В современной разработке глубокого обучения мы обычно полагаемся на другие модули для создания сложных программных систем, таких как строительные блоки. Этот процесс часто бывает быстрым и эффективным. Однако вопрос о том, как быстро обнаруживать и решать проблемы при их возникновении, всегда беспокоил разработчиков и сопровождающих систем глубокого обучения из-за сложности и связанности системы.
Как член технической группы iQiyi, мы подробно записали процесс решения проблем, связанных с тренировкой глубокого обучения, связанных с памятью, в надежде вдохновить коллег, которые усердно работают над решением сложных проблем.
фон
В течение последнего квартала мы наблюдали случайные явления OOM процессорной памяти в кластере A100. С введением обучения на больших моделях ситуация стала еще более невыносимой, что заставило нас решить эту проблему.
Оглядываясь назад, туда, откуда я пришел, я внезапно почувствовал просветление. На самом деле, когда-то мы были очень близки к истине проблемы, но нам не хватило воображения, и мы ее упустили.
процесс
В самом начале мы провели индуктивный анализ исторических логов. Было обнаружено несколько правил, имеющих очень хорошее направляющее значение для окончательного решения:
-
Это новая проблема, возникшая в кластере A100 и не встречавшаяся в других кластерах.
-
Проблема связана с распределенным обучением pytorch ddp; другие режимы обучения с использованием pytorch не встречались.
-
Эта проблема OOM довольно случайна: некоторые возникают в течение 3 часов, а некоторые возникают только через неделю.
-
Всплеск памяти происходит во время OOM, в основном завершая увеличение с 10% до 90% в течение полутора минут, как показано на рисунке ниже:
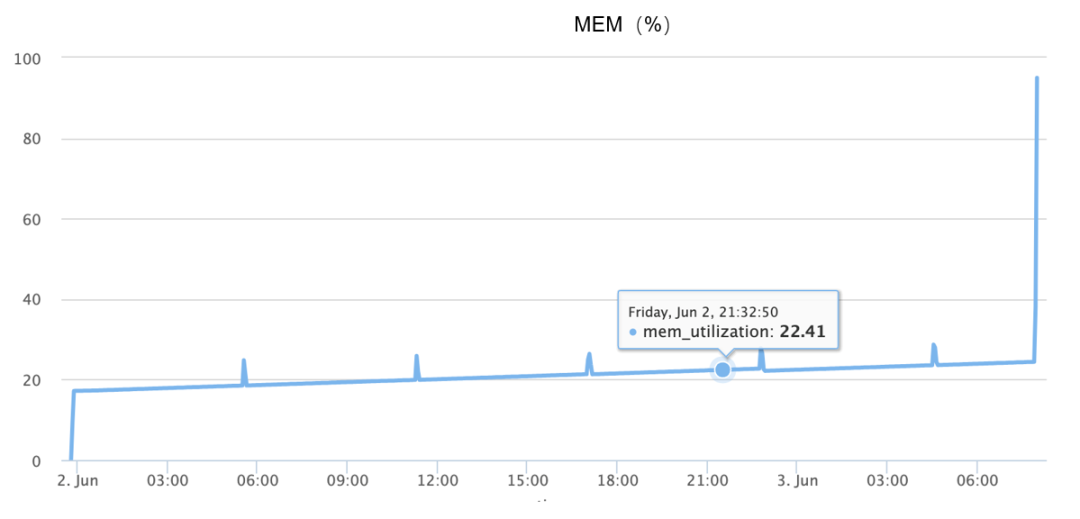
Хотя приведенная выше информация доступна, поскольку проблему невозможно воспроизвести достоверно, вначале я полностью полагался на разностороннее воображение и предположил множество возможных причин, таких как:
-
Может ли это быть проблема с кодом, поскольку объект не перерабатывается, что приводит к постоянным утечкам памяти?
-
Может ли это быть проблема с базовым распределителем памяти, аналогично тому, что распределитель PTMALLOC в glibc имеет слишком много фрагментов, поэтому в определенный момент внезапные запросы к памяти приводят к непрерывному выделению памяти?
-
Может ли это быть аппаратная проблема?
-
Может ли это быть ошибка в конкретной версии программы?
