
И Alibaba Cloud, и Tencent Cloud сталкивались с ситуациями, когда все зоны доступности были парализованы одновременно из-за сбоя компонента. В этой статье мы рассмотрим, как уменьшить область сбоя с точки зрения архитектурного проектирования и минимизировать потери бизнеса при возникновении сбоев, а также рассмотрим практику обеспечения стабильности компании Sealos в качестве примера для обмена опытом и уроками.
Откажитесь от принципа «главный-подчиненный» и выберите одноранговую архитектуру
Из отчета об ошибках Tencent Cloud видно, что одновременный сбой нескольких зон доступности в основном вызван некоторыми централизованными компонентами, такими как унифицированный API, унифицированная аутентификация и другие системные сбои.
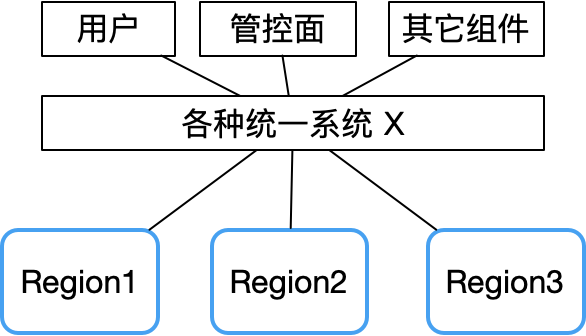
Следовательно, в случае сбоя системы X область сбоя будет очень большой.
Напротив, децентрализованная одноранговая архитектура может хорошо избежать этого риска. В качестве примера возьмем сеть Биткойн. Поскольку центрального узла нет, ее стабильность намного выше, чем у традиционного кластера «главный-подчиненный», и его практически трудно зависнуть.
Таким образом, компания Sealos полностью усвоила уроки Alibaba Cloud и Tencent Cloud при проектировании зон мультидоступности и внедрила бесхозную архитектуру. Все зоны доступности являются автономными. Основная проблема заключается в том, как данные, такие как учетные записи пользователей, хранятся в нескольких зонах доступности. проблема. Получилась такая структура:
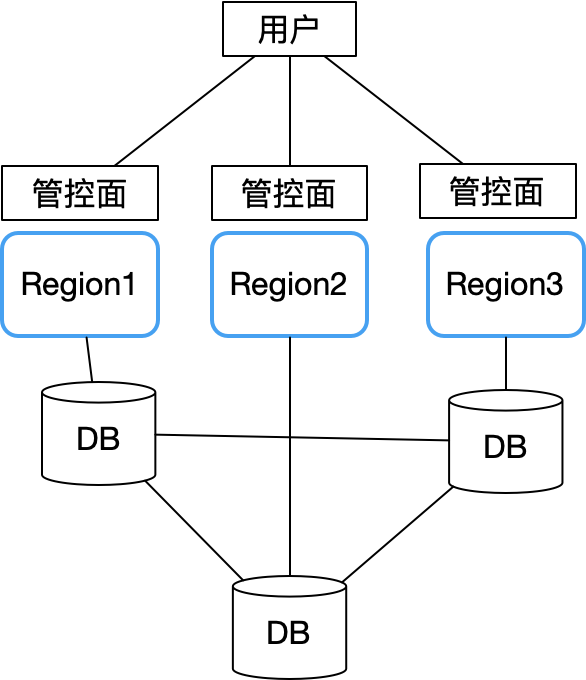
Каждая зона доступности полностью автономна и синхронизирует только ключевые общие данные (например, информацию об учетных записях пользователей) через межрегиональную распределенную базу данных (мы используем CockroachDB). Каждая зона доступности подключена к локальному узлу распределенной базы данных CockroachDB.
