
Автор: Лу Юфэн Источник: Чжиху
Краткое содержание
Разработка MindNLP длилась около года. В целом, она сталкивается с множеством проблем, а также сопровождается рядом воздействий и проблем, связанных с LLM. Будучи поздно появившейся структурой НЛП, которая опирается на MindSpore для своего восходящего роста, ей фактически необходимо подумать о том, как расширить свою экологию.
Как говорится - если не можешь победить, присоединяйся. Но для мира открытого исходного кода нет необходимости говорить о присоединении. Для вас нормально иметь меня и быть частью меня. Более того, в тот момент, когда два дня назад было официально объявлено о Pytorch2.1+Ascend. экологическая прививка, несомненно, является лучшим решением. Хватит сплетен и перейдем к делу.
01
Наборы данных MindNLP
С самого начала разработки MindNLP мы надеемся в полной мере использовать все преимущества и возможности MindSpore, включая функциональное программирование, функции динамических графов, механизмы обработки данных и т. д. Здесь механизм обработки данных вынесен отдельно и подробно рассмотрен.
1.1 Механизм обработки данных MindSpore
Рисунок 1. Схематическая диаграмма конвейера механизма обработки данных MindSpore.
Как показано на рисунке, конструкция механизма обработки данных представляет собой конвейер [1], который очень похож на набор данных Tensorflow и наборы данных в стиле карты Pytorch и в основном нацелен на высокопроизводительную обработку данных.
В эпоху, когда все еще вносят небольшие изменения в модели и небольшие наборы данных для обновления рейтинга, предварительная обработка данных обычно выполняется в автономном режиме, поэтому Python можно использовать для их обработки максимально гибко, и обычно для этого достаточно большого объема памяти сервера. Приспособьтесь к этому. Каждый будет загружать все данные одновременно, а затем открывать несколько процессов для их обработки. После этого загрузите его в Tensor и отправьте в сеть для обучения. Но даже в этом случае, если набор данных немного больше, предварительная обработка набора данных может занять часы или даже дни.
Метод Pipeline фокусируется на нескольких возможностях:
1. Загрузка по требованию
2. Асинхронная обработка
3. Параллельно
Среди них 1 и 2 можно обсудить подробно. Если взять в качестве примера текстовые данные, то если используется простейшая логика предварительной обработки загрузки Python (то есть Pytorch Dataloader), общий поток выполнения будет следующим:
数据集全量加载至内存 -> 全量遍历并预处理 -> 单条数据打包Batch -> 循环返回每个Batch
Метод загрузки Pipeline:
Более наглядное описание: теперь есть указатель, указывающий на начало файла набора данных. Каждый раз мы извлекаем пакет данных, и указатель перемещается на размер пакета, пока он не будет получен.
Очевидно, что выборка только соответствующего объема данных каждый раз может значительно снизить потребление памяти, а промежуточные переменные, генерируемые в процессе предварительной обработки, также можно сжать до небольшого размера. Кроме того, этот метод может преобразовать предварительную обработку данных в режиме онлайн в онлайн:
取Batch size条数据加载 -> Batch size条数据遍历并预处理 -> 返回一个Batch
Рисунок 2. Конвейер обработки данных и сетевых вычислений.
Конвейер обработки данных непрерывно обрабатывает данные и отправляет обработанные данные в кэш на стороне Устройства, после выполнения Шага данные следующего Шага считываются непосредственно из кэша Устройства; Пока сеть обучается, данные также обрабатываются, каждый из которых выполняет свои обязанности.
Конечно, этот метод также является палкой о двух концах. Улучшая использование памяти и производительность, он также создает проблемы с удобством использования. Карта на рис. 1 представляет собой асинхронную обработку. После настройки каждой операции предварительной обработки данных она не будет выполняться напрямую и возвращать результаты. Это не подходит для данных, требующих точного контроля и имеющих множество особых условий, и весьма вероятно выполнение конвейерного выполнения. . Внезапно возникает аномалия.
Однако LLM изменил эту ситуацию. Все задачи стали Next Token Prediction, а вся обработка данных также стала очисткой + Tokenize. Объем данных огромен, и потоковая передача данных в бизнес-сценариях естественно становится оптимальным решением (это так). вероятно, это основная причина, по которой Pytorch начал создавать конвейеры, а наборы данных HuggingFace также являются конвейерами).
