
Автор: Цзинь Сюэфэн
фон
Запуск больших языковых моделей на статических графах имеет множество преимуществ, в том числе:
-
Повышение производительности за счет оптимизации слияния операторов/выполнения всего графа, если это Ascend, вы также можете использовать выполнение полного погружения графа для дальнейшего повышения производительности, и на выполнение полного погружения графа не влияет выполнение обработки данных на стороне хоста. и производительность стабильно хорошая;
-
Статическая оркестровка памяти обеспечивает более эффективное использование памяти без фрагментации, увеличивает размер пакета и, таким образом, повышает производительность обучения;
-
Автоматически оптимизируйте последовательность выполнения и обеспечьте хорошую связь и параллелизм вычислений;
-
......
Однако при запуске больших языковых моделей на статических изображениях также возникают проблемы. Наиболее заметной из них является производительность компиляции.
Процесс компиляции модели нейронной сети фактически преобразует код nn, выраженный на Python, в граф расчета потока данных:
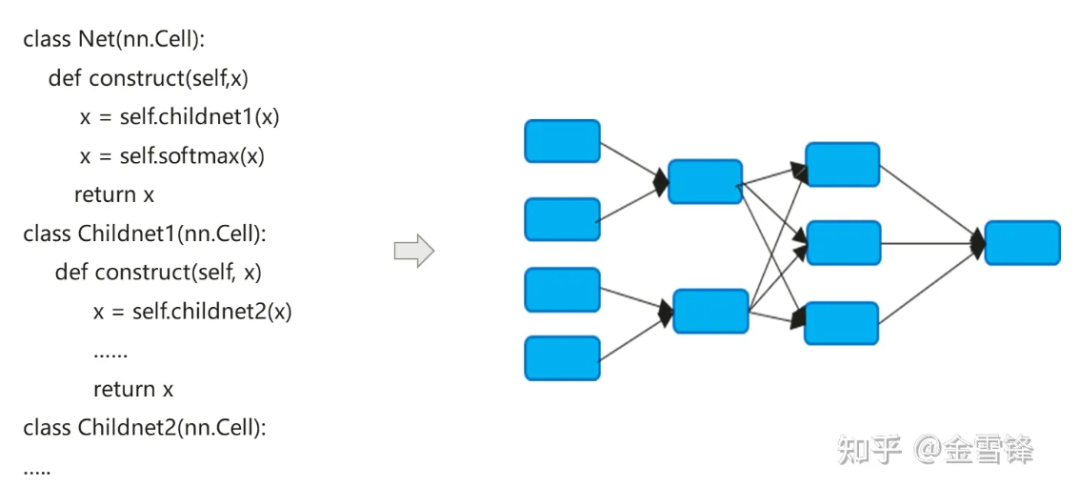
Процесс компиляции моделей нейронных сетей немного отличается от традиционных компиляторов. Метод Inline по умолчанию часто используется для окончательного расширения иерархического выражения кода в плоский граф вычислений. С одной стороны, он стремится максимизировать возможности оптимизации компиляции, а с другой. с другой стороны, это также может упростить логику автоматического дифференцирования и выполнения.
По умолчанию граф вычислений, сформированный после Inline, включает в себя все узлы вычислений, и узлы больше не имеют подразделов графа вычислений. Таким образом, оптимизацию в процессе можно выполнять в более широком масштабе, например, свертывание констант, объединение узлов, параллельный анализ. и т. д., а также может лучше реализовать распределение памяти и уменьшить нагрузку на приложения памяти и производительность при вызове между процедурами. Даже для вычислительных модулей, которые вызываются повторно, компиляторы в области ИИ по-прежнему используют одну и ту же встроенную стратегию. Платя за увеличение размера программы и рост исполняемого кода, они могут максимально использовать методы оптимизации компиляции для повышения производительности во время выполнения.
