Структуры данных и алгоритмы (Python)
Почему?
Мы не можем дать хороший пример:
Если программа работает в финале написал сравнивал поле боя, наш код команды общего хозяйства, и мы написали код солдаты и оружие.
Так что структуры данных и алгоритмы? Ответ: искусство войны!
Мы не можем видеть искусство войны боя на поле боя, так что, может выиграть, может потерпеть неудачу. Даже победа может также заплатить высокую цену. Мы пишем программу Versa: не читают структуры данных и алгоритмы, иногда сталкиваются с проблемой не может иметь какие-либо идеи, я не знаю, как начать решать, большую часть времени может решить проблему, но программа не работает эффективность и экономичность сознание, производительность низкий, иногда помощь инструмент, разработанный другими, чтобы решить эту проблему временно, но узкие места производительности столкнуться, когда они не знают, как целенаправленную оптимизацию.
Если мы часто смотрим на искусстве войны, вы можете сделать это с уверенностью, иногда больше с меньшими затратами! Точно так же, если мы часто смотрим на алгоритмы и структуры данных, мы можем написать программу с легкостью, прозорливый, проникая также может столкнуться с проблемами решаемые.
Таким образом, структуры данных и алгоритмы является одним из важнейших основных навыков разработчик программы, не быстро исправить, чтобы преуспеть несравненный мастер. Рим был построен не за один день, мы обычно должны продолжать брать на себя инициативу, чтобы научиться накапливать.
3-дневное исследование, мы надеемся, так что мы можем понять концепции, понять обычно используемые структуры данных и алгоритмы.
Введенный
Первый взгляд на вопрос:
Если а + B + C = 1000, а ^ 2 + B ^ 2 = с ^ 2 (а, б, в это натуральное число), как получить все из A, B, C возможных комбинаций?
1.1 Первая попытка
1 импорта раз 2 3 start_time = time.time () 4 5 # 注意是三重循环 6 для в диапазоне (0, 1001 ): 7 для б в диапазоне (0, 1001 ): 8 для C в диапазоне (0, 1001 ): 9 , если а ** 2 + B ** 2 == с ** 2 и а + B + C == 1000 : 10 печати ( " а, б, в:% d,% d,% d " % ( а, б, в)) 11 12 END_TIME =time.time () 13 печать ( " истекшее:% е " % (end_time - start_time)) 14 печать ( " завершена! " )
Результат:
а, б, в: 0, 500, 500 а, б, в: 200, 375, 425 а, б, в: 375, 200, 425 а, б, в: 500, 0, 500 , прошедшее: 214,583347 полная!
1.2 Предлагаемый алгоритм
Понятие алгоритма
Является ли сущность компьютерных алгоритмов обработки информации, так как компьютерная программа, по существу, алгоритм, который говорит компьютеру точных шагов для выполнения указанной задачи. В общем случае, когда информация алгоритма обработки, считывает данные из запоминающего устройства или входных данных адреса, записывает результат в устройство вывода или адрес памяти для последующего вызова.
Алгоритм не зависит от присутствия на решении проблем методов и идей.
Для алгоритма, язык не важен, важна идея.
Алгоритм может иметь другой язык, чтобы описать вариант реализации (описанный в описании C, C ++, Python, описания и т.д.), мы теперь понимаем, описаны на языке Python.
Пять характеристик алгоритма
- Входной сигнал: 0 или алгоритм, имеющий множество входов
- Выход: алгоритм выводит, по меньшей мере один или несколько из
- Конечный: алгоритм после этапа автоматического ограниченного бесконечного цикла без концов, и каждый шаг могут быть завершены в течение приемлемого времени
- Неопределенность: Алгоритмы Каждый шаг имеет определенный смысл, не представляется неоднозначным
- Осуществимость: Каждый шаг алгоритма осуществим, что означает, что каждый шаг можно выполнить ограниченное число казней
1,3 вторая попытка
1 импорта раз 2 3 start_time = time.time () 4 5 # 注意是两重循环 6 для в диапазоне (0, 1001 ): 7 для б в диапазоне (0, 1001 ): 8 с = 1000 - а - Ь 9 , если а ** 2 + B ** 2 == с ** 2 : 10 печати ( " а, б, в:% d,% d,% d " % (а, б, в)) 11 12 END_TIME = time.time () 13 печать ( "истекшее:% е " % (end_time - start_time)) 14 печать ( " завершена! " )
Результат:
а, б, в: 0, 500, 500 а, б, в: 200, 375, 425 а, б, в: 375, 200, 425 а, б, в: 500, 0, 500 , прошедшее: 0,182897 полная!