Ниже мы подробно представим первые два предположения.
Чтобы определить, является ли это проблемой кода, мы добавили отладочный код в сцену, где возникла проблема, и периодически вызывали его. Следующий код распечатает все объекты, которые не могут быть переработаны текущим модулем gc Python.
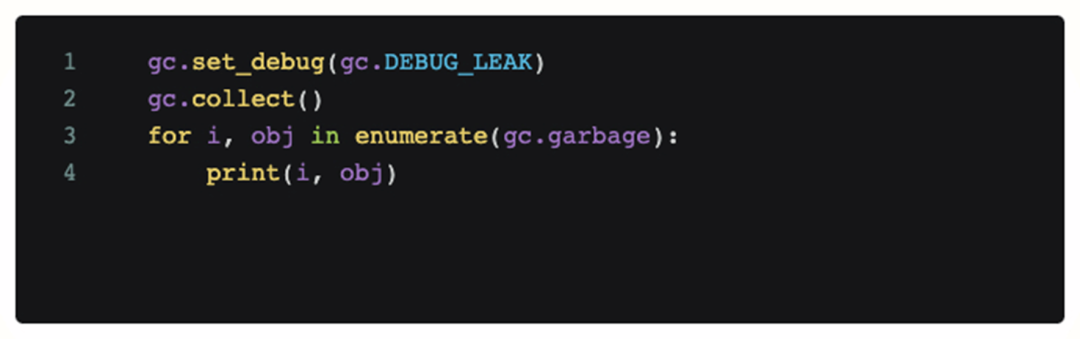 Однако после добавления этого кода полученный анализ журнала показывает, что не существует недостижимого объекта, занимающего много памяти во время OOM, а непрерывный сбор мусора сам по себе не может облегчить OOM. Итак, на данный момент наша первая догадка обанкротилась, проблема не вызвана кодом (утечка памяти).
Однако после добавления этого кода полученный анализ журнала показывает, что не существует недостижимого объекта, занимающего много памяти во время OOM, а непрерывный сбор мусора сам по себе не может облегчить OOM. Итак, на данный момент наша первая догадка обанкротилась, проблема не вызвана кодом (утечка памяти).
-
Это вызвано распределителем памяти?
На этом этапе мы представили распределитель памяти jemalloc. По сравнению с PTMALLOC по умолчанию в glibc, его преимущество состоит в том, что он может обеспечить более эффективное распределение памяти и лучшую поддержку для отладки самого распределения памяти. Этого можно достичь:
-
Может ли быть проблема с распределителем памяти по умолчанию?
-
Улучшенные инструменты отладки и анализа
Чтобы напрямую просмотреть текущий статус jemalloc в Python, не изменяя сам код Torch, мы использовали ctypes для предоставления интерфейса jemalloc непосредственно в Python:
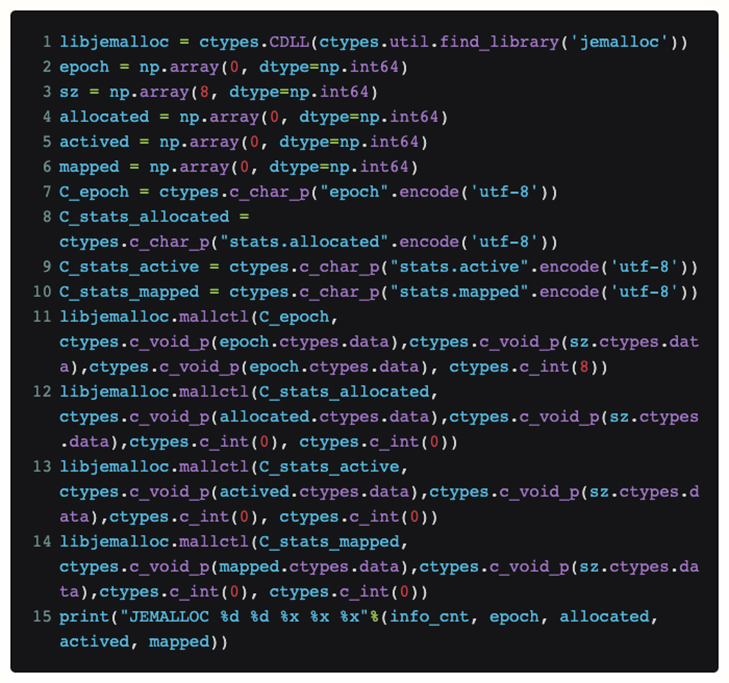
Таким образом, если мы поместим этот код в функцию, мы сможем периодически узнавать [выделенный] запрос, полученный в данный момент jemalloc от верхнего уровня, и фактический размер [отображенной] физической памяти, который он запрашивает из системы.
