
DolphinDB — это высокопроизводительная распределенная база данных временных рядов с распределенными вычислениями, поддержкой транзакций, многорежимным хранилищем и возможностями потоковой пакетной интеграции. Она очень подходит в качестве идеальной легкой платформы для больших данных, позволяющей легко построить универсальную высокопроизводительную систему. база данных производительности реального времени.
В этом руководстве будут использоваться примеры и сценарии, чтобы показать, как быстро создать хранилище данных в реальном времени с помощью DolphinDB, чтобы помочь различным отраслям (таким как энергетика, аэрокосмическая промышленность, Интернет транспортных средств, нефтехимия, горнодобывающая промышленность, интеллектуальное производство, торговля и государственные дела, финансы и т. д.) Быстро реализуйте комплексный расчет индикаторов с малой задержкой и анализ больших данных в бизнес-сценариях.
Это руководство включает введение в принципы и практические операции, а также вспомогательный пример кода. Пользователи могут следовать этому руководству и комбинировать свои собственные бизнес-характеристики для создания легкого и высокопроизводительного хранилища данных в реальном времени .
1. Введение
1.1 Предыстория дела и потребности
С наступлением эпохи больших данных во всех сферах жизни предъявляются все более высокие требования к оперативности и точности обработки данных. Хотя традиционные автономные хранилища данных могут в определенной степени удовлетворить потребности предприятий в хранении данных и автономном анализе, они часто неспособны обрабатывать крупномасштабные данные в реальном времени. Ограничения автономных хранилищ данных особенно очевидны в ведущих интернет-вещах и финансовых компаниях, которые предъявляют очень высокие требования к данным в реальном времени.
На примере электростанций в электроэнергетике каждая электростанция имеет большое количество точек измерения, которые собирают эксплуатационные данные электростанции в режиме реального времени. Как объединить огромные данные о работе электростанций и провести точные и сложные расчеты и анализ данных в реальном времени, стало серьезной проблемой для электростанций. Традиционным базам данных, работающим в режиме реального времени, не хватает совокупного анализа и вычислительных возможностей для обработки больших объемов данных, в то время как автономные хранилища данных, созданные традиционными системами больших данных, трудно удовлетворить более глубокие потребности бизнеса из-за низкой скорости обработки, больших задержек и сложной архитектуры.
Являясь легким универсальным решением для хранилища данных в реальном времени, DolphinDB стал решением этой проблемы благодаря своей высокопроизводительной среде распределенных вычислений, возможностям потоковой обработки данных в реальном времени, распределенному мультимодальному механизму хранения и технологии вычислений в памяти Ideal. .
В этой статье DolphinDB будет использоваться для реализации типичного сценария спроса на стороне производства электроэнергии. С 40 000 точек измерения, осуществляющих выборку каждую секунду на стороне производства электроэнергии, различные индикаторы точек измерения (максимальное значение, минимальное значение, среднее значение, медиана, квантиль 95%, квантиль 5%, величина изменения, скорость изменения, начальное значение, конечное значение и т. д. .) и получить ответ на запрос на уровне миллисекунд. Эти показатели имеют решающее значение для мониторинга работы электростанции, предупреждения о неисправностях, анализа энергоэффективности, отображения больших данных и т. д. (Для получения дополнительных решений по сценариям для отрасли Интернета вещей добавьте помощника DolphinDB dolphindb1)
1.2 Основные понятия хранилища данных
Хранилище данных (сокращенно DW или DWH) — это система, используемая для хранения, обработки и анализа больших объемов данных, предназначенная для поддержки процесса принятия решений в конкретных бизнес-сценариях. Хранилище данных также представляет собой техническую архитектуру, которая может собирать и интегрировать разнородные данные (например, таблицы данных, Json, CSV, Protobuf и т. д.) из нескольких источников данных (таких как MySQL, Oracle, MongoDB, HBase и т. д.) через данные. очистка, интеграция и преобразование, интеграция данных в единую систему хранения (например, DolphinDB, Hadoop) для поддержки многомерного бизнес-анализа, интеллектуального анализа данных и точного принятия решений.
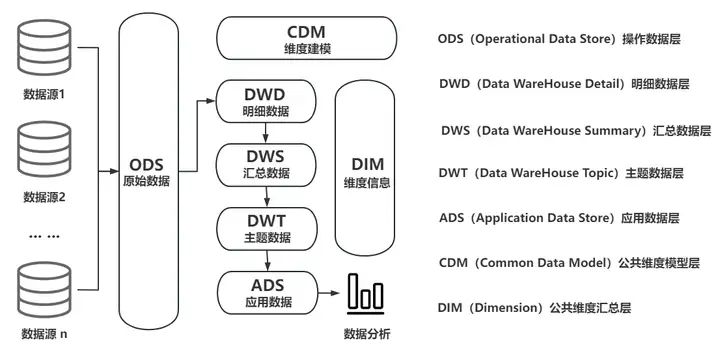
1.1 Типичная схема архитектуры традиционного хранилища данных
Важность хранилища данных заключается в его способности помочь предприятиям обеспечить централизованное управление и эффективное использование данных. Его можно разделить на два типа: автономное хранилище данных и хранилище данных в реальном времени в зависимости от его назначения и характера работы в реальном времени.
