Чтобы разобраться в вопросах интервью, связанных с основами Java, в основном обращайтесь к книге «Мысли о программировании на Java» (4-е издание, написанное Брюсом Экелем, переведенное Чэнь Хаопэном), а остальная часть книги будет включать в себя контент, связанный с сетью. Обратите внимание, что вопросы собеседования о параллельном программировании JVM и Java организованы отдельно, поскольку они содержат много контента.
Система типов Java
Типы данных Java
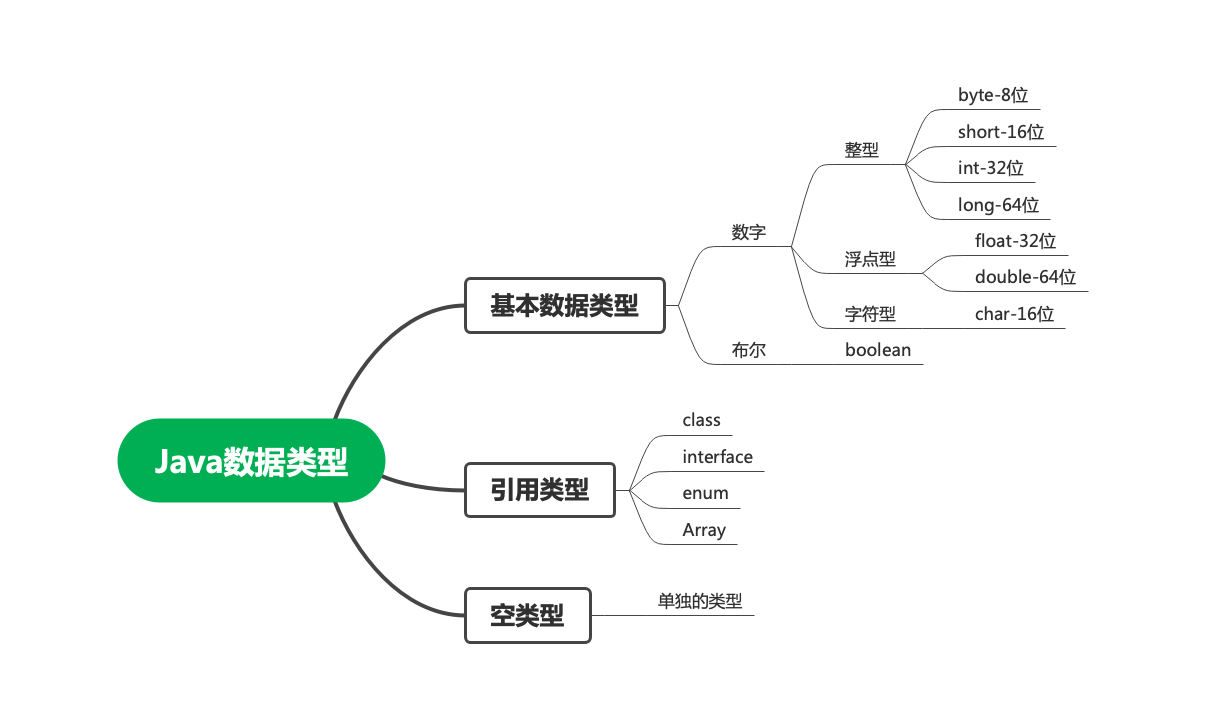
Типы данных Java можно в основном разделить на три категории: базовые типы данных (целые, с плавающей запятой, символьные, логические), ссылочные типы (класс объекта и его подклассы, интерфейсы, перечисления, массивы) и пустые типы. Следовательно, с точки зрения типов данных Java не является строго объектно-ориентированным языком. Схема следующая:
Проблема потери точности с плавающей запятой
Язык Java обрабатывает числа с плавающей запятой, и его логика реализации отличается от логики целых чисел. При неправильном использовании это может вызвать такие проблемы, как потеря точности, неточные вычисления и бесконечные циклы. В серьезных случаях это может привести к экономическим потерям. . Эта статья начнется с потери точности чисел с плавающей запятой и подробно представит принципы и использование чисел с плавающей запятой.
(1) Почему происходит потеря точности?
Компьютеры используют двоичный формат для хранения данных. Из-за ограничений двоичного формата он не может точно представлять все десятичные дроби. Числа с плавающей запятой состоят из целой и десятичной частей, что означает, что компьютер не может точно представлять числа с плавающей запятой. То есть в компьютерах числа с плавающей запятой страдают от потери точности. Здесь мы возьмем преобразование десятичного числа в двоичное в качестве примера, чтобы объяснить, почему двоичный код не может точно представлять десятичные числа.
Метод преобразования десятичных чисел в двоичные числа заключается в «умножении на 2, округлении и расположении по порядку». Основная идея заключается в следующем: умножьте текущую десятичную дробь на два, затем возьмите целую часть произведения и остановите расчет, если десятичная часть произведения равна нулю или достигает требуемой точности. В противном случае умножьте оставшуюся десятичную часть на два, чтобы получить другое произведение, а затем выньте целую часть произведения и так далее. После завершения вычислений целые числа, взятые для каждого выполнения, располагаются по порядку: целое число, взятое первым, используется в качестве старшего значащего бита двоично-десятичного числа, а целое число, взятое позже, используется в качестве младшего значащего бита. Вот как преобразовать десятичное число 0,8125 в двоичное десятичное число.

Конечно, существуют также десятичные дроби, для которых невозможно точно применить двоичное представление. Например, десятичное 0,7.

Десятичные дроби, которые не могут быть представлены в двоичном формате, могут быть представлены только приблизительно в зависимости от точности.
(2) Базовая реализация хранения
чисел с плавающей запятой отличается от хранения целых чисел.Числа с плавающей запятой при хранении в компьютере делятся на три части: бит знака, бит экспоненты и бит мантиссы. Его абстрактная формула:
( − 1 ) S ∗ ( 1. M . . . ) ∗ 2 E (-1)^S*(1.M...)*2^E( - 1 )С∗( 1. М ... )∗2Е
где,ССS представляет знак (положительное число, отрицательное число), E представляет показатель степени, а M представляет собой мантиссу. В Java float — это 32-битное хранилище, а double — 64-битное хранилище.Длина хранения каждой части равна:
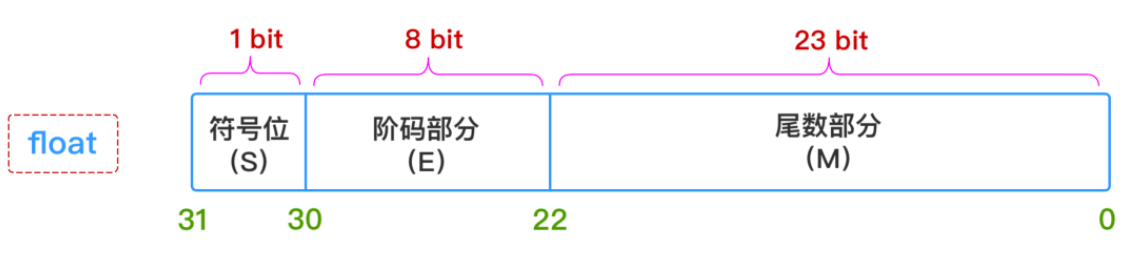
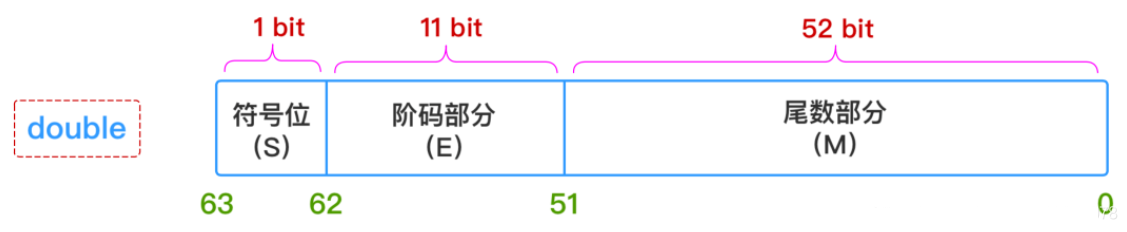 потому что бит экспоненты влияет на размер числа, а бит экспоненты определяет диапазон размеров. Десятичные знаки определяют точность вычислений. Чем больше число, которое могут представлять десятичные знаки, тем выше точность вычислений.
потому что бит экспоненты влияет на размер числа, а бит экспоненты определяет диапазон размеров. Десятичные знаки определяют точность вычислений. Чем больше число, которое могут представлять десятичные знаки, тем выше точность вычислений.
Число с плавающей запятой имеет только 23 десятичных знака, что соответствует 23 двоичным цифрам. Наибольшее десятичное число, которое можно представить, равно 2 в 23-й степени, то есть 8388608, что составляет 7 десятичных цифр. Строго говоря, точность может быть гарантирована на 100% только при быть 6 десятичных цифр.Битовые операции.
В формате double 52 десятичных знака, а соответствующее максимальное десятичное значение составляет 4 503 599 627 370 496. Это число состоит из 16 цифр, поэтому точность расчета может быть гарантирована на 100% только для 15-значных десятичных операций.
(3) Операции с числами с плавающей запятой
Поскольку числа с плавающей запятой не могут точно представлять десятичные дроби, при выполнении операций с числами с плавающей запятой (арифметические операции, операции сравнения и т. д.) необходимо учитывать возможные проблемы, вызванные потерей точности. Здесь мы возьмем сравнение чисел с плавающей запятой в качестве примера, чтобы представить проблему бесконечного цикла, вызванную сравнением двух чисел с плавающей запятой.
public void createEndlessLoop() {
double a = 1.6;
double b = 0.3;
double c = a + b;
double d = 1.9;
while (c != d) {
System.out.println("c: " + c + ", d: " + d);
}
System.out.print("c == d");
}
Когда вышеуказанный метод будет выполнен, метод войдет в бесконечный цикл. При сравнении чисел с плавающей запятой результаты сравнения часто противоречат ожиданиям из-за проблемы потери точности. Основная идея состоит в том, чтобы ввести ошибки для облегчения сравнения чисел с плавающей запятой, но этот подход по-прежнему не может удовлетворить некоторые сценарии. Более подробное раскрытие этой идеи можно найти по ссылке .
(4) Как избежать потери точности
Итак, как избежать проблемы потери точности чисел с плавающей запятой. На самом деле, универсального решения этой проблемы не существует. Выберите подходящий метод обработки в соответствии с различными бизнес-сценариями. Если есть возможность не выполнять операции с числами с плавающей запятой, старайтесь не использовать для операций числа с плавающей запятой. Если для вычислений необходимо использовать числа с плавающей запятой, выберите соответствующий метод обработки в зависимости от сценария. Например, в четырех сценариях арифметических операций с числами с плавающей запятой используйте BigDecimal. Сравнение с плавающей запятой вводит порог ошибки. Правильный способ решения предыдущей проблемы заключается в следующем:
public void createEndlessLoopWithBigDecimal() {
BigDecimal a = new BigDecimal("1.6");
BigDecimal b = new BigDecimal("0.3");
BigDecimal c = a.add(b);
BigDecimal d = new BigDecimal("1.9");
while (c.doubleValue() != d.doubleValue()) {
System.out.println("c: " + c.doubleValue() + ", d: " + d.doubleValue());
}
System.out.print("c == d");
}
Обратите внимание, что экземпляр BigDecimal не инициализируется в форме "BigDecimal a = new BigDecimal(1.6);", поскольку числа с плавающей запятой не могут быть представлены точно, поэтому BigDecimal, созданный с использованием BigDecimal(Double), может потерять точность. Результат присваивания может быть другим от фактической стоимости. Рассмотрим следующий код, который вводит бесконечный цикл.
public void createEndlessLoopWithBigDecimal() {
BigDecimal a = new BigDecimal(1.6);
BigDecimal b = new BigDecimal(0.3);
BigDecimal c = a.add(b);
BigDecimal d = new BigDecimal(1.9);
while (c.doubleValue() != d.doubleValue()) {
System.out.println("c: " + c.doubleValue() + ", d: " + d.doubleValue());
}
System.out.print("c == d");
}
Дополнительные подводные камни при использовании BigDecimal можно найти по ссылке .
