
Spark — это быстрый, универсальный и масштабируемый механизм обработки больших данных . Он обладает такими преимуществами, как высокая производительность, простота использования, отказоустойчивость, бесшовная интеграция с экосистемой Hadoop и высокая активность сообщества. В реальном использовании он имеет широкий спектр сценариев применения:
· Очистка и предварительная обработка данных. В сценариях анализа больших данных данные обычно требуют операций очистки и предварительной обработки, чтобы обеспечить качество и согласованность данных. Spark предоставляет богатый API, который может очищать, фильтровать, преобразовывать и выполнять другие операции с данными.
· Анализ пакетной обработки: Spark подходит для задач пакетной обработки в различных сценариях приложений, включая статистический анализ, интеллектуальный анализ данных, извлечение функций и т. д. Пользователи могут использовать мощный API Spark и встроенные библиотеки для выполнения сложной обработки и анализа данных для анализа данных. внутренняя ценность в
· Интерактивный запрос: Spark предоставляет модуль Spark SQL , который поддерживает запросы SQL . Пользователи могут использовать стандартные операторы SQL для интерактивных запросов и крупномасштабного анализа данных.
Использование Искры в Облаке Кенгуру
В платформе автономной разработки Kangaroo Cloud Stack мы предоставляем три способа использования Spark:
● Создание задач Spark SQL.
Пользователи могут реализовать свою собственную бизнес-логику напрямую, написав SQL. В настоящее время этот метод является наиболее широко используемым способом использования Spark на автономной платформе стека данных, а также наиболее рекомендуемым методом.
● Создать задачу Spark Jar.
Пользователям необходимо использовать язык Scala или Java для реализации бизнес-логики в IDEA, затем скомпилировать и упаковать проект, загрузить полученный пакет Jar на автономную платформу, затем ссылаться на этот пакет Jar при создании задачи Spark Jar и, наконец, отправить задачу. перейти к запланированному запуску.
Для требований, которые трудно достичь или выразить с помощью SQL, или у пользователей есть другие более глубокие требования, задачи Spark Jar , несомненно, предоставляют пользователям более гибкий способ использования Spark.
● Создание задач PySpark.
Пользователи могут напрямую писать соответствующий код Python . Среди нашей клиентской базы немало клиентов, для которых, помимо SQL, основным языком может быть Python. Специально для пользователей с определенными основами анализа данных и алгоритмов они часто проводят более глубокий анализ обработанных данных. В настоящее время задачи PySpark, естественно, являются их лучшим выбором.
Spark играет важную роль в автономной платформе разработки Kangaroo Cloud Data Stack . Поэтому мы внесли в Spark множество внутренних оптимизаций, чтобы клиентам было удобнее отправлять задачи с помощью Spark. Мы также создали несколько инструментов на основе Spark для расширения функциональности всей платформы автономной разработки стека данных.
Кроме того, Spark также играет очень важную роль в сценарии озера данных. Интегрированный модуль озер и хранилищ Kangaroo Cloud уже поддерживает два основных озера данных: Iceberg и Hudi. Пользователи могут использовать Spark для чтения и записи таблиц озер. Нижний уровень управления таблицами озер также реализован с помощью Spark для вызова различных хранимых процедур.
Ниже будет объяснена оптимизация, выполненная внутри Kangaroo Cloud как со стороны движка, так и со стороны самого Spark.
Оптимизация двигателя
Функции внутреннего механизма Kangaroo Cloud в основном используются для отправки задач, получения статуса задачи, сбора журнала задач, остановки задач, проверки синтаксиса и т. д. Мы в разной степени оптимизировали каждую функцию. Ниже приводится краткое введение на двух примерах.
Улучшена скорость отправки Spark on Yarn.
В связи с постоянным развитием и улучшением новых функций подключаемого модуля Spark время, необходимое стороне механизма для отправки задач Spark, также соответственно увеличивается. Поэтому код, связанный с отправкой задач Spark, необходимо оптимизировать. сократить время отправки задач Spark. Улучшить взаимодействие с пользователем.
С этой целью мы проделали следующую работу. Для некоторых распространенных файлов конфигурации, таких как core-site.xml, Yarn-site.xml, файл keytab, spark-sql-application.jar и т. д., получается, что каждый из них. Когда вы отправляете задачу, вам необходимо загрузить ее с сервера. Сервер загружает и отправляет эти файлы конфигурации. Теперь после оптимизации указанный выше файл необходимо загрузить только один раз при инициализации клиента SparkYarnClient , а затем загрузить по указанному пути HDFS. Последующую отправку задач Spark необходимо указать только по соответствующему пути HDFS через параметры. Таким образом, время отправки каждой задачи Spark значительно сокращается.
