Предпосылки применения:
Естественный язык , имеющий временные характеристики, и , следовательно , естественный язык может быть обработан с помощью нейронной сети цикла. Естественный язык слово, предложения, статьи, эти языковые элементы , как единое целое. Python наиболее часто используемых word2vec инструментов может конвертировать слова в вектор, чтобы преобразовать слова в преимуществах векторов являются следующие два:
(1) слово в квантуется, цифровой обработки, таким образом , непосредственно вычисленной нейронной сети;
(2 ) , используя рассчитанное расстояние между векторами, которые могут вычислить расстояние между разными словами, такими , что соотношение между разными словами можно представить вектор расстояния.
Напоминание:
Перед тренировкой необходимо установить модуль gensim следующим утверждением:
pip install gensim
В этом примере следующий код:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import gensim
sentences = [['this', 'is', 'a', 'hot', 'pie'], ['this', 'is', 'a', 'cool', 'pie'],
['this', 'is', 'a', 'red', 'pie'], ['this', 'is', 'not', 'a', 'hot', 'pie']]
model = gensim.models.Word2Vec(sentences, min_count=1)
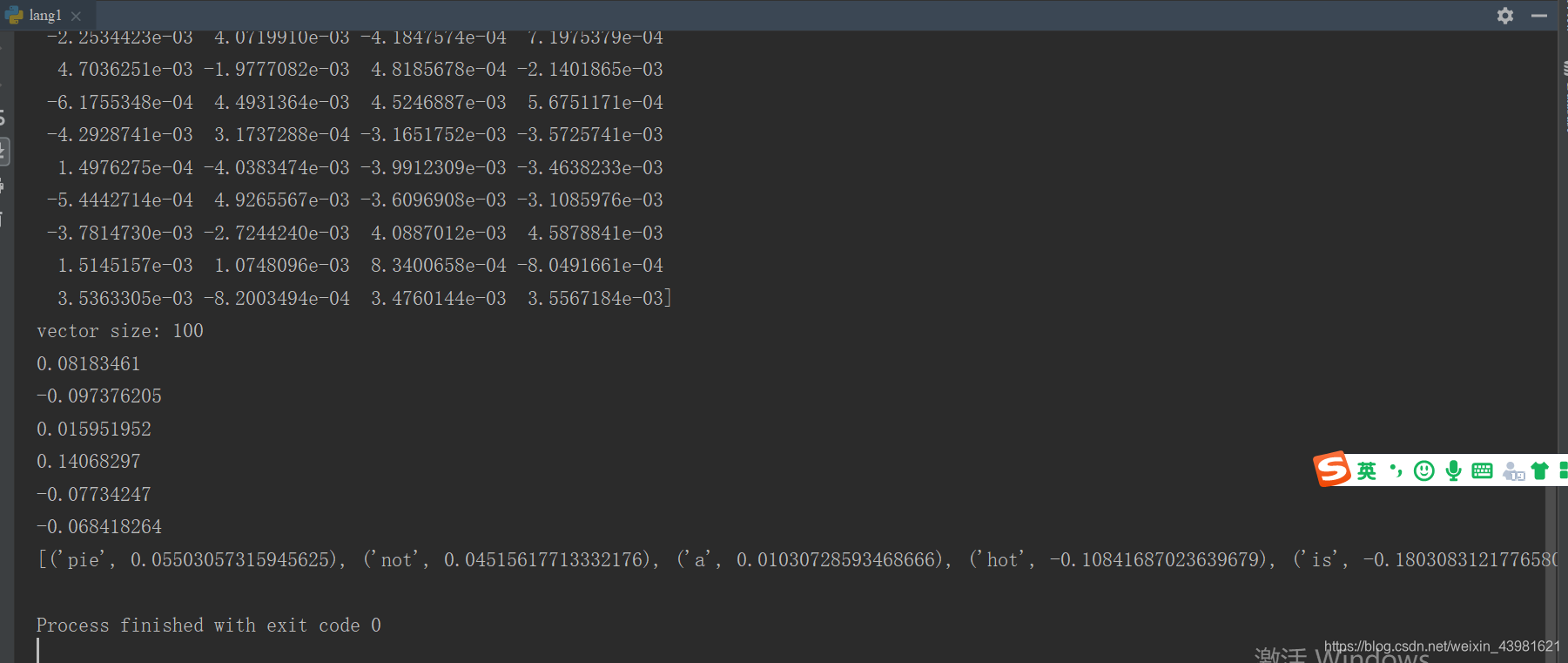
print(model.wv['this'])
print(model.wv['is'])
print('vector size:', len(model.wv['is']))
print(model.wv.similarity('this', 'is'))
print(model.wv.similarity('this', 'not'))
print(model.wv.similarity('this', 'a'))
print(model.wv.similarity('this', 'hot'))
print(model.wv.similarity('this', 'cool'))
print(model.wv.similarity('this', 'pie'))
print(model.wv.most_similar(positive=['cool', 'red'], negative=['this']))
Код Описание:
(1) предложения являются обучающие данные в настоящем варианте осуществления, это 4 слова, и в соответствии со всеми строчными буквами, каждого формата слова , состоящего из отдельного двумерного массива;
(2) = gensim.models.Word2Vec Модель (Приговоры, min_count = параметр официального объяснения min_count 1): игнорирует все слова с общей частотой ниже , чем это, он должен учитывать влияние количества слов меньше , чем происходит min_count выключено;
(3) Печать (model.wv [ «это»]) выходов «это». слово вектор, вектор 100 цифр;
печати (model.wv.similarity ( 'это', 'есть')) выходное слово 'это' и значение 'есть' подобие (4.);
(5) . Печать (model.wv.most_similar (положительные = [ «круто », «красный»], отрицательный = [ «это»])), most_similar извлекает указанное слово в этой модели наиболее близки слова, в котором положительный представляет указанные потребности , чтобы найти близко слово слово, отрицательное его сходство указать , что вы хотите , слово далеко.
Результаты таковы: