
Добро пожаловать в отчет об обновлении функций продукта Kangaroo Cloud 09. В этом отчете мы придерживаемся концепции равного акцента на инновациях и оптимизации, а также проводим глубокую полировку и комплексное обновление продукта. Улучшение каждой детали — это наше неустанное стремление к превосходному качеству. Мы надеемся, что эти новые функции помогут вашему бизнесу работать и развиваться, делая путь к цифровой трансформации более плавным.
Ниже приводится содержание отчета об обновлении функций продукта Kangaroo Cloud, выпуск 09. Для получения дополнительных сведений продолжайте чтение.
Оффлайн-платформа разработки
Новые обновления функций
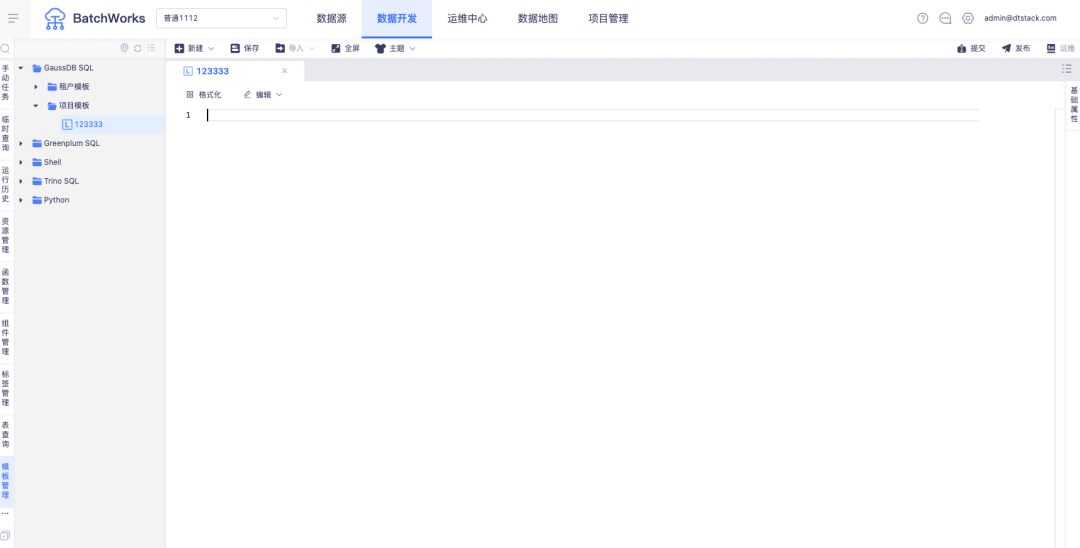
1.Шаблон задачи
Предыстория: Заказчики надеются ежедневно поддерживать общие шаблоны кода в автономном режиме и напрямую ссылаться на них во время разработки данных.
Разница между шаблонами и компонентами:
1. Редактирование поддерживается после ссылки на код шаблона, но редактирование не поддерживается после ссылки на компонент.
2. Изменения шаблона не повлияют на указанные задачи, но изменения компонентов повлияют на указанные задачи.
Описание новой функции: поддержка шаблонов кода проекта и шаблонов кода клиента для каждого типа задач, а также поддержка ссылок на шаблоны кода при создании задач .
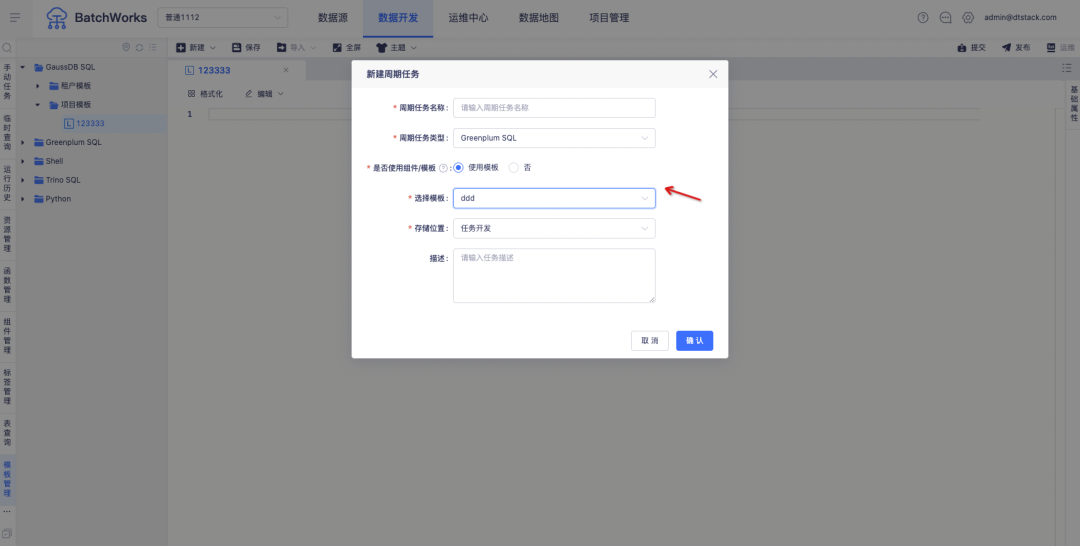
2.shell на агенте/python на агенте добавляет новый элемент управления размерами проекта.
фон:
Shell on Agent — это особый тип задач для автономных платформ.
Задача оболочки не запускается непосредственно на компьютере, развернутом в кластере, а запускается на независимо развернутом серверном узле. Поскольку для одной автономной задачи требуется два ядра, если в сценарии клиента много задач Shell, ресурсы кластера легко заполнить . Таким образом, выполнение таких задач, как Shell и Python, на независимо развернутых узлах может эффективно снизить нагрузку на кластер.
В настоящее время существует проблема. Пока клиент настраивает узел и пользователя сервера на EM и консоли, все проекты в кластере могут использовать настроенного узла и пользователя сервера. Это создает проблему безопасности. Например, для пользователей с высокими правами, такими как root, клиенты уделяют больше внимания вопросам безопасности и не хотят, чтобы все проекты могли использовать эту учетную запись. Поэтому необходимо разработать решение, которое сможет контролировать конфигурацию серверных узлов. и пользователи сервера для решения этой проблемы.
Описание новых возможностей:
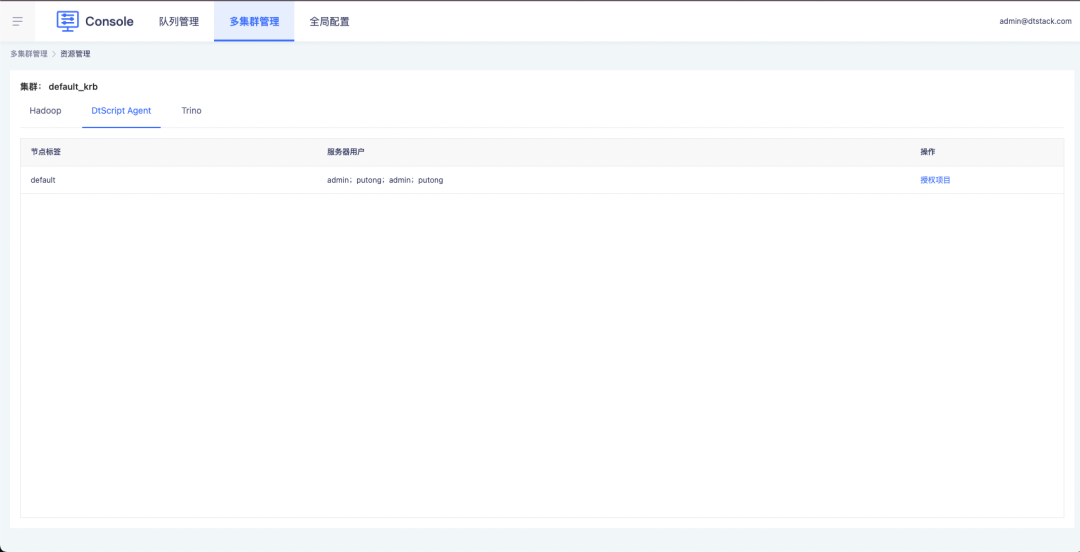
1. Консоль управляет разрешениями пользователей узла и сервера посредством авторизации проекта.
2. Задачи в автономных проектах поддерживают выбор авторизованных серверных узлов и пользователей.
Оптимизация функции
1. Оптимизация конфигурации планирования, которая может контролировать любой периодический экземпляр, который зависит от вышестоящих задач.
фон:
В настоящее время планирование задач Zhongtian может по умолчанию опираться только на вышестоящий экземпляр текущего цикла. У клиентов могут быть следующие сценарии:
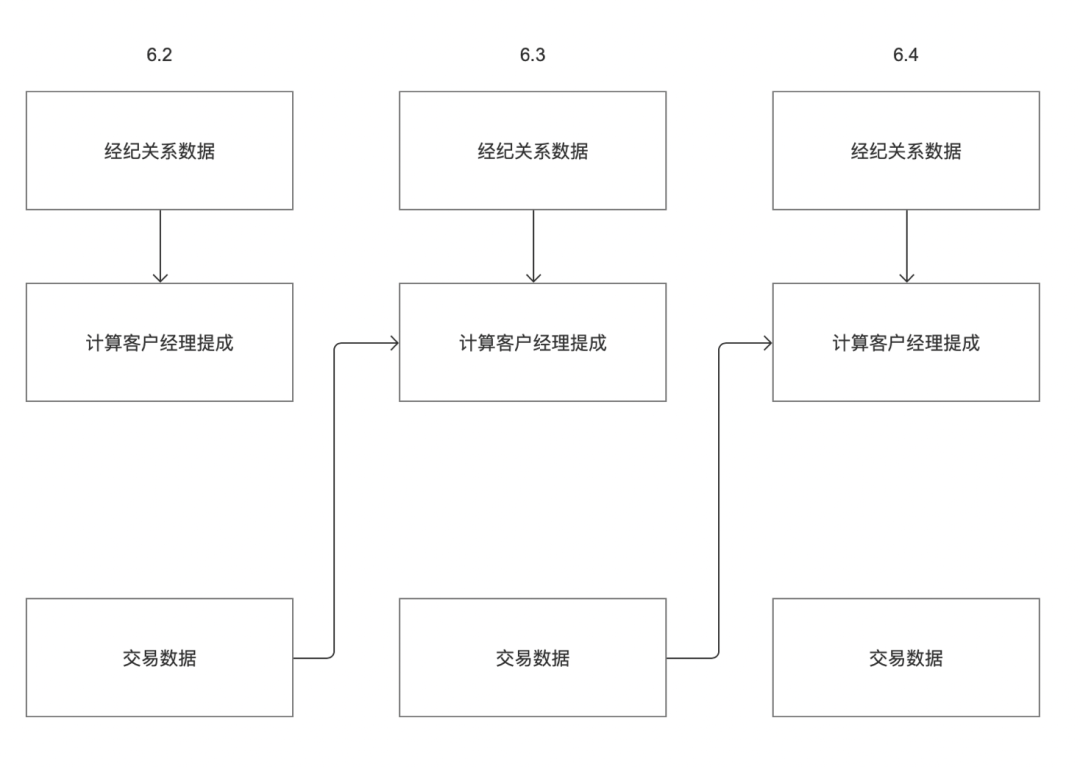
Например, у клиента есть две бизнес-системы «данные о брокерских отношениях» и «данные о транзакциях». Комиссию клиента 3 июня необходимо рассчитать на основе «данных о брокерских отношениях» и «данных о транзакциях» соответственно. Как показано на рисунке выше, время вывода данных бизнес-системы «данные о брокерских отношениях» 2 июня — 3 июня, время вывода данных бизнес-системы «данные о транзакциях» 2 июня — вечер 2 июня;
В соответствии с текущей логикой автономных восходящих и нисходящих зависимостей задача «Расчет комиссии менеджера по работе с клиентами» может получать задачи только 3 июня, но не может получать задачи 2 июня. Поэтому ее необходимо изменить для поддержки настроек зависимостей экземпляра задачи, которые можно настроить цикл.
Инструкции по оптимизации опыта:
Поддерживает настройку цикла планирования зависимых вышестоящих задач .
T представляет запланированное время текущей задачи (задача ниже по потоку), «+ -» представляет направление смещения, «+» представляет смещение времени в будущее, «-» представляет смещение времени в прошлое, а «-» выбрано по умолчанию.
Смещение — это поле числового ввода с максимальным значением 10 и минимальным значением 1, которое представляет количество циклов вышестоящей задачи смещения.
Платформа разработки в реальном времени
Новые обновления функций
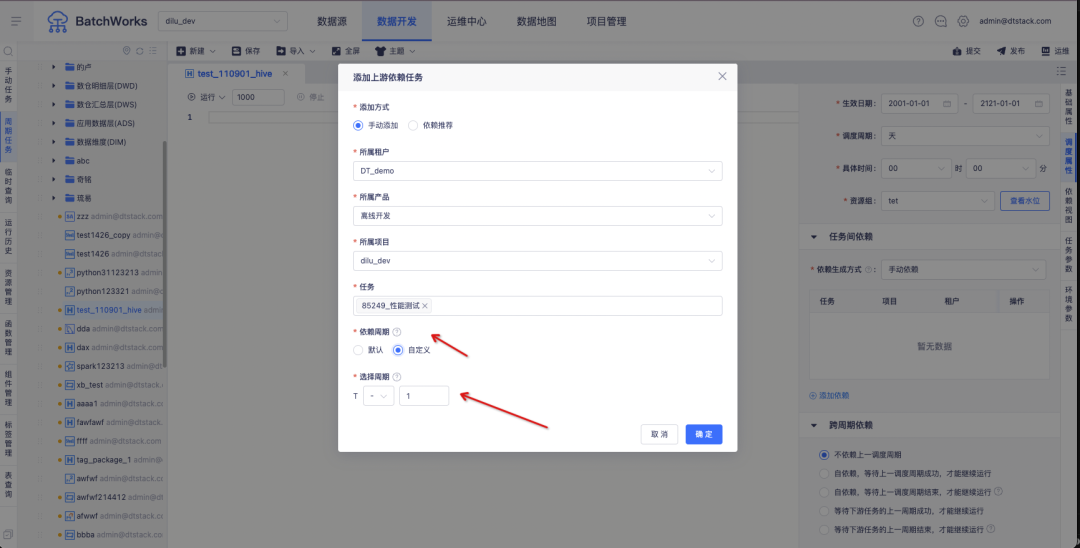
1. Посмотреть анализ родословной
Справочная информация: в настоящее время SQLParser не поддерживает анализ происхождения представлений FlinkSQL. Однако в общих сценариях разработки, если задача включает более трех таблиц, многие собрания предпочитают создавать представления в IDE, чтобы облегчить чтение логики SQL.
Функция:
1. SQLParser поддерживает таблицу представления FlinkSQL для отображения анализа кровного родства.
2. Эксплуатация и обслуживание задач — задачи в реальном времени — сведения о задаче FlinkSQL — функция отображения анализа родословной.
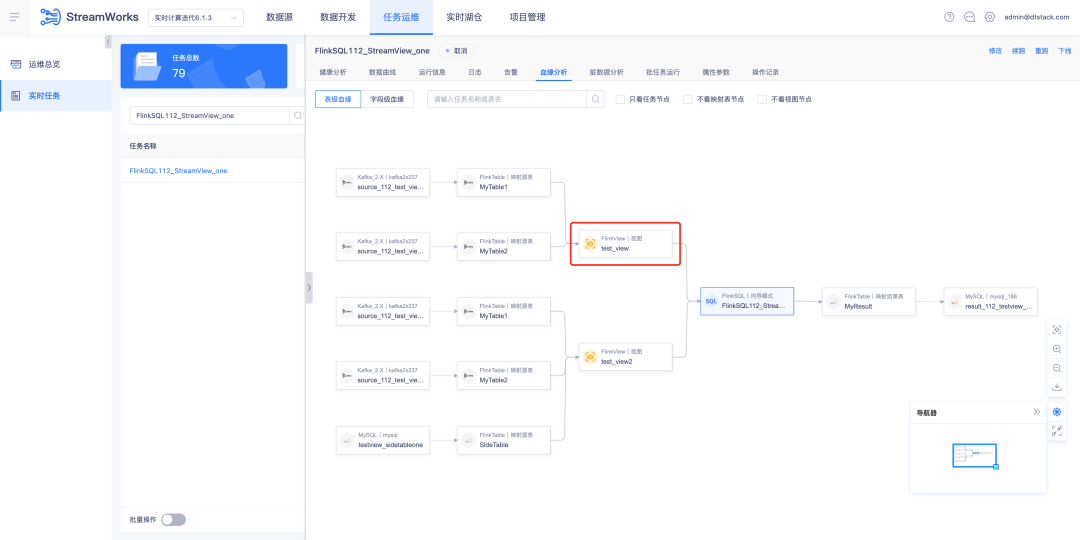
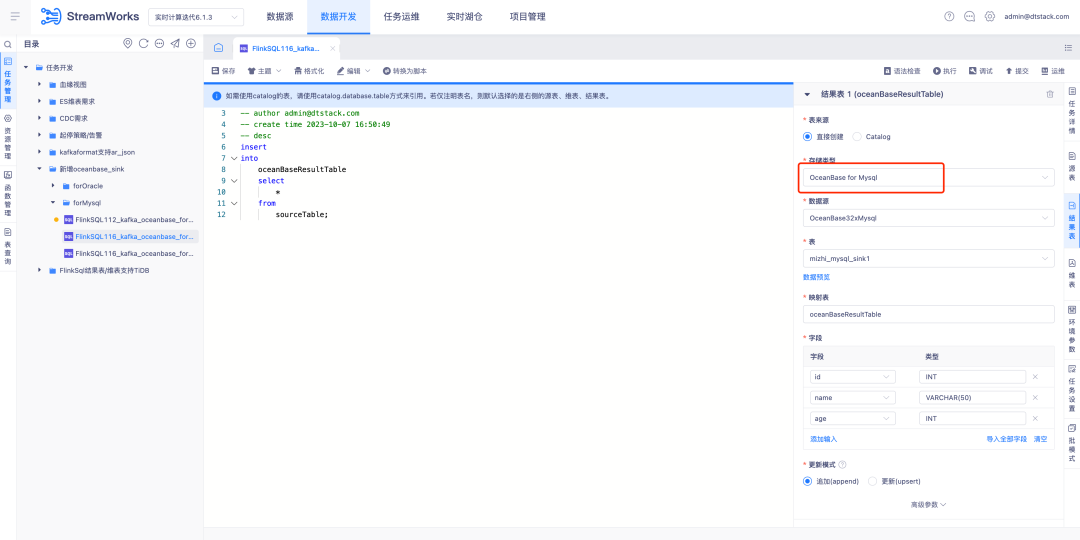
2.FlinkSQL поддерживает Oceanbase Sink.
FlinkSQL версии 1.16 поддерживает таблицы результатов OceanBase и совместим с режимами MySQL и Oracle OceanBase версии 4.2.0, предоставляя пользователям более гибкие и эффективные возможности обработки данных.
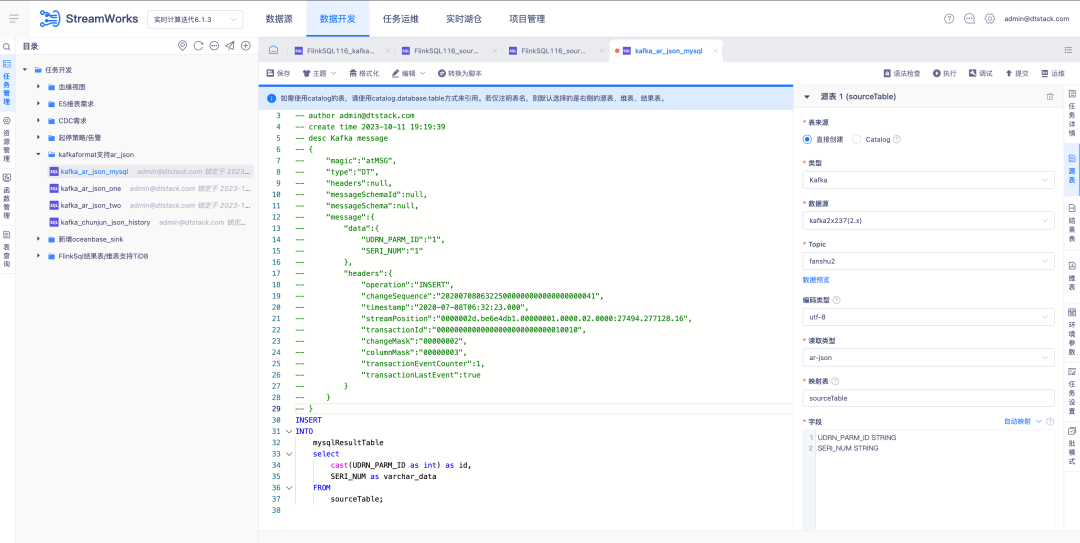
3. Тип чтения исходной таблицы Kafka поддерживает AR Json.
Справочная информация: OGG и Attunity Replication — два широко используемых коммерческих продукта за рубежом. Чтобы лучше удовлетворять потребности клиентов, нам необходимо убедиться, что формат JSON Kafka совместим с типом чтения AR Json.
Описание новой функции: исходная таблица версии FlinkSQL1.16. Тип чтения Kafka поддерживает тип AR Json и поддерживает функции автоматического сопоставления для анализа Json.
4. Поддержка Paimon на озерном складе в режиме реального времени.
Предыстория: При разработке Paimon на этот раз необходимо повторить новую модель разработки FlinkSQL. Используя эту модель, модуль управления складом Lake можно объединить во всю цепочку.
Описание новых возможностей:
1. Управление складом озера добавляет возможность добавлять, удалять, изменять и запрашивать таблицы Paimon.
2. Добавьте функцию визуальной настройки таблицы Paimon в платформу разработки данных.
3. Платформа разработки данных использует IDE для выполнения функций чтения и записи таблицы Paimon.
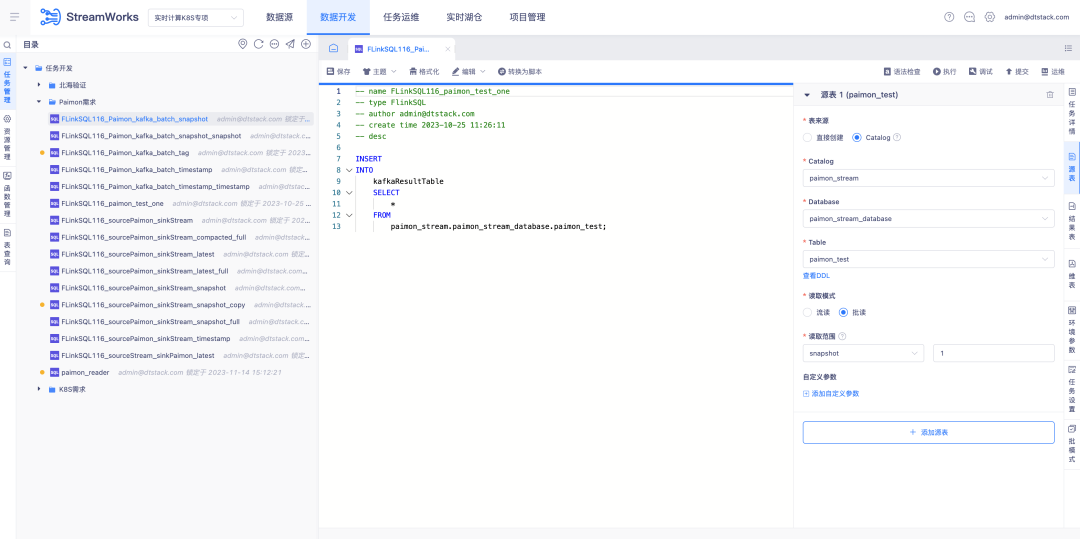
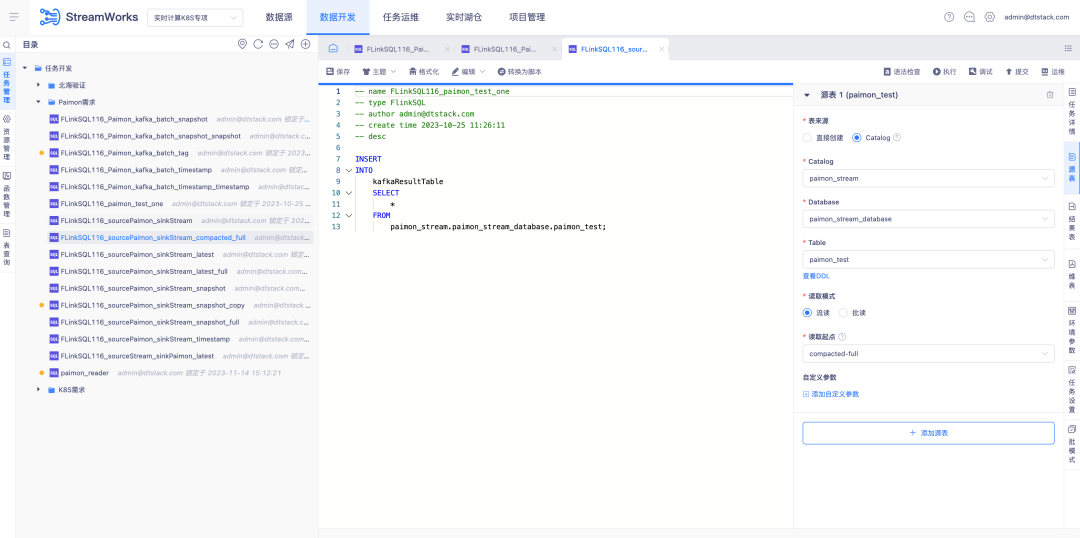
5.FlinkSQL встроенный FlinkCDC.
Справочная информация: FlinkCDC — это компонент сбора данных в реальном времени с открытым исходным кодом и очень высокой скоростью итерации. Базовая платформа Flink, на которой он основан, также аналогична используемой нами платформе ChunJun. Поэтому мы рассматриваем возможность сделать его компонентом по умолчанию для развертывания платформы в реальном времени и упаковать его в нашу систему.
Описание новых возможностей:
1. Пакет развертывания по умолчанию в реальном времени, настройка сбора данных FlinkCDC в реальном времени.
2. В режиме сценария платформы вам необходимо проверить встроенные возможности сбора FlinkCDC и поддерживаемые соединители.
3. В режиме мастера платформы будет настроена коллекция соединителей, поддерживаемая FlinkCDC, в соответствии с ситуацией в проекте.
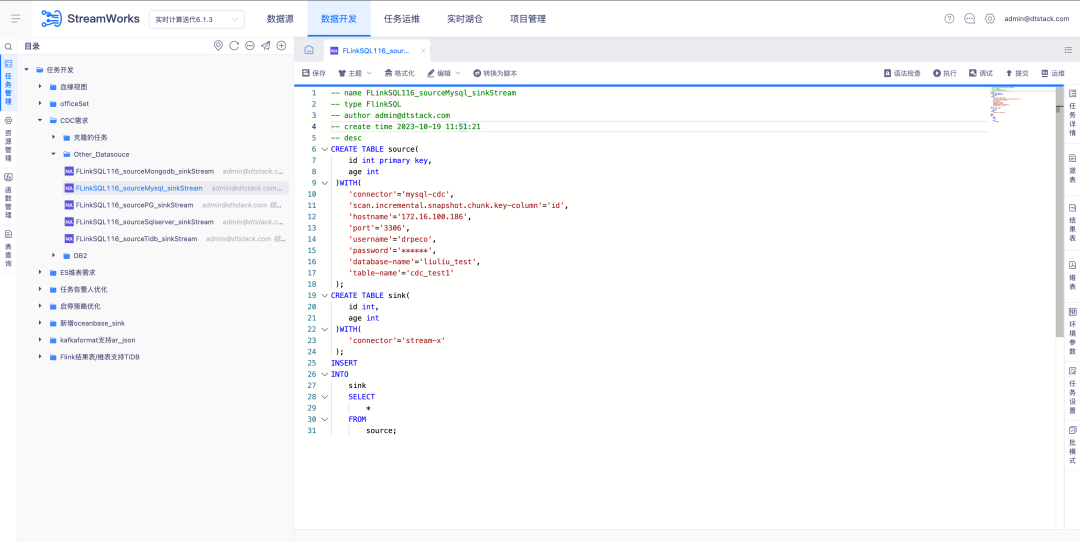
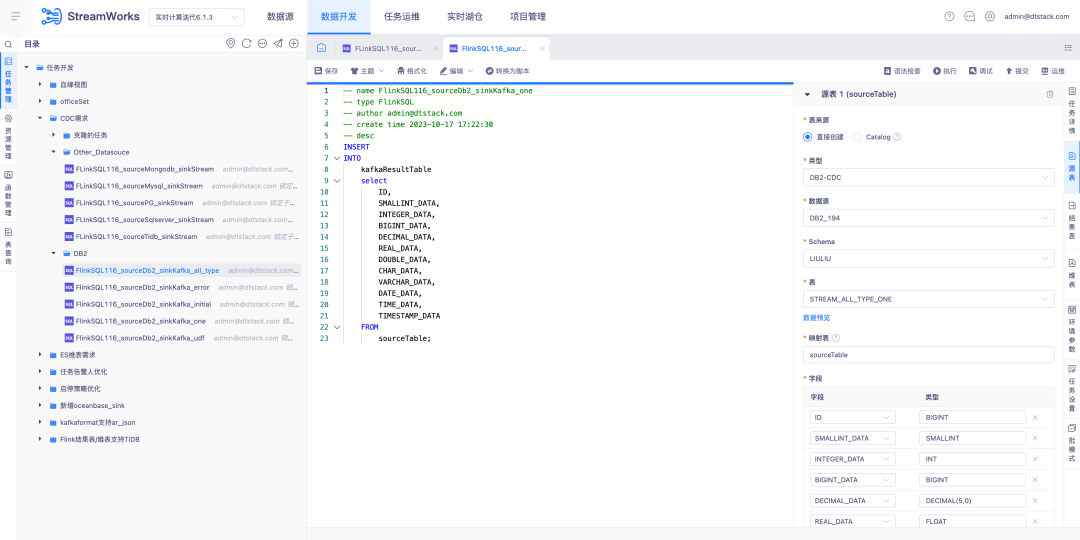
6.FlinkSQL поддерживает источник данных FlinkCDC DB2.
Справочная информация: Заказчикам необходимо поддерживать сбор данных DB2 в реальном времени. Учитывая сложность разработки CDC Connector, FinkCDC просто поддерживает ее, поэтому нижний уровень заимствует возможности FlinkCDC.
Новое описание функции: Платформа реального времени поддерживает режим мастера для настройки исходной таблицы в качестве источника данных DB2-CDC .
Оптимизация функции
1.Оптимизация логики продолжения
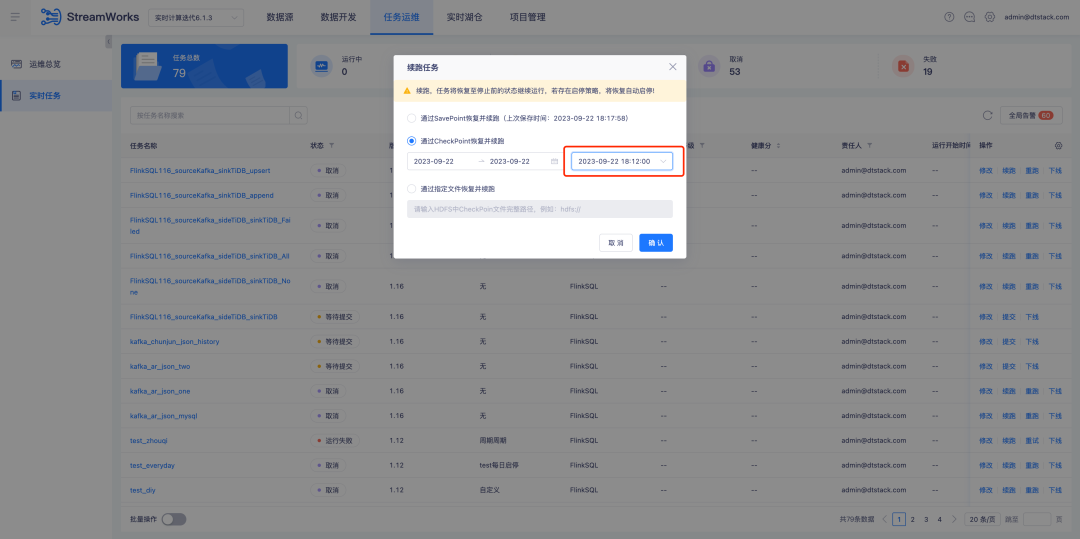
Справочная информация: Когда задача реального времени возобновляется через CheckPoint и продолжает выполняться, момент времени необходимо выбрать вручную. Однако на самом деле в большинстве сценариев продолжения выбираются последние CheckPoint.
