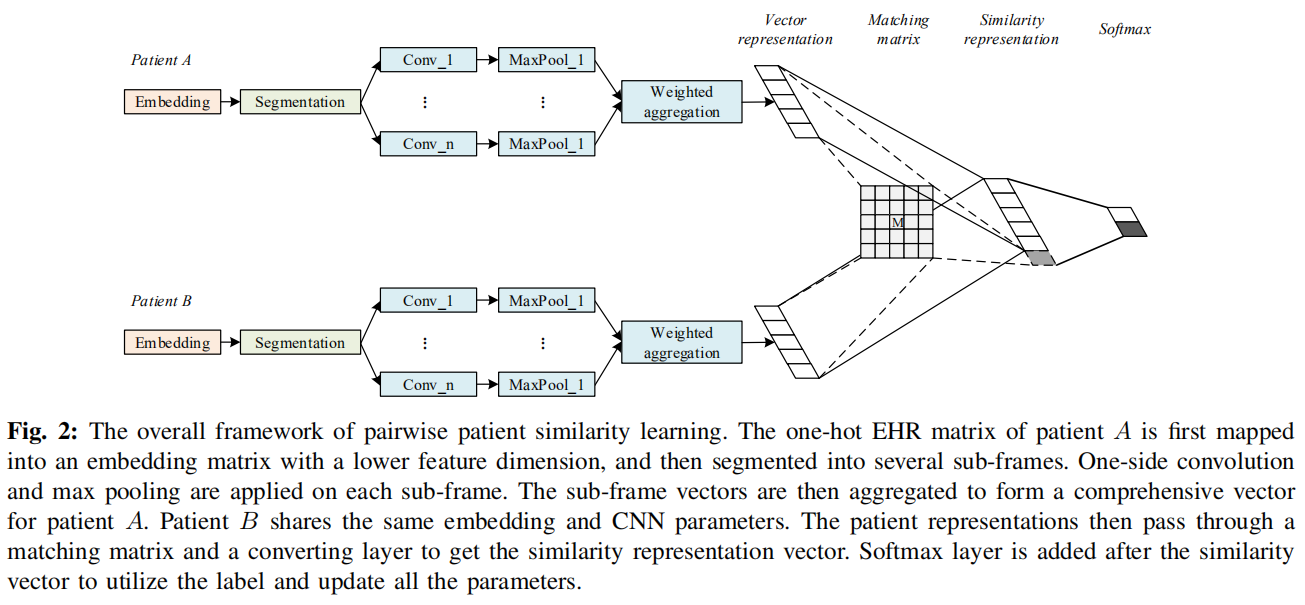
详细过程如下:
-
Basic Notations: 每个病人的记录映射成一个固定维度的二维矩阵
一个病人的记录里包含了他的就诊信息序列。每次就诊记录可以对照International Classification of Disease (ICD-9)进行one-hot编码,映射成一个一维的向量。多次就诊的向量表示按时间顺序拼接,得到二维矩阵。横轴维度为就诊项目数量,为记录库中的medical code的数量。纵坐标维度为就诊次数,不同的病人,就诊次数不同,通过补零,使得所有病人的向量表示具有相同的大小。 -
Visit Embedding : 对病人的矩阵表示进行降维
medical code也就是各种疾病,它们不是相对独立的,可能会存在一些关联关系。上面的表示方法忽略了这种关联关系,用one-hot表示,使得矩阵的维度比较高,且数据比较稀疏。为了降低矩阵的维度和学习疾病之间的关联关系,本文利用一个全连接网络将各种疾病映射到一个向量空间中。于是,就诊记录 将通过公式 转化为 .每个病人将对应一个矩阵 . 其中 为所有的病人就诊记录数的最大值。 -
Convolutional Neural Network :利用卷积神经网络提取特征
病人的矩阵表示中,纵坐标是按就诊有时间排列的,有时间关系,然而横坐标中疾病的先后位置没有时间和空间的关系。于是,文章中利用 one-side convolution operation. 卷积层使用了 个不同大小的 filter,每一种 filter 的数量为 ,一共 个。经过卷积、池化,得到特征向量 . -
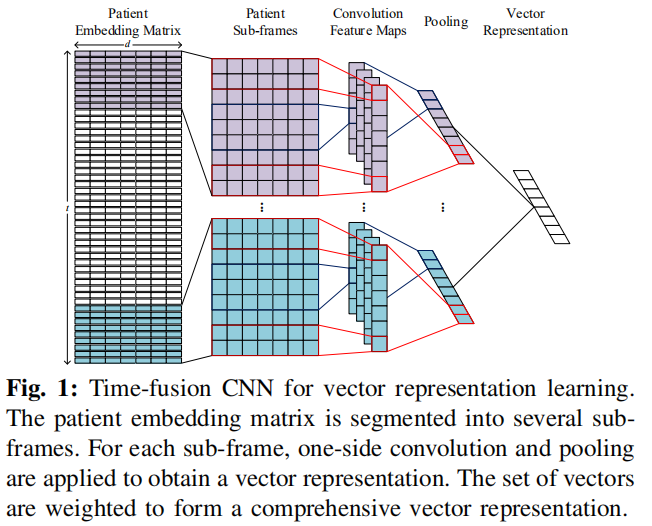
Time Fusion : 充分利用时间信息
上面卷积的操作过程中,没有充分利用就诊记录的时间信息,对每个时间点的数据都是同等对待的。于是,利用 Time Fusion 的概念对上面操作进行调整。对病人的矩阵表示,拆分成多个 sub-frame ,每个 sub-frame 包含固定的 k 个就诊记录。拆分过程中为了避免破坏连续的就诊记录数据,使用滑动窗口。这样可以得到多个 sub-frame。对每个 sub-frame,使用上面CNN的操作得到特征向量。每个特征向量 ,通过公式 得到权重,对所有权重进行softmax操作。最后得到病人的特征向量 . -
Similarity Learning : 相似度学习
