Резюме Внимание II:
Привлечение бумаги:
- Показать, Посещайте и сказать: Neural Image Caption поколение с визуальной Attentio (用 了 трудно \ мягкое внимание внимание)
- Эффективные подходы к Вниманию на основе нейронного машинного перевода (提出 了 глобальное \ локального внимания)
В данной статье Ссылка статьи:
Внимание - бис
было пять Внимание понять модель и ее применение
внимание модели подход Резюме
механизмов Внимание чтения --global внимание и внимание местного
, Ltd. Бесплатно Join Внимание / Local Внимание
Это резюме статьи
- внимание механизмы Основная идея
- Обобщить каждое внимание механизмы (жесткий \ мягкого \ Global \ локальное внимание)
- Другое внимание, связанное с
1 Внимание, по существу, идеологический механизм
Основная идея, см: эта статья , в этой статье также отметила , что само-внимание.
Короткий ответ, это внимание (запрос, ключ, значение) в машинный перевод ключ-значение является то же самое.
PS: Внимание NMT механизм в применении основной идеи см Обобщены: Attentin сводного
2 все виды внимания
Говоря о других внимании:
- трудно внимание
- мягкое внимание
- gloabal внимание
- местное внимание
- самостоятельно внимание: цель = источник -> Multi-голова внимание - (Внимание резюме разряда с)
2,1 трудно внимание
Бумага: Шоу, Посещайте и Скажите :. Neural Image Caption поколение с зрительным вниманием
Примечания Источника: Обзор модели подхода внимания
мягкое внимание , чтобы все компоненты взвешиваются, трудно внимание , является частью стратегии , выбранной составляющей. трудно внимание обеспокоенные части.
мягкое внимание к обучению после этого распространения.
трудно внимание的特点:
тяжелая модель внимания недифференцируема и требует более сложных методов , таких как уменьшение дисперсии или обучение с подкреплением на поезд
удельный
Модель датчика с помощью CNN (VGG сети), извлекает L-мерные векторы аи D изображения, I = 1,2, ... L, каждый вектор представляет собой часть информации об изображении.
декодер является LSTM, т временного шага на каждый вход состоит из трех частей: ZT, ХТ-1, уг -1. В котором ZT и А. И. получены из & alpha; Ti.
по & alpha; Ti внимание модели F АТТ рассчитывается.
F в данном Att представляет собой многослойный персептрон:
она может быть рассчитана ZT ,
где F Внимание Модель Att получения Есть два способа: стохастическое внимание и детерминированное внимание.
2.1.2 Стохастический «Hard» Внимание
й т это время фокус внимания номер позиции декодера, STI , указывающий внимание положение интереса в момент времени T I, STI, I = 1,2, ... L, [ST1, ST2, ... СТЛ] является одной горячей кодирование , индикатор внимания позиция время фокусировки на практике, является источником трудно .
Модель в соответствии с а = (а1, а2, ... Аl) генерирует последовательность у (у1, ..., уС) , с которой = {s1, s2, ... СБНО } является ключевой последовательностью фокуса на оси времени, теоретически L ^ C а.
PS: глубокое изучение мысль: исследование целевой функции, а затем изучить объективные параметры функции градиента.
Используется знаменитое неравенство Йенсена к целевой функции (разворачивания LogP (у | а)), целевая функция для выполнения преобразования (потому что нет никакого явного s), чтобы получить нижнюю границу целевой функции,
то LogP (у | а) вместо исходных объективных параметров функции градиента расчетной модели W, а затем методом Монте - Карло Отбор проб методы делают с.
Есть детали , участвующие в обучении с подкреплением.
2.1.3 Детерминированные «Soft» Внимание
Вся модель гладкая и дифференцируема (то есть целевая функция, которая является целевой функцией правого веса LSTM & alpha; Ti дифференцируема, причина очень проста, так как целевая функция ZT дифференцируема, и ZT из & alpha; Ti дифференцируема, по правилу цепи доступной & alpha; Ti целевая функция дифференцируема) в детерминированной внимания, поэтому изучение впритык тривиальна с помощью стандартного обратного распространения.
В жестком внимании внутри, последовательность каждого временная модели т [st1, ... СТЛА] занимает только 1, все остальное 0, время, которое является положением фокуса, и будет заботиться о каждом мягком внимании на все позиции, только правильный вес в разных местах различны. ZT представляет собой взвешенную сумму д.в.:
Штраф: ,
используется для настройки контекста вектора по отношению к LSTM HT-1 и удельный вес уг-1.
Процесс обучения 2.1.4
Два вида моделей внимания с использованием SGD (стохастический градиентный спуск) на поезд.