Описание оптимизации опыта: при оптимизации для восстановления и продолжения работы через CheckPoint ближайшая контрольная точка в пределах даты будет автоматически выбрана.
2. Стратегия «старт-стоп»/внешняя оптимизация
Справочная информация: В ходе углубленного использования клиентами мы обнаружили, что такие аспекты, как стратегия «старт-стоп», отправка и повторный запуск, можно оптимизировать для достижения более эффективного рабочего процесса и лучшего взаимодействия с пользователем.
В настоящее время конфигурация временных меток Offsite в наших исходных таблицах разработки данных исправлена. Однако в сценариях вычислений задач в реальном времени некоторые клиенты сосредотачиваются только на вычислении данных за день, поэтому они настраивают политику запуска и остановки для повторного запуска задачи каждый день. Они хотят иметь возможность перезапускать задачу каждый день, начиная с полуночи, а не использовать фиксированную отметку времени. Хотя Latest теоретически может удовлетворить это требование, потребление времени запуска задачи в реальном времени может привести к отклонению фактического времени выполнения от нуля, что приведет к ошибкам данных.
Инструкции по оптимизации опыта:
1. Оптимизируйте конфигурацию политики старт-стоп , теперь поддерживайте междневную политику старт-стоп и улучшите взаимодействие с текущей страницей политики старт-стоп, чтобы обеспечить более эффективный и удобный опыт работы.
2. Разработка данных — исходная таблица, поддерживает параметризованную конфигурацию удаленных локаций.
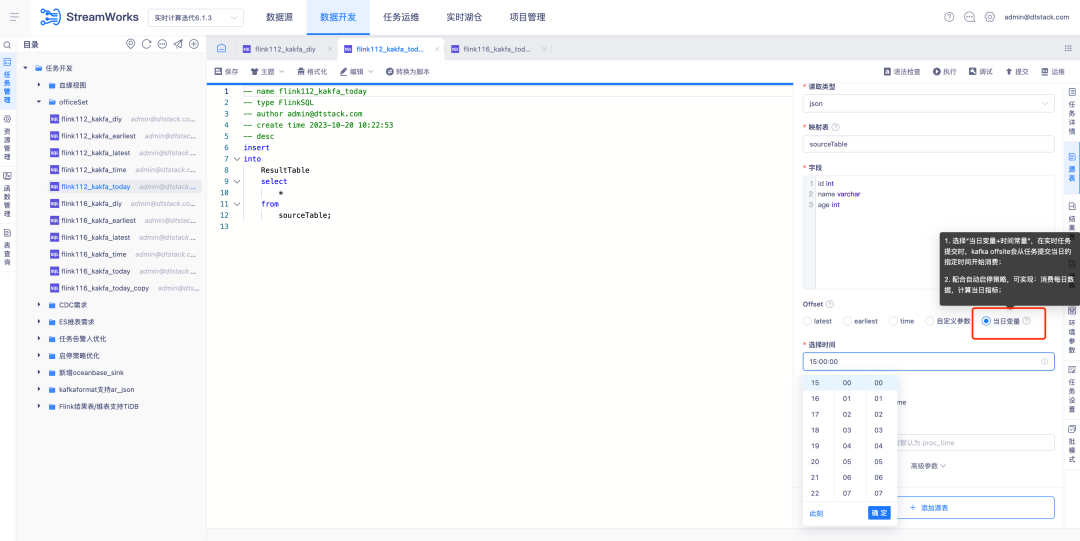
3. Оптимизация подключаемого модуля FlinkSQL1.16 версии ES7.x.
Справочная информация: подключаемый модуль ES FlinkSQL версии 1.10 поддерживает настройку времени ожидания таблицы измерений и ограничения данных по времени ожидания. Эта функция временно недоступна в текущей версии FlinkSQL 1.16 и активно оптимизируется.
Инструкции по оптимизации опыта:
Таблица измерений подключаемого модуля FlinkSQL1.16 версии ES7.x настраивает table.exec.async-lookup.timeout или использует синтаксис подсказок для установки времени ожидания. Когда задача выполняется в режиме LRU таблицы измерений, время ожидания асинхронного запроса составляет. эффект.
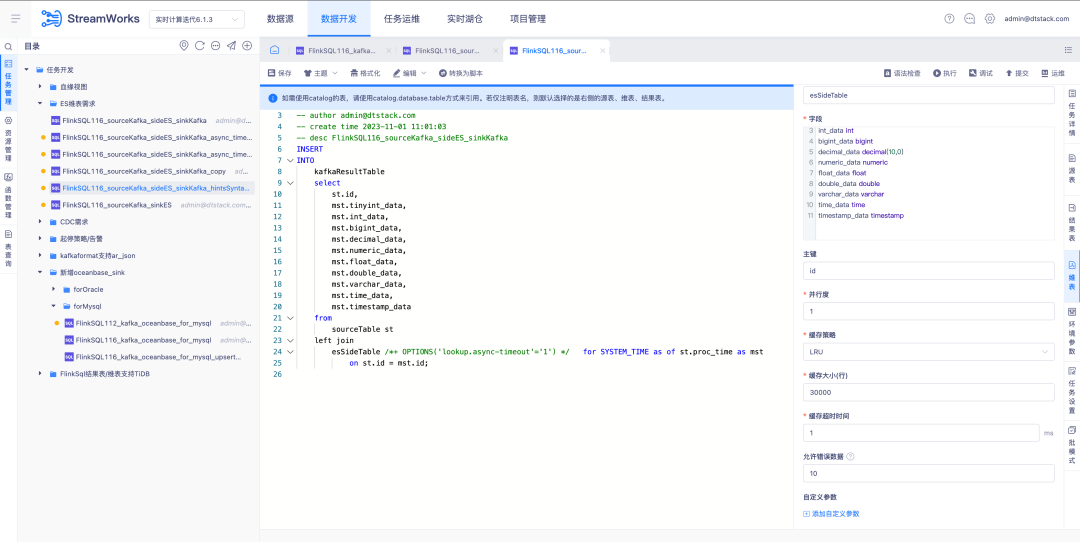
4.Оптимизация конфигурации сигнализации.
Справочная информация: В правилах тревог задачи конфигурацию получения тревог необходимо выбирать вручную. Невозможно автоматически сопоставить и отправить информацию о тревоге в соответствии с ответственным за задачу. В то же время в глобальной конфигурации тревог это также возможно. невозможно автоматически отправить соответствующую информацию о тревоге в соответствии с заданием ответственному лицу.
Инструкции по оптимизации опыта:
1. Настройка получателя конфигурации правила тревоги для одной задачи . Ответственное лицо выбирается по умолчанию. Другие получатели могут быть выбраны с помощью поля выбора.
2. Конфигурация глобального правила тревоги фактически будет отправлена лицу, ответственному за каждую задачу, если отмечено ответственное за задачу. Если выбраны другие получатели, выбранная задача будет отправлена выбранному получателю, если выбранная задача является ненормальной.
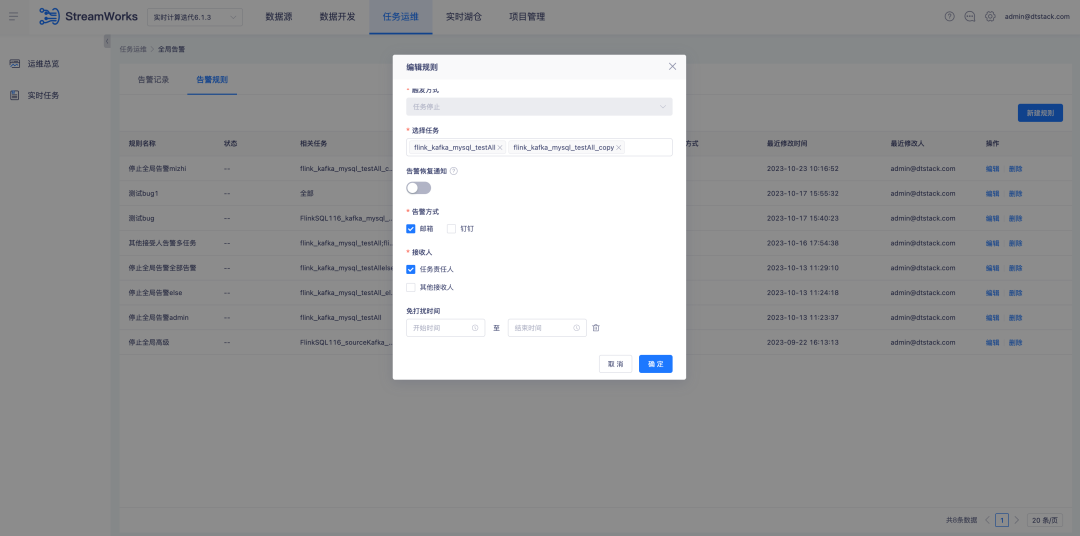
5. Подключаемая платформа Tidb версии FlinkSQL1.12 и 1.16 совместима.
Справочная информация: версии FlinkSQL 1.12 и 1.16 завершили адаптацию к Tidb. Однако уровень платформы был адаптирован только в версии 1.10, поэтому версии 1.12 и 1.16 не поддерживаются.
Инструкции по оптимизации опыта:
Платформа реального времени совместима с подключаемым модулем Tidb версий 1.12 и 1.16 и должна поддерживать как таблицы измерений, так и таблицы результатов.