Примечание Run время: 0.182897 секунд
мера эффективности алгоритма 1.4
Эффективность реакции времени выполнения алгоритма
Для одной и той же задачи, приведем два решения алгоритмы, в реализации двух алгоритмов, мы время выполнения программы были оценены время обнаружены значительные различия между этими двумя программами , которые будут выполнены (214.583347 секунд по сравнению с 0.182897 секунд), Отсюда можно сделать вывод: программа алгоритма время выполнения может отражать эффективность алгоритма, достоинство этого алгоритма.
Время в одиночку абсолютное значение доверия?
Будем считать, что вторая попытка алгоритма работает в низкой производительности машины со старыми компьютерами, ситуация будет? Это, скорее всего, не хватит времени, а не метод 214.583347 секунд, чтобы работать намного быстрее, чем наши компьютеры.
Опираясь исключительно на время работы алгоритма, чтобы сравнить плюсы и минусы не обязательно являются объективными и точными!
Компьютерная программа работает неотделимо от окружающей среды (в том числе оборудования и операционной системы), эти объективные причины могут повлиять на скорости бега и реакцию на время выполнения программы. Так как объективно судить достоинство алгоритма делать?
Трудоемкость и «большое обозначение O»
Мы предполагаем, что каждый раз, когда компьютерный алгоритм для выполнения основных операций в единице времени фиксирован, то число основных операций от имени блока займет много времени. Тем не менее, операторы машин для различных сред, точное время устройства отличается, но основные операции для ряда алгоритмов (т.е. сколько единиц времени, потраченных) в размере такие же порядок величины, таким образом, воздействие на окружающую среду незначительна машина целью эффективности времени реакции алгоритма.
Для эффективности использования времени работы алгоритма, можно использовать «большое обозначение O», чтобы представить.
«Big O обозначение»: целое число монотонная функция F, функция д, если существует целое число, а вещественные постоянные с> 0, так что при достаточно больших п всегда есть F (п) <= C * г (п), говорит функция Р и является асимптотической функция (игнорируя константу), обозначается как F (п) = о (г (п)). Другими словами, стремится к бесконечности предела значимости, скорость роста функции ф при условии г функции, которые функционируют аналогичны характеристикам г функции F.
Время Сложность: предполагая наличие функции г, алгоритм таких, что емкость лечения проблемы с образцом п времени Т (п) = О (г (п)), называемым O (г (п)) алгоритма асимптотический является временная сложность, временная сложность для краткости, называется Т (п)
Как понять «большое обозначение O»
Несмотря на то, хорошо, но ограниченное практическое значение , на практике очень конкретные и подробные алгоритмы анализа. Для пространства природы времени и характера алгоритма, наиболее важным является его величина и тенденции, которая является основной частью анализа эффективности алгоритма. Количество основных операций арифметического масштаба функции дозирующей , что постоянный множитель можно пренебречь. Например, считается , 3N 2 и 100N 2 принадлежат одному и тому же порядку величины, если обработка алгоритма стоят два экземпляра одного и того же размера эти две функции, я думаю , что их эффективность «почти», являются n- 2 стадии.