2.2 Глобальные / Локальные документы Внимание
论文: Эффективные подходы к Вниманию на основе нейронного машинного перевода
Эталонные Записки из:
Papers контекст вычисления векторов:
ч т -> а т -> с т -> ч ~ т
Global Внимание
глобальное внимание в контексте вычисления вектора каратов будет считаться, когда все скрытое состояние датчика генерируется.
Можно видеть, глобальное внимание в отношении Резюме Внимания Внимания похоже , но проще. Разница между ними, может относиться к этой статье , то есть на фиг Примечание:
])
Приглашение декодера целевого скрыто время т все скрытые состояний HT, кодер представляет собой Н ~ S , S = 1,2, ... n - . Это называется: внимани скрытом состоянии .
Для любого H ~ S , вес Т (S) , является переменным вектором выравнивания длины, длиной , равной длиной кодера части временного ряда. Путь сравнения текущего скрытого состояния слоя декодера Н Т и каждый из кодеров скрытого слоя STATUS Н ~ S , полученный:
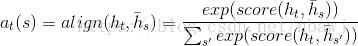
Т (S) представляет собой декодер , и состо ние кодера государственного сравнения полученного.
оценка является функцией на основе содержимого, бумага дает три различные методы расчета (статья называется функция выравнивания):
в которой: усеивают глобального внимания лучше, генерал местного внимания лучше.
Другой только Н Т бороздки все пути Т (S) интегрированы в весовой матрицы, чтобы получить Wa, может быть рассчитали Т :
Пару Т , чтобы сделать взвешенное среднее операции (Н ~ S взвешенного суммирования) может быть получен контекстом вектора С Т , и перейти к следующей стадии
Фигура процесс глобального внимания:

Местное Внимание
глобальное внимание при расчете состояния каждого декодер необходимости сосредоточиться на все входной датчик, в количестве , больший расчет.
местное внимание можно рассматривать как смесь твердого внимания и мягкого внимание (смешивания преимущества), из - за свою вычислительную сложность ниже , чем глобальное внимание, мягкое внимание, и отличаются от жесткого внимания, местное внимание дифференцируемо почти всюду, легко поддается дрессировке.
местное внимание сосредоточено на механизме избирательного контекста, в котором небольшое окно (фокус положение источника каждый раз, когда только небольшая часть), что позволяет уменьшить вычислительные затраты.
В этой модели, каждый из них является мишенью для модели времени т словарного генерирует первый выровненную позицию (в выровненном положении) P т .
Контекст вектор С Т кодером в состоянии заданного значения вычисленного скрытый слой, скрытый слой содержит кодер окна [Р Т Д, Р Т + D], размер D выбран эмпирический.
Эти модели С Т сформированы разные, как представлено ниже глобального размещения ВС .
Назад местное внимание, где P T является индексом положение источника, как будет понятно Внимание внимание как параметры модели. P T вычислили два расчетных программ:
- Монотонный alingnment (местные-м)
Набор Р Т = Т, предполагая , что последовательность источника и последовательность - мишень выравнены , по существу , монотонно, то выравнивание векторов А Т может быть определен как:
- Интеллектуальное выравнивание (локальный р)
Модель предсказывает положение выравнивания, вместо того , чтобы предполагать , что последовательность исходной и целевой выравнивание монотонной последовательности.
Вт р- и v р- параметров быть примерными , чтобы предсказать положение путем обучения. S длина исходного предложения, то этот расчет, Р Т ∈ [0, S].
Для поддержки р т точка выравнивания вблизи предусмотрен р вокруг т гауссово распределение, так что вес выравнивания αt (s) может быть выражена как:
здесь та же функция выравнивания и глобальная в функции выравнивания, можно видеть из центра пта дополнительного удаленность, его источник скрыт состояние в положении , соответствующем весов будет сжиматься до более тяжелой.

