1. Регистрация Китайского университета Mooc
2. Выберите Пекинский технологический институт песни день учителя «Python веб гусеничном и извлечение информации» Mooc курсы
3. Научитесь завершить первый 0 недельный курс четырех недель, каждую неделю и закончить работу
4. Обеспечить изображения или веб-сайты показывают прогресс в обучении, чтобы доказать процесс обучения.

5. Написать менее 1000 слов отмечает исследование, говорить об опыте обучения и достижения.
Исследование отмечает и урожай
Первая неделя: просит библиотеку
Библиотека по установке 1.requests: PIP просит установить
установлена 2. Библиотеки запросов Тестов: Импорт запросы
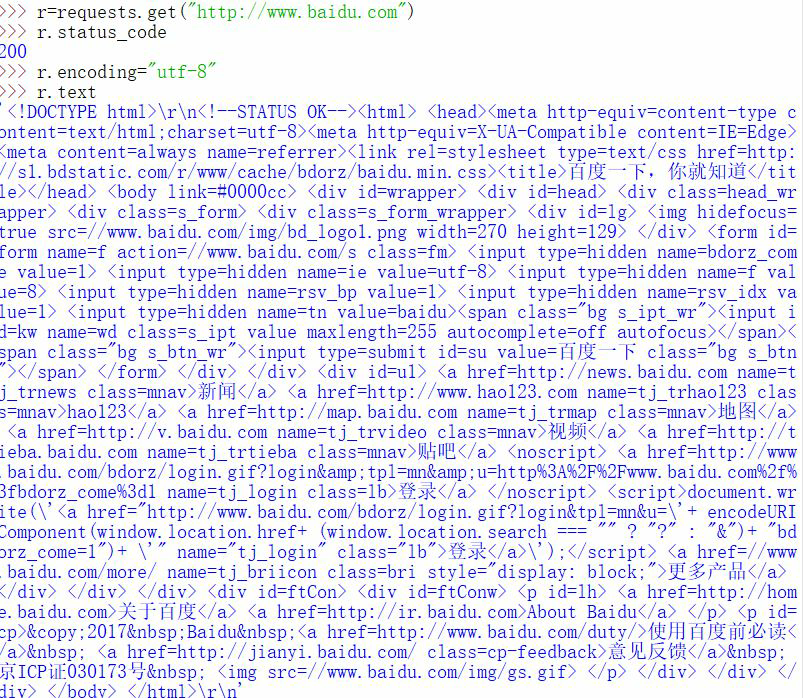
R & л requests.get = ( «http://www.baidu.com»)
код состояния r.status_code
200 для доступа к успеху
r.encoding = 'UTF - 8 . '
r.text
3. Операция экрана ползать Baidu страницы:
Семь основной метод 4.requests библиотеки
requests.request (): создать запрос
requests.get (): Основной метод для получения веб-страниц
requests.head (): Получает информацию заголовка страницы
requests.post (): метод после подавать запросы в Интернете
requests.put (): метод представления поставить запрос на веб-странице
requests.patch (): частичный запрос модификации для представления страницы
requests.delete (): Удалить отправить запрос на веб - страницу
второй недели: красивый суп
1.beautiful установка суп: Пип установить beautifulsoup4
2.beautiful библиотека супа разрешена, траверс, обслуживание «тег дерево» функция библиотека.
3.beautiful суп библиотека парсер html.parser, LXML, XML, html5lib
--- конец --- восстановить содержимое
1. Регистрация Китайского университета Mooc
2. Выберите Пекинский технологический институт песни день учителя «Python веб гусеничном и извлечение информации» Mooc курсы
3. Научитесь завершить первый 0 недельный курс четырех недель, каждую неделю и закончить работу
4. Обеспечить изображения или веб-сайты показывают прогресс в обучении, чтобы доказать процесс обучения.
5. Написать менее 1000 слов отмечает исследование, говорить об опыте обучения и достижения.
Исследование отмечает и урожай
Первая неделя: просит библиотеку
Библиотека по установке 1.requests: PIP просит установить
установлена 2. Библиотеки запросов Тестов: Импорт запросы
R & л requests.get = ( «http://www.baidu.com»)
код состояния r.status_code
200 для доступа к успеху
r.encoding = 'UTF - 8 . '
r.text
3. Операция экрана ползать Baidu страницы:
Семь основной метод 4.requests библиотеки
requests.request():创造一个请求
requests.get():获取网页的主要方法
requests.head():获取网页头信息
requests.post():向网页提交post请求的方法
requests.put():向网页提交put请求的方法
requests.patch():向网页提交局部修改请求
requests.delete():向网页提交删除请求
第二周:beautiful soup
1.beautiful soup的安装:pip install beautifulsoup4
2.beautiful soup库是解析、遍历、维护“标签树”的功能库。
3.beautiful soup库解析器有html.parser、lxml、xml、html5lib
第三周:re正则表达式
1.正则表达式常用操作符:*表示前一个字符0次或无限次扩展,例如:abc*为ab、abc、abcc、abccc...
+表示前一个字符1次或无限次扩展,例如:abc+为abc、abcc、abccc...
?表示前一个字符0次或1次扩展,例如:abc?为ab、abc
{m}表示扩展前一个字符m次,例如ab{2}c为abbc
{m,n}表示扩展前一个字符m到n次,例如ab{1,3}c为abc、abbc、abbbc
2.re的主要功能函数
re.search():在一个字符串中搜索匹配正则表达式的第一个位置,返回match对象
re.match():在一个字符串的开始位置起匹配正则表达式,返回match对象
re.findall():搜索字符串
re.split():将一个字符串按照正则表达式匹配结果进行分割,返回列表类型
re.finditer():搜索字符串,返回匹配结果的迭代类型
re.sub():在一个字符串中替换所有匹配正则表达式的子串,返回替换后的字符串
第四周:scrapy爬虫框架
1.Engine:控制所有模块之间的数据流
2.Downloader:根据请求下载网页
3.Scheduler:对所有爬取请求进行调度管理
4.Downloader Middleware实施Engine、Scheduler和Downloader之间进行用户可配置的控制
5.Spider解析Downloader返回的响应
6.Item Pipelines的操作包括:清理、检查和查重爬取项中的HTML数据、将数据存储到数据库
7.Scrapy的常用命令:startproject:创建一个新工程
genspider:创建一个爬虫
settings:获得爬虫配置信息
crawl:运行一个爬虫
收获
通过学习嵩天老师的《Python网络爬虫与信息提取》,对爬虫知识有了部分了解。网络爬虫又被称为网页蜘蛛,是一种按照一定的规则,自动的抓取信息的程序或者脚本。爬虫技术是通过链接地址来寻找网页。通过这几天的学习,也体会到爬虫技术的有趣之处,但是要掌握这门技术,还是需要花很多心思去学习。在平台学习的过程中,也发现资源的广泛性,只要想学习,就可以从平台上寻找到各种有用的课程,通过学习课程,掌握知识。要学会好好利用这些宝贵的资源。