Автономные хранилища данных обычно реализуются по принципу Т-1, то есть исторические данные предыдущего дня импортируются в хранилище данных посредством рабочих задач каждый день в определенное время (например, ранним утром), а затем массивные исторические данные ( пакетные данные) анализируются с помощью OLAP (онлайн-аналитическая обработка).
Для большинства предприятий существует острая необходимость в T+0 для реализации контроля рисков в реальном времени, анализа эффектов в реальном времени, управления процессами в реальном времени и других функций в бизнесе. Традиционные автономные хранилища данных не могут удовлетворить требования реального времени, поэтому появилась новая архитектура хранилища данных, учитывающая возможности реального времени и аналитические возможности, то есть хранилища данных реального времени.
Технические требования и сложность реализации хранилищ данных реального времени намного превосходят требования традиционных хранилищ данных. По сравнению с традиционными хранилищами данных хранилища данных реального времени могут иметь более эффективные возможности обработки данных и частоту обновления данных в реальном времени (квазиреальном времени). В соответствии с требованиями к производительности с малой задержкой необходимо решить технические проблемы, такие как неоднородность источников данных, контроль качества данных, транзакции и строгая согласованность, многорежимное хранилище и высокопроизводительный агрегирующий анализ. Более того, как предоставить обычным разработчикам возможность разработки, эксплуатации и обслуживания хранилищ данных в реальном времени, а также непрерывно и стабильно выполнять итерации продукта, также является очень большим испытанием.
1.3 Типичная архитектура традиционного хранилища данных реального времени
Традиционные хранилища данных реального времени обычно основаны на платформе больших данных Hadoop и используют архитектуру Lambda или архитектуру Kappa. Технология сложна, а цикл разработки длительный, что является огромным бременем для предприятий с точки зрения затрат на разработку, затрат времени и инвестиций в оборудование.
Типичный технологический стек традиционного хранилища данных реального времени выглядит следующим образом:
- Коллекция (Sqoop, Flume, Flink CDC, DataX, Kafka)
- Хранилище (HBase, HDFS, Hive, MySQL, MongoDB)
- Обработка данных и вычисления (Hive, Spark, Flink, Storm, Presto)
- OLAP-анализ и запросы (TSDB/HTAP, ES, Kylin, DorisDB)
Если предприятия захотят внедрить традиционные хранилища данных в реальном времени, они столкнутся со многими проблемами, такими как высокие затраты на обучение, большое потребление ресурсов, а также недостаточная масштабируемость и производительность в реальном времени.
1.4 Архитектура и производительность хранилища данных DolphinDB в режиме реального времени
В отличие от сложных традиционных хранилищ данных реального времени, DolphinDB может быстро реализовать облегченные хранилища данных реального времени благодаря возможностям собственного продукта. Он может независимо выполнять сбор, хранение, потоковые вычисления, ETL, анализ и расчет решений, а также визуальное отображение. Его также можно использовать в качестве эффективного дополнения к различным сторонним приложениям, развернутым на предприятии (таким как платформа больших данных, промежуточная платформа искусственного интеллекта, панель управления), для обеспечения технической поддержки хранилища данных в реальном времени для систем приложений корпоративного уровня и групповых задач. средние платформы данных уровня для достижения более сложных сценариев применения.
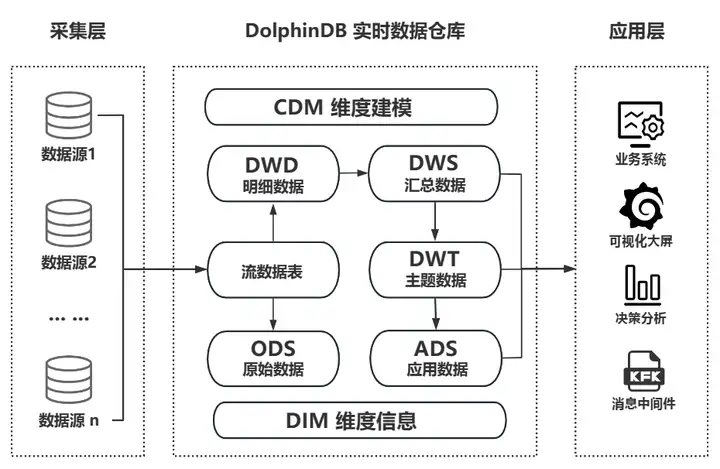
Схема бизнес-архитектуры хранилища данных DolphinDB в реальном времени
DolphinDB имеет богатые и проверенные примеры практики хранения данных в различных отраслях, таких как Интернет вещей и финансы, что полностью демонстрирует его обширную прикладную ценность.
