
01
фон
02
Введение в платформу журналов Venus
Venus — это платформа обслуживания журналов, разработанная iQiyi. Она обеспечивает сбор, обработку, хранение, анализ и другие функции. Она в основном используется для устранения неполадок журналов, анализа больших данных, мониторинга и оповещения внутри компании. Общая архитектура показана на рисунке. 1. показано.
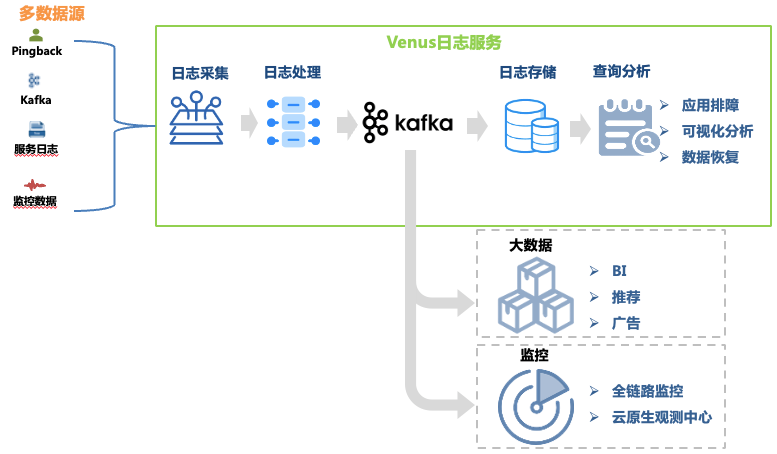 Рисунок 1. Связь с Венерой.
Рисунок 1. Связь с Венерой.
В этой статье основное внимание уделяется развитию архитектуры ссылки для устранения неполадок журнала. Ее ссылки на данные включают:
Сбор журналов : путем развертывания агентов сбора на компьютерах и хостах контейнеров собираются журналы из внешних, внутренних, мониторинговых и других источников каждого направления бизнеса, а также поддерживается возможность самостоятельной доставки журналов, соответствующих требованиям к формату. . Было развернуто более 30 000 агентов, поддерживающих 10 источников данных, таких как Kafka, MySQL, K8s и шлюзы.
Обработка журнала : после сбора журнала он подвергается стандартизированной обработке, такой как обычное извлечение и извлечение встроенным парсером, и единообразно записывается в Kafka в формате JSON, а затем записывается в систему хранения с помощью программы дампа.
Хранение журналов : Venus хранит около 10 000 потоков бизнес-журналов с пиковой скоростью записи более 10 миллионов запросов в секунду и ежедневными новыми журналами, превышающими 500 ТБ. По мере изменения масштаба хранилища выбор систем хранения претерпел множество изменений: от ElasticSearch до озера данных.
Анализ запросов : Venus обеспечивает визуальный анализ запросов, контекстный запрос, диск журнала, распознавание образов, загрузку журналов и другие функции.
Чтобы обеспечить хранение и быстрый анализ больших объемов данных журналов, платформа журналов Venus претерпела три крупных обновления архитектуры, постепенно превращаясь из классической архитектуры ELK в систему собственной разработки, основанную на озерах данных. В этой статье будут описаны возникающие проблемы. во время трансформации архитектуры и решений Venus.
03
Венера 1.0: на основе архитектуры ELK.
Версия Venus 1.0 стартовала в 2015 году и была построена на основе популярного в то время ElasticSearch+Kibana, как показано на рисунке 2. ElasticSearch отвечает за функции хранения и анализа журналов, а Kibana предоставляет возможности визуального запроса и анализа. Вам нужно только использовать Kafka и записывать журналы в ElasticSearch для предоставления услуг журналов.
