wordcloud是Python扩展库中一种将词语用图片表达出来的一种形式,通过词云生成的图片,我们可以更加直观的看出某篇文章的故事梗概。
首先贴出一张词云图(以哈利波特小说为例):

在生成词云图之前,首先要做一些准备工作
安装结巴分词库
pip install jieba
Python中的分词模块有很多,他们的功能也都是大同小异,我们安装的结巴分词 是当前使用的最多的类型。
下面我来简单介绍一下结巴分词的用法
结巴分词的分词模式分为三种:
(1)全模式:把句子中所有的可以成词的词语都扫描出来, 速度快,但是不能解决歧义问题
(2)精确模式:将句子最精确地切开,适合文本分析

(3)搜索引擎模式:在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词
下面用一个简单的例子来看一下三种模式的分词区别:
import jieba
# 全模式:把句子中所有的可以成词的词语都扫描出来, 速度快,但是不能解决歧义问题
text = "哈利波特是一常优秀的文学作品"
seg_list = jieba.cut(text, cut_all=True)
print(u"[全模式]: ", "/ ".join(seg_list))
# 精确模式:将句子最精确地切开,适合文本分析
seg_list = jieba.cut(text, cut_all=False)
print(u"[精确模式]: ", "/ ".join(seg_list))
# 默认是精确模式
seg_list = jieba.cut(text)
print(u"[默认模式]: ", "/ ".join(seg_list))
# 搜索引擎模式:在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词
seg_list = jieba.cut_for_search(text)
print(u"[搜索引擎模式]: ", "/ ".join(seg_list))下面是对这句话的分词方式:
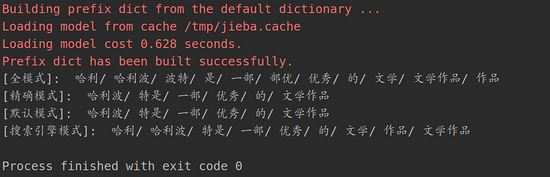
通过这三种分词模式可以看出,这些分词模式并没有很好的划分出“哈利波特”这个专有名词,这是因为在结巴分词的字典中并没有记录这个名词,所以需要我们手动添加自定义字典。
添加自定义字典:找一个方便引用的位置(下图的路径是我安装的位置),新建文本文档(后缀名为.txt),将想添加的词输入进去(注意输入格式),保存并退出。
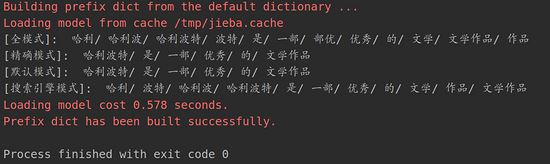
在上面的代码中加入自定义字典的路径,再点击运行。
jieba.load_userdict("/home/jmhao/anaconda3/lib/python3.7/site-packages/jieba/mydict.txt")分词结果,可以看出“哈利波特”这个词已经被识别出来了。
结巴分词还有另一个禁用词的输出结果。
stopwords = {}.fromkeys(['优秀', '文学作品'])
#添加禁用词之后
seg_list = jieba.cut(text)
final = ''
for seg in seg_list:
if seg not in stopwords:
final += seg
seg_list_new = jieba.cut(final)
print(u"[切割之后]: ", "/ ".join(seg_list_new))可以看到输出结果中并没有“优秀”和“文学作品”两个词

结巴分词还有很多比较复杂的操作,具体的可以去官网查看,我就不再过多的赘述了。
下面我们正式开始词云的制作。
首先下载模块,这里我所使用的环境是Anaconda,由于Anaconda中包含很多常用的扩展包,所以这里只需要下载wordcloud。若使用的环境不是Anaconda,则另需安装numpy和PIL模块。
pip install wordcloud
然后我们需要找一篇文章并使用结巴分词将文章分成词语的形式。
# 分词模块
def cut(text):
# 选择分词模式
word_list = jieba.cut(text,cut_all= True)
# 分词后在单独个体之间加上空格
result = " ".join(word_list)
# 返回分词结果
return result这里我在当前文件夹下创建了一个文本文档“xiaoshuo.txt”,并复制了一章的小说作为词云的主体文字。
使用代码控制,打开并读取小说的内容
#导入文本文件,进行分词,制作词云
with open("xiaoshuo.txt") as fp:
text = fp.read()
# 将读取的中文文档进行分词
text = cut(text)在网上找到一张白色背景的图片下载到当前文件夹,作为词云的背景图(若不指定图片,则默认生成矩形词云)
#设置词云形状,若设置了词云的形状,生成的词云与图片保持一致,后面设置的宽度和高度将默认无效
mask = np.array(image.open("monkey.jpeg"))接下来可以根据喜好来定义词云的颜色、轮廓等参数 下面为常用的参数设置方法

完整代码
#导入词云库
from wordcloud import WordCloud
#导入图像处理库
import PIL.Image as image
#导入数据处理库
import numpy as np
#导入结巴分词库
import jieba
# 分词模块
def cut(text):
# 选择分词模式
word_list = jieba.cut(text,cut_all= True)
# 分词后在单独个体之间加上空格
result = " ".join(word_list)
return result
#导入文本文件,进行分词,制作词云
with open("xiaoshuo.txt") as fp:
text = fp.read()
# 将读取的中文文档进行分词
text = cut(text)
#设置词云形状
mask = np.array(image.open("monkey.jpeg"))
#自定义词云
wordcloud = WordCloud(
# 遮罩层,除白色背景外,其余图层全部绘制(之前设置的宽高无效)
mask=mask,
#默认黑色背景,更改为白色
background_color='#FFFFFF',
#按照比例扩大或缩小画布
scale=,
# 若想生成中文字体,需添加中文字体路径
font_path="/usr/share/fonts/bb5828/逐浪雅宋体.otf"
).generate(text)
#返回对象
image_produce = wordcloud.to_image()
#保存图片
wordcloud.to_file("new_wordcloud.jpg")
#显示图像
image_produce.show()注:若想要生成以下样式的词云图,找到的图片背景必须为白色,或者使用Photoshop抠图替换成白色背景,否则生成的词云为矩形
我的词云原图:

生成的词云图:

文源网络,仅供学习之用,如有侵权,联系删除。
我将优质的技术文章和经验总结都汇集在了我的公众号【Python圈子】里。
在学习Python的道路上肯定会遇见困难,别慌,我这里有一套学习资料,包含40+本电子书,600+个教学视频,涉及Python基础、爬虫、框架、数据分析、机器学习等,不怕你学不会!还有学习交流群,一起学习进步~