В новой версии стека данных для временных запросов мы также будем оценивать сложность выполняемого SQL на основе пользовательских правил и отправлять менее сложный SQL в SparkSQLEngine, запущенный на стороне движка , чтобы ускорить работу. Этот внутренний SparkSQLEngine раньше использовался только для проверки синтаксиса, но теперь он также берет на себя часть функции выполнения SQL, и SparkSQLEngine также может динамически расширять и сжимать ресурсы в соответствии с общей рабочей ситуацией для достижения эффективного использования ресурсов.
Проверка грамматики
В более старых версиях стека данных для проверки синтаксиса SQL механизм сначала отправляет SQL на Spark Thrift Server. Этот сервер Spark Thrift развертывается в локальном режиме и используется не только для проверки синтаксиса. Все метаданные на других платформах получаются путем отправки SQL на этот сервер Spark Thrift для выполнения. У этого метода есть серьезные недостатки, поэтому мы внесли некоторые оптимизации. Задача Spark запускается в локальном режиме на стороне Engine . При выполнении проверки синтаксиса SQL-запрос больше не отправляется на Spark Thrift Server. Вместо этого SparkSession поддерживается внутри системы для непосредственного выполнения проверки синтаксиса SQL.
Хотя этот метод не требует прочного соединения с внешним сервером Spark Thrift, он оказывает определенное давление на компонент планирования, а общая сложность Engine-Plugins также значительно возрастает в процессе реализации.
Чтобы оптимизировать вышеупомянутые проблемы, мы провели дополнительную оптимизацию. Когда компонент планирования запускается, он отправляет задачу Spark SparkSQLEngine в Yarn. Его можно понимать как удаленный сервер Spark Thrift, работающий на Yarn. Сторона механизма постоянно отслеживает состояние работоспособности SparkSQLEngine . Таким образом, каждый раз, когда выполняется проверка синтаксиса, механизм отправляет SQL в SparkSQLEngine через JDBC для проверки синтаксиса.
Благодаря описанной выше оптимизации платформа автономной разработки отделена от Spark Thrift Server, поэтому EasyManager не требуется развертывать дополнительный Spark Thrift Server, что делает развертывание более легким. Нет необходимости поддерживать резидентный процесс Spark в локальном режиме на стороне планирования. Это также открывает путь к усовершенствованию интерактивных запросов задач Spark SQL на автономной платформе разработки.
Отделение автономной платформы разработки от сервера Spark Thrift, развернутого EasyManager, даст следующие преимущества:
· Возможность по-настоящему реализовать сосуществование нескольких кластеров Spark и нескольких версий.
· Стандартное развертывание EasyManager позволяет удалить Spark Thrift Server и снизить нагрузку на фронтальную эксплуатацию и обслуживание.
· Проверка синтаксиса Spark SQL становится более простой, нет необходимости кэшировать SparkContext, что снижает использование ресурсов движка.
Оптимизация функции искры
По мере развития бизнеса мы обнаруживаем, что Spark с открытым исходным кодом не имеет соответствующих функциональных реализаций в некоторых сценариях. Поэтому мы разработали больше новых плагинов на основе Spark с открытым исходным кодом для поддержки более функциональных приложений стека данных.
Диагностика миссии
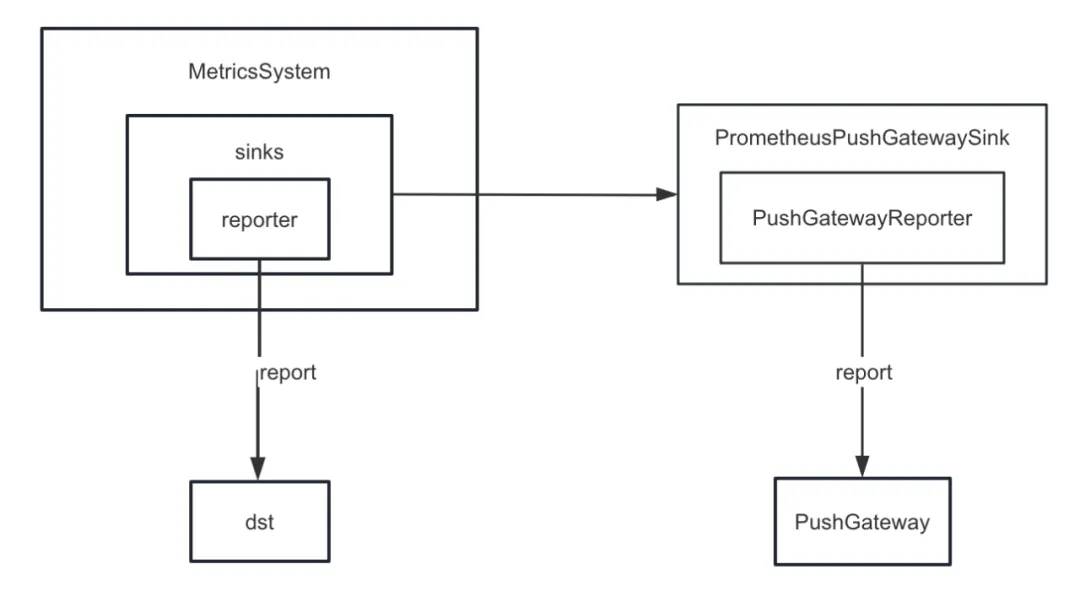
Во-первых, мы улучшили приемник метрик Spark. В Spark предусмотрены различные внутренние приемники. Помимо ConsoleSink, существуют также CSVSink, JmxSink, MetricsServlet, GraphiteSink, Slf4jSink, StatsdSink и т. д. PrometheusServlet также был добавлен после Spark3.0, но он не может удовлетворить наши потребности.