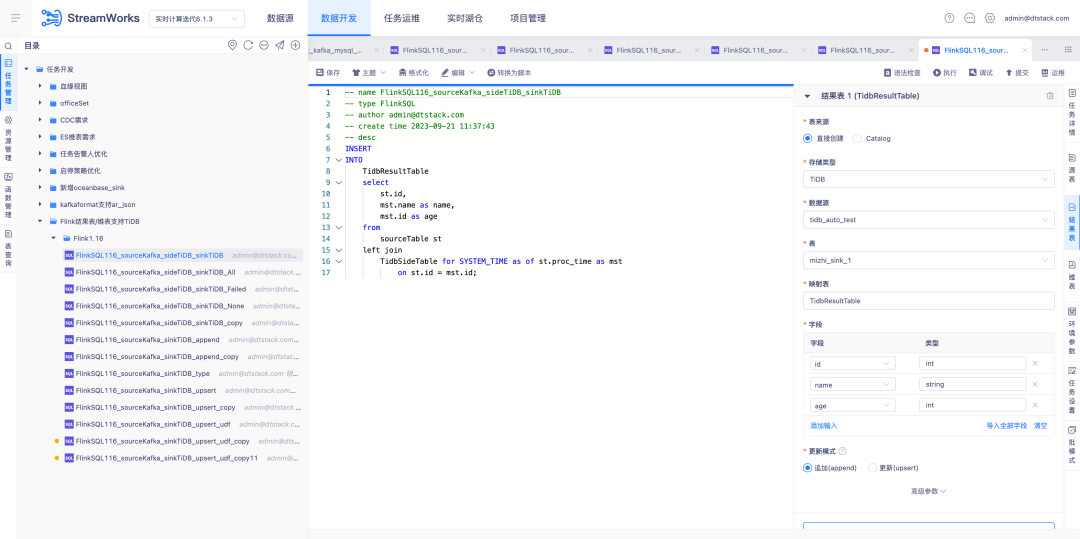
6. Версия FlinkSQL1.12 и 1.16, адаптация Hive для huaweiCloud.
Справочная информация: резервная копия данных Kafka в реальном времени вводится в MRS Hive. При возникновении проблем с данными вычислений в реальном времени можно проанализировать сообщения резервного копирования в Hive.
Инструкции по оптимизации опыта:
FlinkSQL версии 1.12 и 1.16 адаптирован к Hive huaweiCloud. Центр источников данных, механизм и платформа одновременно разрабатываются для поддержки таблицы результатов Hive huaweiCloud . Вам необходимо обратить внимание на сценарий включения Kerberos.
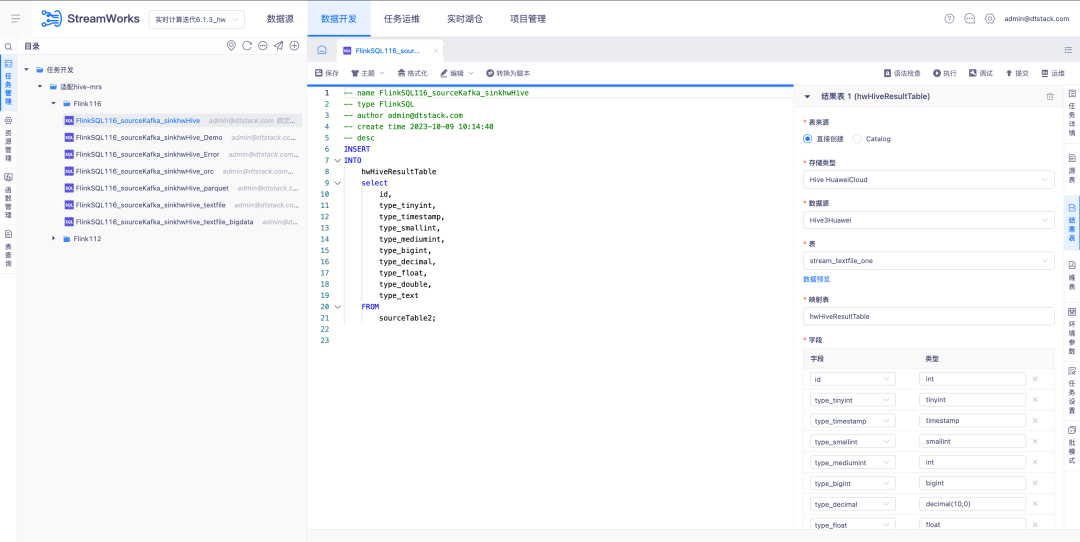
Платформа обслуживания данных
Новые обновления функций
1. Поддержка API создания версии HBase TBDS.
Добавлен API создания версии HBase TBDS, в том числе: API создания режима мастера , импорт и экспорт, а также публикация в целевых проектах.

Оптимизация функции
1. Источник данных Oracle поддерживает DML.
Улучшите источники данных, поддерживаемые DML .
2. Анализ комментариев в режиме пользовательского SQL больше не перезаписывает описание.
Справочная информация. Согласно исторической логике, после повторного анализа пользовательской схемы SQL для базы данных комментарии, поставляемые с базой данных, перезапишут измененные инструкции.
Инструкции по оптимизации опыта: Измените историческую логику. Для измененных инструкций комментарии в базе данных больше не будут перезаписываться после повторного анализа.
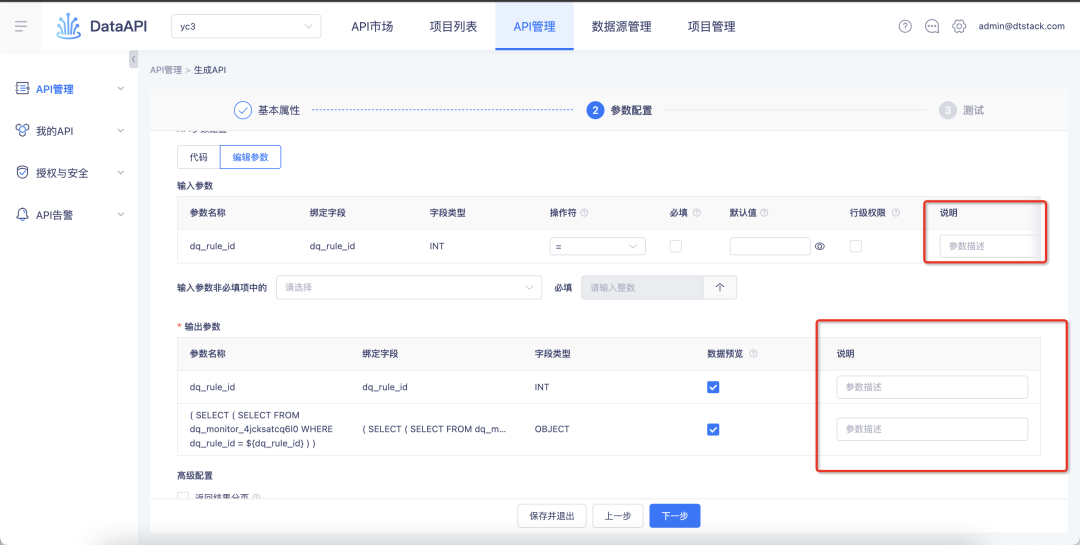
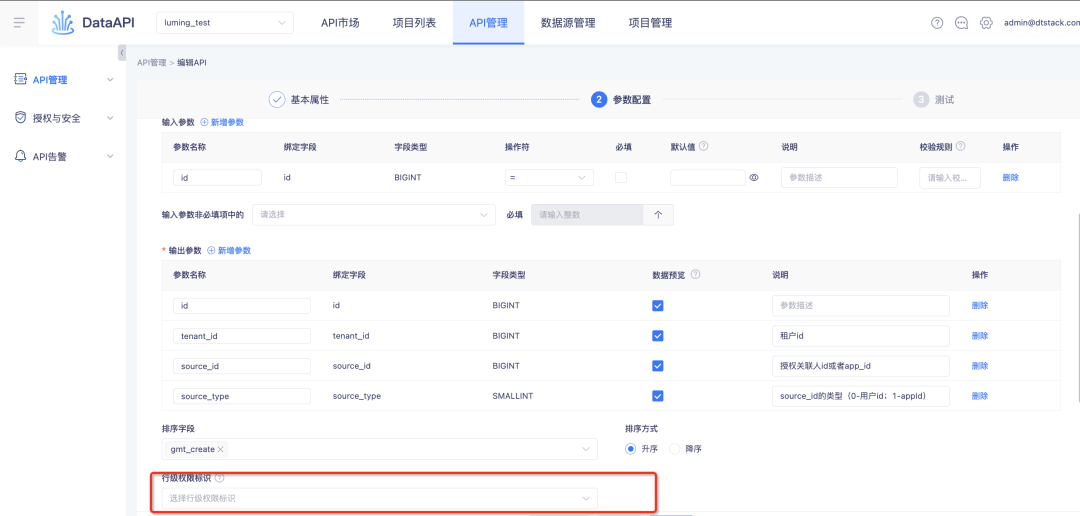
3. После включения разрешений на уровне строк их заполнять по умолчанию не требуется.
Справочная информация: для исторических разрешений на уровне строк разрешения на уровне строк будут включены из полей в таблице. После включения поля будут обязательными по умолчанию, и отмена пользователем не поддерживается.
Описание оптимизации взаимодействия: эта итерация настраивает историческую логику. Разрешения на уровне строк будут включены на уровне API. После включения API будет использовать таблицу.
4. Обновление версии Framework и компонентов.
Обновлена версия платформы Spring Cloud (Boot), а также обновлен компонент Nacos, чтобы снизить вероятность появления уязвимостей и повысить стабильность самого API.
Платформа анализа данных клиентов
Новые обновления функций
1. Поддержка пользовательских функций UDF.
Справочная информация: номер мобильного телефона, идентификационный номер и другие данные, включенные в данные, обрабатываемые клиентом, являются зашифрованными данными. С точки зрения аудита данные такого типа не могут отображаться в виде обычного текста, но возможны сценарии, в которых содержимое будет представлено в виде обычного текста. отображается в бизнесе верхнего уровня. Например: SMS-маркетинг на основе номеров мобильных телефонов.
Клиентам необходимо как можно позже отложить процесс расшифровки, поместить его на платформу меток для завершения и добавить собственные метки посредством настройки функции UDF для завершения обработки.
Описание новых функций: В центр тегов добавлен новый модуль управления функциями , под которым можно создавать, просматривать и удалять UDF-функции (только версии Trino385 и выше поддерживают создание функций)
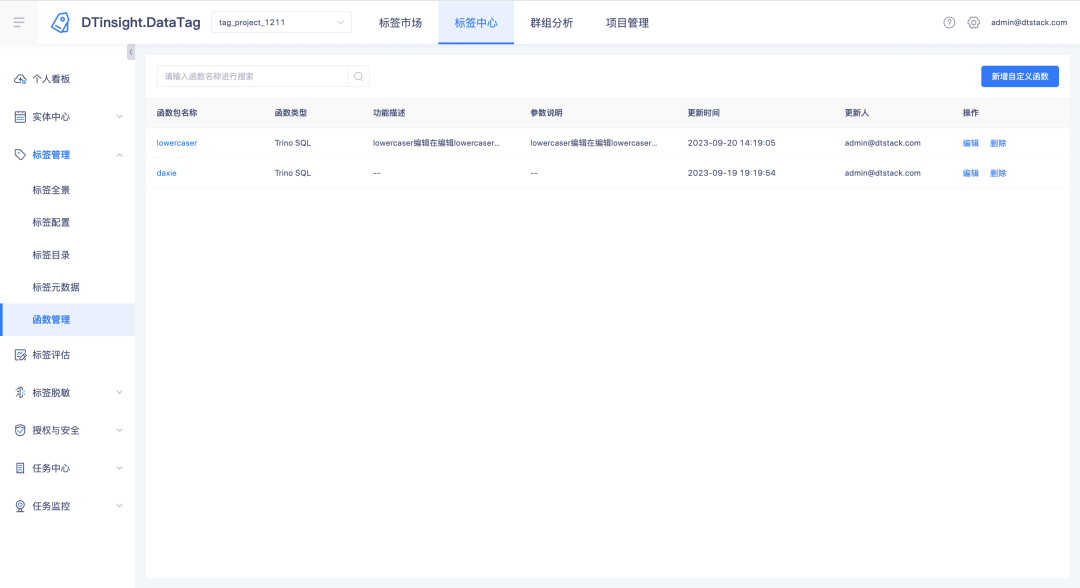
Для загруженных функций вы можете нажать на имя функции, чтобы просмотреть сведения о функции.