1.2 Проблемы поддержки набора данных MindNLP
Как упоминалось ранее, при обработке данных MindNLP полностью используется механизм обработки данных MindSpore, и он поддерживает более 20 наборов данных в течение одного года (по данным torchtext). Однако при реальном использовании очевидно, что различные задачи НЛП требуют большего, чем просто эти наборы данных, и постоянно адаптироваться к открытой области сложно.
Кроме того, набор данных Shengsi MindSpore также вызвал некоторые проблемы. Основная проблема заключается в том, что набор данных MindSpore разработал три типа загрузчиков, а именно:
1. Загрузчик специального набора данных: например, IMDBDataset, EnWik9Dataset и т. д.
2. Текстовый абстрактный загрузчик: TextFileDataset.
3. Пользовательский загрузчик: GeneratorDataset.
Если вы используете 1, это означает, что вам нужно постоянно добавлять адаптации; если вы используете 2, вам необходимо предварительно обработать такие форматы, как xml, json и т. д., перед загрузкой. Это противоречит концепции высокоэффективного проектирования Pipeline, и вам придется это сделать. все еще сталкиваемся с необходимостью ручной адаптации. Объем разработки с использованием 3 означает, что первый шаг на рисунке 1 возвращается к полной загрузке, что явно не то, что нам нужно. Однако из-за необходимости быстрой поддержки набора данных мы все же выбрали для поддержки метод 1+3.
Это неэффективно и требует каждый раз отдельной адаптации. Так есть ли какое-то постоянное решение?
02
Экологическая трансплантация HuggingFace
Загрузка набора данных MindNLP преследует не более чем две цели:
1. Поддержка больших наборов данных без адаптации.
2. Используйте эффективный конвейер
Раз уж вы не сможете сделать это сами, давайте доверимся силе экологии. Помимо хранилища Transformers, HuggingFace разработала библиотеки для различных процессов обучения ИИ. Наборы данных накапливаются в течение нескольких лет и поддерживают большое количество наборов данных. А поскольку HuggingFace предоставляет услуги хостинга, многие новые наборы данных также находятся непосредственно в хранилище. Центр наборов данных. Публикуйте напрямую. Используя наборы данных для решения проблемы 1, давайте посмотрим на вторую проблему.
Фактически, большинство людей, использующих набор данных MindSpore, в основном выбирают два метода обработки:
1. Автономная предварительная обработка в MindRecord и последующая загрузка с помощью MindDataset.
2. Загрузите набор данных в память, а затем загрузите его с помощью специального загрузчика набора данных/GeneratorDataset.
Чтобы иметь возможность выполнять предварительную онлайн-обработку, метод 1 явно не рекомендуется, поэтому идея использования наборов данных HuggingFace также очень проста. Я рассмотрел две идеи и обсужу их ниже.
2. 1 Загрузка набора данных по прививке
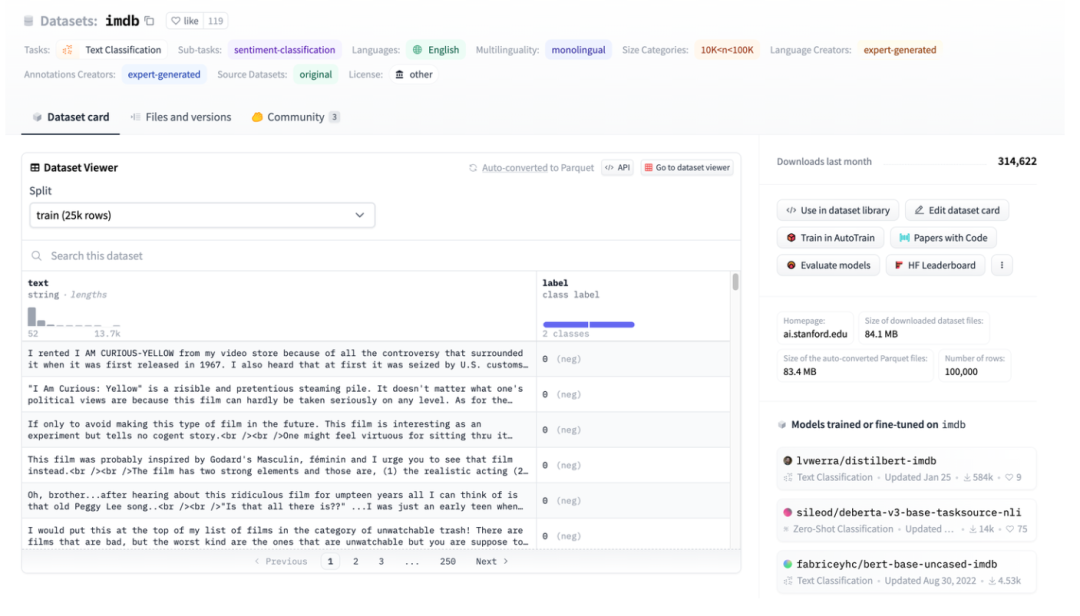 Рисунок 3. Иллюстрация набора данных HuggingFace на примере IMDB.
