1. Введение в наборы данных
Набор данных CIFAR-10 состоит из 60 000 цветных изображений размером 32x32 в 10 категориях , 6000по одному изображению в каждой категории. Есть 50000обучающие изображения и 10000тестовые изображения.
Набор данных разделен на 5 обучающих пакетов и 1 тестовый пакет, каждый пакет содержит 10 000 изображений. Тестовый пакет содержит ровно 1000 случайно выбранных изображений из каждого класса. Обучающие пакеты содержат оставшиеся изображения в случайном порядке, но некоторые обучающие пакеты могут содержать больше изображений из одного класса, чем из другого. В общей сложности обучающий пакет содержит ровно 5000 изображений из каждого класса.
Подведем итог:
Size(大小):Изображение RGB 32×32, сам набор данных — канал BGR,
Num(数量):обучающий набор 50000 и тестовый набор 10000, всего 60000 изображений
Classes(十种类别):самолета (самолета), автомобиля (автомобиля), птицы (птицы), кота (кота), оленя (оленя) ), собака (собака), лягушка (лягушка), лошадь (лошадь), корабль (корабль), грузовик (грузовик)

Ссылка для скачивания
Dream是个帅哥Поделиться от блоггера ( ):
Ссылка: https://pan.baidu.com/s/1gKazlkk108V_1nrc68VoSQ . Код извлечения: 0213.
Папка набора данных
Набор данных CIFAR-100 (расширенный)
Этот набор данных аналогичен CIFAR-10, за исключением того, что он имеет 100 классов, и каждый класс содержит 600 изображений. Для каждого класса имеется 500 обучающих изображений и 100 тестовых изображений. 100 подкатегорий CIFAR-100 разделены на 20 широких категорий. У каждого изображения есть тег «хороший» (подкатегория, к которой оно принадлежит) и тег «грубый» (основная категория, к которой оно принадлежит).
Сравнение набора данных CIFAR-10 и набора данных MNIST
- Размеры разные: набор данных CIFAR-10 имеет 4 измерения, а набор данных MNIST имеет 3 измерения (четыре измерения CIRAR-10: количество образцов одновременно, высота изображения, ширина изображения, количество каналов изображения -> NHWC; три измерения MNIST: количество выборок, высота изображения, ширина изображения -> NHW)
- Типы изображений различаются: набор данных CIFAR-10 представляет собой изображение RGB (с тремя каналами), а набор данных MNIST представляет собой изображение в оттенках серого, поэтому набор данных CIFAR-10 имеет на одно измерение больше, чем набор данных MNIST. .
- Содержание изображений разное: набор данных CIFAR-10 показывает множество различных объектов (кошки, собаки, самолеты, автомобили...), а набор данных MNIST показывает рукописные цифры от 0 до 9, написанные разными людьми.
2. Чтение набора данных
Прочитайте набор данных
Выберите data_batch_1, чтобы визуализировать одно из изображений:
def unpickle(file):
import pickle
with open(file, 'rb') as fo:
dict = pickle.load(fo, encoding='bytes')
return dict
dict = unpickle('D:\PycharmProjects\model-fuxian\CIFAR\cifar-10-batches-py\data_batch_1')
print(dict)
Результаты вывода:
В пакете наборов данных есть 4 ключа словаря. Нам нужно использовать метку данных и содержимое данных (10000×32×32×3, 10000 трехканальных изображений RGB 32×32).