Если взять в качестве примера проект хранилища данных в реальном времени провинциальной таможенной электронной портовой компании, то хранилище данных в реальном времени, созданное DolphinDB, полностью использует преимущества легкого универсального продукта All In One. Он поддерживает доступ к разнородным данным из нескольких источников, совместим со стандартным SQL, поддерживает сложные многотабличные ассоциации и обладает мощными возможностями очистки данных ETL, что значительно сокращает цепочку обработки данных и снижает затраты на эксплуатацию, обслуживание и разработку. Его бизнес-структура и технические характеристики показаны на рисунке ниже:
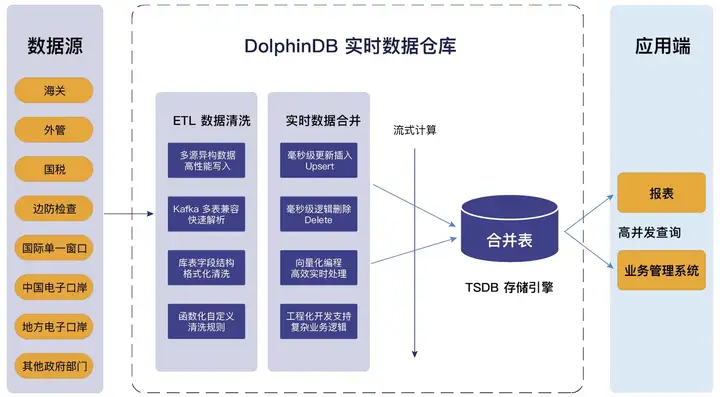
Схема бизнес-структуры проекта электронного хранилища данных в реальном времени в провинциальном порту
Ниже приводится ссылка на показатели производительности хранилища данных в реальном времени, которые DolphinDB может поддерживать при развертывании кластера высокой доступности из трех компьютеров:
- Количество поддерживаемых точек измерения: >100 миллионов точек измерения.
- Пропускная способность записи: > 100 миллионов точек измерения в секунду
- Количество записей, поддерживаемых ODS: > 1 триллиона
- Максимальное количество клиентских подключений: >5000
- Параллельные запросы (QPS): >5000
- Многомерный агрегирующий запрос: уровень миллисекунд
- Извлечение значения функции потокового вычисления в реальном времени: > 500 000 в секунду
- Время синхронизации для удаления и изменения (мягкое удаление, обновление) одной записи и одного процесса: ≈ 10 мс
- Кластер высокой доступности: несколько копий (высокая доступность данных), несколько узлов управления (высокая доступность метаданных), повторное подключение при отключении клиента и аварийное переключение (высокая доступность клиента).
- Эластичное расширение: горизонтальное расширение (добавление узлов) без простоя, вертикальное расширение (добавление дисковых томов) без простоя и поддержка обновлений в оттенках серого.
2. Практика хранения данных DolphinDB в режиме реального времени
Далее мы будем использовать DolphinDB для создания легкого хранилища данных в реальном времени, используя в качестве примера реальные потребности мониторинга генераторного оборудования гидроэлектростанций в реальном времени. Этот случай можно применить к энергетике, промышленному Интернету вещей, Интернету транспортных средств и другим отраслям.
Приглашаем всех попробовать и убедиться вместе!
2.1 Установка и развертывание DolphinDB
1. Загрузите последнюю версию официального сайта сообщества, рекомендуется версия 2.00.11 или выше.
Портал: https://cdn.dolphindb.cn/downloads/DolphinDB_Win64_V2.00.11.3.zip
2. В пути распаковки Windows не должно быть пробелов, чтобы избежать установки в путь к Program Files.
Официальное руководство на сайте: https://docs.dolphindb.cn/zh/tutorials/deploy_dolphindb_on_new_server.htm l
3. В этом тесте используется корпоративная версия, и вы можете подать заявку на бесплатную пробную лицензию. Если вы используете бесплатную версию сообщества, рекомендуется снизить уровень данных теста.
Как получить: https://dolphindb.cn/product# загрузки.
4. Если в процессе установки и тестирования у вас возникнут вопросы, вы можете в фоновом режиме отправить личное сообщение для консультации.
2.2 Требования к индикаторам хранилища данных в реальном времени
- Ситуация с основными данными
Количество точек измерения: 40000
Частота выборки: секунды
- Расчетный показатель (агрегированное значение)

2.3 Практическое планирование плана
На основе платформы потоковых вычислений DolphinDB создается легкое периферийное хранилище данных в реальном времени. Все результаты вычислений эффективно обрабатываются во время записи данных, а задержка контролируется на уровне миллисекунд.