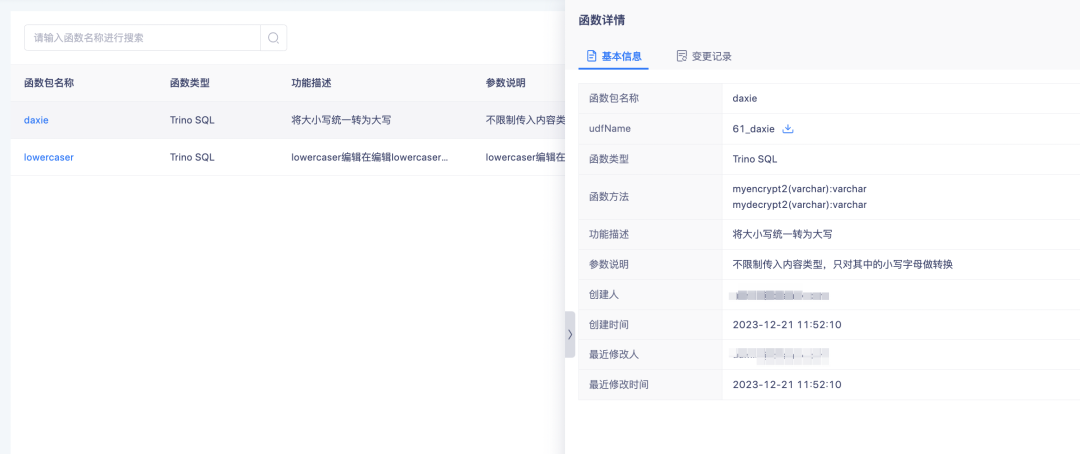
Загруженная функция в основном используется для обработки производных тегов SQL.
2. Поддержка обработки многозначных тегов.
Справочная информация: текущие правила обработки производных тегов и комбинированных тегов заключаются в том, что когда экземпляр впервые достигает определенного условия правила, соответствующее значение тега будет отмечено на экземпляре, и в конечном итоге другие значения тега больше не будут сопоставляться. , результаты тегов с одним значением будут сохранены в базе данных.
Однако в практических приложениях условия не обязательно являются взаимоисключающими. Например, пользователю предоставляется метка предпочтения продукта на основе того, сколько раз пользователь покупал определенный тип продукта. Пользователю может понравиться как мебель, так и одежда. В этом случае необходимо поддерживать несколько значений настроек метки.
Описание новых возможностей:
Теги производных правил, производные теги SQL, комбинированные теги и обработка пользовательских тегов поддерживают конфигурацию как теги с несколькими значениями , и система вычисляет их на основе заданного типа значения тега.
• Теги с одним значением: сопоставление осуществляется в порядке, соответствующем конфигурации правила. Прекращается сопоставление при достижении определенного значения тега. В результате данных имеется не более одного значения тега.
• Теги с несколькими значениями: сопоставление последовательно в соответствии с порядком настройки правил. Каждое правило будет сопоставлено один раз. В результате данных будет не более n настроенных значений тегов.
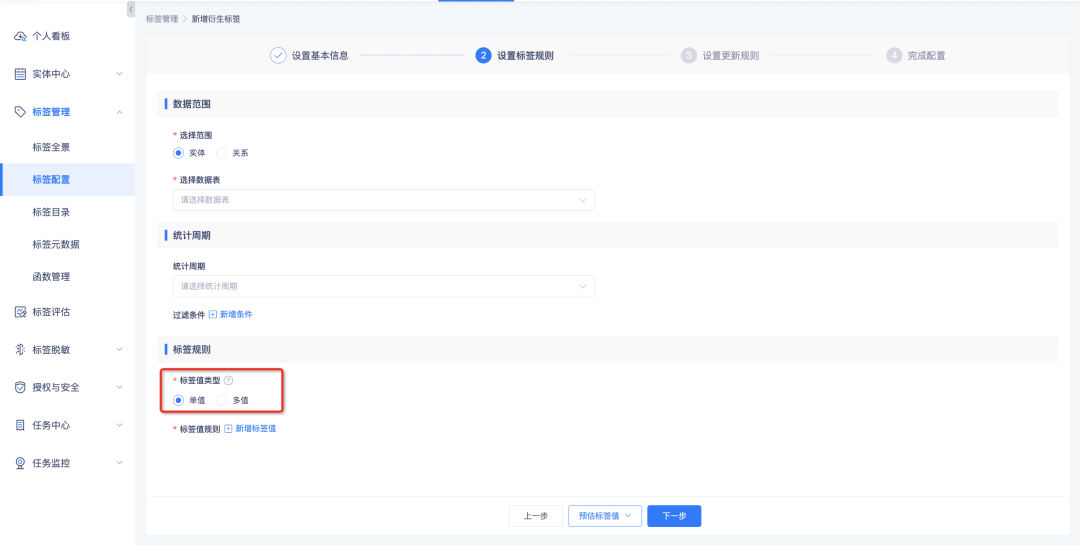
На основании результатов расчета детали метки будут подсчитывать количество экземпляров для каждой отдельной метки, то есть сумма количества экземпляров, охваченных каждым значением метки однозначной метки, равна количеству экземпляров, охваченных меткой. и количество экземпляров, охватываемых каждым значением метки многозначной метки. Сумма чисел больше или равна количеству экземпляров покрытия метки.
3. Индивидуальный ролевой стыковочный бизнес-центр.
Предыстория: Раньше роли были встроенными в систему, и роли нельзя было добавлять/изменять/удалять. Права ролей нельзя было настраивать. Функции были слишком фиксированными и не могли гибко настраиваться в соответствии с реальными бизнес-сценариями. Клиенты В версии 6.0 в бизнес-центр добавлена функция настройки роли, продукт-тег подключается к этой функции бизнес-центра для достижения следующих эффектов:
1. Поддержка новых ролей
2. Поддержка разрешений настраиваемых ролей.
Новое описание функции: настройте роли и разрешения их индикаторов в бизнес-центре, и платформа маркировки автоматически представит результаты настройки разрешений для запроса.
1. Добавьте новые роли и настройте точки доступа ролей в бизнес-центре:
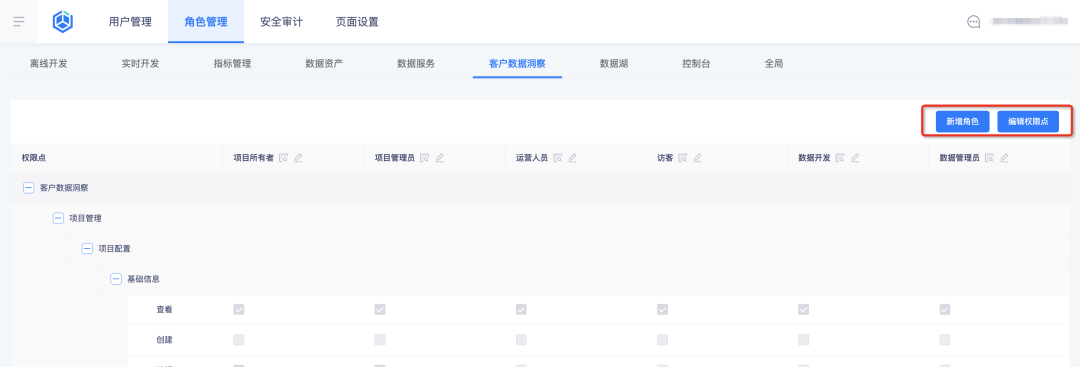
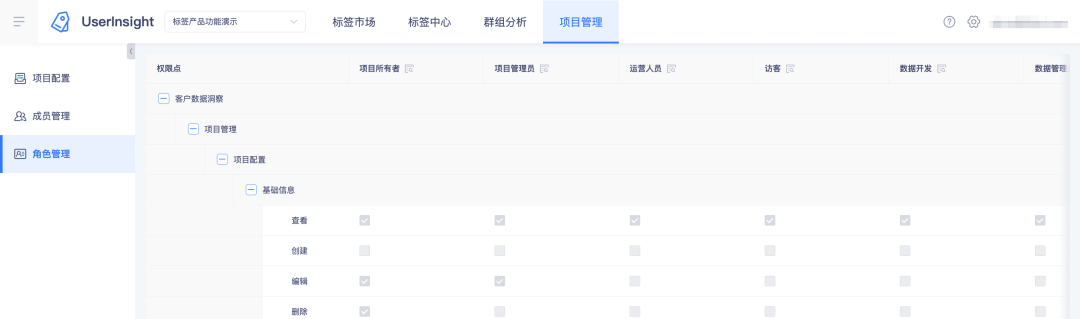
2. Просмотрите роли и их точки доступа на платформе тегов:
4. Формат отображения данных поддерживает настройку.
Справочная информация: для числовых тегов настройка точности отображения в настоящее время не поддерживается, что приводит к неравномерному отображению страниц. Некоторые отображают целые числа, например 1, а некоторые десятичные числа, например 1,234. Общее впечатление от чтения невысокое. опыта, необходимо Добавить настройки правила отображения данных.
Описание новых возможностей:
1. При создании/редактировании сущностей, редактировании атомарных тегов и создании/редактировании производных тегов SQL поддерживается установка правил отображения для числовых тегов.