При разработке функции диагностики задач нам необходимо унифицированно отправлять внутренние индикаторы Spark в PushGateway, а сервер Prometheus периодически извлекает индикаторы из PushGateway. Наконец, вызвав интерфейс запросов, предоставляемый Prometheus, мы можем запросить внутренние. показатели Spark практически в реальном времени.

Но Spark не реализует внутренние индикаторы для PushGateway. Поэтому мы добавили плагин spark-prometheus-sink и настроили PrometheusPushGatewaySink для передачи внутренних индикаторов Spark в PushGateway.
Кроме того, мы также настроили новый индикатор для описания хода выполнения задачи отображения временного запроса Spark SQL. Конкретные шаги заключаются в следующем:
· Добавьте индикатор для описания хода выполнения автономных задач, настроив JobProgressSource , и зарегистрируйте индикатор в системе управления индикаторами во внутренней системе управления Spark.
· Настройте JobProgressListener и зарегистрируйте JobProgressListener в ListenerBus во внутренней системе управления Spark. Среди них логика метода onJobStart JobProgressListener заключается в вычислении количества всех задач в текущем задании; логика метода onTaskEnd заключается в вычислении и обновлении текущего хода выполнения автономной задачи после завершения каждой задачи ; Метод onJobEnd предназначен для расчета и обновления текущего хода выполнения автономной задачи после завершения каждого задания. Обновить текущий прогресс автономной задачи.
Подключение к коммерческой версии кластера Hadoop
По мере увеличения числа клиентов Kangaroo Cloud их среда также меняется. Некоторые клиенты используют версию кластеров Hadoop с открытым исходным кодом, а значительное количество клиентов используют HDP, CDH, CDP, TDH и т. д. Когда мы подключаемся к кластерам этих клиентов, стороне разработки часто необходимо вносить новые адаптации, а стороне эксплуатации и обслуживания также необходимо настраивать дополнительные параметры или выполнять другие дополнительные операции каждый раз при развертывании и обновлении.
Если взять в качестве примера HDP, то при подключении к HDP мы используем Spark2.3, который поставляется с HDP, и нам также необходимо добавить некоторые параметры на стороне эксплуатации и обслуживания и переместить все пакеты Jar Spark, поставляемые с HDP. Указать каталог. Эти операции на самом деле привнесут некоторую путаницу и проблемы в эксплуатацию и обслуживание. Разные типы кластеров должны поддерживать разные документы по эксплуатации и техническому обслуживанию, а процесс развертывания также более подвержен ошибкам. И мы действительно внесли функциональные улучшения и исправили ошибки в исходный код Spark. Если вы используете Spark, поставляемый с HDP, вы не сможете пользоваться всеми преимуществами нашего Spark, поддерживаемого внутри компании.
Чтобы решить вышеуказанные проблемы, наш внутренний Spark был адаптирован для существующих и распространенных издателей на существующем рынке. Другими словами, наш внутренний Spark может работать на всех кластерах Hadoop. Таким образом, независимо от того, какой тип кластера Hadoop подключен, для эксплуатации и обслуживания необходимо развернуть только один и тот же Spark, что значительно снижает нагрузку на развертывание эксплуатации и обслуживания. Что еще более важно, клиенты могут напрямую использовать нашу внутреннюю стабильную версию Spark, чтобы получить больше новых функций и повысить производительность.