:
{ b'batch_label': b'обучающий пакет 1 из 5', b'labels': [6, 9 … 1,5], b'data': array([[ 59, 43, …, 84, 72], …[ 62, 61, 60, …, 130, 130, 131]], dtype=uint8), b'filenames': [b'leptodactylus_pentadactylus_s_000004.png',…b'cur_s_000170.png'] }
Среди них значение каждого представителя следующее:
b'batch_label': набор файлов, которому он принадлежит
b'labels': метка изображения
b'data' : данные изображения
b'filename' : имя изображения
Тип чтения
print(type(dict[b'batch_label']))
print(type(dict[b'labels']))
print(type(dict[b'data']))
print(type(dict[b'filenames']))
Результат вывода:
<класс «байты»>
<класс «список»>
<класс «numpy.ndarray»>
<класс «список»>
Читать картинки
img = dict[b'data']
print(img.shape)
Выходной результат: (10000, 3072), где 3072 = 32 * 32 * 3 (размер изображения)
3. Вызов набора данных
Вызовы TensorFlow
from tensorflow.keras.datasets import cifar10
(x_train,y_train), (x_test, y_test) = cifar10.load_data()
местный звонок
def unpickle(file):
import pickle
with open(file, 'rb') as fo:
dict = pickle.load(fo, encoding='bytes')
return dict
dict = unpickle('D:\PycharmProjects\model-fuxian\CIFAR\cifar-10-batches-py\data_batch_1')
4. Обучение сверточной нейронной сети
Ссылка здесь: Портал
1.Укажите графический процессор
gpus = tf.config.experimental.list_physical_devices('GPU')
tf.config.experimental.set_memory_growth(gpus[0],True)
#初始化
plt.rcParams['font.sans-serif'] = ['SimHei']
2. Загрузите данные
cifar10 = tf.keras.datasets.cifar10
(train_x,train_y),(test_x,test_y) = cifar10.load_data()
print('\n train_x:%s, train_y:%s, test_x:%s, test_y:%s'%(train_x.shape,train_y.shape,test_x.shape,test_y.shape))
3. Предварительная обработка данных
X_train,X_test = tf.cast(train_x/255.0,tf.float32),tf.cast(test_x/255.0,tf.float32) #归一化
y_train,y_test = tf.cast(train_y,tf.int16),tf.cast(test_y,tf.int16)
4. Постройте модель
Параметры алгоритма Адама используют общедоступные параметры keras по умолчанию, функция потерь использует разреженную функцию перекрестных энтропийных потерь, а точность использует функцию точности разреженной классификации.
model = tf.keras.Sequential()
##特征提取阶段
#第一层
model.add(tf.keras.layers.Conv2D(16,kernel_size=(3,3),padding='same',activation=tf.nn.relu,data_format='channels_last',input_shape=X_train.shape[1:])) #卷积层,16个卷积核,大小(3,3),保持原图像大小,relu激活函数,输入形状(28,28,1)
model.add(tf.keras.layers.Conv2D(16,kernel_size=(3,3),padding='same',activation=tf.nn.relu))
model.add(tf.keras.layers.MaxPool2D(pool_size=(2,2))) #池化层,最大值池化,卷积核(2,2)
#第二层
model.add(tf.keras.layers.Conv2D(32,kernel_size=(3,3),padding='same',activation=tf.nn.relu))
model.add(tf.keras.layers.Conv2D(32,kernel_size=(3,3),padding='same',activation=tf.nn.relu))
model.add(tf.keras.layers.MaxPool2D(pool_size=(2,2)))
##分类识别阶段
#第三层
model.add(tf.keras.layers.Flatten()) #改变输入形状
#第四层
model.add(tf.keras.layers.Dense(128,activation='relu')) #全连接网络层,128个神经元,relu激活函数
model.add(tf.keras.layers.Dense(10,activation='softmax')) #输出层,10个节点
print(model.summary()) #查看网络结构和参数信息
#配置模型训练方法
model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['sparse_categorical_accuracy'])
5. Обучите модель
Размер пакетного обучения — 64, итерация — 5, а коэффициент тестового набора — 0,2 (48 000 данных обучающего набора, 12 000 данных тестового набора).
history = model.fit(X_train,y_train,batch_size=64,epochs=5,validation_split=0.2)
6. Оцените модель
model.evaluate(X_test,y_test,verbose=2) #每次迭代输出一条记录,来评价该模型是否有比较好的泛化能力
#保存整个模型
model.save('CIFAR10_CNN_weights.h5')
7. Визуализация результатов
print(history.history)
loss = history.history['loss'] #训练集损失
val_loss = history.history['val_loss'] #测试集损失
acc = history.history['sparse_categorical_accuracy'] #训练集准确率
val_acc = history.history['val_sparse_categorical_accuracy'] #测试集准确率
plt.figure(figsize=(10,3))
plt.subplot(121)
plt.plot(loss,color='b',label='train')
plt.plot(val_loss,color='r',label='test')
plt.ylabel('loss')
plt.legend()
plt.subplot(122)
plt.plot(acc,color='b',label='train')
plt.plot(val_acc,color='r',label='test')
plt.ylabel('Accuracy')
plt.legend()
8. Используйте модели
plt.figure()
for i in range(10):
num = np.random.randint(1,10000)
plt.subplot(2,5,i+1)
plt.axis('off')
plt.imshow(test_x[num],cmap='gray')
demo = tf.reshape(X_test[num],(1,32,32,3))
y_pred = np.argmax(model.predict(demo))
plt.title('标签值:'+str(test_y[num])+'\n预测值:'+str(y_pred))
plt.show()
Выходные результаты:

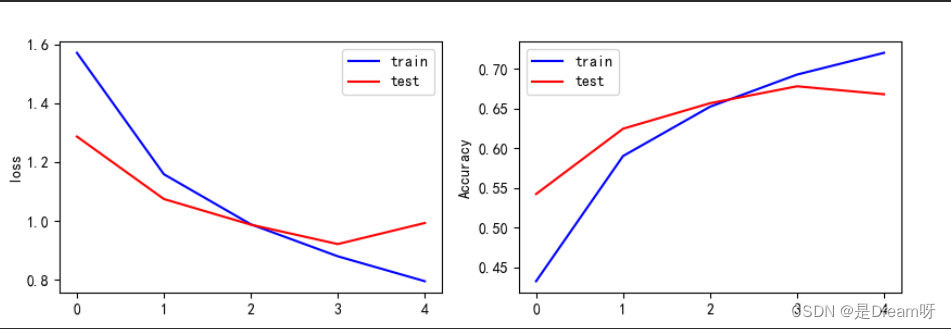
приведенное выше содержимое представляет собой значение функции потерь и точность обучающей выборки, а также значение функции потерь и точность тестовой выборки. Вы можете увидеть изменения в функции потерь и точности на каждой итерации обучения, начиная с последней. Результат итерации Кажется, что значение функции потерь тестового образца достигает 0,9123, а точность достигает только 0,6839.
Этот результат не очень хороший.Я попробовал увеличить количество итераций и обнаружил, что значение функции потерь обучающей выборки может достигать 0,04, а точность достигать 0,98; но на самом деле модель обучения давала возрастающие ошибки обобщения.Это обучение Феномен избыточности заключается в том, что после попытки лучшая способность к обобщению достигается на 5-й итерации, поэтому мы можем выбрать повторение только 5 раз.

Файл обученной модели — использовать напрямую
Введение в набор данных CIFAR10 и использование сверточных нейронных сетей для обучения моделей классификации изображений — прилагается полный код и файлы обученной модели — используйте напрямую: https://download.csdn.net/download/weixin_51390582/88788820