После фактического процесса воспроизведения было наконец обнаружено, что два выделенных и сопоставленных значения очень близки, когда происходит OOM. Итак, наша гипотеза о фрагментации памяти терпит крах.
-
Что именно вызвало проблему?
Когда мы были на исходе, мы еще раз разобрались с существующими журналами ООМ и обнаружили, что есть направление, на котором раньше не было внимания: то есть у нас было несколько машин, работающих в одинаковое время (1-2 минуты рядом) несколько раз ) происходит ООМ.
Так какое же логическое объяснение есть у этой волшебной синхронности? Обычные ошибки не должны вызывать повторения такой согласованности. Так что между ними может быть какая-то неизбежная связь.
Так откуда же взялась эта корреляция? Чтобы изучить эту проблему, аналитическая перспектива смещается к сетевому общению в распределенном обучении.
Первоначальное подозрение по поводу связи было сосредоточено на машинах, на которых наблюдался OOM. Предполагалось, что они по какой-то причине общались друг с другом, что могло вызвать проблемы друг с другом. Поэтому к ежедневному обучению для мониторинга сетевого трафика был добавлен tcpdump.
Наконец, после присоединения к tcpdump, я уловил самое сомнительное общение во время OOM. То есть машина OOM получила трафик сканирования безопасности за несколько минут до возникновения проблемы.
окончательное позиционирование
Обнаружив, что команда безопасности сканирует подозрительный объект, мы вместе с командой безопасности провели анализ и, наконец, обнаружили, что проблема OOM может стабильно воспроизводиться на основе сканирования, поэтому причина срабатывания была почти определена. Однако на данный момент мы можем только воспроизвести и изменить стратегию сканирования безопасности, чтобы избежать проблемы OOM. Нам также необходимо дополнительно проанализировать код и, наконец, найти его.
После анализа и позиционирования кода было окончательно установлено, что проблема заключается в протоколе распределенного обучения Pytorch. Соответствующий код выглядит следующим образом:
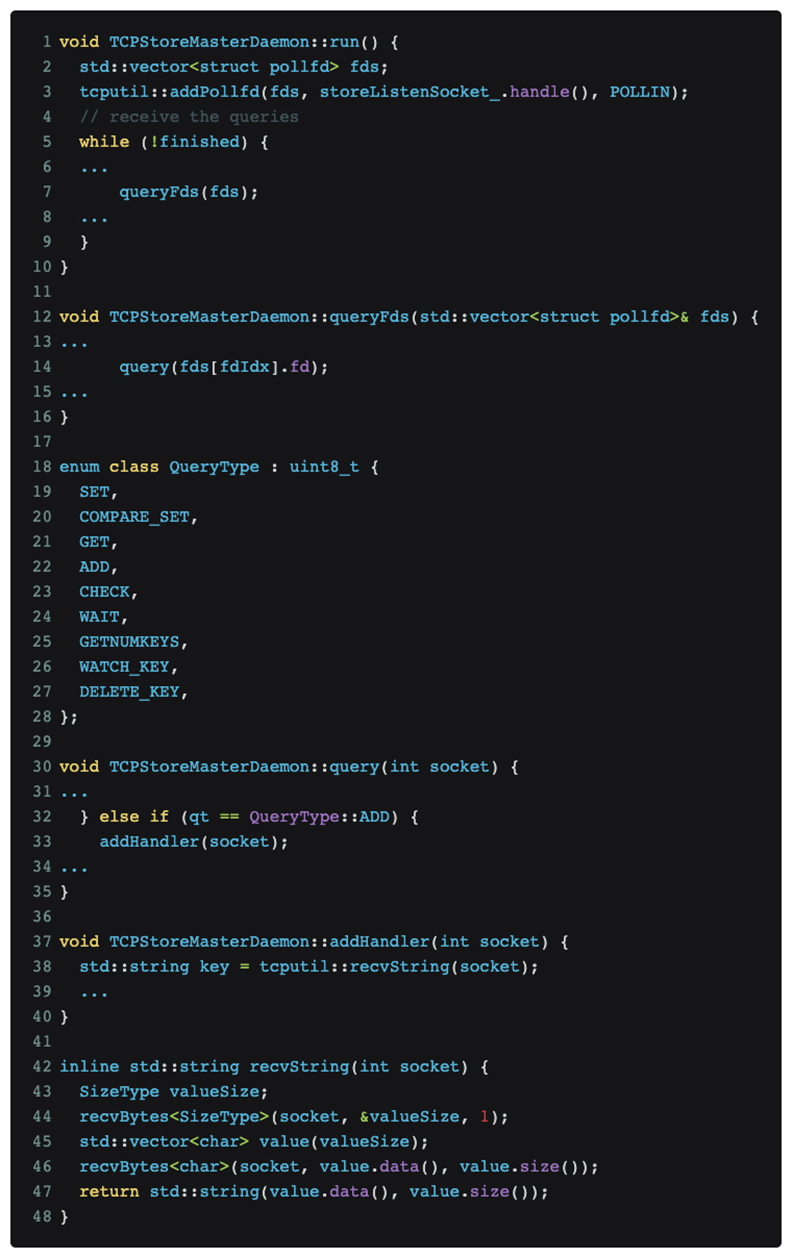
Как показано на рисунке выше, распределенное обучение pytorch продолжает прослушивать сообщения на главном порту.