Новые возможности Spark3.2-AQE
В более старых версиях Data Stack версия Spark по умолчанию — 2.1.3. Позже мы обновили версию Spark до 2.4.8. Начиная с Data Stack 6.0, можно также использовать Spark 3.2. Здесь мы сосредоточимся на AQE , который также является самой важной новой функцией в Spark3.x.
Обзор AQE
До версии Spark3.2 AQE был отключен по умолчанию. Чтобы включить AQE, необходимо установить для spark.sql.adaptive.enabled значение true. После Spark3.2 AQE включен по умолчанию. Пока задача соответствует условиям запуска AQE во время работы, вы можете наслаждаться оптимизацией, предоставляемой AQE.
Следует отметить, что оптимизация AQE будет происходить только на этапе перемешивания. Если операция перемешивания не участвует в работающем процессе SQL, AQE не будет играть никакой роли, даже если значение spark.sql.adaptive.enabled равно. истинный. Точнее, AQE вступит в силу только в том случае, если план физического выполнения содержит узел обмена или содержит подзапрос.
Во время работы AQE собирает информацию промежуточных файлов, сгенерированных на этапе тасования карты, собирает статистику по этой информации и динамически корректирует Оптимизированный логический план и еще не выполненный Spark Plan на основе существующих правил, модифицируя тем самым исходный Оператор SQL. Оптимизация времени выполнения.
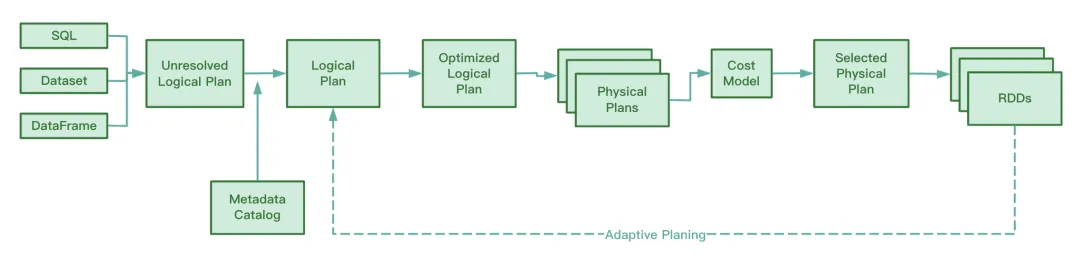
Судя по исходному коду Spark, AQE включает в себя следующие четыре правила оптимизации:

Мы знаем, что RBO оптимизирует SQL на основе ряда правил, включая перемещение предикатов, сокращение столбцов, замену констант и т. д. Эти статические правила сами по себе встроены в Spark. Когда Spark выполняет SQL, эти правила будут применяться к SQL одно за другим.
Преимущества AQE
Эта функция CBO доступна только после Spark2.2. По сравнению с RBO, CBO объединяет статистическую информацию таблицы и выбирает более оптимизированный план выполнения на основе этой статистической информации и модели затрат.
Однако CBO поддерживает только таблицы, зарегистрированные в Hive Metastore. CBO не поддерживает такие файлы, как паркет и орк, хранящиеся в распределенных файловых системах. Более того, если в таблице Hive отсутствуют метаданные, CBO не сможет собирать статистику при сборе статистики, что может привести к сбою CBO.
Еще одним недостатком CBO является то, что CBO необходимо выполнить ANALYZE TABLE COMPUTE STATISTICS для сбора статистической информации перед оптимизацией. Если во время выполнения этот оператор встретит большую таблицу, это займет больше времени, а эффективность сбора будет низкой.
Будь то CBO или RBO, это статическая оптимизация. Если после отправки плана физического выполнения объем данных и распределение данных изменяются во время выполнения задачи, CBO не будет оптимизировать существующий план физического выполнения.
В отличие от CBO и RBO, во время процесса работы AQE будет анализировать промежуточные файлы, созданные в процессе перемешивания карты, а также динамически корректировать и оптимизировать план логического выполнения и план физического выполнения, которые еще не начали выполнение по сравнению со статически оптимизированным CBO. По сравнению с RBO, обработка AQE позволяет получить более оптимизированный план физического выполнения .