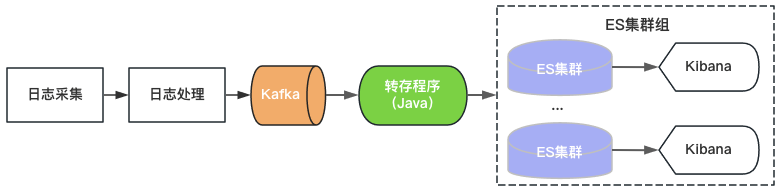 Рисунок 2. Архитектура Венеры 1.0
Рисунок 2. Архитектура Венеры 1.0
Поскольку существуют верхние ограничения на пропускную способность, емкость хранилища и количество сегментов индекса одного кластера ElasticSearch, Venus продолжает добавлять новые кластеры ElasticSearch, чтобы удовлетворить растущий спрос на журналы. Чтобы контролировать затраты, загрузка каждого ElasticSearch находится на высоком уровне, а индекс настроен на 0 копий. Часто встречаются такие проблемы, как внезапная запись трафика, большой запрос данных или сбой компьютера, приводящий к недоступности кластера. В то же время из-за большого количества индексов в кластере, большого объема данных и длительного времени восстановления логи долгое время недоступны, и опыт использования Venus становится все хуже.
04
Венера 2.0: на основе ElasticSearch + Hive
Классификация кластеров. Кластеры ElasticSearch делятся на две категории: высококачественные и низкокачественные. Ключевые предприятия используют высококачественные кластеры, нагрузка на кластер контролируется на низком уровне, а индекс включен с конфигурацией с 1 копией, чтобы выдерживать сбой одного узла, неключевые предприятия используют низкокачественный кластер, нагрузку; контролируется на высоком уровне, и индекс по-прежнему использует конфигурацию с нулевым копированием.
Классификация хранилища: ElasticSearch и Hive с двойной записью для журналов длительного хранения. ElasticSearch сохраняет журналы за последние 7 дней, а Hive сохраняет журналы в течение более длительного периода времени, что снижает нагрузку на хранилище ElasticSearch, а также снижает риск зависания ElasticSearch из-за запросов больших данных. Однако, поскольку Hive не может выполнять интерактивные запросы, журналы Hive необходимо запрашивать через автономную вычислительную платформу, что приводит к ухудшению качества запросов.
Единый портал запросов: предоставляет унифицированный визуальный портал запросов и анализа, аналогичный Kibana, защищающий базовый кластер ElasticSearch. При сбое кластера вновь записанные журналы планируются для других кластеров, не влияя на запросы и анализ новых журналов. Прозрачно планируйте трафик между кластерами, когда нагрузка на кластер несбалансирована.
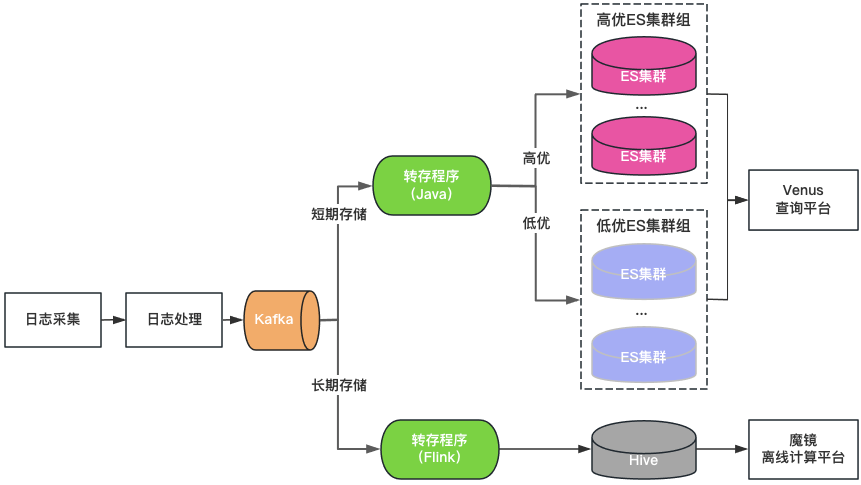
Рисунок 3. Архитектура Венеры 2.0
Venus 2.0 — это компромиссное решение для защиты ключевых предприятий и снижения риска и последствий сбоев. У него по-прежнему есть проблемы, связанные с высокой стоимостью и плохой стабильностью:
ElasticSearch имеет короткое время хранения: из-за большого количества журналов ElasticSearch может хранить только 7 дней, что не соответствует ежедневным потребностям бизнеса.
Много входов и фрагментация данных: более 20 кластеров ElasticSearch + 1 кластер Hive, много входов запросов, что очень неудобно для запросов и управления.
Высокая стоимость: хотя ElasticSearch хранит журналы только в течение 7 дней, он по-прежнему использует более 500 компьютеров.