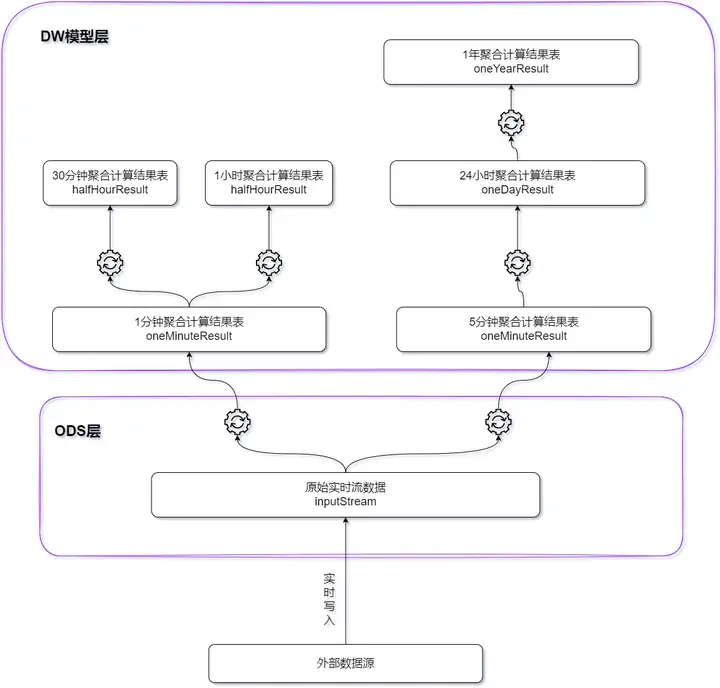
- Для индикаторов с периодом расчета 1 минута и периодом расчета 5 минут в качестве базовой таблицы используются исходные данные реального времени;
- Для индикаторов с периодом расчета 30 минут и периодом расчета 1 час в качестве базовой таблицы используется результат расчета 1 минута;
- Для индикаторов 24-часового цикла расчета в качестве базовой таблицы используется результат расчета за 5 минут;
- Для показателей с годовым периодом расчета в качестве базовой таблицы используются результаты расчета за 24 часа.
Окно расчета и размер скользящего шага каждого типа индикатора показаны в следующей таблице:
| Цикл расчета | длина окна | размер скользящего шага | Примечание |
|---|---|---|---|
| 1 минута | 1 минута | 1 минута | Каждую 1 минуту рассчитываются значения в окне за последнюю минуту. |
| 5 минут | 5 минут | 5 минут | Каждые 5 минут рассчитываются значения за последние 5 минут. |
| 30 минут | 30 минут | 30 минут | Каждые 30 минут рассчитываются значения за последние 30 минут. |
| 1 час | 1 час | 1 час | Каждый 1 час рассчитываются значения в пределах окна за последний 1 час. |
| 24 часа | 24 часа | 24 часа | Каждые 24 часа рассчитываются значения за последние 24 часа. |
| 1 год | 1 год | 24 часа | Каждый 1 день рассчитываются значения в пределах окна за последний год. |
3. Тестирование производительности и результаты
3.1 Тестовая среда
Чтобы облегчить тестирование и проверку, для реализации легкого хранилища данных в реальном времени используется метод развертывания с одним компьютером и одним узлом. Конфигурация сервера следующая:
- Процессор: 12 ядер
- Память: 32 ГБ
- Диск: жесткий диск 1,1 Тб, 150 МБ/с.
Используйте сценарий для моделирования данных в реальном времени всех точек измерения (40 000) в течение 24 часов (2023.01.01T00:00:00-2023.01.02T00:00:01.000) и выполните 1 минуту, 5 минут, 30 минут, 1 час и 24 часа. Выполняются агрегированные вычисления окон, и результаты вычислений записываются в распределенную базу данных. (В определенном окне количество элементов данных может быть меньше длины окна)
Для расчета 1-летнего окна также моделируются данные в реальном времени о результатах расчета 24-часового окна, а результаты моделирования агрегируются и рассчитываются в реальном времени.
Подробный сценарий тестирования включен во вложение в конце статьи.
3.2 Результаты испытаний
Результаты теста производительности показаны в таблице ниже:
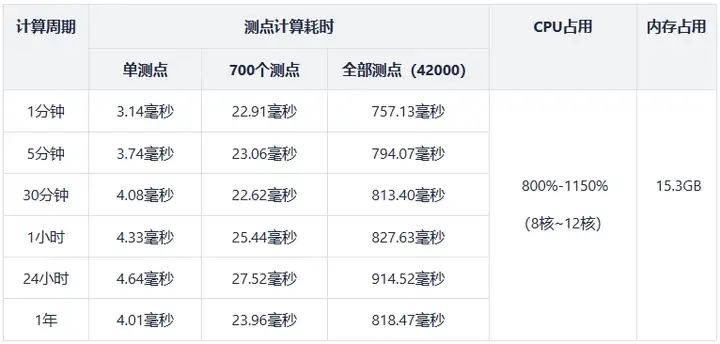
Примечание. В приведенной выше таблице время расчета для всех точек измерения — это время расчета показателей всех точек измерения во временном окне время расчета для одной/нескольких точек измерения — это время расчета показателей выбранного измерения; точки во временном окне.