Три основные особенности AQE
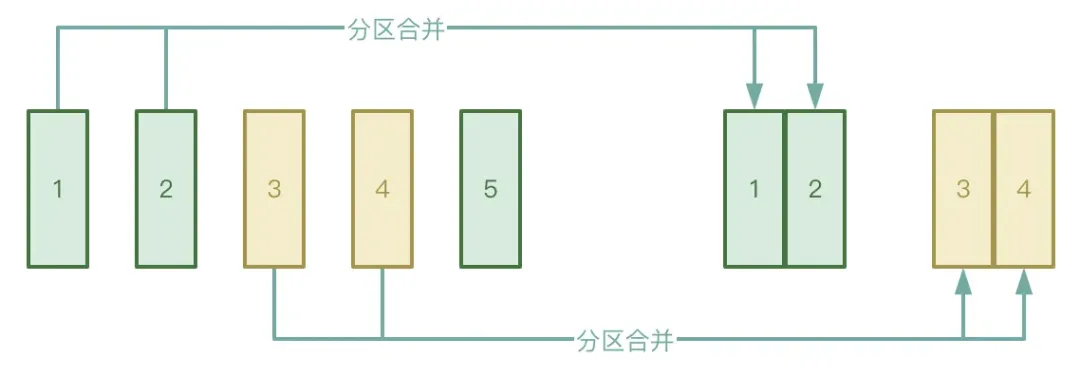
● Автоматическое объединение разделов.
Процесс «Перемешать» разделен на два этапа: этап «Карта» и этап «Сокращение». На этапе «Сокращение» промежуточные временные файлы, созданные на этапе «Карта», передаются соответствующему исполнителю. Если данные, обработанные на этапе «Карта», распределены очень неравномерно, их много. Ключи На самом деле, есть только несколько ключей, после обработки данные могут образовать большое количество небольших файлов.
Чтобы избежать описанной выше ситуации, вы можете включить функцию автоматического объединения разделов AQE, чтобы избежать запуска слишком большого количества задач сокращения для извлечения небольших файлов, созданных на этапе карты.
● Автоматическая обработка асимметрии данных.
Сценарий приложения в основном относится к объединениям данных. При возникновении перекоса данных AQE может автоматически обнаружить перекос раздела и разделить его в соответствии с определенными правилами. В настоящее время в Spark3.2 автоматическая обработка искажения данных поддерживается как для SortMergeJoin, так и для ShuffleHashJoin.
● Присоединяйтесь к корректировке стратегии.
AQE будет динамически понижать версию Hash Join и Sort Merge Join до Broadcast Join.
Мы знаем, что как только задача Spark начинает выполняться, определяется степень параллелизма. Например, на этапе тасования карты параллелизм — это количество разделов; на этапе тасования сокращения параллелизм — это значение spark.sql.shuffle.partitions, которое по умолчанию равно 200. Если объем данных становится меньше во время выполнения задачи Spark, что приводит к уменьшению размера большинства разделов, это приведет к пустой трате ресурсов, если для обработки небольшого набора данных все еще будет запущено так много потоков.
В процессе выполнения AQE автоматически объединяет разделы на основе промежуточных временных результатов, полученных после перемешивания, и при определенных условиях, применяя правила CoalesceShufflePartitions и комбинируя параметры, предоставленные пользователем, что фактически регулирует количество редукторов. Первоначально поток сокращения извлекал данные только из одного обработанного раздела. Теперь поток сокращения будет извлекать данные из большего количества разделов в соответствии с реальной ситуацией, что может уменьшить потерю ресурсов и повысить эффективность выполнения задач. Адрес загрузки «Белой книги по системе отраслевых индикаторов»: https://www.dtstack.com/resources/1057?src=szsm
Адрес загрузки «Информационного документа о продукте Dutstack»: https://www.dtstack.com/resources/1004?src=szsm
Адрес для скачивания «Белой книги по отраслевой практике управления данными»: https://www.dtstack.com/resources/1001?src=szsm
Для тех, кто хочет узнать или получить дополнительную информацию о продуктах больших данных, отраслевых решениях и историях клиентов, посетите официальный сайт Kangaroo Cloud: https://www.dtstack.com/?src=szkyzg .
Я решил отказаться от открытого исходного кода Hongmeng Ван Чэнлу, отец Hongmeng с открытым исходным кодом: Hongmeng с открытым исходным кодом — единственное мероприятие в области промышленного программного обеспечения, посвященное архитектурным инновациям в области базового программного обеспечения в Китае: выпущен OGG 1.0, Huawei предоставляет весь исходный код. Google Reader убит «горой кодового дерьма» Официально выпущена Fedora Linux 40 Бывший разработчик Microsoft: производительность Windows 11 «смехотворно плоха» Ма Хуатэн и Чжоу Хунъи пожимают друг другу руки, чтобы «устранить обиды» Известные игровые компании издали новые правила : свадебные подарки сотрудников не должны превышать 100 000 юаней Ubuntu 24.04 LTS официально выпущена Pinduoduo был приговорен к недобросовестной конкуренции Компенсация в размере 5 миллионов юаней