
На прошедшей весенней конференции 2024 года компания Kangaroo Cloud представила новый выпуск версии V6.2 продукта стека данных . Среди них EasyMR, как ключевая функция в стеке данных V6.2, представляет собой глубокое понимание Kangaroo Cloud и постоянные инновации в экосистеме больших данных.
EasyMR (далее совместно именуемый EMR) — это механизм эластичных вычислений , созданный Kangaroo Cloud на основе компонентов с открытым исходным кодом, таких как Hadoop, Hive, Spark, Flink и HBase. Он обеспечивает безопасность, надежность, эластичное масштабирование и низкую стоимость . хранение данных и вычислительные услуги . Среди них независимо разработанная платформа управления операциями и обслуживанием больших данных EasyManager корпоративного уровня, поддерживающая комплексные функции создания, управления, развертывания, эксплуатации, обслуживания и мониторинга кластеров Hadoop, обеспечивая эффективное решение для центров обработки данных.
Учитывая растущие потребности предприятий в обработке и анализе данных, версия EMR6.2 предоставит пользователям более качественные услуги по эксплуатации и обслуживанию больших данных, а также оптимизацию производительности вычислений. Ниже приводится подробное описание оптимизации четырех основных функций версии EMR6.2, которое поможет пользователям полностью понять этот инновационный продукт.
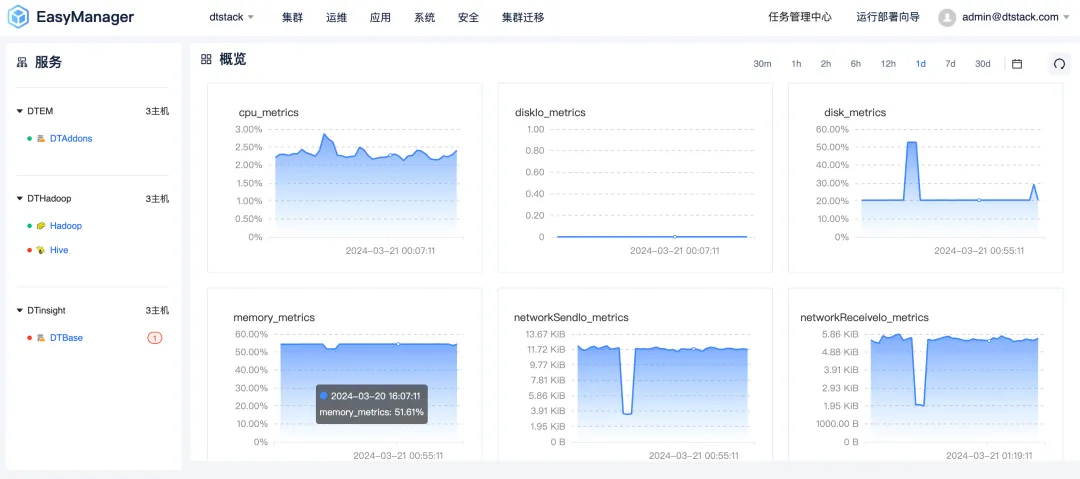
Пользовательский интерфейс полностью обновлен и обновлен: простой и удобный интерактивный интерфейс.
Kangaroo Cloud понимает важность пользовательского опыта, поэтому в версии EMR6.2 мы полностью обновили и обновили интерфейс пользовательского интерфейса. Новый дизайн интерфейса выполнен в простом, но элегантном стиле и призван предоставить пользователям интуитивно понятный и удобный интерактивный опыт. Независимо от того, являетесь ли вы новичком или опытным пользователем, вы можете быстро приступить к работе и легко управлять сложными кластерами больших данных.
Кроме того, мы также оптимизировали скорость отклика и плавность работы интерфейса, чтобы пользователи могли наслаждаться более плавной работой во время работы и обслуживания кластера .