Как видно из приведенного выше описания, встроенная оптимизация очень полезна для повышения производительности во время выполнения, но, соответственно, чрезмерная встроенность также приводит к увеличению времени компиляции. Поскольку граф подвычислений интегрирован во весь граф, с глобальной точки зрения количество узлов вычислительного графа, которые должен обрабатывать компилятор, быстро увеличивается. Компиляторы обычно используют механизм Pass для организации и упорядочения методов оптимизации. Различные методы оптимизации соединяются последовательно в форме Pass, и процесс обработки проходит через каждый узел графа вычислений. Количество проходов обработки зависит от процесса сопоставления и преобразования узла и прохода. Иногда для завершения обработки требуется несколько проходов. Вообще говоря, если количество проходов равно M, а количество вычислительных узлов графа равно N, время всего процесса компиляции и оптимизации напрямую связано со значением M * N. В эпоху больших языковых моделей эта проблема стала более заметной. Есть две основные причины: во-первых, структура больших языковых моделей глубока и имеет большое количество узлов, во-вторых, при обучении больших языковых моделей; при включении конвейерного параллелизма масштаб модели и количество узлов дополнительно увеличивается. Если исходный размер графа равен O, включите конвейерный параллелизм, и размер одноузлового графа станет (O/X)*Y. , где X — количество стадий в конвейере, а Y — количество микропакетов. В действительности во время процесса настройки Y намного больше, чем X. Например, X — 16, а Y обычно устанавливается на 64–192. Таким образом, после включения распараллеливания конвейера масштаб компиляции графа еще больше увеличится до 4-12 раз по сравнению с исходным размером.

Если взять в качестве примера некую сеть 13B, состоящую из десятков миллиардов языковых моделей, количество вычислительных узлов в графе вычислений достигает 135 000, а время одной компиляции может достигать 3 часов.
**1.** Идеи по оптимизации
Мы заметили, что структура нейронной сети глубокого обучения состоит из нескольких слоев. В модели языка большой модели эти слои представляют собой стопки блоков Transformer. Особенно когда включен конвейерный параллелизм, уровни каждого микропакета абсолютно одинаковы. . Поэтому мы задаемся вопросом, можем ли мы заранее сохранить эти структуры слоев без Inline или Inline, чтобы производительность компиляции можно было улучшить экспоненциально. Например, если мы будем следовать микропакету как границе и сохранять структуру подграфа микропакета. тогда теоретически время компиляции может быть в один раз больше исходного Y (Y — количество микропакетов).
Что касается кода, написанного в модели, мы видим, что способ повторного использования одного и того же слоя обычно представляет собой цикл или итеративный вызов. Слой обычно соответствует элементу последовательной структуры в итеративном процессе, часто подграфу; используя цикл или итерацию для многократного вызова одного и того же вычислительного блока, как показано в коде ниже, блок соответствует подграфу слоя или микропакета.
class Block(nn.Cell):
def __init__(self, config):
.......
def construct(self, x, attention_mask, layer_past):
......
class GPT_Model(nn.Cell):
def __init__(self, config):
......
for i in range(config.num_layers):
self.blocks.append(Block)
......
self.num_layers = config.num_layers
def construct(self, input_ids, input_mask, layer_past):
......
present_layer = ()
for i in range(self.num_layers):
hidden_states, present = self.blocks[i](...)
present_layer = present_layer + (present,)
......
Следовательно, если мы рассматриваем тело цикла как часто вызываемый подграф и сообщаем компилятору отложить встроенную обработку, пометив его как Lazy Inline, то прирост производительности можно получить на большинстве этапов компиляции. Например, когда нейронная сеть циклически вызывает одну и ту же структуру подграфа, мы не расширяем подграф на этапе компиляции, а затем, в конце компиляции, запускается встроенная оптимизация для выполнения необходимой оптимизации и обработки прохода преобразования; Таким образом, для компилятора большую часть времени это код меньшего размера, а не код, который был встроен в код, что значительно повышает производительность компиляции.
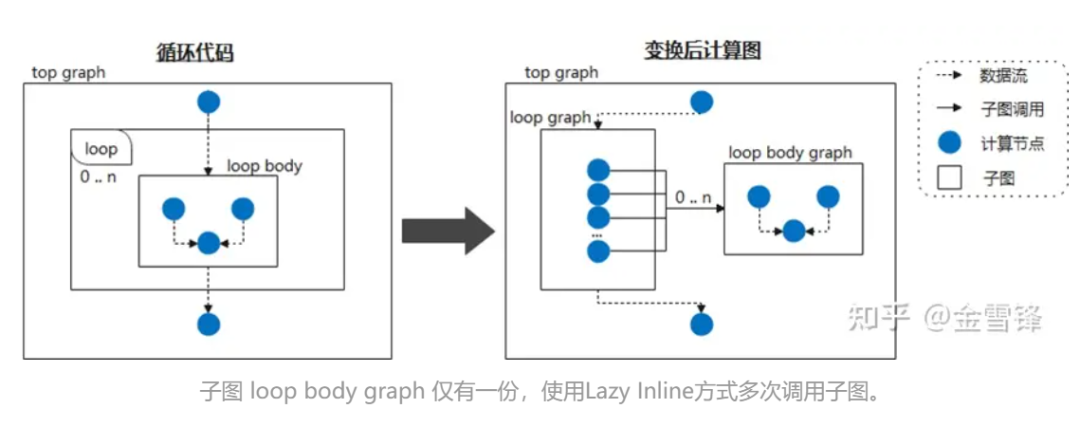
Во время конкретной реализации вы можете поставить метку, похожую на @lazy-inline, на соответствующий класс Layer, чтобы сообщить компилятору, вызывается ли отмеченный Layer в теле цикла или другими способами, он не будет включен во время компиляции. не выполняется до момента выполнения.
**2. ** Практика MindSpore.
Кажется, что принципы и идеи Lazy Inline не сложны, но существующий механизм компиляции графов AI, как правило, не является тем компилятором, который поддерживает полные функции компиляции, поэтому реализовать эту функцию по-прежнему очень сложно.
К счастью, компилятор графов MindSpore при разработке IR учел универсальность, включая вызовы подфункций, замыкания и другие функции.
① Экземпляры ячеек компилируются в многократно используемые графики вычислений.
Cell — это базовый строительный блок нейронной сети MindSpore и базовый класс всех нейронных сетей. Cell может представлять собой отдельный модуль нейронной сети, такой как conv2d, relu,atch_norm и т. д., или это может быть комбинация модулей, которые создают сеть. В GRAPH_MODE (режим статического графика) Cell будет скомпилирован в график вычислений.
Когда вам нужно настроить сеть, вам нужно наследовать класс Cell и переопределить методы __init__ и construct. Класс Cell переопределяет метод __call__. Когда вызывается экземпляр класса Cell, выполняется метод конструктора. Определить структуру сети в методе построения.
В следующем примере создается простая сеть для реализации функции расчета свертки. Операторы в сети определяются в __init__ и используются в методе конструкции. Сетевая структура кейса: Conv2d -> BiasAdd.
В методе построения x — входные данные, а выходные — результат, полученный после расчета структуры сети.
import mindspore.nn as nn
import mindspore.ops as ops
from mindspore import Parameter
from mindspore.common.initializer import initializer
from mindspore._extends import lazy_inline
class MyNet(nn.Cell):
@lazy_inline
def __init__(self, in_channels=10, out_channels=20, kernel_size=3):
super(Net, self).__init__()
self.conv2d = ops.Conv2D(out_channels, kernel_size)
self.bias_add = ops.BiasAdd()
self.weight = Parameter(initializer('normal', [out_channels, in_channels, kernel_size, kernel_size]))
def construct(self, x):
output = self.conv2d(x, self.weight)
output = self.bias_add(output, self.bias)
return output
@Lazy_Inline — декоратор Cell::__init__. Его функция — сгенерировать все параметры __init__ в значение атрибута cell_init_args Cell, self.cell_init_args = type(self).__name__ + str(arguments). Атрибут cell_init_args служит уникальным идентификатором экземпляра Cell в компиляции MindSpore. То же значение cell_init_args указывает на то, что имя класса Cell и значения параметров инициализации совпадают.
Конструкция(self, x) определяет структуру сети, которая аналогична классу Cell. Структура сети зависит от входных параметров self и x. Self содержит такие параметры, как веса. Эти веса инициализируются случайным образом или в результате обучения, поэтому эти веса различны для каждого экземпляра ячейки. Другие собственные атрибуты определяются параметром __init__, а параметр __init__ вычисляется @lazy_inline для получения идентификатора экземпляра Cell cell_init_args. Таким образом, конструкция графа расчета компиляции экземпляра Cell (self, x) преобразуется в конструкцию (x, self. cell_init_args, self.trainable_parameters() ).
Если это один и тот же класс Cell и параметры cell_init_args одинаковы, мы называем эти экземпляры нейронов повторно используемыми экземплярами нейронов, а граф вычислений, соответствующий этому экземпляру нейрона, называется повторно используемым графом вычислений reuse_construct(X, self.trainable_parameters()). Можно сделать вывод, что график вычислений каждого экземпляра Cell можно преобразовать в:
def construct(self, x)
Reuse_construct(x, self.trainable_parameters())
После введения многоразовых вычислительных графов нейронные ячейки (многоразовые вычислительные графы) с одинаковыми cell_init_args необходимо составить и скомпилировать только один раз. Чем больше ячеек в сети, тем выше может быть производительность. Но у всего есть две стороны. Если граф вычислений этих ячеек слишком мал или слишком велик, это приведет к плохой компиляции и оптимизации некоторых функций, таких как объединение операторов, мультиплексирование памяти, поглощение всего графа, вызов нескольких графов и т. д. .
Таким образом, версия MindSpore в настоящее время поддерживает только ручную идентификацию того, какие этапы компиляции ячеек генерируют повторно используемые графики вычислений. В последующих версиях будут планироваться автоматические стратегии для создания повторно используемых графов вычислений, например, сколько операторов содержит ячейка, сколько раз используется ячейка, а также другие факторы, позволяющие взвесить, следует ли создавать повторно используемый график вычислений, и давать предложения по оптимизации.
Ниже для абстрактного и упрощенного объяснения используется структура GPT:
class Block(nn.Cell):
@lazy_inline
def __init__(self, config):
.......
def construct(self, x, attention_mask, layer_past):
......
class GPT_Model(nn.Cell):
def __init__(self, config):
......
for i in range(config.num_layers):
self.blocks.append(Block(config, None))
......
self.num_layers = config.num_layers
def construct(self, input_ids, input_mask, layer_past):
......
present_layer = ()
for i in range(self.num_layers):
hidden_states, present = self.blocks[i](...)
present_layer = present_layer + (present,)
......
GPT состоит из нескольких слоев блоков. Все параметры инициализации этих блоков имеют одинаковую конфигурацию, поэтому структуры этих блоков одинаковы и будут внутренне преобразованы компилятором в следующую структуру:
def Reuse_Block(x, attention_mask, layer_past,block_parameters) :
......
具体的Block 实例的计算图如下:
def construct(self, x, attention_mask, layer_past):
return Reuse_Block(x, attention_mask, layer_past,
self. trainable_parameters())
При такой структуре в первой половине процесса компиляции это независимый граф вычислений, который не встраивается в общий граф вычислений. В большой граф вычислений встраивается только заключительная небольшая часть оптимизации Pass.
② Комбинация L****azy Inline и автоматического дифференцирования/параллельного/пересчета и других функций.
После принятия решения Lazy Inline оно окажет некоторое влияние на исходный процесс и потребует соответствующих адаптаций, в основном автоматического дифференцирования, параллелизма и пересчета.
