1.1 HDFS генерируется фон
С увеличением объемом данных, хранящимся в операционной системе не меньше, чем все данных, затем распространяются на более управления дисковой операционной системы, но не удобно управлять и поддерживать, настоятельную потребность в систему для управления нескольких машин файлы, который является распределенным управлением файловой системы. HDFS распределенной системы управления файлами только в одном.
1.2 Определение HDFS
HDFS (Hadoop Distributed File System), которая является файловой системой для хранения файлов, чтобы найти файлы в дереве каталогов, во-вторых, он распространяется на многие серверы работают вместе, чтобы достичь своей функциональности серверов в кластере имеют свои собственные роль.
HDFS сценариев использования: подходит для однократной записи, читали многие из сцен, и не поддерживает изменяющие файлы. Подходит для проведения анализа данных, не подходит для сетевых приложений.
2. HDFS преимущества и недостатки
2.1 Преимущества:
1) Высокая отказоустойчивость
(1) множественные копии данных автоматически сохраняются, что при увеличении копии шаблона данных, улучшении отказоустойчивости


(2) копию данных после потери, он может автоматически восстановить


(1) Шкала данных: в состоянии обрабатывать масштаб достиг ГБ, ТБ, даже больше уровня данных РВ;
3) может быть построены в недорогой машине, с помощью нескольких копий повышенной надежности.
2.2 недостатки
1) не подходит для низкого задержка доступа к данным;
2) не может быть эффективным для большого количества маленьких файлов сохраняются:
(1) хранение большого количества маленьких файлов, то он будет принимать информацию каталога NameNode и блокировать много памяти для хранения файлов;
(2) хранения мелких файлов адресации больше, чем время чтения, в нарушение целей проекта HDFS.
3) не поддерживает одновременную запись, изменять файлы в случайном порядке
(1) файл может иметь только один запись, не позволяет несколько потоков писать;
(2) поддерживает только добавление данных (дополнительный), не поддерживает случайную модификацию файлов


3. Архитектура HDFS, состоящая из
3.1 Общая структура выглядит следующим образом:
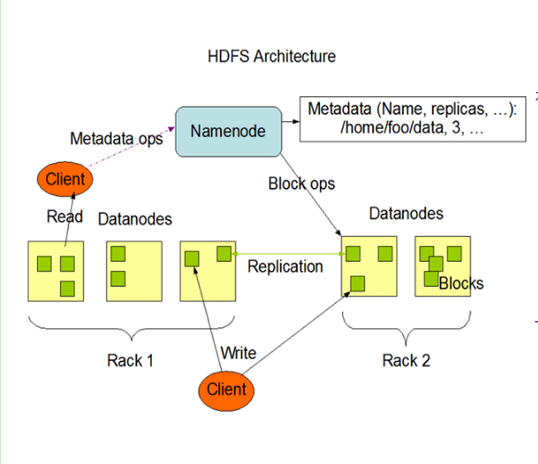

3,2 HDFS архитектура Детальнее
1) NameNode (аббревиатура: ND): это мастер, он является исполнительным, ответственным за управление информацией HDFS:
(1) Управление HDFS пространства имен;
(2) копия стратегии управления;
(3) блок управления (блок) отображение информации;
(4) обработки на стороне клиента читать и писать запросы.
2)DataNode(简称:DN):就是slave,NameNode下达指令,DataNode执行实际的操作:
(1)存储实际的数据块;
(2)执行数据块的读/写操作。
3)Client:客户端,与NameNode交互的程序,职责或功能如下:
(1)文件切分:在上传文件至HDFS的时候,Client会将文件分切成一个个的Block上传;
(2)与NameNode交互,可以获取文件的位置信息(存在哪个节点上)
(3)Client可以通过一些命令来访问HDFS,比如增删改查操作;
(4)Client通过一些命令来管理HDFS,比如将NameNode格式化。
4)SecondaryNameNode:并非是NameNode的热备。当NameNode挂掉的时候,它并不会立即替换NameNode并提供服务。
(1)辅助NameNode,分担其工作量,比如定期合并FsImage和Edits(后边会讲到,这里不用理解),并将合并后的FsImage.checkPoint推送给NameNode;
(2)在紧急情况下可以辅助恢复NameNode。
4 HDFS的文件块大小
1)HDFS中的文件在物理上是按照块(Block)存储的,块id大小可以通过配置参数(dfs.blocksize)来规定,默认大小在Hadoop2.x的版本中是128M,老版本的是64M。
2)块的大小设定:文件的寻址时间应为块文件的传输时间的1%,这是比较合理的设定。
3)思考:为什么块的大小不能设置太小,也不能设置太大?
(1)HDFS的块如果设置的太小,会增加寻址时间,程序长时间在寻找块的存储位置;
(2)如果设置太大,从磁盘传输的时间会明显大于定位这个块的起始位置所需的时间。导致在处理这个块的数据时,浪费了大量的时间在IO上。
因此,块的大小可以根据数据量和磁盘的IO速度决定如何设置。