HashMap线程不安全的原因:
1、put的时候导致的多线程数据不一致。
这个问题比较好想象,比如有两个线程A和B,首先A希望插入一个key-value对到HashMap中,首先计算记录所要落到的桶的索引坐标,然后获取到该桶里面的链表头结点,此时线程A的时间片用完了,而此时线程B被调度得以执行,和线程A一样执行,只不过线程B成功将记录插到了桶里面,假设线程A插入的记录计算出来的桶索引和线程B要插入的记录计算出来的桶索引是一样的,那么当线程B成功插入之后,线程A再次被调度运行时,它依然持有过期的链表头但是它对此一无所知,以至于它认为它应该这样做,如此一来就覆盖了线程B插入的记录,这样线程B插入的记录就凭空消失了,造成了数据不一致的行为。
2、在扩容的时候,jdk1.8之前是采用头插法,当两个线程同时检测到hashmap需要扩容,在进行同时扩容的时候有可能会造成链表的循环,主要原因就是,采用头插法,新链表与旧链表的顺序是反的,在1.8后采用尾插法就不会出现这种问题,同时1.8的链表长度如果大于8就会转变成红黑树。
我们俩就举个例子:
如下:A的下一个指针是指向B的,即A->B->C
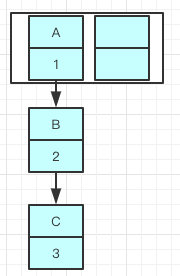
在进行扩容的时候,采用单链表的头插法,同一位置上新元素总会被放在链表的头部位置,那么原来的Entry元素就会往后一个位置。
很有可能就会出现下面的情况:
B的下一个指针指向了A
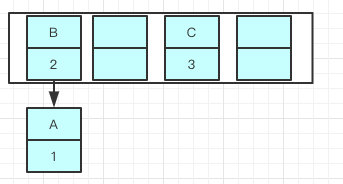
一旦几个线程都调整完成,就可能出现环形链表,
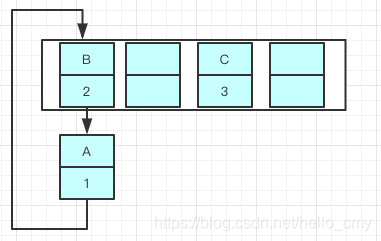
那么如何解决这个问题呢?
1、使用HashTable替代HashMap
当一个线程访问HashTable的同步方法时,其他线程如果也要访问同步方法,会被阻塞住。举个例子,当一个线程使用put方法时,另一个线程不但不可以使用put方法,连get方法都不可以。效率很低,所以基本不用。
HashTable内方法上使用了synchronized。
//Hashtable
Map<String, String> hashtable = new Hashtable<>();
2、类ConcurrentHashMap定义Map
package java.util.concurrent;
public class ConcurrentHashMap<K,V> extends AbstractMap<K,V>
implements ConcurrentMap<K,V>, Serializable {
...
}
ConcurrentHashMap是JUC包中的一个类,方法内部使用了synchronized保证线程安全。
//ConcurrentHashMap
Map<String, String> concurrentHashMap = new ConcurrentHashMap<>();
3、Collections类的synchronizedMap(Map m)方法可以返回一个线程安全的Map
Map map = Collections.synchronizedMap(new HashMap<>());
经别人测试,ConcurrentHashMap的性能很高!!!
参考文章: https://blog.csdn.net/mrleeapple/article/details/91648659