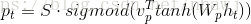
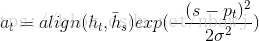
Получено С Т ч вычисляется после ~ T метода, с помощью контекста соединительного слоя вектора С Т и Н Т , интегрированной в час ~ Т :
ч ~ Т = TANH (Wc из [С Т ; ч Т ])
ч ~ Т является внимание вектор, вероятность того, что предсказанный выходной вектор , порожденный следующее распределение формулы слова:
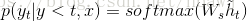
Фигура местный процесс внимания:

2.2.1 Глобальная против местного Attention
Таким образом, глобальное / локальное различие заключается в следующем:
- Бывший вектор Расстановка Т размер переменной, в зависимости от части датчика длины входной последовательности;
- Вектор , который контекст Т размер фиксирован, А Т ∈R 2D + 1. ;
Global Внимание и местные Внимание преимущества и недостатки, практика Global с немного больше, потому что:
- Местное внимание, когда датчик не долго, количество вычислений и не снижает
- вектор положения Р Т предсказание не очень точно, непосредственно влияет на точность местного Внимания
2.2.2 Подход ввода кормления
inputfeeding подхода: вниманите векторы ч ~ т подаются в качестве входных данных для последующих шагов по времени, чтобы сообщить о модели прошлых решений выравнивания. Эффект этого двояка:
- сделать модель полностью осведомлены о предыдущем выборе выравнивания
- мы создаем очень глубокую сеть, охватывающую как по горизонтали, так и по вертикали
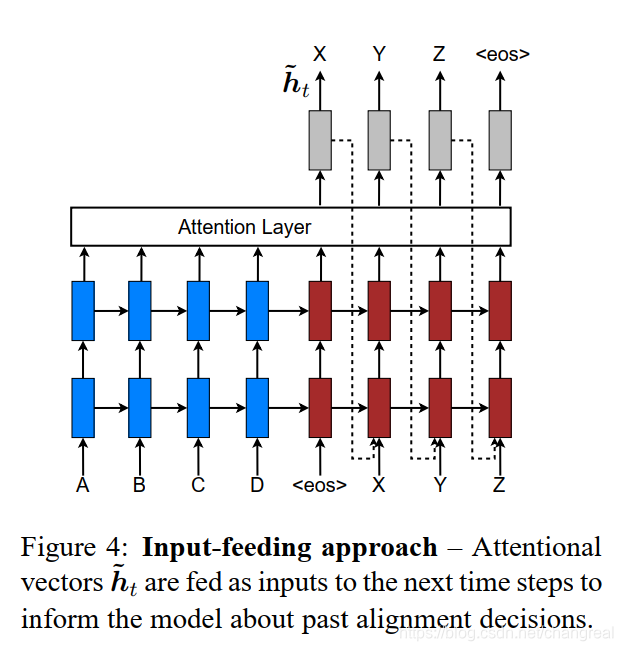
2.2.3 В настоящем документе кратко технической точки использования:
- Global \ местное внимание,
- Подход ввода вскармливание
- лучше функции выравнивания
2.2.4 Советы по реализации бумаги
Реализация времени , необходимого для концепций и методов:
прогрессивных слоев , таких как модели первого на основе, а затем + обратный + отсев, + глобальное внимание + подача входного сигнала + UNK заменить, а затем посмотреть на степень оценки улучшения.
обратное реверс исходного предложения,
вышеприведенные известные методы, такие , как на: Источник реверса , отсев , unknowed Замена Technique .
путем интеграции различных параметров, таких как 8 различных моделей, таких как внимание , используя различные методы, без использования отсева
Словарь размера, например, принимая каждый язык верхнего 50k,
неизвестное слово , используемое <unk>вместо
предложения для заполнения, LSTM слоев, например, в начальных проектных параметрах [-0.1, 0.1] в диапазоне, нормализованный градиент перемасштабирован всякий раз , когда его норма превышает 5.
Методы обучения: синг
разработан гиперпараметры:
LSTM слои, такие как количество единиц каждого 100cells, сколько измерений слов вложения, номер эпохи, мини-размер партии, такие как 128,
скорость обучения может быть изменена, например, в начале 1 , 5pochs каждой последующей эпохи после уменьшения вдвое отсева , таких как 0,2,
а также отсев начала 12pochs, после того, как 8epochs вдвое сократить скорость обучения
Экспериментальный анализ:
- Смотри снизился кривой обучения
- Эффекты длинных предложений
- внимани архитектуры
- выравнивание качества
3 другие
Дизайн 3.1 Внимание
-
на основе определения местоположения внимания
Расположение основе, что означает , что внимание здесь нет других дополнительных объектов интереса, а именно внимание вектор привет сам.
си = е (привет) = активация (WTHI + Ь) -
всеобщее внимание (не часто)
-
конкатенации на основе внимания
Concatenation основе смысл, внимание здесь просто больше внимания на другие объекты.
И е , который предназначен для измерения корреляционной функции между приветом и ХТАМИ.
си = е (привет, ХТ) = vTactivation (W1hi + W2ht + Ь)
Расширение 3,2 Внимания
К2 предложение документа, каждое предложение по k1 (k1 размеров каждого предложения) состоит из слова.
Первый слой: слово-уровень внимания
имеет k1k1 слово для каждого предложения, соответствующие векторы имеют k1k1 Wiwi, используя второй главы упомянутого способ, в результате чего в векторе экспрессии для каждого предложения, обозначаемых stisti.
Второй слой: предложение уровня внимания
вниманием первого слоя, мы можем получить k2k2 stisti, повторное использование способ второй главе уже упоминалось, в результате чего в векторе экспрессии Диди каждый документ, конечно, вы можете получить каждый stisti веса , соответствующие веса αiαi, а затем получить их, анализировать конкретную задачу.