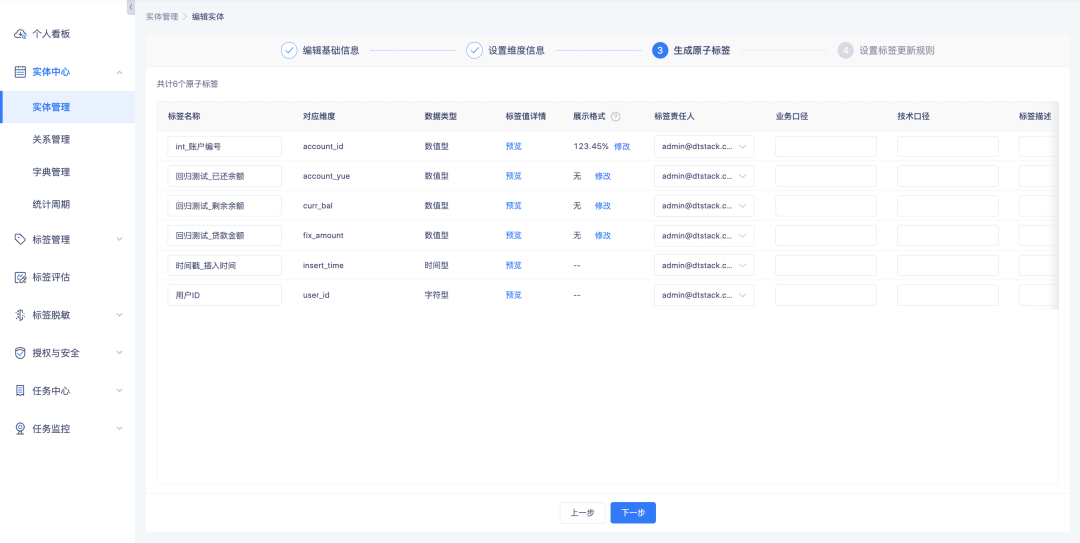
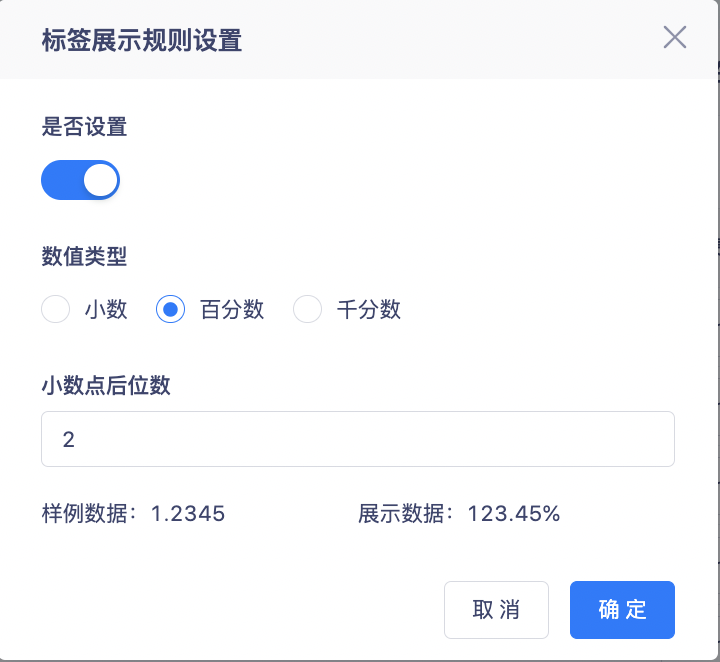
2. Поддерживает отображение в десятичном, процентном и тысячном виде, а также поддерживает настройку количества цифр после десятичной точки.
3. Данные тегов, отображаемые на страницах, связанных с группой, отображаются в соответствии с установленными правилами отображения.
5. Загрузка файлов тегов/групп поддерживает просмотр хода загрузки.
Справочная информация: функция импорта файлов в настоящее время загружается без подсказок о ходе выполнения. Если файл слишком велик, время ожидания велико, из-за чего пользователи неправильно поймут, что страница зависла, поэтому необходимо добавить подсказки о ходе выполнения, чтобы сделать текущий прогресс понятным. пользователи.
Описание новых возможностей:
1. Добавлены подсказки о ходе выполнения задач при загрузке этикеток, групповых файлов и автономных запросов.
2. Групповая загрузка файлов была настроена для поддержки загрузки файлов размером до 500 МБ.
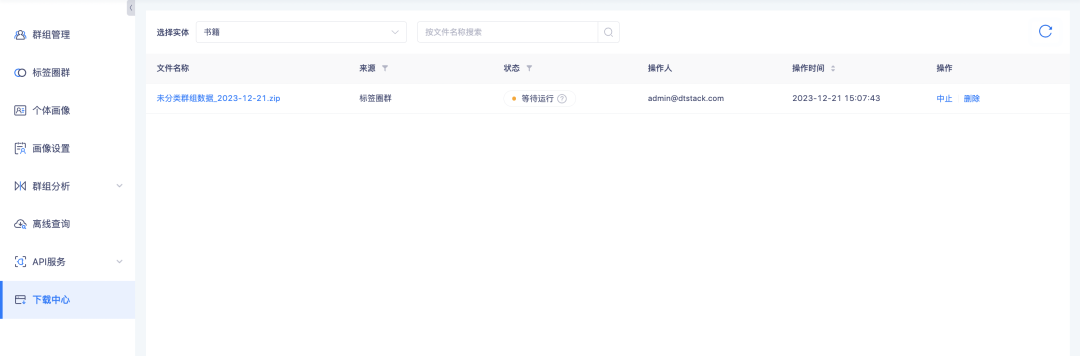
6. Центр загрузки поддерживает запрос о ходе загрузки.
Справочная информация: во время процесса загрузки данных из-за большого объема данных подготовка данных перед их загрузкой занимает много времени. Пользователи не ожидают этого при их использовании, и им необходимо часто обновлять данные, чтобы определить, будет ли загрузка. можно выполнить. Необходимо добавить подсказки о ходе загрузки, чтобы пользователи могли определить, как долго ждать.
Новое описание функции: Статус задачи центра загрузки добавляет статус ожидания запуска и прерванного выполнения. Среди них загрузка списка групп групп тегов, списка групп сведений о группе, загрузка списка экземпляров локальной группы, списка экземпляров деталей автономной группы, пересечения групп и списка экземпляров различий зависит от данных списка групп. объем загрузки велик, он будет выполняться в режиме последовательной загрузки. Задачи, относящиеся к списку групп, будут поставлены в очередь для выполнения в очереди. Остальные загрузки с небольшими объемами данных будут выполняться напрямую. . Пока задачи выполняются, вы можете прервать задачи, которые больше не нужны.
Оптимизация функции
1. Экспорт данных настроен на загрузку файлов через центр загрузки.
Предыстория: Загрузка файлов на некоторых страницах осуществляется напрямую, поэтому кнопка всегда находится в рабочем состоянии, и пользователь не может отслеживать ход загрузки.
Описание оптимизации опыта: после нажатия кнопки, связанной с экспортом данных, файл будет загружен асинхронно. После завершения загрузки вы можете войти в модуль «Центр загрузки», чтобы загрузить сведения о данных. Используемые кнопки страницы: Тег . Группа круга — экспорт данных, сведения о группе — список групп — экспорт данных, загрузка экспорта списка экземпляров локальной группы, автономный запрос — загрузка локальной группы/пересечение группы и экспорт данных о различиях, пересечение групп и экспорт данных о различиях.
Если объем данных слишком велик, система экспортирует его в отдельные файлы исходя из верхнего предела количества записей, установленного пользователем.
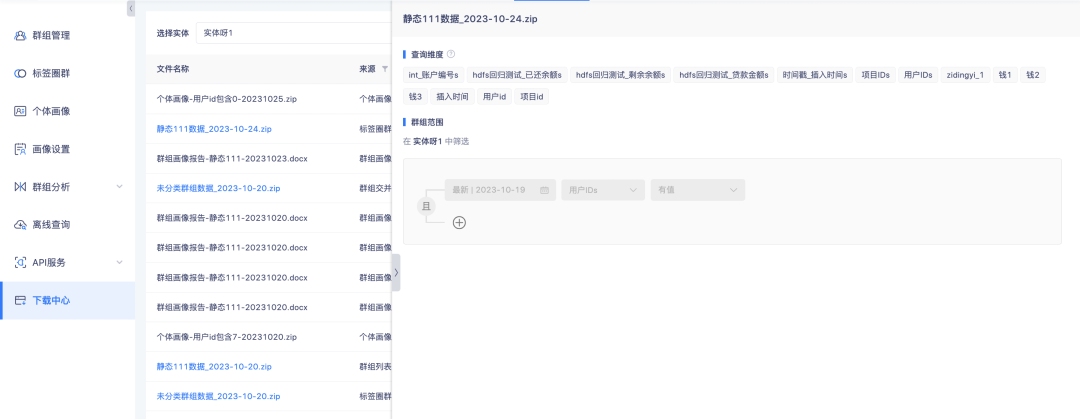
2. Данные списка из групп кругов тегов и сведения о группах в центре загрузки поддерживают просмотр сведений о конфигурации.
Предыстория: В настоящее время в центре загрузки имеется множество источников файлов, и различать содержимое только по именам файлов неудобно. Необходимо увеличить количество источников данных файлов, чтобы улучшить доступность данных.
Описание оптимизации взаимодействия: список данных из групп кругов тегов и сведения о группах поддерживают клики. Нажмите на боковую панель, чтобы открыть сведения о конфигурации.
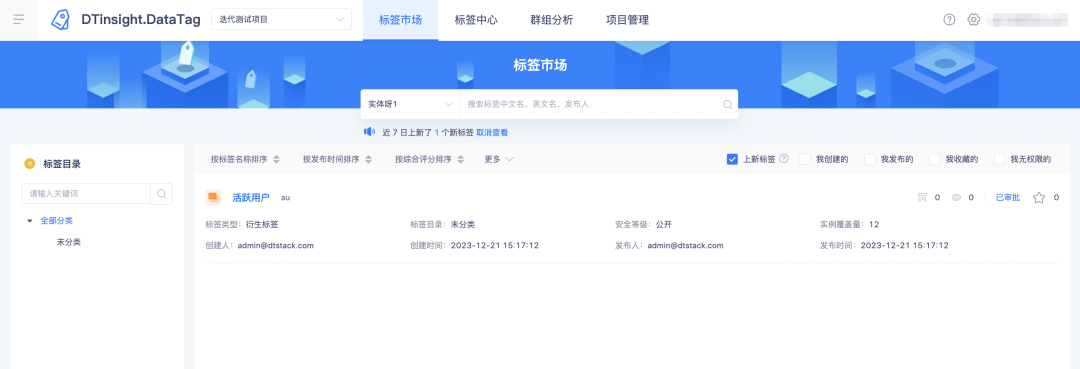
3. Оптимизация новых функций тегов на рынке тегов.
Справочная информация: В настоящее время платформа не объясняет определение новых тегов, и их необходимо добавить.
Описание оптимизации опыта: Новые теги на платформе определяются как последние 24 часа, но при фактическом использовании люди обычно не обращают на них внимания в выходные дни. Когда они снова обратят внимание в понедельник, возникнут ситуации, когда будут обновлены теги. С пятницы по воскресенье утром уведомление не может быть отправлено. Измените определение на последние 7 дней.
4. Оптимизация адаптации разрешений на переключение между субпродуктами
Когда отмеченный продукт переключается между подпродуктами, содержимое вкладки на странице будет отсутствовать. Это вызвано проблемами с разрешениями. Эта оптимизация гарантирует, что функция будет доступна при переключении страниц между продуктами.