Таким образом, сбой в одной зоне доступности не повлияет на непрерывность бизнеса в других регионах. Только при возникновении общей проблемы в кластере распределенной базы данных плоскость управления всех зон доступности станет недоступной. К счастью, CockroachDB сам по себе обладает отличными показателями отказоустойчивости, аварийного восстановления и реагирования на сетевые разделы, что значительно снижает вероятность возникновения такой ситуации. Таким образом, общая архитектура проста. Просто сосредоточьтесь на повышении стабильности базы данных, мониторинге и разрушительном тестировании.
Еще одним преимуществом этого является то, что это обеспечивает удобство выделения оттенков серого и дифференцированных операций. Например, новые функции могут быть сначала проверены при небольшом трафике в некоторых областях, а затем полностью запущены после стабилизации; различные области также могут предоставлять индивидуальные услуги на основе характеристик групп клиентов без необходимости быть полностью согласованными.
Абсолютно стабильной системы не существует.
Все много жалуются на стабильность облака, но у всех без исключения поставщиков облачных систем были сбои. У нас тоже было много сбоев. Здесь самое главное — это вопрос не только технический, но и организационный. Проблема управления также является проблемой затрат. Я поделюсь этим с вами на основе конкретных примеров, с которыми мы столкнулись в ходе предпринимательского процесса.
Уроки Силоса, извлеченные из неудач
Крупный провал Лафа 17 марта 2023 г.
Это была первая серьезная неудача, с которой мы столкнулись при открытии бизнеса. Нам дали пощечину всего через два дня после запуска продукта. Причина, по которой мы так хорошо помним это время, заключается в том, что это было празднование первого юбилея компании. , а мы даже торт разрезать не успели. Это продолжалось где-то до трёх часов ночи.
Конечная причина сбоя была очень странной. Мы использовали легкие серверы для дешевых . Сетевая виртуализация контейнеров на легких серверах приводила к потере пакетов. В итоге мы перенесли весь кластер на обычный VPC-сервер, поэтому неоднократно возникала проблема. был стабильным. Секс и стоимость неразделимы.
Поэтому многие люди думают, что публичное облако стоит дорого. Во многих случаях решение оставшихся 10% проблем обходится во много раз дороже.
Впоследствии компания Laf столкнулась с рядом проблем со стабильностью базы данных, поскольку использовала модель, в которой несколько арендаторов совместно используют библиотеку MongoDB . Окончательный вывод заключался в том, что этот путь не будет работать, и нам было сложно решить проблему изоляции базы данных. проблема, поэтому теперь Все приняли метод независимой базы данных, и проблема была наконец решена.
Также есть проблема со стабильностью на шлюзе. Мы изначально выбрали ненадежный контроллер Ingress , который вызывал частые проблемы. Не буду называть конкретный контроллер. В итоге мы заменили его на Higress, что полностью решило проблему. Он требует меньше ресурсов и более стабилен. Я также очень благодарен команде Alibaba Higress за их личную поддержку. Проблемы, которые мы выявили, также помогли Higress стать более зрелым, что является беспроигрышной ситуацией.
В июне 2023 года было официально запущено наше публичное облако Sealos. Одной из самых больших проблем, с которыми мы столкнулись, были атаки CC с большим трафиком. Добавление защиты может решить эту проблему, но это также означает рост затрат, поэтому приходится искать компромисс. Во-вторых, это очень сбивает с толку. Если вы не предотвратите стабильность, ее будет сложно решить. Если вы предотвратите ее, вы не сможете окупить затраты, продав ее. Позже, после замены шлюза, мы обнаружили, что Envoy действительно мощный и действительно может противостоять атакующему трафику. До этого мы использовали Nginx, который был универсальным. Более того, отличительной чертой K8 является его сильная способность к самовосстановлению. Даже если шлюз выйдет из строя, он может самовосстановиться в течение 5 минут. Если он не выйдет из строя одновременно, это не повлияет на бизнес.