Рисунок 3. Иллюстрация набора данных HuggingFace на примере IMDB.
На рисунке 3 показан снимок экрана страницы imdb. Вы можете видеть, что данные хорошо структурированы. Затем используйте наборы данных HuggingFace для прямой загрузки, а затем напрямую используйте абстрактный загрузчик данных TextFileDataset для непосредственного чтения обработанных файлов для использования.
Рисунок 4. Интерфейс TextFileDataset.
Вы можете видеть, что TextFileDataset необходимо передать только путь к файлу или список путей для загрузки. Однако во время практической работы я столкнулся с проблемой: наборы данных HuggingFace используют файлы Apache Arrow.
Рисунок 5. Знакомство с форматом стрелок наборов данных HuggingFace.
Apache Arrow[2] — это независимый от языка мультисистемный стандарт высокопроизводительного формата обмена данными, который можно скопировать с нуля. Это означает, что набор данных MindSpore не может быть прочитан напрямую и просто. Хотя им также можно управлять с помощью библиотеки pyarrow, это увеличивает сложность и возвращает состояние, требующее предварительной обработки перед загрузкой. Однако оказывается, что характеристики файлов Arrow больше подходят для набора данных MindSpore.
2. 2 Преимущества формата Arrow
В среде Multiwalker двуногие роботы пытаются нести свой груз и идти вправо. Несколько роботов несут крупный груз, и работать им нужно вместе, как показано на картинке ниже.
HuggingFace использует формат Apache Arrow, который имеет несколько очевидных преимуществ:
1. Стандартный формат Arrow допускает чтение с нулевым копированием, что практически исключает все накладные расходы на сериализацию.
2. Стрелка ориентирована на столбцы, поэтому запросы и обработка фрагментов данных или столбцов данных выполняются быстрее.
3. Arrow обрабатывает каждый набор данных как файл, отображенный в памяти. При доступе к частям данных в большом файле нет необходимости загружать весь файл, и несколько процессов могут совместно использовать память. Отображение памяти позволяет использовать большие наборы данных на машинах с относительно небольшой памятью устройства. Для загрузки полного набора данных английской Википедии требуется всего несколько МБ ОЗУ.
4. При загрузке данных вы можете установить параметры потоковой передачи для потоковой загрузки.
А сейчас давайте вернемся и посмотрим на дизайн механизма данных MindSpore: загрузка по требованию, онлайн-обработка и наборы данных HuggingFace идеально подходят.
2.3 Адаптация MindNLP
Поскольку файл стрелки, загружаемый наборами данных HuggingFace, сам по себе является файлом, отображенным в памяти, нет необходимости копировать его в память, а использование индексного индекса не приведет к его полной загрузке, поэтому его можно напрямую использовать в качестве исходных данных для загрузки и отправлять непосредственно в GeneratorDataset для использования.
Рисунок 6. Интерфейс GeneratorDataset.
Для создания GeneratorDataset в основном требуются исходные данные и имя столбца, соответствующее каждому столбцу данных. Оглядываясь на рисунок 3, вы можете видеть, что HuggingFace Datasets назвал все столбцы. Ниже приведен перехваченный основной код:
from mindspore.dataset import GeneratorDataset
from datasets import load_dataset as hf_load
......