Сканирование Nmap [nmap -sS -sV] вызвало тип сообщения QueryType::ADD, который представляет собой номер зеленого поля [03] в части данных, показанной на изображении tcpdump выше, что заставило pytorch попытаться использовать RecvString. функция для предварительного выделения буфера для получения того, что она считает последующими сообщениями. Но эта длина буфера анализируется с использованием типа uint64_t[little-endian] после [03], который представляет собой номер красного поля [e0060b0000], который составляет 962174058496 байт. Это значение подразумевает, что будут получены данные 1T, и pytorch. будет После того, как распределитель памяти запрашивает соответствующую память, распределитель памяти далее запрашивает соответствующую физическую страницу из ядра. Поскольку наш обучающий кластер графического процессора не настроен на огромную таблицу страниц, Linux может только постепенно удовлетворить запрос памяти 1T распределителя памяти в прерываниях отсутствия страниц в соответствии с детализацией 4 КБ, что означает, что выделение всей памяти занимает около 1 минуты, и Наблюдавшийся ранее ООМ, вероятно, возникает в ответ на быстрый рост памяти примерно за 1 минуту.
решение
Зная причину и следствие, решение становится естественным:
1. Краткосрочное: измените политику сканирования безопасности, чтобы избежать
2. В долгосрочной перспективе: общение с сообществом для повышения надежности [ 1 ]
Подведем итог
Завершив обратный процесс исследования проблем OOM, мы обнаружили, что в ходе этого процесса мы фактически провели эффективный раунд тестирования инструментов, связанных с памятью, и методов отладки.
В ходе этого процесса мы обнаружили, что есть некоторые общие моменты, которые можно использовать в качестве ссылки в последующих исследованиях и разработках:
-
Jemalloc может обеспечить очень эффективный количественный анализ проблем с памятью и выявить основные проблемы, связанные с памятью, в гибридных системах программирования, таких как Python+C.
-
Мемрей. В процессе отладки у нас были большие надежды на него, но в конце концов мы обнаружили, что область, в которой memray может работать лучше всего, по-прежнему находится на стороне чистого Python, и он не поддерживает гибридные системы программирования, такие как pytorch DDP.
Иногда нам все же нужно думать о проблемах в более широком измерении. Например, если процесс взаимодействия с внешними несвязанными службами не включен в рассмотрение, реальная основная причина не будет обнаружена.
Может быть, вы тоже хотите увидеть