两个特征向量之间的相似度可以通过这个公式得到 . 其中 . 为了保证 是对称矩阵, . 其中 , 确保低阶特性. 至此,得到两个特征向量的相似度 . 通过 , 其中 , 是按位相加操作。之后, 和 连接成一个向量,经过全连接网络和softmax操作,得到最终的概率 , 代表两个病人之间的相似度。其中 代表两个病人有患同一种病的风险。最后利用 与 的交叉熵计算损失值 。其中 为所有病人对的总数。如果有 个病人,那么 .
2. 个性化预测 Personalized Prediction
对每一个病人,计算他和其它病人的相似度,然后根据相似度排序。然后根据与他较为相似的一群人,来对他进行个性化预测。
-
K Nearest Neighbors
选择与测试病人最接近的 k 个病人,然后在他们中间出现最频繁的疾病作为预测结果。 -
Discriminate Classification
选择 k 个最相似的病人和 k 个最不相似的病人,然后训练一个多类别逻辑回归模型作为预测模型。一个病人训练一套参数,来进行个性化预测。 -
Weighted Sampling
上面两种方式都需要优化参数 k ,于是,提出利用权重采样来挑选病人的训练群体。即,按照相似度的分布来挑选病人,然后利用采样的病人数据,通过多数投票法来得到预测结果。
BibTeX:
@inproceedings{DBLP:conf/bibm/SuoMYHZZG17,
author = {Qiuling Suo and
Fenglong Ma and
Ye Yuan and
Mengdi Huai and
Weida Zhong and
Aidong Zhang and
Jing Gao},
title = {Personalized disease prediction using a CNN-based similarity learning
method},
booktitle = {2017 {IEEE} International Conference on Bioinformatics and Biomedicine,
{BIBM} 2017, Kansas City, MO, USA, November 13-16, 2017},
pages = {811--816},
year = {2017},
url = {https://doi.org/10.1109/BIBM.2017.8217759},
doi = {10.1109/BIBM.2017.8217759},
timestamp = {Wed, 16 Oct 2019 14:14:56 +0200},
biburl = {https://dblp.org/rec/bib/conf/bibm/SuoMYHZZG17},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