def load_dataset(...):
ds_ret = hf_load(path,
name=name,
data_dir=data_dir,
data_files=data_files,
split=split,
cache_dir=cache_dir,
features=features,
download_config=download_config,
download_mode=download_mode,
verification_mode=verification_mode,
keep_in_memory=keep_in_memory,
save_infos=save_infos,
revision=revision,
streaming=streaming,
num_proc=num_proc,
storage_options=storage_options,
)
if isinstance(ds_ret, (list, tuple)):
ds_dict = dict(zip(split, ds_ret))
else:
ds_dict = ds_ret
datasets_dict = {}
for key, raw_ds in ds_dict.items():
column_names = list(raw_ds.features.keys())
source = TransferDataset(raw_ds, column_names) if isinstance(raw_ds, Dataset) \
else TransferIterableDataset(raw_ds, column_names)
ms_ds = GeneratorDataset(
source=source,
column_names=column_names,
shuffle=shuffle,
num_parallel_workers=num_proc if num_proc else 1)
datasets_dict[key] = ms_ds
if len(datasets_dict) == 1:
return datasets_dict.popitem()[1]
return datasets_dict
Этапы обработки также очень просты:
1. Загрузите с помощью load_dataset наборы данных HuggingFace.
2. Используйте инкапсулированные транзитные классы для инкапсуляции.
3. Передайте GeneratorDataset.
Для простоты использования мы сохраняем настройки параметров интерфейса load_dataset точно такими же, как и у наборов данных HuggingFace, но возвращается класс или Dict, который может обрабатываться механизмом данных MindSpore, чтобы обеспечить плавное соединение возможности обработки данных Shengsi MindSpore могут быть завершены.
Кратко поговорим о структуре транзитного класса.
Типы данных наборов данных HuggingFace включают Dataset и IterableDataset:
Существует два типа объектов набора данных: Dataset и IterableDataset. Какой тип набора данных вы решите использовать или создать, зависит от размера набора данных. В общем, anIterableDataset идеально подходит для больших наборов данных (подумайте о сотнях ГБ!) Из-за его ленивого поведения и преимуществ в скорости, а Dataset отлично подходит для всего остального. На этой странице будут сравниваться различия между Dataset и IterableDataset, чтобы помочь вам выбрать подходящий для вас объект набора данных.[3]
При обходе этих двух типов наборов данных возвращается dict, который не поддерживается механизмом обработки данных MindSpore. Поэтому создаются два класса передачи для чтения данных в dict без добавления других дополнительных операций. Для набора данных создайте класс TransferDataset и прочитайте его в методе __getitem__.
class TransferDataset():
"""TransferDataset for Huggingface Dataset."""
def __init__(self, arrow_ds, column_names):
self.ds = arrow_ds
self.column_names = column_names
def __getitem__(self, index):
return tuple(self.ds[int(index)][name] for name in self.column_names)
def __len__(self):
return self.ds.dataset_size
Для потоковой передачи данных IterableDataset вам необходимо прочитать их в методе __iter__ и построить TransferIterableDataset как итерируемый объект.
class TransferIterableDataset():
"""TransferIterableDataset for Huggingface IterableDataset."""
def __init__(self, arrow_ds, column_names):
self.ds = arrow_ds
self.column_names = column_names
def __iter__(self):
for data in self.ds:
yield tuple(data[name] for name in self.column_names)
На данный момент план, который не требует особых усилий и позволяет полностью использовать наборы данных HuggingFace, завершен. По сравнению с НЛП Паддл стратегия прививки проста и элегантна.
03
в заключение
В качестве платформы с открытым исходным кодом на самом деле можно использовать большое количество ресурсов с открытым исходным кодом. Так называемое постоянное расширение экосистемы север-юг не обязательно означает адаптацию. Я использую ее, вы используете ее, вы используете меня. , и вы счастливы и не беспокоитесь. На этот раз наборы данных HuggingFace включены в практический обмен данными Shengsi MindSpore, что обеспечит более глубокое понимание Shengsi MindNLP, а также поможет расширить экосистему Shengsi MindSpore.
Рекомендации
[1] https://www.mindspore.cn/docs/zh-CN/r2.1/design/data_engine.htm
[3] https://huggingface.co/docs/datasets/about_mapstyle_vs_iterable
Программист, родившийся в 1990-х годах, разработал программу для переноса видео и заработал более 7 миллионов менее чем за год. Концовка была очень суровой! Google подтвердил увольнения, связанные с «проклятием 35-летней давности» китайских программистов в командах Flutter, Dart и . Python Arc Browser для Windows 1.0 через 3 месяца официально Доля рынка Windows 10 достигает 70%, Windows 11 GitHub продолжает снижаться GitHub выпускает собственный инструмент разработки AI GitHub Copilot Workspace JAVA. — единственный запрос строгого типа, который может обрабатывать OLTP+OLAP. Это лучший ORM. Мы встречаемся слишком поздно.