Интегрированное чтение и запись: сервер ElasticSearch отвечает за одновременное чтение и запись, влияя друг на друга.
Множество ошибок: ошибки ElasticSearch составляют 80% от общего числа ошибок Venus. После ошибок чтение и запись блокируются, логи легко теряются, а обработка затрудняется.
05
Венера 3.0: новая архитектура на основе озера данных
Подумываю о внедрении озера данных
После углубленного анализа сценария журнала Венеры мы резюмируем его характеристики следующим образом:
Большой объем данных : почти 10 000 потоков бизнес-журналов с пиковой скоростью записи 10 миллионов запросов в секунду и хранилищем данных на уровне ПБ.
Пишите больше и меньше проверяйте . Бизнес обычно запрашивает журналы только тогда, когда возникает необходимость устранения неполадок. Большинство журналов не требуют запросов в течение дня, а общее количество запросов в секунду также чрезвычайно низкое.
Интерактивный запрос . Журналы в основном используются для устранения неполадок в срочных сценариях, требующих нескольких последовательных запросов и интерактивных запросов второго уровня.
Что касается проблем, возникающих при использовании ElasticSearch для хранения и анализа логов, мы считаем, что это не совсем соответствует сценарию логов Venus по следующим причинам:
Один кластер имеет ограниченное количество операций записи в секунду и масштаб хранилища, поэтому нескольким кластерам необходимо совместно использовать трафик. Необходимо учитывать сложные вопросы стратегии планирования, такие как размер кластера, трафик записи, пространство для хранения и количество индексов, что увеличивает сложность управления. Поскольку трафик бизнес-журналов широко варьируется и непредсказуем, чтобы устранить влияние внезапного трафика на стабильность кластера, часто необходимо зарезервировать больше простаивающих ресурсов, что приводит к огромной трате ресурсов кластера.
