众所周知,python是一个很强大的语言,它拥有众多的库,今天我尝试了使用python进行验证码的识别。
开始,我们先进行验证码的下载。
下载
我们先找见一个登陆需要验证码的网站,比如说这个网站:http://user.sc.chinaz.com/login.aspx


按F12进入调试界面,点击network,再点一下验证码进行刷新

可以看到这个图片:

点击进入图片就可以得到一个验证码的界面
此后我们再将该界面的图片进行下载就可以得到一堆的验证码了。

识别:
下载完所有的代码,我们就可以进行验证码的识别了。python的验证码识别包我们可以下载pytesseract包
当然,在下载pytesseract包之前,我们还得下载tesseract包。如果仅仅就是这样的话那还是远远不够的,会出现找不见tesseract包的错误,所以我们还需要下载Tesseract-OCR
具体的下载方式可以参考博文:Tesseract-OCR下载和安装
如果还出现错误的话,可以参考这篇博文:python3.5 tesseract-ocr 验证码识别错误解决方案
以上两篇博文基本上可以解决下载tesseract的很多错误了(亲测,有效)
好了,上代码:
import requests,urllib,pytesseract
from PIL import Image
pytesseract.pytesseract.tesseract_cmd = 'D:/Tesseract-OCR/tesseract.exe'
tessdata_dir_config = '--tessdata-dir "D:/Tesseract-OCR/tessdata"'
url = 'http://user.sc.chinaz.com/getcode.aspx?h=30&t=0.7468559373230685' #验证码网址,可以根据需求更换
storeurl = 'C:/Users/11037/Desktop/yanzhengma' #保存本地文件夹
def savaImg(picurl,saveurl): #存储图片函数
bytes = urllib.request.urlopen(picurl)
file = open(saveurl,'wb')
file.write(bytes.read())
file.flush()
file.close()
return True
def getpicture(): #获取验证码函数
coun = int(input('请输入需要下载的验证码数量:'))
for i in range(coun):
theurl = storeurl + '/' + str(i) + '.jpg'
if savaImg(url,theurl):
print('已下载:'+str(i+1))
def jpgtostring(pictureurl): #图片转验证码函数
print('图片源地址:'+pictureurl)
picture = Image.open(pictureurl)
result = pytesseract.image_to_string(picture,lang='eng',config=tessdata_dir_config)
print(result)
pictureurl = 'C:/Users/11037/Desktop/yanzhengma/1.jpg'
jpgtostring(pictureurl)
验证码原图:
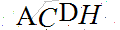
运行结果:

