

Источник статьи Интеллектуальная творческая группа ByteDance |
Мы рады поделиться с вами нашей последней моделью графа Винсента, SDXL-Lightning, которая обеспечивает беспрецедентную скорость и качество и теперь доступна сообществу.
Модель: https://huggingface.co/ByteDance/SDXL-Lightning
Статья: https://arxiv.org/abs/2402.13929 .

Молниеносное создание изображений
Генеративный искусственный интеллект привлекает внимание всего мира благодаря своей способности создавать потрясающие изображения и даже видео на основе текстовых подсказок. Однако современные генеративные модели основаны на диффузии — итеративном процессе, который постепенно преобразует шум в образцы изображений. Этот процесс требует огромных вычислительных ресурсов и является медленным. В процессе генерации образцов изображений высокого качества время обработки одного изображения составляет около 5 секунд, что обычно требует многократного обращения (от 20 до 40 раз) к огромной нейронной сети. . Эта скорость ограничивает сценарии приложений, требующие быстрой генерации в реальном времени. Как ускорить генерацию при одновременном повышении качества — это горячая область текущих исследований и основная цель нашей работы.
SDXL-Lightning преодолевает этот барьер благодаря инновационной технологии — прогрессивной состязательной дистилляции — для достижения беспрецедентной скорости генерации. Модель способна генерировать изображения чрезвычайно высокого качества и разрешения всего за 2 или 4 шага, сокращая вычислительные затраты и время в десять раз. Наш метод может даже генерировать изображения за 1 шаг для приложений, чувствительных к тайм-ауту, хотя некоторым качеством можно немного пожертвовать.
Помимо преимущества в скорости, SDXL-Lightning также обеспечивает значительную производительность в качестве изображения и превосходит предыдущие технологии ускорения в оценках. Достигайте более высокого разрешения и лучшей детализации, сохраняя при этом хорошее разнообразие и соответствие изображения и текста.
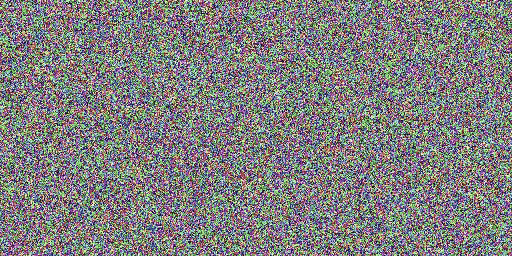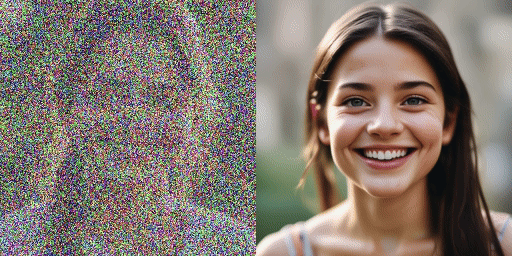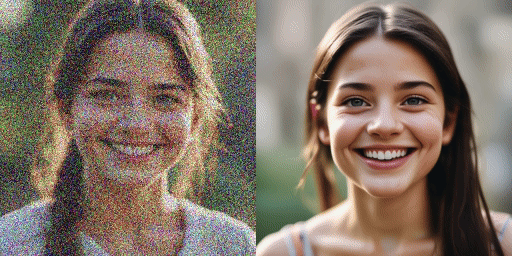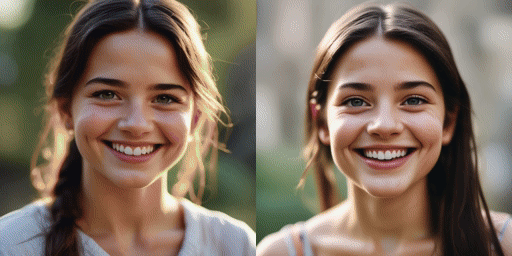 сравнение скорости
сравнение скорости
Оригинальная модель (20 шагов), наша модель (2 шага)
Эффект модели
Наша модель может генерировать изображения в 1, 2, 4 и 8 шагов. Чем больше шагов вывода, тем лучше качество изображения.
Вот результаты нашего 4-этапного процесса:
Вот результаты нашей двухэтапной сборки:
По сравнению с предыдущими методами (Турбо и LCM), наш метод генерирует изображения, которые значительно улучшены в деталях и более соответствуют стилю и макету исходной генеративной модели.

Верните сообществу, открытая модель
Волна открытого исходного кода стала ключевой силой в содействии быстрому развитию искусственного интеллекта, и ByteDance гордится тем, что является частью этой волны. Наша модель основана на SDXL, в настоящее время самой популярной открытой модели для изображений для генерации текста, которая уже имеет процветающую экосистему. Теперь мы решили открыть SDXL-Lightning для разработчиков, исследователей и творческих практиков по всему миру, чтобы они могли получить доступ к этой модели и применить ее для дальнейшего продвижения инноваций и сотрудничества во всей отрасли.
При разработке SDXL-Lightning мы учитывали совместимость с сообществом открытых моделей. Многие художники и разработчики сообщества создали различные модели создания стилизованных изображений, например, в стилях мультфильмов и аниме. Для поддержки этих моделей мы предоставляем SDXL-Lightning в качестве плагина для ускорения работы, который можно легко интегрировать в модели SDXL различных стилей, чтобы ускорить создание изображений для различных моделей.
 Нашу модель также можно комбинировать с очень популярным в настоящее время плагином управления ControlNet для достижения чрезвычайно быстрого и контролируемого создания изображений.
Нашу модель также можно комбинировать с очень популярным в настоящее время плагином управления ControlNet для достижения чрезвычайно быстрого и контролируемого создания изображений.
 Наша модель также поддерживает ComfyUI, в настоящее время самое популярное программное обеспечение поколения в сообществе с открытым исходным кодом, и модель можно загрузить непосредственно для использования:
Наша модель также поддерживает ComfyUI, в настоящее время самое популярное программное обеспечение поколения в сообществе с открытым исходным кодом, и модель можно загрузить непосредственно для использования: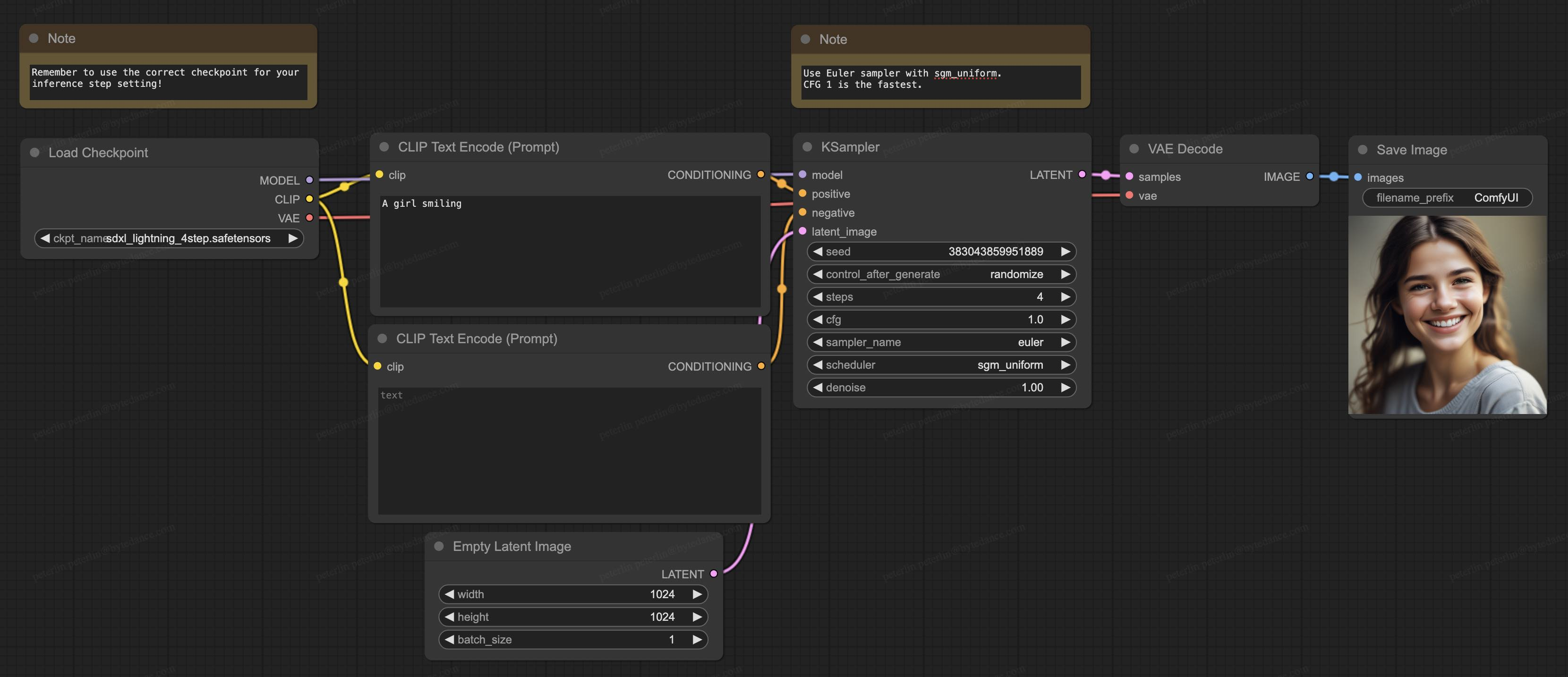
О технических деталях
Теоретически генерация изображения — это пошаговый процесс преобразования шума в четкое изображение. В этом процессе нейронная сеть изучает градиенты на различных позициях потока преобразования.
Конкретные шаги для создания изображения следующие: сначала мы случайным образом выбираем образец шума в начальной точке потока, а затем используем нейронную сеть для расчета градиента. На основе градиента в текущей позиции мы вносим небольшие корректировки в образец, а затем повторяем процесс. С каждой итерацией образцы приближаются к окончательному распределению изображений, пока не будет получено четкое изображение.
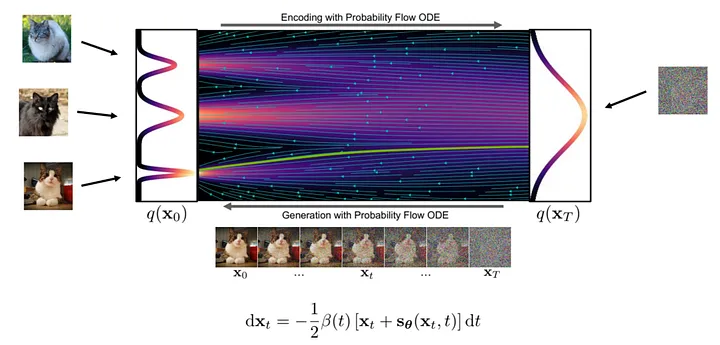 Рисунок: Процесс генерации ( изображение : https://arxiv.org/abs/2011.13456 )
Рисунок: Процесс генерации ( изображение : https://arxiv.org/abs/2011.13456 )
Поскольку поток генерации сложен и нелинейен, процесс генерации должен выполняться только небольшими шагами за раз, чтобы уменьшить накопление ошибок градиента, поэтому требуются частые вычисления нейронной сети, поэтому объем вычислений велик.
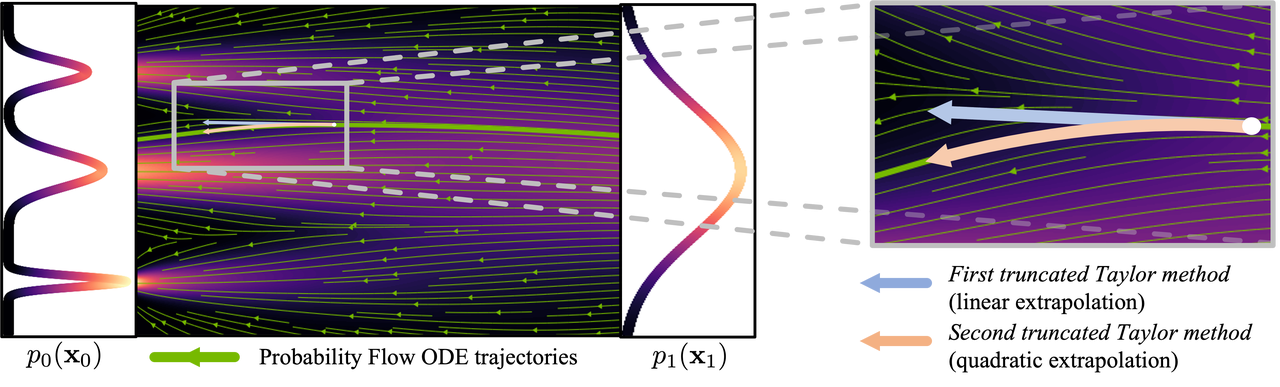 Рисунок: Процесс кривой ( изображение взято с сайта : https://arxiv.org/abs/2210.05475 )
Рисунок: Процесс кривой ( изображение взято с сайта : https://arxiv.org/abs/2210.05475 )
Чтобы сократить количество шагов, необходимых для создания изображений, поиску решений было посвящено много исследований. Некоторые исследования предлагают методы выборки, которые уменьшают ошибки, в то время как другие пытаются сделать генерируемый поток более линейным. Несмотря на достижения в этих методах, для создания изображений по-прежнему требуется более 10 шагов вывода.