4. Резюме
Благодаря изучению и практике этого руководства мы получили глубокое понимание мощных возможностей DolphinDB в создании легких хранилищ данных в реальном времени. Благодаря своим высокопроизводительным, распределенным вычислительным характеристикам в реальном времени DolphinDB предоставляет различным отраслям мощный инструмент для быстрого выполнения вычислений с малой задержкой и анализа сложных показателей на больших объемах данных.
На практике мы можем убедиться в простоте использования и эффективности DolphinDB. Будь то импорт данных, запрос данных или сложные потоковые вычисления, DolphinDB предоставляет краткий и понятный синтаксис и мощные функции. Скрипт, представленный во вложении, не только включает в себя основные методы использования и работы DolphinDB, но также обеспечивает глубокое понимание принципов построения и сценариев применения хранилища данных реального времени. Это позволяет нам быстро построить хранилище данных в режиме реального времени, отвечающее потребностям бизнеса, и реагировать на различные сложные потребности анализа в режиме реального времени.
Наконец, я надеюсь, что читатели смогут объединить пример кода из этого руководства с собственными бизнес-характеристиками, чтобы создать легкое и высокопроизводительное хранилище данных, работающее в режиме реального времени. В практических приложениях потенциал DolphinDB постоянно исследуется. Будь то энергетика, нефтехимическая промышленность, интеллектуальное производство, аэрокосмическая промышленность, Интернет транспортных средств, финансы и другие отрасли, DolphinDB может обеспечить надежную поддержку широкого спектра реальных приложений. Хранилища данных времени.
5. Аксессуары
Результаты теста можно воспроизвести на сервере DolphinDB с помощью следующего скрипта:
def clearEnv(){
//取消订阅
unsubscribeTable(tableName=`inputStream, actionName="dispatch1")
unsubscribeTable(tableName=`inputStream, actionName="dispatch2")
unsubscribeTable(tableName=`oneMinuteResult, actionName="calcHalfHour")
unsubscribeTable(tableName=`oneMinuteResult, actionName="calcOneHour")
unsubscribeTable(tableName=`fiveMinuteResult, actionName="calcOneDay")
unsubscribeTable(tableName = `oneDayResultSimulate,actionName=`calcOneYear)
unsubscribeTable(tableName = `oneMinuteResult,actionName=`appendInToDFS)
unsubscribeTable(tableName = `fiveMinuteResult,actionName=`appendInToDFS)
unsubscribeTable(tableName = `halfHourResult,actionName=`appendInToDFS)
unsubscribeTable(tableName = `oneHourResult,actionName=`appendInToDFS)
unsubscribeTable(tableName = `oneDayResult,actionName=`appendInToDFS)
unsubscribeTable(tableName = `oneYearResult,actionName=`appendInToDFS)
//删除流计算引擎
for(i in 1..2){
try{dropStreamEngine(`dispatchDemo+string(i))}catch(ex){print(ex)}
}
for(i in 1..5){
try{dropStreamEngine(`oneMinuteCalc+string(i))}catch(ex){print(ex)}
try{dropStreamEngine(`fiveMinuteCalc+string(i))}catch(ex){print(ex)}
}
try{dropStreamEngine(`halfHourCalc)}catch(ex){print(ex)}
try{dropStreamEngine(`oneHourCalc)}catch(ex){print(ex)}
try{dropStreamEngine(`oneDayCalc)}catch(ex){print(ex)}
try{dropStreamEngine(`oneYearCalc)}catch(ex){print(ex)}
//删除流数据表
try{dropStreamTable(`inputStream)}catch(ex){print(ex)}
try{dropStreamTable(`oneMinuteResult)}catch(ex){print(ex)}
try{dropStreamTable(`fiveMinuteResult)}catch(ex){print(ex)}
try{dropStreamTable(`halfHourResult)}catch(ex){print(ex)}
try{dropStreamTable(`oneHourResult)}catch(ex){print(ex)}
try{dropStreamTable(`oneDayResult)}catch(ex){print(ex)}
try{dropStreamTable(`oneDayResultSimulate)}catch(ex){print(ex)}
try{dropStreamTable(`oneYearResult)}catch(ex){print(ex)}
}
def createStreamTable(){
//定义输入流表
enableTableShareAndPersistence(table = streamTable(1000:0,`Time`deviceId`value,`TIMESTAMP`SYMBOL`DOUBLE),
tableName = `inputStream,cacheSize = 1000000,precache=1000000)