Худшее Трудоемкость
Алгоритмы анализа, есть несколько возможностей, чтобы рассмотреть следующие вопросы:
- Алгоритм для завершения работы требуется минимальное количество базовых операций, что является оптимальной Трудоемкость
- Сколько основные арифметические операции занимают работу, что худшее время сложность
- Сколько основных арифметические операции для завершения работы в среднем, что в средней сложности времени
对于最优时间复杂度,其价值不大,因为它没有提供什么有用信息,其反映的只是最乐观最理想的情况,没有参考价值。
对于最坏时间复杂度,提供了一种保证,表明算法在此种程度的基本操作中一定能完成工作。
对于平均时间复杂度,是对算法的一个全面评价,因此它完整全面的反映了这个算法的性质。但另一方面,这种衡量并没有保证,不是每个计算都能在这个基本操作内完成。而且,对于平均情况的计算,也会因为应用算法的实例分布可能并不均匀而难以计算。
因此,我们主要关注算法的最坏情况,亦即最坏时间复杂度。
时间复杂度的几条基本计算规则
- 基本操作,即只有常数项,认为其时间复杂度为O(1)
- 顺序结构,时间复杂度按加法进行计算
- 循环结构,时间复杂度按乘法进行计算
- 分支结构,时间复杂度取最大值
- 判断一个算法的效率时,往往只需要关注操作数量的最高次项,其它次要项和常数项可以忽略
- 在没有特殊说明时,我们所分析的算法的时间复杂度都是指最坏时间复杂度
1.5 算法分析
1.第一次尝试的算法核心部分
for a in range(0, 1001): for b in range(0, 1001): for c in range(0, 1001): if a**2 + b**2 == c**2 and a+b+c == 1000: print("a, b, c: %d, %d, %d" % (a, b, c))
时间复杂度:
T(n) = O(n*n*n) = O(n3)
2.第二次尝试的算法核心部分
for a in range(0, 1001): for b in range(0, 1001-a): c = 1000 - a - b if a**2 + b**2 == c**2: print("a, b, c: %d, %d, %d" % (a, b, c))
时间复杂度:
T(n) = O(n*n*(1+1)) = O(n*n) = O(n2)
由此可见,我们尝试的第二种算法要比第一种算法的时间复杂度好多的。
1.6 常见时间复杂度
| 执行次数函数举例 | 阶 | 非正式术语 |
| 12 | O(1) | 常数阶 |
| 2n+3 | O(n) | 线性阶 |
| 3n2+2n+1 | O(n2) | 平方阶 |
| 5log2n+20 | O(logn) | 对数阶 |
| 2n+3nlog2n+19 | O(nlogn) | nlogn阶 |
| 6n3+2n2+3n+4 | O(n3) | 立方阶 |
| 2n | O(2n) | 指数阶 |
注意,经常将log2n(以2为底的对数)简写成logn
常见时间复杂度之间的关系
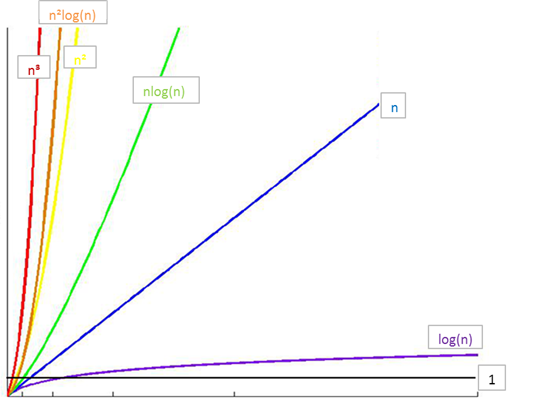
所消耗的时间从小到大
O(1) < O(logn) < O(n) < O(nlogn) < O(n2) < O(n3) < O(2n) < O(n!) < O(nn)
练习: 时间复杂度练习( 参考算法的效率规则判断 )
O(5)
O(2n + 1)
O(n²+ n + 1)
O(3n³+1)
1.7 Python内置类型性能分析
timeit模块
timeit模块可以用来测试一小段Python代码的执行速度。
class timeit.Timer(stmt='pass', setup='pass', timer=<timer function>)
Timer是测量小段代码执行速度的类。
stmt参数是要测试的代码语句(statment);
setup参数是运行代码时需要的设置;
timer参数是一个定时器函数,与平台有关。
timeit.Timer.timeit(number=1000000)
Timer类中测试语句执行速度的对象方法。number参数是测试代码时的测试次数,默认为1000000次。方法返回执行代码的平均耗时,一个float类型的秒数。
list的操作测试