Дифференцированная конфигурация: удовлетворение разнообразных потребностей
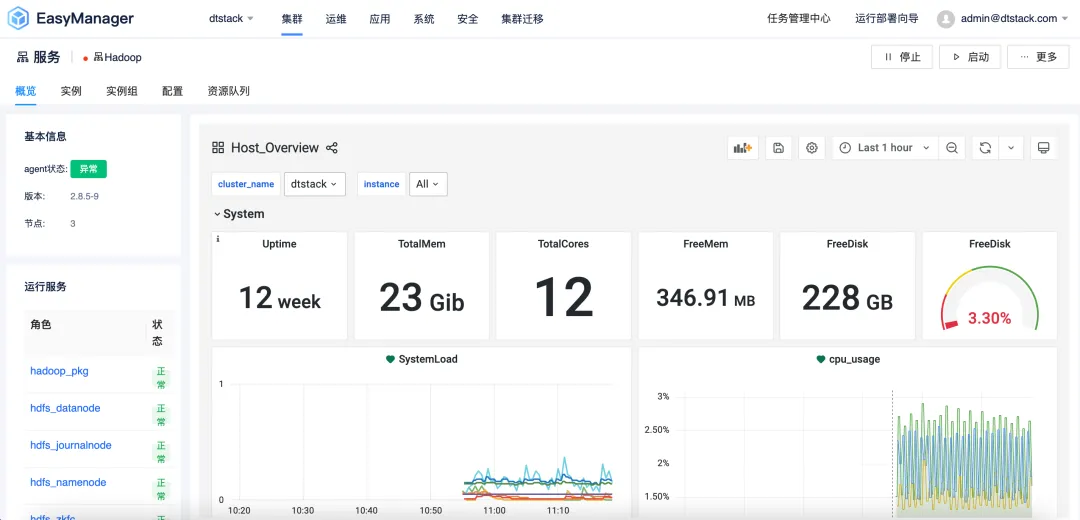
В версии EMR6.2 представлена функция настройки, дифференцированная по группам экземпляров , позволяющая пользователям настраивать конфигурацию кластера в соответствии со своими конкретными потребностями. Пользователи могут создавать независимые группы экземпляров из разных узлов кластера EMR и устанавливать определенные параметры конфигурации в группе экземпляров для повышения производительности, использования ресурсов и планирования задач.
Будь то недорогой стартап или крупное предприятие с более высокими требованиями к производительности, EMR6.2 может предоставить гибкие варианты конфигурации для удовлетворения потребностей различных пользователей.
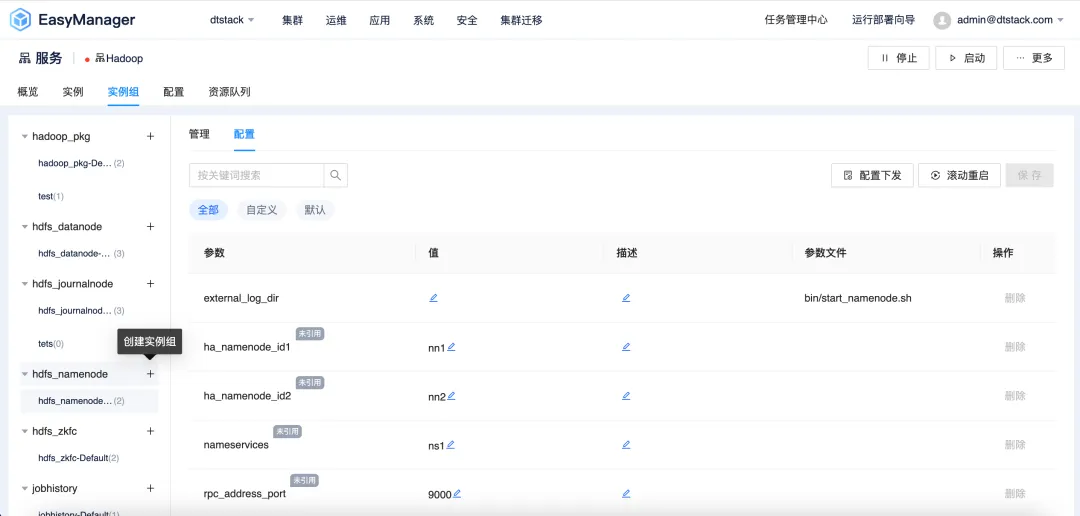
Конкретные преимущества реализации стратегий дифференцированной конфигурации для групп экземпляров включают, помимо прочего, следующее:
● Распределение ресурсов
Дифференцированная конфигурация позволяет эффективно реализовать более точное распределение ресурсов в соответствии с уникальными потребностями различных задач, охватывая несколько уровней, таких как вычислительные ресурсы, ресурсы хранения и сетевые ресурсы. Избегайте непроизводительной траты ресурсов и улучшайте их использование, чтобы гарантировать, что все задачи в кластере поддерживаются соответствующими ресурсами.