colName = `Time`deviceId`filterTime`MAX`MIN`MEAN`MED`P95`P5`CHANGE`CHANGE_RATE`first`last`endTime
colType = `TIMESTAMP`SYMBOL`NANOTIMESTAMP join take(`DOUBLE,10) join `NANOTIMESTAMP
//定义1分钟窗口计算结果流表
enableTableShareAndPersistence(table = streamTable(1000:0,colName,colType),
tableName = `oneMinuteResult,cacheSize = 1000000,precache=1000000)
//定义5分钟窗口计算结果流表
enableTableShareAndPersistence(table = streamTable(1000:0,colName,colType),
tableName = `fiveMinuteResult,cacheSize = 1000000,precache=1000000)
//定义30分钟窗口计算结果流表
enableTableShareAndPersistence(table = streamTable(1000:0,colName,colType),
tableName = `halfHourResult,cacheSize = 1000000,precache=1000000)
//定义1小时窗口计算结果流表
enableTableShareAndPersistence(table = streamTable(1000:0,colName,colType),
tableName = `oneHourResult,cacheSize = 1000000,precache=1000000)
//定义24小时窗口计算结果流表
enableTableShareAndPersistence(table = streamTable(1000:0,colName,colType),
tableName = `oneDayResult,cacheSize = 1000000,precache=1000000)
//定义模拟24小时窗口计算结果流表
colName = `TIME`deviceId`MAX`MIN`MEAN`MED`P95`P5`CHANGE`CHANGE_RATE`first`last
colType = `DATE`SYMBOL join take(`DOUBLE,10)
enableTableShareAndPersistence(table = streamTable(1000:0,colName,colType),
tableName = `oneDayResultSimulate,cacheSize = 1000000,precache=1000000)
//定义1年窗口计算结果流表
colName = `Time`deviceId`filterTime`MAX`MIN`MEAN`MED`P95`P5`CHANGE`CHANGE_RATE`first`last`endTime
colType = `DATE`SYMBOL`NANOTIMESTAMP join take(`DOUBLE,10) join `NANOTIMESTAMP
enableTableShareAndPersistence(table = streamTable(1000:0,colName,colType),
tableName = `oneYearResult,cacheSize = 1000000,precache=1000000)
}
def createDFS(){
//创建存储计算1分钟窗口计算结果表
if(existsDatabase("dfs://oneMinuteCalc")){dropDatabase("dfs://oneMinuteCalc")}
db1 = database(, VALUE,2023.01.01..2023.01.03)
db2 = database(, HASH,[SYMBOL,20])
db = database(directory="dfs://oneMinuteCalc", partitionType=COMPO, partitionScheme=[db1,db2],engine="TSDB")
colName = `Time`deviceId`filterTime`MAX`MIN`MEAN`MED`P95`P5`CHANGE`CHANGE_RATE`first`last`endTime
colType = `TIMESTAMP`SYMBOL`NANOTIMESTAMP join take(`DOUBLE,10) join `NANOTIMESTAMP
t = table(1:0,colName,colType)
pt = db.createPartitionedTable(table=t,tableName ="test" ,partitionColumns = ["Time","deviceId"],
sortColumns =["deviceId","Time"],compressMethods={Time:"delta"})
//创建存储计算5分钟窗口计算结果表
if(existsDatabase("dfs://fiveMinuteCalc")){dropDatabase("dfs://fiveMinuteCalc")}
db = database(directory="dfs://fiveMinuteCalc", partitionType=VALUE,
partitionScheme=2023.01.01..2023.01.03,engine="TSDB")
t = table(1:0,colName,colType)
pt = db.createPartitionedTable(table=t,tableName ="test" ,partitionColumns = ["Time"],
sortColumns =["deviceId","Time"],compressMethods={Time:"delta"},
sortKeyMappingFunction=[hashBucket{,100}])
//创建存储计算30分钟窗口计算结果表
if(existsDatabase("dfs://halfHourCalc")){dropDatabase("dfs://halfHourCalc")}
db = database(directory="dfs://halfHourCalc", partitionType=VALUE,
partitionScheme=2023.01.01..2023.01.03,engine="TSDB")
t = table(1:0,colName,colType)
pt = db.createPartitionedTable(table=t,tableName ="test" ,partitionColumns = ["Time"],
sortColumns =["deviceId","Time"],compressMethods={Time:"delta"})
//创建存储计算1小时窗口计算结果表
if(existsDatabase("dfs://oneHourCalc")){dropDatabase("dfs://oneHourCalc")}
db = database(directory="dfs://oneHourCalc", partitionType=VALUE,
partitionScheme=2023.01.01..2023.01.03,engine="TSDB")
t = table(1:0,colName,colType)
pt = db.createPartitionedTable(table=t,tableName ="test" ,partitionColumns = ["Time"],
sortColumns =["deviceId","Time"],compressMethods={Time:"delta"})
//创建存储计算24小时窗口计算结果表
if(existsDatabase("dfs://oneDayCalc")){dropDatabase("dfs://oneDayCalc")}
db = database(directory="dfs://oneDayCalc", partitionType=VALUE,
partitionScheme=2023.01.01..2023.01.03,engine="TSDB")
t = table(1:0,colName,colType)
pt = db.createPartitionedTable(table=t,tableName ="test" ,partitionColumns = ["Time"],
