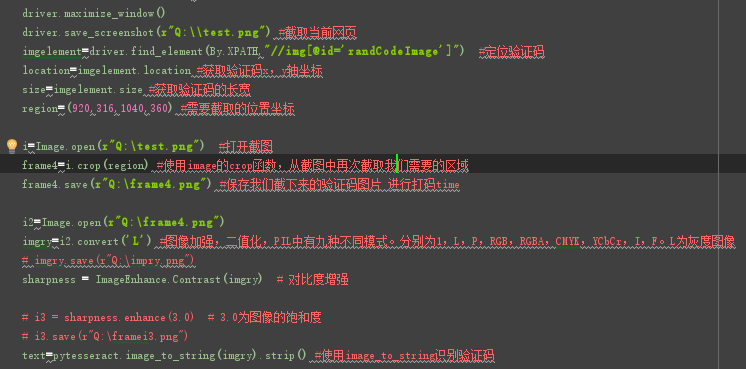
Основные шаги:
Место коды приняты - «Использовать изображение в кадрирования функцию, требуемую площадь , занимаемую снова - » вырубить , чтобы сохранить кодирующую область Time- «улучшение изображения, бинарный - » Enhanced Contrast - «выходные коды
По PIL + pytesseract + Тессеракт-OCR достижения идентификационных кодов
PIL для обработки изображений библиотеки Python . ( PIL установлены сторонние библиотеки: PIP установить PIL ). Image класс является PIL библиотека является очень важным классом , чтобы создать экземпляр этого класса, непосредственно загрузки файлов изображений можно прочитать и обработанное изображение изображение , полученное с помощью метода сканирования.
Тессеракт: с открытым исходным кодом OCR распознавания двигатель. И не прямо в питона использования, необходимо использовать Python классы обертки pytesseract .
Python-тессеракт является оптическим распознавания символов Tesseract OCR двигателя Python классы - оболочки. Уметь читать любые обычные файлы изображений (JPG, GIF, PNG, TIFF и т.д.) и декодируется в читаемый язык.
Определение следующих шагов:
1, установить PIL ( загрузить файл с расширением .exe , чтобы выполнить установку )
2, установить Тессеракт (скачать файл .exe для выполнения установки)
3, монтаж pytesseract (устанавливаются с помощью пипа installpytesseract)
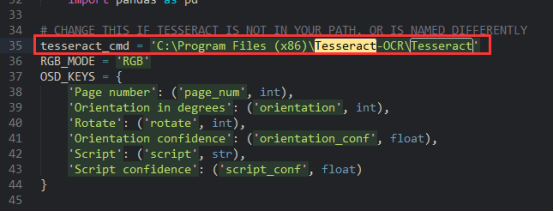
Примечание: C: \ python27 \ Lib \ Site-пакеты Стандартный пакет \ pytesseract \ pytesseract.py файл, Tesseract_cmd путь к файлу, вам необходимо изменить путь установки, в противном случае он будет сообщен Тессеракт путь проблема выполнения. Как следует:
Успешная идентификация проверочный код