●Оптимизация планирования задач.
Для разных типов задач или заданий можно установить разные параметры конфигурации в соответствии с их характеристиками, чтобы оптимизировать планирование задач и эффективность выполнения.
● Отказоустойчивость и стабильность.
Благодаря дифференцированной конфигурации можно повысить отказоустойчивость и стабильность кластера. В зависимости от важности и нагрузки узла или группы экземпляров могут быть установлены различные механизмы отказоустойчивости и стратегии обработки сбоев, чтобы гарантировать, что кластер сможет поддерживать стабильную работу в условиях нештатных ситуаций.
● Управление затратами
Дифференцированная конфигурация также может помочь управлять затратами. В соответствии с потребностями бизнеса и бюджетными ограничениями можно разумно настроить различные группы экземпляров в кластере, чтобы избежать непроизводительной траты ресурсов, снизить затраты на эксплуатацию и обслуживание и найти баланс между производительностью и стоимостью.
Миграция кластера: плавный переход без остановки бизнеса
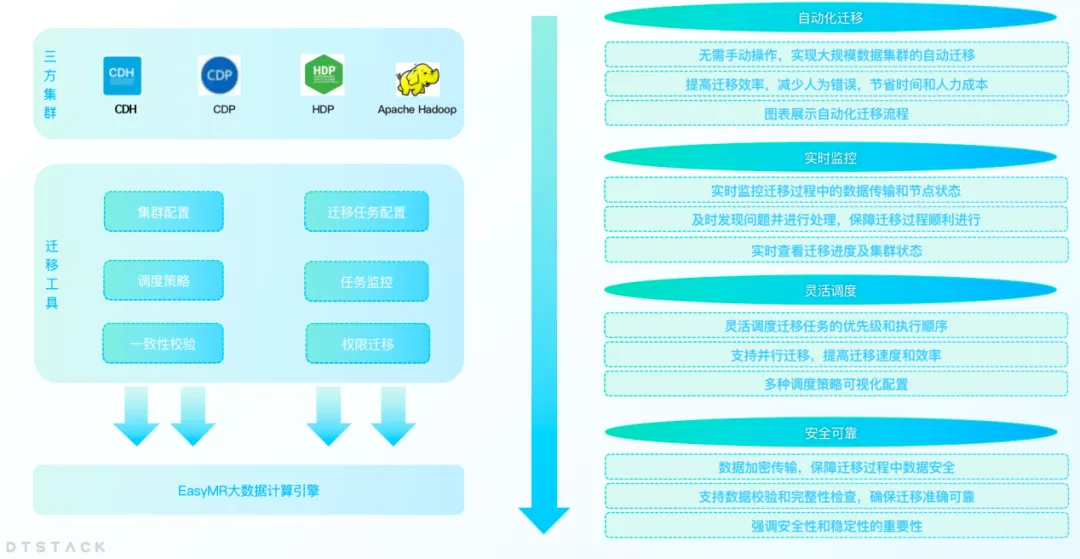
По мере развития бизнеса предприятия растущий объем данных часто приводит к таким проблемам, как недостаточная мощность центра обработки данных или изменения в центрах обработки данных. Предприятиям необходимо переносить данные из одного центра обработки данных в другой. В то же время в условиях замены локализации все больше компаний мигрируют неинновационные платформы, такие как CDH, HDP и CDP, на локализованные платформы больших данных. Поэтому компания EMR запустила функцию миграции кластеров больших данных , чтобы помочь предприятиям эффективно выполнить миграцию центров обработки данных.