Лучшие практики обеспечения стабильности
Процесс устранения неполадок
Чтобы постоянно улучшать стабильность системы, компания Sealos внедрила строгий внутренний процесс управления сбоями:
Каждый раз, когда происходит сбой, его необходимо подробно фиксировать и постоянно отслеживать. Многие компании прекращают процесс проверки ошибок, но на самом деле проверка не является целью. Главное — сформулировать практические корректирующие меры и реализовать их, чтобы полностью предотвратить повторение подобных ошибок. После завершения обработки неисправности вам все равно необходимо продолжать наблюдать за ней в течение определенного периода времени, пока не будет подтверждено, что проблема больше не возникает.
Что касается целей управления, мы изначально определили цель стабильности и конвергенции в OKR первого квартала 2024 года следующим образом:

Позже я обнаружил, что этот общий OKR в стиле лозунга ненадежен, и достижение стабильности должно быть более конкретным. Результатом этого KR стало то, что нам не удалось его достичь, и он почти не дал никакого эффекта. В процессе конвергенции вам не нужно полностью фокусироваться на нескольких основных моментах каждый квартал и продолжать повторять действия в течение нескольких кварталов, и конвергенция будет очень хорошей.
Итак, во втором квартале мы поставили более конкретные цели:

Установление стабильности не может ограничиваться установлением индикатора и не может быть слишком общим. Оно требует конкретных и видимых мер и конкретных методов измерения.
Например, если установлено 99,9%, как этого добиться? Так какова доступность на данный момент? Каковы основные проблемы, стоящие перед нами? Как измерить? Что должно быть сделано? Кто это сделает? Настройки не ограничиваются доступным временем, но должны быть подробно перечислены, например, уровень неисправности, количество неисправностей, продолжительность неисправности, наблюдение за крупными неисправностями клиента и т. д.
Необходимо выделить специальные категории и перечислить приоритеты, такие как: стабильность базы данных, стабильность шлюза, большие показатели доступности клиентской службы, отказ от перегрузки ресурсов ЦП/памяти.
Нам также следует сосредоточиться на мониторинге крупных клиентов, таких как Auto Chess, коммерческие клиенты FastGPT, Chongchunxue Studio и т. д. (ежемесячное использование более 30 ядер, выберите 5 типичных).
Проблем со стабильностью не так много. Как только эти крупные клиенты будут хорошо обслужены, мелкие клиенты в принципе могут быть охвачены. Не гонитесь за слишком большим количеством проблем, сосредоточьтесь на решении текущих основных проблем со стабильностью, а затем обязательно начните полный процесс отслеживания.
Студенты, допустившие неисправности, могут быть наказаны, лишены премии или даже исключены. Как начинающая компания, мы обычно не используем карательные меры , потому что вовлеченные стороны не хотят вызывать сбои, и все действительно усердно работают над решением проблемы. Те, кто действительно может бороться, — это те , кто пострадал. предпочитают положительные стимулы, например: «Если ежеквартальная частота неудач снижается, дайте соответствующие стимулы» .
Простой архитектурный дизайн
Архитектура системы связана со стабильностью с самого начала проектирования. Чем сложнее архитектура, тем легче возникают проблемы, поэтому многие компании не обращают на это внимания. Я часто участвую в проектировании и анализе архитектуры компании и обычно это обнаруживаю. что дизайн слишком сложен для меня, я чувствую, что что-то не так. Зона мультидоступности Sealos — очень хороший пример. Чтобы превратить сложную вещь в простой CRUD, вам нужно только улучшить стабильность базы данных. Структура таблицы базы данных проста, и многие проблемы со стабильностью решены.
То же самое относится и к нашей системе учета. Изначально мы планировали, что она будет иметь более десятка CRD, но после более чем полугодовой борьбы стабильность не удалось стабилизировать. Наконец, мы перепроектировали и выбрали систему. Это заняло почти все. две недели на разработку, и уже через месяц он был стабильно онлайн.
Поэтому: простой дизайн имеет решающее значение для стабильности!