Полнотекстовая индексация во время записи потребляет много ресурсов ЦП, что приводит к расширению данных и значительному увеличению затрат на вычисления и хранение. Во многих сценариях хранение журналов анализа требует больше ресурсов, чем ресурсы фоновой службы. Для таких сценариев, как журналы, в которых много записей и мало запросов, предварительное вычисление полнотекстового индекса более удобно.
Данные хранения и вычисления выполняются на одном компьютере. Запросы больших объемов данных или совокупный анализ могут легко повлиять на запись, вызывая задержки записи или даже сбои кластера.
为了解决上述问题,我们调研了ClickHouse、Iceberg数据湖等替代方案。其中,Iceberg是爱奇艺内部选择的数据湖技术,是一种存储在HDFS或对象存储之上的表结构,支持分钟级的写入可见性及海量数据的存储。Iceberg对接Trino查询引擎,可以支持秒级的交互式查询,满足日志的查询分析需求。
针对海量日志场景,我们对ElasticSearch、ElasticSearch+Hive、ClickHouse、Iceberg+Trino等方案做了对比评估:
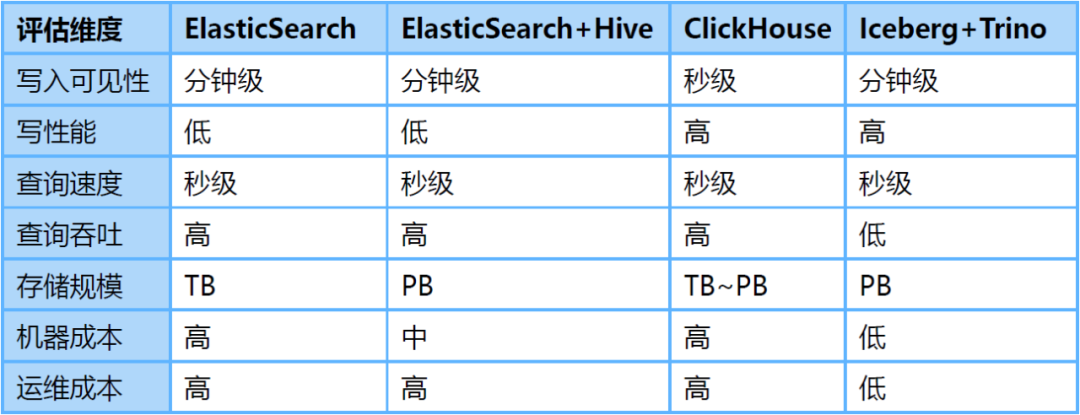
-
存储空间大:Iceberg底层数据存储在大数据统一的存储底座HDFS上,意味着可以使用大数据的超大存储空间,不需要再通过多个集群分担存储,降低了存储的维护代价。 -
存储成本低:日志写入到Iceberg不做全文索引等预处理,同时开启压缩。HDFS开启三副本相比于ElasticSearch的三副本存储空间降低近90%,相比ElasticSearch的单副本存储空间仍然降低30%。同时,日志存储可以与大数据业务共用HDFS空间,进一步降低存储成本。 -
计算成本低:对于日志这种写多查少的场景,相比于ElasticSearch存储前做全文索引等预处理,按查询触发计算更能有效利用算力。 -
存算隔离:Iceberg存储数据,Trino分析数据的存算分离架构天然的解决了查询分析对写入的影响。
基于数据湖架构的建设
通过上述评估,我们基于Iceberg和Trino构建了Venus 3.0。采集到Kafka中的日志由转存程序写入Iceberg数据湖。Venus查询平台通过Trino引擎查询分析数据湖中的日志。架构如图4所示。
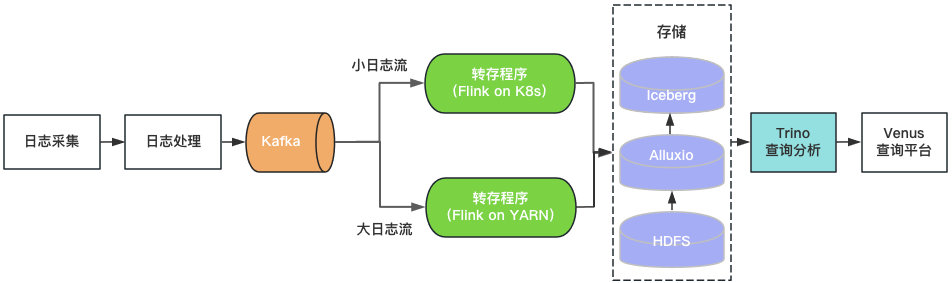 图4 Venus 3.0架构
图4 Venus 3.0架构
-
日志存储
-
查询分析
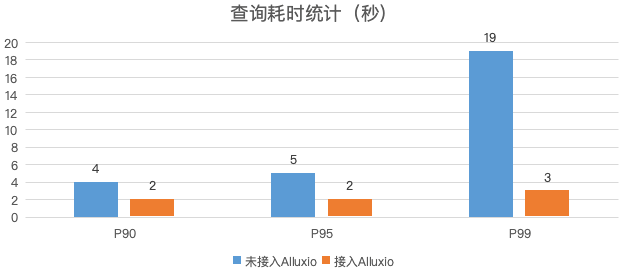
图5 日志查询性能对比
-
转存程序
-
落地效果
-
存储空间 :日志的物理存储空间降低30%,考虑到ElasticSearch集群的磁盘存储空间利用率较低,实际存储空间降低50%以上。 -
计算资源 :Trino使用的CPU核数相比于ElasticSearch减少80%,转存程序资源消耗降低70%。 -
稳定性提升:迁移到数据湖后,故障数降低了85%,大幅节省运维人力。
06
总结与规划
-
Iceberg+Trino的数据湖架构支持的查询并发较低,我们将尝试使用Bloomfilter、Zorder等轻量级索引提升查询性能,提高查询并发,满足更多的实时分析的需求。 -
目前Venus存储了近万个业务日志流,日新增日志超过500TB。计划引入基于数据热度的日志生命周期管理机制,及时下线不再使用的日志,进一步节省资源。 -
如图1所示,Venus同时也承载了大数据分析链路的Pingback用户数据的采集与处理,该链路与日志数据链路比较类似,参考日志入湖经验,我们对Pingback数据的处理环节进行基于数据湖的流批一体化改造。目前已完成一期开发与上线,应用于直播监控、QOS、DWD湖仓等场景,后续将继续推广至更多的湖仓场景。详细技术细节将在后续的数据湖系列文章中介绍。

本文分享自微信公众号 - 爱奇艺技术产品团队(iQIYI-TP)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。