Функция миграции кластеров позволяет пользователям беспрепятственно переносить свои кластеры больших данных между различными центрами обработки данных или облачными службами, не беспокоясь о потере данных или прерывании работы. Благодаря этой функции предприятия могут более гибко настраивать свою ИТ-инфраструктуру для адаптации к меняющимся потребностям рынка.
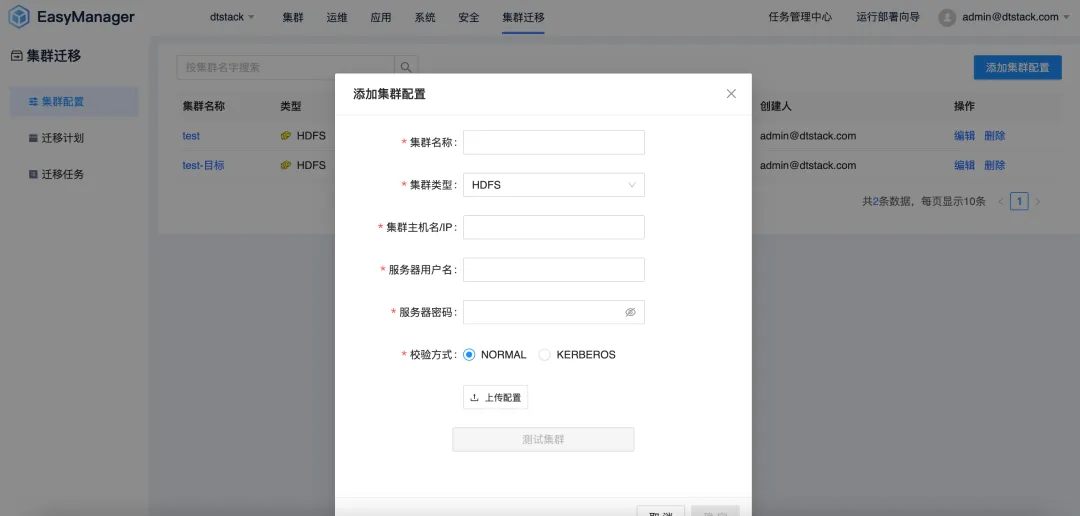
Обнаружено обновление двигателя: скачок производительности, новый опыт
Самое интересное то, что версия EMR6.2 добилась серьезного прорыва в производительности вычислительного механизма . Мы не только оптимизировали существующие вычислительные механизмы Spark и Flink, но также представили новые алгоритмы и технологии для повышения скорости обработки данных и эффективности вычислений. Это означает, что пользователи могут выполнять более сложные задачи анализа данных за более короткое время, тем самым ускоряя процесс принятия решений и повышая конкурентоспособность компании.
● Spark3 поддерживает оптимизацию индекса Z-oreder.
Z-Order — это технология, которая может сжимать многомерные данные в одно измерение. Для части данных мы можем рассматривать несколько полей, которые нужно отсортировать, как несколько измерений данных. Z-Order может передавать определенные правила сопоставления многомерных данных. одномерные данные.
