каталог
[Это ссылка на 4000 + статье. Хотя блогеры не делают NLP, но все равно очень интересно. Конечно, блоггеры понимание и перевод этой статьи очень отрывисто]
Мотивация : механизм внимания очень важен, NLP модель теперь СОТ будет соединена друг с другом посредством механизмов сосредоточения внимания кодера и декодера.
Вклад : В данной работе авторы предложили преобразователь (трансформатор). Эта структура не имеет ничего общего с циркуляцией и свертка сети, только с механизмами внимания. В целом модель обучения быстрее и проще параллельно, лучшие результаты.
Мотивация подробнее
Текущий цикл логическая сеть и логика описана в организме человека, являются последовательности: С операцией заранее начинаетс позиция символа, т.е. \ (Т \) Время неявного состоянием \ (h_t \) находится на время неявное состояние \ (H_ {т-1} \) и функция времени текущего входа.
Однако, эта логическая последовательность имеет недостаток: не способствует распараллеливания. Особенно когда длинная последовательность, этот недостаток усиливается.
В этом случае механизм внимания на автор этого видение. Вниманите механизмы уже являются неотъемлемой частью многих задач моделирования последовательности и преобразование модели (трансдукция) может быть использован для моделирования никаких зависимостей на больших расстояния . Тем не менее, этот механизм является сеть внимания и рециркуляции используется одновременно .
Предлагаемый конвертер, внимание, чтобы сделать модели из сети петли рамы. В это время, он имеет возможности параллельных преобразователей.
2. Связанные работы
Там некоторая работа в попытке уменьшить количество вычислительной последовательности, и такие ByteNet ConvS2S. Все они подкреплены свертка нейронной сетью. Их общая проблема: Когда длина увеличивается последовательности, количество вычислений линейного или логарифмического роста будет увеличиваться.
Преобразователь может сделать: Пусть объем вычислений является фиксированной постоянной, хотя некоторые потери производительности.
Так как механизмы сосредоточения внимания: в пределах одной последовательности, создание механизмов между сосредоточением внимания различными позициями, и для моделирования самой последовательности.
[Конец Воспоминания: блоггеры не понимают, не узнать. ]
Авторы утверждают, первый преобразователь основан исключительно на механизме внимания от модели преобразования, без RNN или структуры свертки.
3. Преобразователь структура
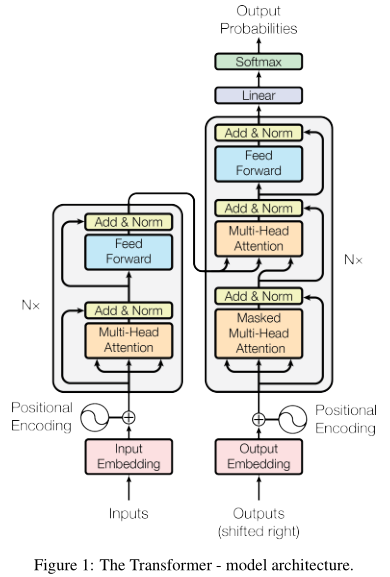
Левые кодер, право декодер.
(Как показано на левой стороне, такую же конфигурацию , как кодер 6 . \ (N = 6 \) ), каждая структура , содержащая два слоя: один слой длиной механизмы ( к вниманию оранжевые), полностью подключенный сетевой уровень (синий ). Есть два коротких соединения внутреннего слоя и нормализованы. Все слои выводятся \ (D_k = 512 \) измерение.
Правая сторона представляет собой декодер. Декодер также одной и той же структуры 6 состава, но структура каждого из множества длинных механизмов (к вниманию середине). Этот модуль выполняется на выходе кодера. Кроме того, в нижней части этого долго внимания модуль также был изменен: только выход из механизма внимания для выполнения перед, независимо от его выхода после. Изменить способ маскируется.
3,1 Подробное механизм внимания
Внимание механизм по существу, достаточно прост: входной запрос и набор ключей - пар значений; выходное значение является взвешенной комбинацией; функция вычисления веса, полученная в результате выполнения запроса и совместимой связью.