5. Поддержка регулировки и настройки ширины столбца.
Список групп, список групп сведений о группе, список групп и пользователей круга тегов, список пересечений групп и список экземпляров различий , а также ширина столбца списка тегов поддерживают настройку.
После настройки ширины столбца она вступит в силу для последующего использования в зависимости от текущего браузера и текущего пользователя, вошедшего в систему. Когда пользователь входит в систему с помощью нового браузера, очищает кеш текущего браузера или входит в систему снова, будут отображены настройки по умолчанию.
Платформа управления индикаторами
Новые обновления функций
1. Индивидуальный ролевой стыковочный бизнес-центр.
Предыстория: раньше роли были встроенными в систему, и роли нельзя было добавлять, изменять или удалять. Разрешения ролей нельзя было настроить. Функции были слишком фиксированными и не могли гибко настраиваться в соответствии с реальным бизнес-сценарием клиента. .
Описание новых возможностей:
Настройте роль и разрешения ее индикатора в бизнес-центре , и платформа индикаторов автоматически представит результаты конфигурации разрешений для запроса:
1. Добавьте новые роли и настройте точки разрешения ролей в бизнес-центре.
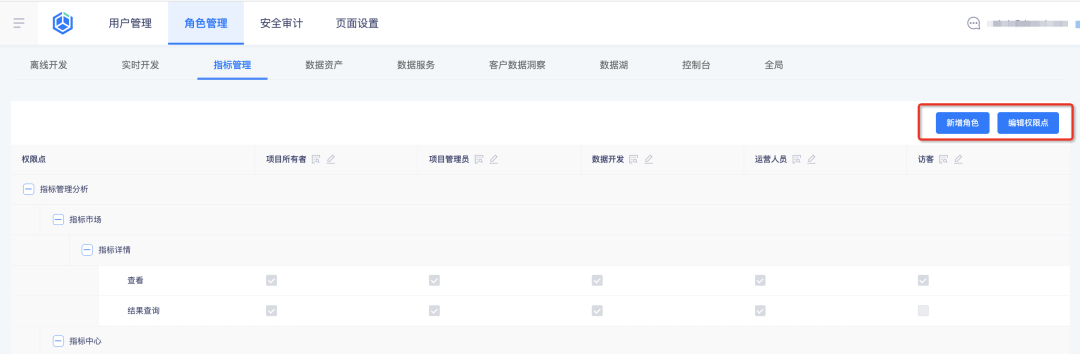
2. Просмотр ролей и их точек доступа на платформе индикаторов.
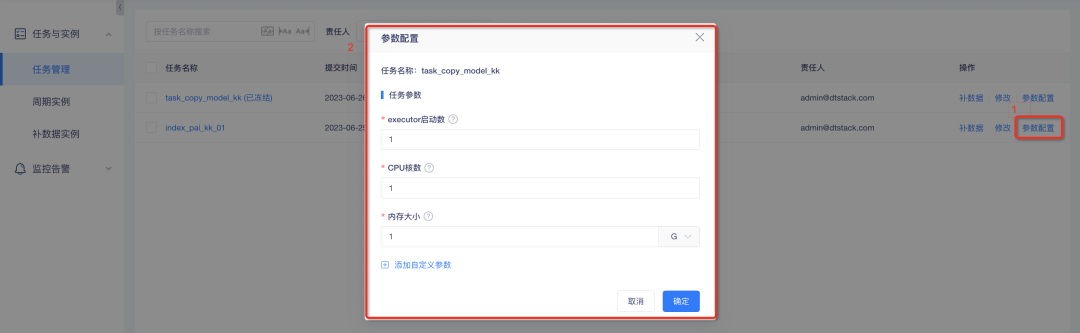
2. Задачи Spark и синхронизации данных поддерживают настройку настраиваемых параметров.
Справочная информация: для задач Spark и задач синхронизации данных настройку параметров в настоящее время можно выполнять только через консоль. Результаты настройки вступят в силу глобально. Однако различия в величине данных между задачами-индикаторами велики, и настройка одних и тех же параметров приведет к ненужным тратам. Таким образом, для задач Spark и синхронизации данных можно задать параметры уровня задач, чтобы облегчить гибкое управление задачами.
Описание новых возможностей:
1. Конфигурация пользовательских параметров задачи Spark : среди них можно установить количество запусков исполнителя, количество ядер ЦП и объем памяти;
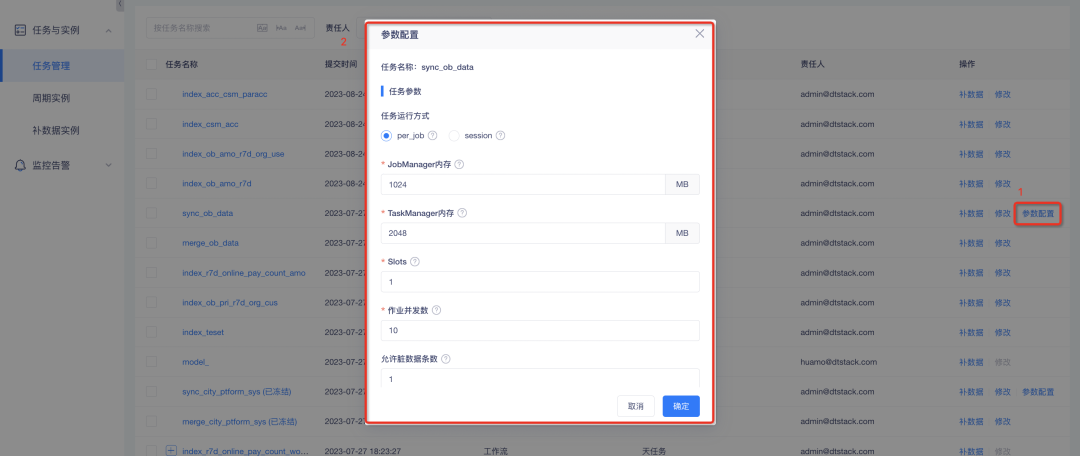
2. Конфигурация настраиваемых параметров для задач синхронизации данных : в режиме каждого задания требуется память диспетчера заданий, память диспетчера задач и слоты, а также количество одновременных заданий и размер WriteBufferSize HBase;
Оптимизация функции
1. Браузер поддерживает одновременное открытие нескольких проектов.
Справочная информация: в функции истории файл cookie не сохраняет параметры проекта. В результате, когда стек данных открывает новое окно проекта, содержимое окна истории будет обновлено, и пользователь вернется на страницу списка проектов для проекта. выбор, который влияет на использование клиентами.
Описание оптимизации взаимодействия: эта оптимизация позволяет браузеру одновременно открывать несколько проектов для запросов, операций и т. д., чтобы повысить эффективность использования продукта.
2. Edge совместим с браузером
Функции, совместимые с браузером egde, будут соответствующим образом адаптированы для повышения удобства использования продукта в основных браузерах.
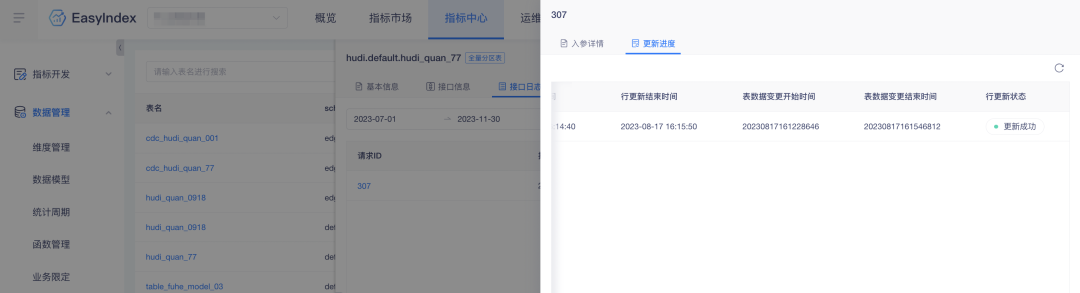
3. Время обновления дополнительной таблицы обновления строк.
Справочная информация: в записи данных обновления строки отсутствует период времени изменения данных таблицы, что делает поиск данных неудобным. Чтобы повысить эффективность поиска данных, в платформу добавляются соответствующие данные.
Описание оптимизации опыта: Обновление строки индикатора добавляет время начала и окончания изменения данных таблицы.
4. Добавьте функцию ручного обновления в статус обновления строки.
Во время процесса обновления строки, чтобы облегчить своевременное отслеживание хода обновления, на страницу добавляется кнопка обновления для повышения эффективности обновления.
5. Оптимизация наполненных моделью размерных объектов и функций размерных атрибутов.
При редактировании модели на этапе настройки информации об измерениях система по умолчанию заполняет информацию об измерениях, привязанную к основным полям таблицы измерений, если пользователь изменил связанные измерения в исторической версии, и если вы не обратите внимания. при корректировке в процессе редактирования неверные данные будут сохранены. Чтобы избежать ошибок в данных, они корректируются так, чтобы повторять информацию, сохраненную в предыдущей версии.
6. Шлюз API поддерживает пользовательские префиксы.
Информация о префиксе индикатора в настоящее время записывается в элемент конфигурации API. В то же время API в настоящее время имеет специальную функцию префикса для повышения гибкости конфигурации API. В настоящее время, когда элементы конфигурации API индикатора не соответствуют пользовательскому префиксу API, данные не могут быть вызваны нормально. Необходимо настроить параметры конфигурации API стыковки, чтобы гарантировать уникальность глобальной конфигурации.
Адрес загрузки «Информационного документа о продукте Dutstack»: https://www.dtstack.com/resources/1004?src=szsm
Адрес для скачивания «Белой книги по отраслевой практике управления данными»: https://www.dtstack.com/resources/1001?src=szsm
Для тех, кто хочет узнать или получить дополнительную информацию о продуктах больших данных, отраслевых решениях и историях клиентов, посетите официальный сайт Kangaroo Cloud: https://www.dtstack.com/?src=szkyzg .
Линус взял на себя задачу не допустить, чтобы разработчики ядра заменяли табуляции пробелами. Его отец — один из немногих руководителей, умеющих писать код, его второй сын — директор отдела технологий с открытым исходным кодом, а младший сын — ядро с открытым исходным кодом. участник Робин Ли: Естественный язык станет новым универсальным языком программирования. Модель с открытым исходным кодом будет все больше и больше отставать от Huawei: потребуется 1 год, чтобы полностью перенести 5000 часто используемых мобильных приложений на язык Hongmeng, наиболее подверженный этому . сторонние уязвимости. Расширенный текстовый редактор Quill 2.0 был выпущен с функциями, надежностью и разработчиками. Опыт был значительно улучшен. Ма Хуатэн и Чжоу Хунъи пожали друг другу руки, чтобы «устранить обиды». Meta Llama 3 официально выпущен. источник Laoxiangji не является кодом, причины этого очень трогательны. Google объявил о масштабной реструктуризации.