В частности, значение z создается с помощью определенных правил . Значение z можно понимать как одномерные данные, упомянутые выше. На данный момент мы можем сортировать на основе одномерных данных. Как показано ниже:
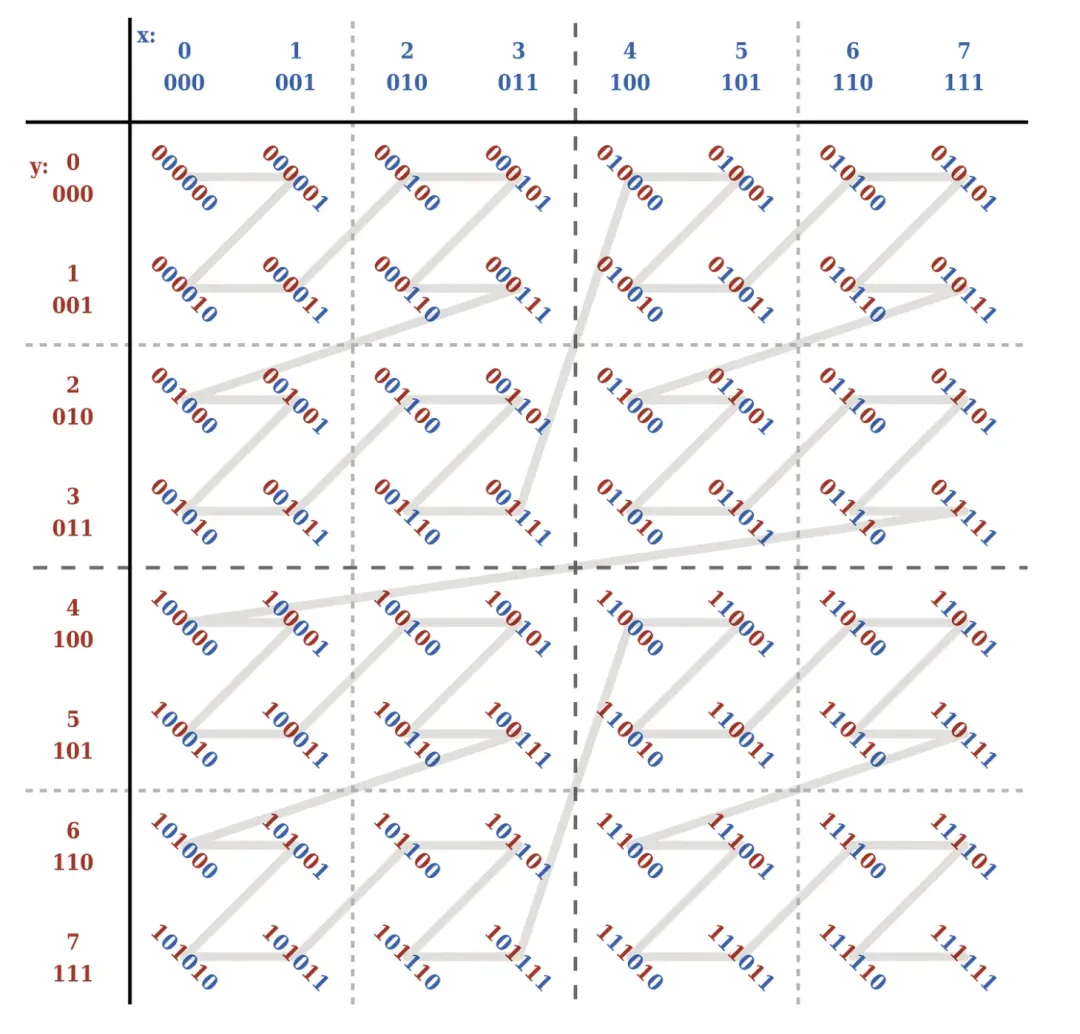
В Spark SQL компания Kangaroo Cloud добавила синтаксис OPTIMIZE XX ZORDER BY для поддержки индекса Z-Order, реализуя оптимизацию индекса Z-Order для таблицы INSERT INTO, таблицы INSERT OVERWRITE, таблицы CREATE TABLE AS SELECT, DISTINCT и других SQL.
Spark3 поддерживает оптимизацию Z-порядка, что значительно повышает эффективность обработки данных и запросов, снижает накладные расходы на ввод-вывод и ускоряет выполнение заданий. Оптимизация Z-порядка может сыграть важную роль, особенно в сценариях, где необходимо обрабатывать крупномасштабные наборы данных и сложные операции запросов. При решении проблемы скорости сжатия файлов после использования оптимизации Z-порядка степень сжатия файлов увеличилась почти на 20% по сравнению с ручной оптимизацией и увеличилась почти в 10 раз по сравнению с исходной задачей по сравнению с Spark3 с открытым исходным кодом. Задача, производительность также составляет почти 30%. Улучшение значительно повысило производительность и эффективность автономных операций.
● Flink Горячее обновление задачи для каждого задания.