Для автоматического дифференцирования появляется узел пересылки, аналогичный функции вызова, и необходимо обеспечить обработку дифференциации;
Для параллельных процессов главное, чтобы обработка параллельных проходов Pipeline была адаптирована к сценариям неполного изображения, поскольку предыдущая обрезка Pipeline основывалась на всей картинке, а теперь ее нужно разрезать на основе общего подграфа. Конкретный план состоит в том, чтобы сначала раскрасить в соответствии со стадией, разделить узлы в общей ячейке в соответствии со стадией, сохранить только узлы, соответствующие стадии текущего процесса, и вставить оператор отправки/получения, а затем разделить узлы. за пределами общей ячейки, сохраняя соответствующие узлы текущего процесса. Узел этапа также выводит оператор отправки/получения в общей ячейке из общей ячейки;
Для процесса пересчета старый процесс пересчета обрабатывает операторы на всем графе после Inline. Путем поиска пересчитываемых блоков непрерывных операторов операторы, которые необходимо пересчитать, и параметры пересчета определяются в соответствии с конфигурацией пересчета пользователя. оператор, от которого зависит выполнение вычисляемого оператора. После Lazy Inline последовательные операторы пересчета могут находиться в разных подграфах, и между прямым узлом и обратным узлом не может быть найдено никакого отношения связи, поэтому исходная стратегия поиска, основанная на всем операторе графа, терпит неудачу.
Наш план адаптации заключается в обработке пересчитанных ячеек или операторов после автоматической дифференциации. Процесс автоматического дифференцирования создаст замыкание для подграфа или одного оператора, созданного Cell, который возвращает прямой вывод и функцию обратного распространения ошибки, а также мы получаем связь между каждым замыканием и исходной прямой частью. Благодаря этой информации, на основе конфигурации пересчета пользователя, каждое замыкание используется в качестве базовой единицы, ячейка и оператор обрабатываются единообразно, а исходная прямая часть копируется обратно в исходный граф, и через него можно передать отношение зависимости. Закрытие в замыкании. Приобретение функции обратного распространения ошибки может, наконец, обеспечить схему пересчета, которая не полагается на Inline всего графика.
③Вторая обработка и влияние
IR, созданный после включения Lazy Inline на внешнем интерфейсе, отправляется на серверную часть, прежде чем он сможет быть выполнен на устройстве через прием подграфа. Однако после Lazy Inline все равно будут возникать некоторые проблемы при выполнении погружения подграфа, такие как невозможность использования оптимального метода повторного использования памяти и выделения потока, невозможность использования внутреннего кэша графа для ускорения компиляции во время компиляции. и невозможность выполнения перекрестной обработки графов (оптимизация памяти, объединение коммуникаций, объединение операторов и т. д.) и другие проблемы.
Для достижения оптимальной производительности серверной части необходимо обработать IR Lazy Inline в форму, подходящую для выполнения внутренней обработки. Главное, что нужно сделать, — это преобразовать оператор Partial, сгенерированный автоматическим дифференцированием, в обычный вызов подграфа и изменить его. захваченные переменные передаются как обычные параметры, чтобы можно было погрузить весь граф и выполнить всю сеть.
Во всем процессе приема графа эти вызовы имеют два метода обработки: встроенный в граф и встроенный в последовательность выполнения. Встроенное на графике приведет к расширению графа, и последующая скорость компиляции будет медленнее, однако встроенное в последовательность выполнения приведет к тому, что жизненный цикл части последовательности выполнения будет особенно продолжительным во время повторного использования памяти и в в конце памяти не хватит.
В конце концов, метод обработки, который мы приняли, заключался в повторном использовании встроенного процесса последовательности выполнения на этапе оптимизации, выборе оператора, компиляции оператора и других процессах, чтобы сделать размер графа как можно меньшим и избежать слишком большого количества узлов графа, влияющих на серверную часть. составление графика времени. Перед выполнением оптимизации последовательности, распределения потоков, повторного использования памяти и других процессов эти вызовы выполняются в реальных узлах Inline, чтобы получить оптимальный эффект повторного использования памяти. Кроме того, за счет некоторой оптимизации памяти и связи, устранения избыточных вычислений и других методов после встроенного графика можно добиться отсутствия ухудшения памяти и производительности.
В настоящее время невозможно достичь всех оптимизаций на уровне графа. Одноточечную идентификацию можно разместить только на этапе после Inline, и невозможно сэкономить время на оптимизации порядка выполнения, выделении потока и повторном использовании памяти.