3.1.1 Масштабирование продукта точечного механизма внимания
Авторы говорят, что предложенный механизм для сведения: масштабирование скалярного произведения внимания (масштабируются внимание скалярного произведения). Рисунок слева:
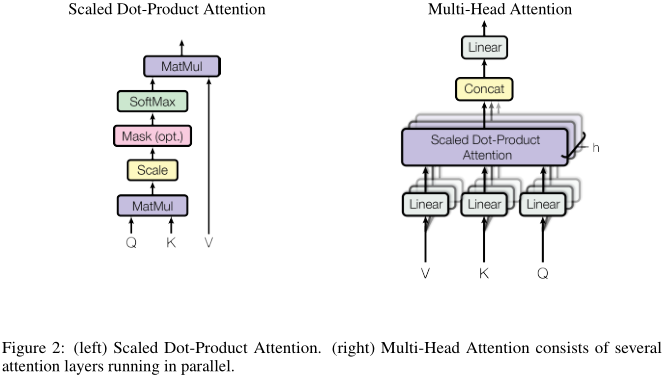
запросы и точка ключа, деленный на квадратном корне из 512 (масштабирования), и после того, как SoftMax значения, умноженного на процессе взвешивания является полным вниманием.
В практической работе этого процесса будет матрицирование, т.е. первый блок матрицы \ (Q \) , \ (К \) и \ (V \) , затем вычисляет:
\ [\ текст по Внимание} {(Q, K, V) , = \ {текст SoftMax} (\ гидроразрыва {QK ^ Т} {\ SQRT {D_k}}) V \]
除了这里用到的点积形式,还有一种常用的注意力策略:加性注意力。加性注意力(additive attention)只需要借助单层前向网络计算兼容函数。尽管理论上,加性注意力和点积注意力的计算复杂度接近,但由于矩阵操作有加速算法,因此点积注意力更高效。在性能上,当\(d_k\)较大时,点积注意力不如加性注意力。可能的原因是:当维度较高时,点积结果可能会很大(脚注4),因此softmax函数的梯度很小,导致训练困难。因此,我们将点积结果除以根号512。
3.1.2 多头注意力机制
我们总结一下上一节的放缩点积注意力机制:只有单个注意力函数,输入key和query,输出加权后的value。注意,输入、输出都是\(d_k = 512\)维。
除此之外,作者提出了更进一步的处理,如上图右:我们首先将value、query和key分别线性映射到\(d_k = 64\)、\(d_k\)和\(d_v = 64\)维,然后再通过上一节的注意力机制,处理得到\(d_v\)维的输出。该操作执行\(h = 8\)次,每一次的线性映射函数和注意力函数都不一样。最后,\(h\)个\(d_v\)维输出再经过一次线性映射,得到一个\(d_v\)维最终输出。这就是所谓的multi-head。
多头与之前的“单头”有什么进步呢?博主的想法:
Не только ключ, запрос комплексного лечения, а также ключ, обработка запросов и значение отдельно. Там могут быть некоторые ключевые и запрос по своей сути очень интересно.
Они совершили восемь различных «одна голова», а затем окончательный результат reweighted каждую комбинацию. Этот факт позволяет каждой функция фокусировки отвечает за восемь различных представления пространства. Например, некоторые функции больше внимания к этой теме, глагол, и поэтому обращать больше внимания на какую-либо функцию.
Поскольку каждые размеры «с одной головкой» уменьшается, общий объем вычислений не улучшилось.
Возвращаясь к первой диаграмме. В трансформаторе, автор использовал в три длительного внимания:
Кодер - между декодером. запрос от слоя декодера, ключа и вывода значений от кодера. Т.е .: Обратите внимание, что декодер, так что положение каждого из входной последовательности. Это характерно для механизма внимания.
Кодер. В это время, ключ, значение, и являются производными от одного запроса. То есть: внимание слоя на слой каждого места.
Декодер. В это время, ключ, значение, и являются производными от одного запроса. То есть: внимание слоя на слой каждого места. Обратите внимание, что мы не должны левонаправленный поток информации, таким образом мы позволяем соответствующая маска отрицательная бесконечность (никакого отношения).
3,2 полностью подключена сеть
Полностью подключенная сеть включает в себя две карты, Relu нелинейными. Вход и выход 512-мерного размер скрытого слоя 2048.
Вложениях не знаю, не читал.
3.3 кодированная информация о положении
Так как трансформатор свертка не содержит циклическую структуру, и, в частности, поэтому мы хотим, чтобы информация о положении закодировать. немного детали.
Немного отдохнуть.
В общем, Google нарушая присущую оригинальную модель: моделирующий внимание с RNN или CNN. Этот прорыв является самым большим вкладом этой статьи.