线性回归到底要干什么,顾名思义很简单,即在已有数据集上通过构建一个线性的模型来拟合该数据集特征向量的各个分量之间的关系,对于需要预测结果的新数据,我们利用已经拟合好的线性模型来预测其结果。关于线性回归的方法,现在使用得比较广泛的就是梯度下降和最小二乘法;我打算把最小二乘法和梯度下降分两篇博客来写,这篇就来说一说我对线性回归及最小二乘法的理解以及原理实现。
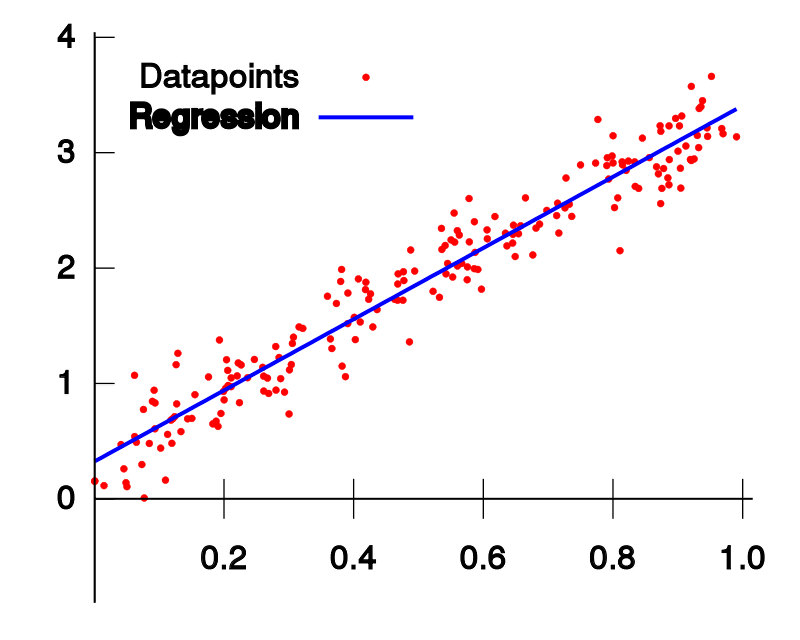
线性模型在二维空间中就是一条直线,在三维空间是一个平面,高维空间的线性模型不好去描述长什么样子;如果这个数据集能够用一个线性模型来拟合它的数据关系,不管是多少维的数据,我们构建线性模型的方法都是通用的。之前看吴恩达机器学习视频,第一节课讲的就是线性回归算法,课程里面提到了一个非常简单的案例:房屋估价系统。房屋估价系统问题就是当知道房屋面积、卧室个数与房屋价格的对应关系之后,在得知一个新的房屋信息后如何得到对应的新房屋价格,如果我们将房屋面积用x1表示,卧室个数用x2表示,即房屋价格h(x)可以被表示为房屋面积与卧室个数的一维线性方程:
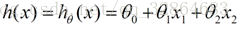
这就是我们所说的线性模型,当然这个案例中只有房屋面积和卧室个数两个特征分量作,现实情况下我们要拟合的模型可能有相当多的特征分量,那么线性模型中对应的权重值θ也会有相同多的数量。为了方便表示我们使用矩阵和向量来表示这些数据:
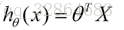
向量θ(长度为n)中每一个分量都是估计表达式函数h(x)中一个参数,矩阵X(m*n)表示由数据集中每一个样本的特征向量所组成的矩阵。其实这样一个看起来很简单的式子,它的本质经常就是一个规模极其庞大的线性方程组。如果我们用向量Y(长度为m)来表示数据集的实际值,如果用实际值来建立一个方程组,参数向量θ中的每一个值就是我们要求的未知量;大多数情况下建立的是一个超定方程组(没有确定的解),这个时候我们只能求出超定方程组的最优解。通过建立一个损失函数来衡量估计值和实际之间的误差的大小,我们将最小化损失函数作为一个约束条件来求出参数向量的最优解。
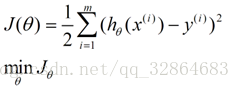
函数J(θ)即为损失函数,它计算出数据集中每一个样例的估计值和实际值的平方差并求取平均。然后就是我们的最小二乘法登场了,最小二乘法通过数学推导(后面给出证明)可以直接得到一个标准方程,这个标准方程的解就是最优的参数向量。
最小二乘法通过数学推导出标准方程的过程其实非常简单,知乎上有一篇博客https://zhuanlan.zhihu.com/p/22474562写得很详细,这里借鉴一下:
***********************************************************************************************
我们定义观测结果y和预测结果y'之间的差别为Rss(和上文提到的J(θ)是一个意思):
设若参数的矩阵为
,则
那么
按照我们的定义,这个Rss的意思是y和y'之间的差,那么当Rss无限趋近于0的时候,则y≈y',即我们求得的预测结果就等于实际结果。
于是,令Rss等于某一极小值
,则
对参数
展开,得
进而就可以得到
于是我们就得到正规方程了。
***********************************************************************************************
通过正规方程计算得到最优的参数向量之后,就可以确定线性回归方程了,预测只需要将特征向量代入到回归方程之中,就可以计算出估计值了。
既然弄清了原理,那么实现就会显得非常简单;考虑到这个算法过程中使用矩阵乘法的次数很多,所以我使用了python语言以及调用numpy库来实现线性回归的算法。
#coding=utf-8
import numpy as np
import copy
from sklearn.datasets import load_boston
class LinerRegression:
M_x=[]#
M_y=[]#
M_theta=[]#参数向量
trained=False
def __init__(self):
pass
def regression(self,data,target):
self.M_x = np.mat(data)
self.M_y = np.mat(target)
M_x_T =self.M_x.T#计算X矩阵的转置矩阵
self.M_theta = (M_x_T * self.M_x).I * M_x_T * self.M_y.I#通过最小二乘法计算出参数向量
self.trained=True
def predict(self,vec):
if not self.trained:
print "You haven't finished the regression!"
return
M_vec=np.mat(vec)
estimate=M_vec*self.M_theta
return estimate
if __name__ == '__main__':
#从sklearn的数据集中获取相关向量数据集data和房价数据集target
data,target=load_boston(return_X_y=True)
lr=LinerRegression()
lr.regression(data,target)
#随机提取几个样例观察一下拟合效果
test=data[::17]
M_test=np.mat(test)
print lr.predict(M_test)
real=target[::17]
print real