В реальных производственных операциях часто происходят изменения параметров задачи в реальном времени или настройка оператора и функции. Обычно текущую задачу можно только сначала отменить, а затем выбрать CheckPoint для восстановления или повторного запуска. Весь процесс занимает около 3-5 минут. подождите, что очень сложно. Большая трата времени на разработку задачи.
Чтобы решить проблему прерывания обслуживания, вызванную обновлениями задач в традиционном режиме каждого задания, улучшить стабильность задач и доступность системы, а также удовлетворить требования к непрерывности бизнеса и высокой доступности в производственной среде. Команда Kangaroo Cloud Engine провела соответствующие исследования и улучшения исходного кода, а также оптимизировала горячий перезапуск задач в асинхронном обратном вызове отмены задачи для каждого задания :
① Сначала определите, существует ли в настоящее время новый кеш JobGraph. Если кеш есть, введите логику горячего перезапуска.
② Получите информацию CheckPoint об отмененной задаче и заполните ее в новом JobGraph.
③Обновите JobGrap до JobMaster и очистите информацию кэша JobGraph.
④Очистите ресурсы, управляемые SloyPool, в JobMaster.
⑤JobMaster повторно создает ScheduleNg и планирует его запуск. Это запустит новый запуск планирования JobGraph.
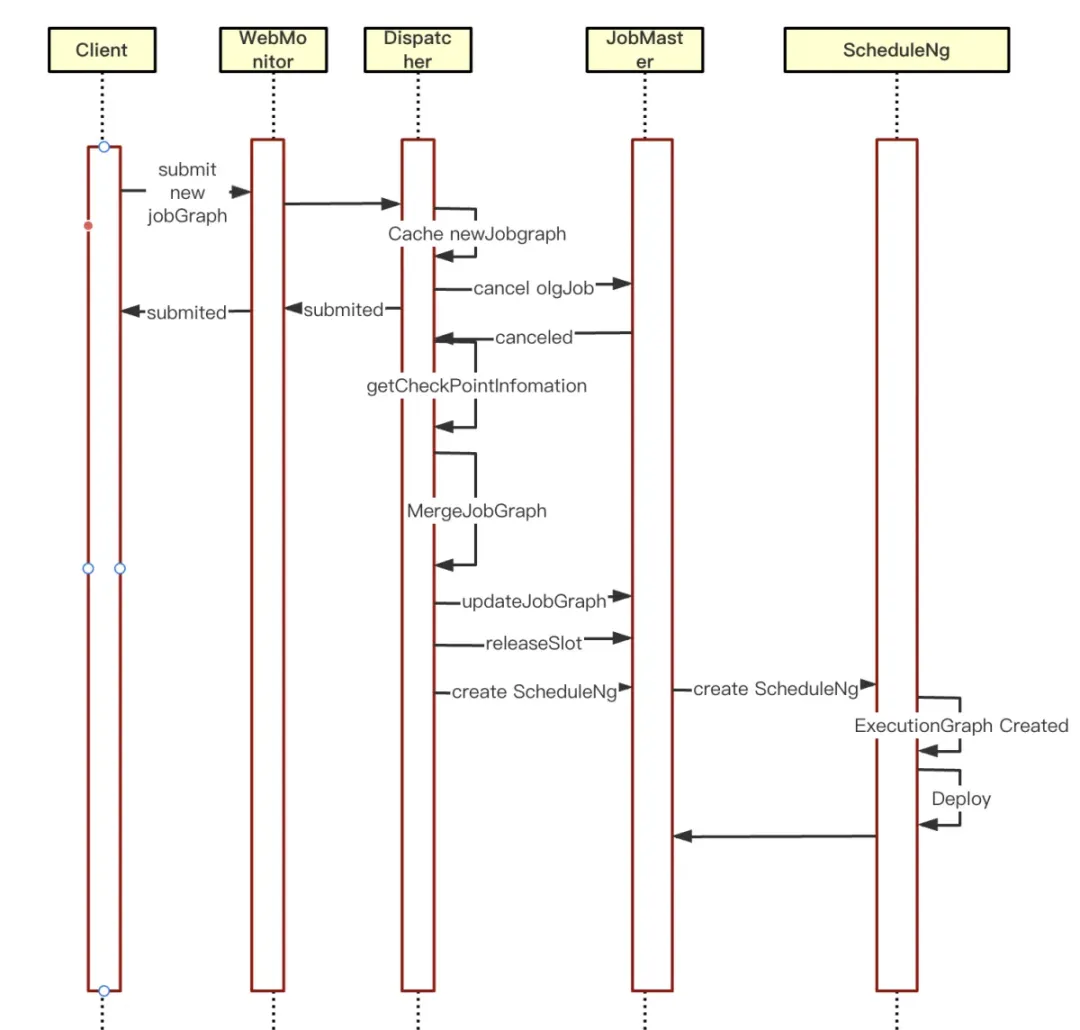
Оптимизация горячего обновления Flink для каждой задачи значительно повышает эффективность разработки, сокращает время простоев и повышает гибкость и надежность приложений. Для приложений реального времени, требующих быстрой итерации и динамической настройки, это обеспечивает максимальную эффективность.