sortColumns =["deviceId","Time"],compressMethods={Time:"delta"})
//创建存储计算1年窗口计算结果表
if(existsDatabase("dfs://oneYearCalc")){dropDatabase("dfs://oneYearCalc")}
db = database(directory="dfs://oneYearCalc", partitionType=VALUE,
partitionScheme=2023.01.01..2023.01.03,engine="TSDB")
t = table(1:0,colName,colType)
pt = db.createPartitionedTable(table=t,tableName ="test" ,partitionColumns = ["Time"],
sortColumns =["deviceId","Time"],compressMethods={Time:"delta"})
}
//1分钟窗口计算过滤函数
def filter1(msg){
t = select *,now(true) as filterTime from msg
getStreamEngine(`dispatchDemo1).append!(t)
}
//5分钟窗口计算过滤函数
def filter2(msg){
t = select *,now(true) as filterTime from msg
getStreamEngine(`dispatchDemo2).append!(t)
}
//30分钟窗口计算过滤函数
def filter3(msg){
t = select *,now(true) as filterTime2 from msg
getStreamEngine(`halfHourCalc).append!(t)
}
//1小时窗口计算
def filter4(msg){
t = select *,now(true) as filterTime2 from msg
getStreamEngine(`oneHourCalc).append!(t)
}
//24小时窗口计算
def filter5(msg){
t = select *,now(true) as filterTime2 from msg
getStreamEngine(`oneDayCalc).append!(t)
}
clearEnv();
createStreamTable();
createDFS();
schemas1 = table(1:0,`Time`deviceId`value`filterTime,`TIMESTAMP`SYMBOL`DOUBLE`NANOTIMESTAMP)
metrics1 = <[first(filterTime),max(value),min(value),mean(value),med(value),percentile(value,95),
percentile(value,5),last(value)-first(value),
(last(value)-first(value))/first(value),first(value),last(value),now(true)]>
//创建1分钟窗口聚合计算引擎
for(i in 1..5){
engine1 = createTimeSeriesEngine(name="oneMinuteCalc"+string(i), windowSize=60000, step=60000,
metrics=metrics1 , dummyTable=schemas1 , outputTable=objByName(`oneMinuteResult),
timeColumn = `Time, useSystemTime=false, keyColumn = `deviceId)
}
//创建5分钟窗口聚合计算引擎
for(i in 1..5){
engine2 = createTimeSeriesEngine(name="fiveMinuteCalc"+string(i), windowSize=300000, step=300000,
metrics=metrics1 , dummyTable=schemas1 , outputTable=objByName(`fiveMinuteResult),
timeColumn = `Time, useSystemTime=false, keyColumn = `deviceId)
}
//1分钟、5分钟窗口聚合计算分发引擎
dispatchEngine1=createStreamDispatchEngine(name="dispatchDemo1", dummyTable=schemas1, keyColumn=`deviceId,
outputTable=[getStreamEngine("oneMinuteCalc1"),getStreamEngine("oneMinuteCalc2"),
getStreamEngine("oneMinuteCalc3"),getStreamEngine("oneMinuteCalc4"),
getStreamEngine("oneMinuteCalc5")])
dispatchEngine2=createStreamDispatchEngine(name="dispatchDemo2", dummyTable=schemas1, keyColumn=`deviceId,
outputTable=[getStreamEngine("fiveMinuteCalc1"),getStreamEngine("fiveMinuteCalc2"),
getStreamEngine("fiveMinuteCalc3"),getStreamEngine("fiveMinuteCalc4"),
getStreamEngine("fiveMinuteCalc5")])
colName = `Time`deviceId`filterTime`MAX`MIN`MEAN`MED`P95`P5`CHANGE`CHANGE_RATE`first`last`endTime`filterTime2
colType = `TIMESTAMP`SYMBOL`NANOTIMESTAMP join take(`DOUBLE,10) join `NANOTIMESTAMP`NANOTIMESTAMP
schemas2 = table(1:0,colName,colType)
metrics2 = <[first(filterTime2),max(MAX),min(MIN),mean(MEAN),med(MED),avg(P95),avg(P5),last(last)-first(first),
(last(last)-first(first))/first(first),first(first),last(last),now(true)]>
//创建30分钟窗口聚合计算引擎
engine3 = createTimeSeriesEngine(name="halfHourCalc", windowSize=1800000, step=1800000, metrics=metrics2 ,
dummyTable=schemas2 , outputTable=objByName(`halfHourResult),
timeColumn = `Time, useSystemTime=false, keyColumn = `deviceId)
//创建1小时窗口聚合计算引擎
engine4 = createTimeSeriesEngine(name="oneHourCalc", windowSize=3600000, step=3600000, metrics=metrics2 ,
dummyTable=schemas2 , outputTable=objByName(`oneHourResult),
timeColumn = `Time, useSystemTime=false, keyColumn = `deviceId)
//创建24小时窗口聚合计算引擎
engine5 = createTimeSeriesEngine(name="oneDayCalc", windowSize=86400000, step=86400000,
metrics=metrics2 , dummyTable=schemas2 , outputTable=objByName(`oneDayResult),
timeColumn = `Time, useSystemTime=false, keyColumn = `deviceId)
//订阅
subscribeTable(tableName=`inputStream, actionName="dispatch1", handler=filter1, msgAsTable = true,
