Zookeeper много проблем, с которыми сталкиваются распределенными системами, такие как распределенные замок, единую службу имен, распределительный центр, управление кластерным Лидера выборова
Подготовка среды
Распространены среди узлов системы связи, Zookeeper этот процесс, чтобы гарантировать, что данные уникальны, безопасно и надежно
- Измените файл конфигурации
/Conf/zoo_sample.cfg модифицирован для zoo.cfg
Профиль Reading
# zookeeper 服务器和客户端之间维持心跳的时间间隔,即每个ticktime发送一个心跳包,单位是毫秒
# zookeeper 中session过期的时间是 ticktime*2
tickTime=2000
# Leader 允许Follower在initLimit时间内完成从Leader身上同步全部数据的工作, 随机集群的不断扩大,Follower从Leader上同步数据的时间就会变成,此时有必要,默认是0
initLimit=10
# Leader会和集群中的其他机器进行通信,在syncLimit时间内,都没有从Follower上获取返回数据,就认为这个节点挂了
syncLimit=5
# 存储快照文件的目录,默认情况下事务日志也在这里了,下面单独配置,因为因为日志的写性能影响zookeeper的性能
dataDir=E:\\zookeeper\\zookeeper-3.4.14\\data
dataLogDir=E:\\zookeeper\\zookeeper-3.4.14\\log
# the port at which the clients will connect
# 客户端连接的端口
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1- начало
Сценарий начинается в / бен / каталог
загрузки Linux ./zkCli.sh -server localhost:2181
****
успешно запущен в консоли клиента
# 默认的节点叫zookeeper
[zk: localhost:2181(CONNECTED) 1] ls /
[zookeeper]
# 创建一个节点
[zk: localhost:2181(CONNECTED) 11] create /changwu1 "num1"
Created /changwu1
# 重新查看
[zk: localhost:2181(CONNECTED) 14] ls /
[zookeeper, changwu1]
# 获取节点的内容
[zk: localhost:2181(CONNECTED) 17] get /changwu1
num1
cZxid = 0x2
ctime = Mon Sep 16 15:56:27 CST 2019
mZxid = 0x2
mtime = Mon Sep 16 15:56:27 CST 2019
pZxid = 0x2
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 4
numChildren = 0
# 退出
quit
# 删除一个节点
[zk: localhost:2181(CONNECTED) 32] delete /changwu1
[zk: localhost:2181(CONNECTED) 33] ls /
[zookeeper]
# 递归删除节点
rmr /path1/path2
这个path1 和 path2 其实是两个节点
# 修改节点数据
set /path "value"
# 节点的状态
[zk: localhost:2181(CONNECTED) 50] stat /z1
cZxid = 0x5
ctime = Mon Sep 16 16:04:35 CST 2019
mZxid = 0x7
mtime = Mon Sep 16 16:06:31 CST 2019
pZxid = 0x6
cversion = 1
dataVersion = 1
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 8
numChildren = 1
# 创建永久有序节点
create -s /pathСоздать узел формы, и мы MkDir, создать структуру каталогов подобную
Кластер Setup
- В zoo.cfg три экземпляра, и внести изменения в файл конфигурации
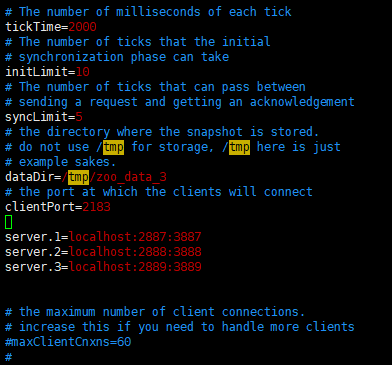
Второй порт 2887, чтобы синхронизировать данные между лидером и последователем, третьи порты используются, чтобы избрать новый лидер
- Создание каталога в шести каталоге ТМР zoo_data_1-3 zoo_logs_1-3 соответственно
- Создайте файл MyId
[root@139 tmp]# echo 1 > zoo_data_1/myid
[root@139 tmp]# echo 2 > zoo_data_2/myid
[root@139 tmp]# echo 3 > zoo_data_3/myidЗапустите сервер кластера
[root@139 bin]# ./zkServer.sh start ../conf/zoo1.cfg
ZooKeeper JMX enabled by default
Using config: ../conf/zoo1.cfg
Starting zookeeper ... STARTED
[root@139 bin]# ./zkServer.sh start ../conf/zoo2.cfg
ZooKeeper JMX enabled by default
Using config: ../conf/zoo2.cfg
Starting zookeeper ... STARTED
[root@139 bin]# ./zkServer.sh start ../conf/zoo3.cfg
ZooKeeper JMX enabled by default
Using config: ../conf/zoo3.cfg
Starting zookeeper ... STARTEDПроверьте состояние каждого узла, соответственно,
[root@139 bin]# ./zkServer.sh status ../conf/zoo3.cfg
ZooKeeper JMX enabled by default
Using config: ../conf/zoo3.cfg
Mode: follower
[root@139 bin]# ./zkServer.sh status ../conf/zoo1.cfg