def test1(): l = [] for i in range(1000): l = l + [i] def test2(): l = [] for i in range(1000): l.append(i) def test3(): l = [i for i in range(1000)] def test4(): l = list(range(1000)) from timeit import Timer t1 = Timer("test1()", "from __main__ import test1") print("concat ",t1.timeit(number=1000), "seconds") t2 = Timer("test2()", "from __main__ import test2") print("append ",t2.timeit(number=1000), "seconds") t3 = Timer("test3()", "from __main__ import test3") print("comprehension ",t3.timeit(number=1000), "seconds") t4 = Timer("test4()", "from __main__ import test4") print("list range ",t4.timeit(number=1000), "seconds") # ('concat ', 1.7890608310699463, 'seconds') # ('append ', 0.13796091079711914, 'seconds') # ('comprehension ', 0.05671119689941406, 'seconds') # ('list range ', 0.014147043228149414, 'seconds')
pop操作测试
x = range(2000000) pop_zero = Timer("x.pop(0)","from __main__ import x") print("pop_zero ",pop_zero.timeit(number=1000), "seconds") x = range(2000000) pop_end = Timer("x.pop()","from __main__ import x") print("pop_end ",pop_end.timeit(number=1000), "seconds") # ('pop_zero ', 1.9101738929748535, 'seconds') # ('pop_end ', 0.00023603439331054688, 'seconds')
测试pop操作:从结果可以看出,pop最后一个元素的效率远远高于pop第一个元素
可以自行尝试下list的append(value)和insert(0,value),即一个后面插入和一个前面插入???
list内置操作的时间复杂度

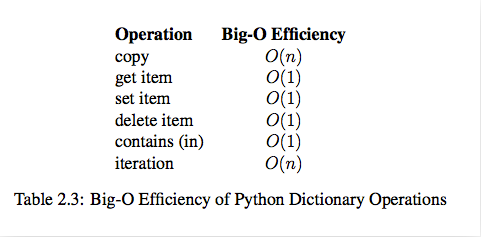
1.8 数据结构
我们如何用Python中的类型来保存一个班的学生信息? 如果想要快速的通过学生姓名获取其信息呢?
实际上当我们在思考这个问题的时候,我们已经用到了数据结构。列表和字典都可以存储一个班的学生信息,但是想要在列表中获取一名同学的信息时,就要遍历这个列表,其时间复杂度为O(n),而使用字典存储时,可将学生姓名作为字典的键,学生信息作为值,进而查询时不需要遍历便可快速获取到学生信息,其时间复杂度为O(1)。
我们为了解决问题,需要将数据保存下来,然后根据数据的存储方式来设计算法实现进行处理,那么数据的存储方式不同就会导致需要不同的算法进行处理。我们希望算法解决问题的效率越快越好,于是我们就需要考虑数据究竟如何保存的问题,这就是数据结构。
在上面的问题中我们可以选择Python中的列表或字典来存储学生信息。列表和字典就是Python内建帮我们封装好的两种数据结构。
概念
数据是一个抽象的概念,将其进行分类后得到程序设计语言中的基本类型。如:int,float,char等。数据元素之间不是独立的,存在特定的关系,这些关系便是结构。数据结构指数据对象中数据元素之间的关系。
Python给我们提供了很多现成的数据结构类型,这些系统自己定义好的,不需要我们自己去定义的数据结构叫做Python的内置数据结构,比如列表、元组、字典。而有些数据组织方式,Python系统里面没有直接定义,需要我们自己去定义实现这些数据的组织方式,这些数据组织方式称之为Python的扩展数据结构,比如栈,队列等。
算法与数据结构的区别
数据结构只是静态的描述了数据元素之间的关系。
高效的程序需要在数据结构的基础上设计和选择算法。
程序 = 数据结构 + 算法
总结:算法是为了解决实际问题而设计的,数据结构是算法需要处理的问题载体
抽象数据类型(Abstract Data Type)
抽象数据类型(ADT)的含义是指一个数学模型以及定义在此数学模型上的一组操作。即把数据类型和数据类型上的运算捆在一起,进行封装。引入抽象数据类型的目的是把数据类型的表示和数据类型上运算的实现与这些数据类型和运算在程序中的引用隔开,使它们相互独立。
最常用的数据运算有五种:
- 插入
- 删除
- 修改
- 查找
- 排序