Умеренный мониторинг, целенаправленный
Наблюдение – это палка о двух концах: слишком многого недостаточно. Многие сбои Sealos были вызваны тем, что мониторинг Prometheus занимал слишком много ресурсов, а сервер API был перегружен, что, в свою очередь, вызывало новые проблемы со стабильностью. Усвоив урок, мы перешли на более легкое решение для мониторинга, такое как VictoriaMetrics, при этом строго контролируя количество индикаторов мониторинга. Такие инструменты, как Uptime Kuma, очень полезны. Они могут тестировать друг друга в разных регионах и вовремя находить проблемы.
То же самое относится и к вызову. Каждый день поступают тысячи сигналов тревоги. Что происходит по вызову? Итак, здесь мы в основном начинаем с 0 и постепенно суммируем. Например, мы сначала делаем это с точки зрения «окончательной стабильности бизнеса крупного клиента». Например, если сбой контейнера запускает это, если есть вызов. , телефон, вероятно, будет звонить без перерыва. Затем медленно добавляйте такие вещи, как хост не готов. Теоретически хост не готов и не должен влиять на бизнес. По мере постепенного развития системы в конечном итоге можно будет сделать хост неготовым без необходимости дежурства.
Не бойтесь смущения, сообщая о неисправностях.
Обзорный отчет Tencent Cloud был очень хорош. Он правдиво объяснял причины сбоя, объективно анализировал недостатки и обещал активно это исправлять. Такое откровенное и ответственное отношение на самом деле помогает завоевать доверие пользователей. Напротив, сохранение проблемы в секрете из-за страха брожения общественного мнения равносильно употреблению яда для утоления жажды. Вместо этого у пользователей возникает ощущение, что это непрозрачный черный ящик, и они не знают, что произойдет в будущем . Клиенты, которые действительно любят ваши продукты и готовы расти вместе с вами, могут терпеть непринципиальные ошибки. Ключевым моментом является проявление искренности и действий для реального улучшения.
Подведем итог
Публичный облачный сервис Sealos запущен более года и собрал более 100 000 зарегистрированных пользователей. Благодаря превосходным функциям, опыту и экономичности многие разработчики отдают ему предпочтение, а некоторые крупные клиенты также начали пытаться перенести свой бизнес в наше облако Sealos. Среди них есть несколько масштабных интернет-продуктов. Например, игра «Happy Auto Chess» имеет более 4 миллионов активных пользователей .
Заглядывая в будущее, мы верим, что благодаря систематическому устранению неисправностей мы продолжим добиваться стабильности благодаря простому и эффективному проектированию архитектуры, устойчивой и устойчивой стратегии мониторинга, а также открытому и честному общению, Sealos, облаку, которое было создано. взлелеянное и разработанное небольшой отечественной компанией с открытым исходным кодом, оно обязательно станет очень продвинутым облаком!
Линус взял дело в свои руки, чтобы не дать разработчикам ядра заменять табуляции пробелами. Его отец — один из немногих руководителей, умеющих писать код, его второй сын — директор отдела технологий с открытым исходным кодом, а младший сын — ядро. Соавтор открытого исходного кода Huawei: потребовался 1 год для преобразования 5000 часто используемых мобильных приложений. Комплексный переход на Hongmeng Java — язык, наиболее подверженный сторонним уязвимостям. Ван Чэнлу, отец Hongmeng: Hongmeng с открытым исходным кодом — единственная архитектурная инновация. в области базового программного обеспечения в Китае Ма Хуатенг и Чжоу Хунъи пожимают друг другу руки, чтобы «избавиться от обид». Бывший разработчик Microsoft: производительность Windows 11 «смехотворно плоха» « Хотя то, что Laoxiangji является открытым исходным кодом, - это не код, а причины этого. Meta Llama 3 официально выпущена. Google объявляет о масштабной реструктуризации .