Повышенная эффективность разработки: разработчики могут быстро тестировать и повторять код, не проходя утомительный процесс остановки и перезапуска, что ускоряет циклы разработки и позволяет выпускать более частые выпуски.
· Сокращение времени простоя. Горячие обновления могут минимизировать время простоя приложений, тем самым повышая доступность услуг, что особенно важно для критически важных приложений и приложений реального времени.
· Динамическая настройка параметров. Параметры конфигурации задания, такие как параллелизм или параметры оператора , можно динамически настраивать без перезапуска задания, что обеспечивает гибкую настройку на основе потока данных в реальном времени или условий нагрузки.
● Разработка других функций
Кроме того, что касается движка, мы также разработали такие функции, как стыковка Spark Ranger , оптимизация материализованного представления Spark и изоляция загрузки классов режима сеанса Flink, чтобы улучшить вычислительную производительность движка, одновременно повышая безопасность и масштабируемость задач движка.
Подведем итог
Подводя итог, можно сказать, что выпуск EMR6.2 знаменует собой еще одну важную веху для Kangaroo Cloud в области услуг больших данных. Благодаря оптимизации четырех основных функций, включая комплексное обновление и обновление пользовательского интерфейса, дифференцированную конфигурацию, миграцию кластера и обновление ядра, EMR6.2 предоставляет пользователям более мощную, гибкую и эффективную платформу для вычислений больших данных , помогая предприятиям в управлении данными и качественный скачок в анализе.
Адрес загрузки «Белой книги по системе отраслевых индикаторов»: https://www.dtstack.com/resources/1057?src=szsm
Адрес загрузки «Информационного документа о продукте Dutstack»: https://www.dtstack.com/resources/1004?src=szsm
Адрес для скачивания «Белой книги по отраслевой практике управления данными»: https://www.dtstack.com/resources/1001?src=szsm
Для тех, кто хочет узнать или получить дополнительную информацию о продуктах больших данных, отраслевых решениях и историях клиентов, посетите официальный сайт Kangaroo Cloud: https://www.dtstack.com/?src=szkyzg .
Линус взял на себя задачу не допустить, чтобы разработчики ядра заменяли табуляции пробелами. Его отец — один из немногих руководителей, умеющих писать код, его второй сын — директор отдела технологий с открытым исходным кодом, а младший сын — ядро с открытым исходным кодом. участник Робин Ли: Естественный язык станет новым универсальным языком программирования. Модель с открытым исходным кодом будет все больше и больше отставать от Huawei: потребуется 1 год, чтобы полностью перенести 5000 часто используемых мобильных приложений на язык Hongmeng, наиболее подверженный этому . сторонние уязвимости. Расширенный текстовый редактор Quill 2.0 был выпущен с функциями, надежностью и разработчиками. Опыт был значительно улучшен. Ма Хуатэн и Чжоу Хунъи пожали друг другу руки, чтобы «устранить обиды». Meta Llama 3 официально выпущен. источник Laoxiangji не является кодом, причины этого очень трогательны. Google объявил о масштабной реструктуризации.