Другой метод — дистилляция модели, которая позволяет генерировать высококачественные изображения менее чем за 10 шагов вывода. Вместо расчета градиента в текущем положении потока, дистилляция модели изменяет цель прогнозирования модели, чтобы напрямую предсказать следующее, более дальнее положение потока. В частности, мы обучаем сеть учеников напрямую предсказывать результат сети учителей после завершения многоэтапных рассуждений. Такая стратегия может значительно сократить количество необходимых шагов вывода. Повторно применяя этот процесс, мы можем еще больше сократить количество шагов вывода. Предыдущие исследования назвали этот подход прогрессивной дистилляцией.
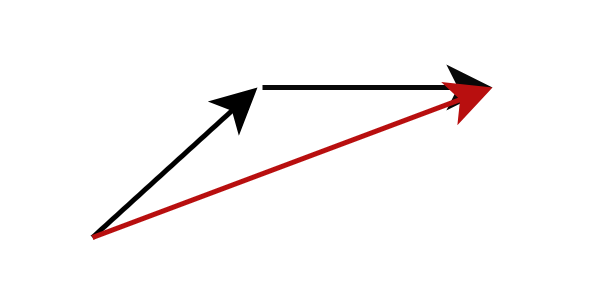 Рисунок: Прогрессивная дистилляция : сеть учеников предсказывает результат сети учителей после нескольких шагов.
Рисунок: Прогрессивная дистилляция : сеть учеников предсказывает результат сети учителей после нескольких шагов.
На практике студенческие сети часто испытывают трудности с точным прогнозированием будущих положений потока. Ошибка усиливается по мере накопления каждого шага, в результате чего изображения, создаваемые моделью, начинают становиться размытыми после менее чем 8 шагов вывода.
Чтобы решить эту проблему, наша стратегия состоит не в том, чтобы заставить сеть учеников точно соответствовать предсказаниям сети учителей, а в том, чтобы сделать сеть учеников согласованной с сетью учителей с точки зрения распределения вероятностей. Другими словами, студенческая сеть обучена предсказывать вероятностно возможное местоположение, и даже если это местоположение не совсем точно, мы не наказываем его. Эта цель достигается за счет состязательного обучения, которое вводит дополнительную дискриминационную сеть, помогающую достичь соответствия распределения результатов сети ученика и учителя.
Это краткий обзор наших методов исследования. В нашем техническом документе ( https://arxiv.org/abs/2402.13929 ) мы предоставляем более углубленный теоретический анализ, стратегию обучения и конкретные детали формулировки модели.
За пределами SDXL-Lightning
Хотя это исследование в основном посвящено использованию технологии SDXL-Lightning для генерации изображений, потенциал применения предлагаемого нами метода прогрессивной состязательной дистилляции не ограничивается статическими изображениями. Эту инновационную технологию также можно использовать для быстрого и качественного создания видео, аудио и другого мультимодального контента. Мы искренне приглашаем вас испытать SDXL-Lightning на платформе HuggingFace и с нетерпением ждем ваших ценных комментариев и отзывов.
Модель: https://huggingface.co/ByteDance/SDXL-Lightning
Статья: https://arxiv.org/abs/2402.13929 .
Товарищ-цыпленок «открыл исходный код» Deepin-IDE и наконец-то добился начальной загрузки! Хороший парень, Tencent действительно превратила Switch в «мыслящую обучающуюся машину». Обзор сбоев Tencent Cloud от 8 апреля и объяснение ситуации. Реконструкция запуска удаленного рабочего стола RustDesk. Веб-клиент . Терминальная база данных с открытым исходным кодом WeChat на основе SQLite. WCDB положила начало серьезному обновлению. Апрельский список TIOBE: PHP упал до рекордно низкого уровня, Фабрис Беллард, отец FFmpeg, выпустил инструмент сжатия звука TSAC , Google выпустил большую модель кода CodeGemma , она вас убьет? Это так хорошо, что это инструмент с открытым исходным кодом - инструмент для редактирования изображений и плакатов с открытым исходным кодом.