batchSize = 10240)
subscribeTable(tableName=`inputStream, actionName="dispatch2", handler=filter2, msgAsTable = true,
batchSize = 10240)
subscribeTable(tableName=`oneMinuteResult, actionName="calcHalfHour", handler=filter3,
msgAsTable = true,batchSize = 10240)
subscribeTable(tableName=`oneMinuteResult, actionName="calcOneHour", handler=filter4,
msgAsTable = true,batchSize = 10240)
subscribeTable(tableName=`fiveMinuteResult, actionName="calcOneDay", handler=filter5,
msgAsTable = true,batchSize = 10240)
subscribeTable(tableName = `oneMinuteResult,actionName=`appendInToDFS,offset=0,
handler=loadTable("dfs://oneMinuteCalc","test"),
msgAsTable=true,batchSize=10240)
subscribeTable(tableName = `fiveMinuteResult,actionName=`appendInToDFS,offset=0,
handler=loadTable("dfs://fiveMinuteCalc","test"),
msgAsTable=true,batchSize=10240)
subscribeTable(tableName = `halfHourResult,actionName=`appendInToDFS,offset=0,
handler=loadTable("dfs://halfHourCalc","test"),
msgAsTable=true,batchSize=10240)
subscribeTable(tableName = `oneHourResult,actionName=`appendInToDFS,offset=0,
handler=loadTable("dfs://oneHourCalc","test"),
msgAsTable=true,batchSize=10240)
subscribeTable(tableName = `oneDayResult,actionName=`appendInToDFS,offset=0,
handler=loadTable("dfs://oneDayCalc","test"),
msgAsTable=true,batchSize=10240)
def filter6(msg){
tmp = select * ,now(true) as filterTime from msg
getStreamEngine(`oneYearCalc).append!(tmp)
}
colName = `Time`deviceId`MAX`MIN`MEAN`MED`P95`P5`CHANGE`CHANGE_RATE`first`last`filterTime
colType = `DATE`SYMBOL join take(`DOUBLE,10) join `NANOTIMESTAMP
schemas3 = table(1:0,colName,colType)
metrics3 = <[last(filterTime),max(MAX),min(MIN),mean(MEAN),med(MED),avg(P95),avg(P5),last(last)-first(first),
(last(last)-first(first))/first(first),first(first),last(last),now(true)]>
engine6 = createTimeSeriesEngine(name="oneYearCalc", windowSize=365, step=1, metrics=metrics3 ,
dummyTable=schemas3 , outputTable=objByName(`oneYearResult),
timeColumn = `Time, useSystemTime=false, keyColumn = `deviceId)
subscribeTable(tableName = `oneDayResultSimulate,actionName=`calcOneYear, handler=filter6,
msgAsTable = true,batchSize = 10240)
subscribeTable(tableName = `oneYearResult,actionName=`appendInToDFS,offset=0,
handler=loadTable("dfs://oneYearCalc","test"),
msgAsTable=true)
deviceIdList = lapd(string(rand(10000,700)),6,"0") //测点id
//模拟数据的函数,一共模拟1小时的数据
def simulateData(deviceIdList){
num = deviceIdList.size()
startTime = timestamp(2023.01.01)
do{
Time = take(startTime,num)
deviceId = deviceIdList
value = rand(100.0,num)
objByName(`inputStream).append!(table(Time,deviceId,value))
startTime = startTime+1000
sleep(100)
}while(startTime<=2023.01.02T00:00:10.000)
}
def simulateOneDay(deviceIdList){
num = deviceIdList.size()
startTime =2022.01.01
do{
Time = take(startTime,num)
deviceId = deviceIdList
MAX = rand(100.0,num)
MIN = rand(100.0,num)
MEAN = rand(100.0,num)
MED = rand(100.0,num)
P95 = rand(100.0,num)
P5 = rand(100.0,num)
CHANGE = rand(100.0,num)
CHANGE_RATE = rand(100.0,num)
first = rand(100.0,num)
last = rand(100.0,num)
tmp = table(Time,deviceId,MAX,MIN,MEAN,MED,P95,P5,CHANGE,CHANGE_RATE,first,last)
objByName(`oneDayResultSimulate).append!(tmp)
startTime = startTime+1
sleep(500)
}while(startTime<=2023.12.31)
}
submitJob("simulateData","write",simulateData,deviceIdList)
submitJob("simulateOneDay","write",simulateOneDay,deviceIdList)
//耗时统计
tmp1 = select Time,deviceId,filterTime,endTime from loadTable("dfs://oneYearCalc","test") order by Time,deviceId
tmp2 = select Time,deviceId,next(filterTime) as startTime,endTime from tmp1 context by deviceId
select avg(endTime-startTime)\1000\1000 as timeUsed from tmp2 group by deviceId //统计单个测点的计算耗时
tmp3 = select min(startTime) as st,max(endTime) as dt from tmp2 group by Time
select (dt-st)\1000\1000 as used from tmp3 //统计整个时间窗口的计算耗时