④Достижение эффектов
Оптимизация производительности компиляции больших моделей использует решение Lazy Inline для повышения производительности компиляции в 3–8 раз. Если взять в качестве примера сеть 13B из 10 миллиардов больших моделей, то после применения решения Lazy Inline масштаб компиляции графа вычислений упал со 130 000+. Node до 20 000+ узлов, время компиляции сократилось с 3 часов до 20 минут, а в сочетании с кэшированием результатов компиляции общая эффективность значительно улучшилась.
⑤Ограничения использования и следующие шаги
1. Cell Идентификатор экземпляра Cell генерируется на основе имени класса Cell и значения параметра __init__. Это основано на предположении, что параметры init определяют все свойства Cell и что свойства Cell в начале композиции конструкции соответствуют свойствам после выполнения init. Следовательно, свойства Cell, связанные с композицией, не могут быть изменены. после выполнения инициализации.
2. Параметры функции-конструктора не могут иметь значения по умолчанию. Если существующая версия MindSpore имеет значения по умолчанию для параметров функции конструкции, каждый раз, когда она используется, она будет специализироваться на новом графе вычислений, последующие версии оптимизируют исходный механизм специализации;
3. Ячейка состоит из нескольких общих экземпляров Cell_X, и каждая Cell_X состоит из нескольких общих экземпляров Cell_Y. Если инициализация Cell_X и Cell_Y оформлена как @lazy_inline, только самая внешняя Cell_X может быть скомпилирована в повторно используемый граф вычислений, а график вычислений внутренней Cell_Y по-прежнему будет встроенным; последующие версии планируют поддерживать эту многоуровневую ленивую встроенную строку; механизм.
Как помочь клиентам в написании кода с высокой связностью и низкой связностью также является одной из целей, которые преследует фреймворк MindSpore. Например, используется параметр Block::__init__, который содержит индекс Layer. другие параметры одинаковы. Поскольку индекс слоя используется каждый. Каждый слой различен, в результате чего блок не может быть повторно использован из-за небольших различий. Например, следующий код существует в определенном коде версии GTP:
class Block (nn.Cell):
"""
Self-Attention module for each layer
Args:
config(GPTConfig): the config of network
scale: scale factor for initialization
layer_idx: current layer index
"""
def __init__(self, config, scale=1.0, layer_idx=None):
......
if layer_idx is not None:
self.coeff = math.sqrt(layer_idx * math.sqrt(self.size_per_head))
self.coeff = Tensor(self.coeff)
......
def construct(self, x, attention_mask, layer_past=None):
......
Чтобы сделать блок многоразовым, мы можем оптимизировать его, извлечь вычисления, связанные с индексом слоя, а затем использовать их в качестве параметров Construct для ввода их в исходную композицию, чтобы параметры инициализации блока были одинаковыми.
Измените приведенный выше сегмент кода на следующий сегмент кода, удалите части, связанные с Init и Layer Index, и добавьте параметр coeff для построения.
class Block (nn.Cell):
def __init__(self, config, scale=1.0):
......
def construct(self, x, attention_mask, layer_past, coeff):
......
В последующих версиях Shengsi MindSpore мы планируем идентифицировать такие незначительно отличающиеся блоки и предоставлять предложения по оптимизации этих блоков для оптимизации и улучшения.
Программист, родившийся в 1990-х годах, разработал программу для переноса видео и заработал более 7 миллионов менее чем за год. Концовка была очень суровой! Google подтвердил увольнения, связанные с «проклятием 35-летней давности» китайских программистов в командах Flutter, Dart и . Python Arc Browser для Windows 1.0 через 3 месяца официально Доля рынка Windows 10 достигает 70%, Windows 11 GitHub продолжает снижаться GitHub выпускает собственный инструмент разработки AI GitHub Copilot Workspace JAVA. — единственный запрос строгого типа, который может обрабатывать OLTP+OLAP. Это лучший ORM. Мы встречаемся слишком поздно.