ZooKeeper JMX enabled by default
Using config: ../conf/zoo1.cfg
Mode: leader
[root@139 bin]# ./zkServer.sh status ../conf/zoo2.cfg
ZooKeeper JMX enabled by default
Using config: ../conf/zoo2.cfg
Mode: follower
Клиент подключения
./zkCli -server localhost:服务端的端口号
zkCli.sh -server localhost:2181
zkCli.sh -server localhost:2182
zkCli.sh -server localhost:2183Добавление наблюдателя
- И, как и первые три, создать каталог Сентинел, используемый в каталоге ТМР zoo_data_4 zoo_logs_4 соответственно
- Он MyId создавать файлы в каталоге zoo_data_4 написать 4
- Изменение первого файла конфигурации три узла
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/tmp/zoo_data_1
dataLogDir=/tmp/zoo_logs_1
clientPort=2181
# 第一个端用于Leader和Leanner之间同步, 第二个端口,用户选举过程中的投票通信
server.1=localhost:2887:3887
server.2=localhost:2888:3888
server.3=localhost:2889:3889
server.4=localhost:2890:3890:observer- Добавить профиль просмотра
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/tmp/zoo_data_4
dataLogDir=/tmp/zoo_logs_4
# 观察者的配置
peerType=observer
clientPort=2184
# 第一个端用于Leader和Leanner之间同步, 第二个端口,用户选举过程中的投票通信
server.1=localhost:2887:3887
server.2=localhost:2888:3888
server.3=localhost:2889:3889
server.4=localhost:2890:3890:observerКластер роли
лидер
Опрос и резолюция, окончательный статус был обновлен
толкатель
Прием обработки запроса клиента для участия в Leader спонсируемых резолюции
наблюдатель
Разрешать соединения клиента, перенаправляет запрос на Лидер байт, но он не участвует в голосовании, но только синхронизирует лидер государства, это способ расширить зоопарк
? Почему это добавить наблюдателя и работа зоопарка тесно связана с:
Кластер множество зоопарка сервера, каждый сервер для обработки запроса может быть множество клиента, и если это запрос на чтение, локальная база данных с текущим суб-сервер напрямую , соответствующий настоящему, однако, если запрос является запросом записи для изменения состояния зоопарка , становится затруднительным, лидер узел Zookeeper будет опрашивать этот механизм является Заб соглашения , согласие более половины узлов, поместит эту операцию загружаются в память, и ответы клиентов
В этом процессе Zookeeper служили две функции, с одной стороны , чтобы принять соединение клиента, с другой стороны , они должны инициировать голосование по резолюции, эти две функции , чтобы ограничить Zookeeper расширение хотели бы поддержать несколько клиентских подключений, вы должны добавить сервер но все больше и больше сервера каждый раз , когда опрос становится тяжелым, поэтому наблюдатель возник
Наблюдатель, не будет участвовать в голосовании, в то время как другие узлы в стадии голосования наблюдателей получения соединения клиента, переадресация лидера соединения, но он также будет получать результаты процесса голосования, тем самым значительно повысить пропускную способность системы
компактнее
Лидер и вместе коллективно узел состояния синхронизации, наблюдатель и коллективно компактнее Последователя
Zookeeper в CPA
CP: Когда узел кластера остается только лидер последователь, лидер повесил трубку, вы должны переизбрать, избирательный процесс в системе является непригодным для использования
AP: Лидер Последователь наблюдателя, о составе трех групп, для достижения AP, повесил трубку, когда лидер, то же выборы, но наблюдатель может продолжать принимать запрос клиента, но наблюдатель данные не могут быть последние данные