Использование BigDecimal
Когда числа с плавающей запятой хранятся в компьютерах, возникает проблема потери точности . Если вы столкнулись с арифметическими операциями с плавающей запятой или операциями сравнения, рекомендуемый подход — использовать BigDecimal.
При использовании BigDecimal для операций с числами с плавающей запятой, согласно «Руководству по разработке Java» Alibaba , существуют следующие сокращения программирования:
Первое сокращение программирования:

Второе сокращение программирования: Для получения дополнительной информации об анализе исходного кода BigDecimal обратитесь к предыдущей статье

автора.
преобразование типов
автоматическое преобразование типов
бросать
Упаковка и распаковка
Упаковка — это использование механизма упаковки при преобразовании базовых типов данных в типы-оболочки. Функция автобокса доступна в Java SE5. Box в основном выполняет следующие операции:
(1) Выделяет память в куче Java. Помимо выделения памяти, необходимой для каждого поля базового типа данных, также необходимо добавить элементы, которые есть у каждого объекта в куче Java (заголовок объекта, информация о выравнивании и т. д.).
(2) Назначьте поля основных типов данных в стеке памяти указанной выше куче Java.
(3) Вернуть адрес объекта. Базовый тип данных преобразуется в тип-оболочку, и возвращается ссылочный адрес типа-оболочки.
Распаковка заключается в получении адреса каждого поля в упакованном объекте. Распаковка предназначена для упаковки. Если объекта упаковки нет, распаковка не будет найдена. Распаковка преобразует данные только в тот тип, для которого они были изначально распакованы. За операцией распаковки часто следует операция копирования поля. Так называемое копирование поля относится к копированию значения поля, соответствующего базовому типу данных, из кучи Java в экземпляр значения на основе стека памяти.
Пример кода для примеров упаковки и распаковки выглядит следующим образом:
int i = 1;
Integer a = i; //装箱
int j=(int)a; //拆箱
Упаковка и распаковка — это всего лишь проявление преобразования типов. Упаковка и распаковка возможны только для преобразований значений и ссылочных типов. Упаковка и распаковка являются подходящим подмножеством преобразования типов. Распаковка — это всего лишь случай кастинга.
Тип продвижения
автоматическое продвижение
Введение в класс объектов
Класс Java Object является родительским классом для всех классов. Это означает, что все классы Java наследуют Object, а подклассы могут использовать все методы Object. Поскольку все классы наследуются от класса Object, ключевое слово Extends Object опускается.
Обратите внимание, что, строго говоря, базовые типы данных не наследуются от Object. В основном это связано с соображениями производительности. (Другими словами, цель использования базовых типов для таких типов данных, как boolean, int, double и т. д., заключается в повышении производительности)
(1) Метод клонирования Метод клонирования — это защищенный метод, используемый для реализации неглубоких копий
объектов . Обратите внимание, что этот метод можно вызвать только в том случае, если реализован интерфейс Cloneable, в противном случае будет выброшено исключение CloneNotSupported . (2) Метод getClass Метод getClass — это последний метод, который возвращает ссылку на класс, представляющую фактический тип объекта. Метод getClass в основном используется в сценах отражения . (3) Метод toStringМетод toString используется для возврата строкового представления объекта. Этот метод широко используется (например, для получения сериализованного представления объекта) и обычно покрывается подклассами. (4) Метод Equals и метод hashCode Метод Equals определен в классе Object, и его первоначальное поведение заключается в сравнении адресов объектов в памяти. В практических приложениях метод равенства часто переопределяется. При переопределении метода равенства обязательно переопределите метод hashCode . Это связано с тем, что в контейнере хэш-таблицы (например, Hashtable, HashMap и т. д.) сначала будут сравниваться хеш-коды. Только когда хеш-коды равны, будет далее использоваться метод равенства для определения того, равны ли они (это в основном рассматривает метод равенства с проблемами производительности). (5) Метод ожидания, метод notify и метод notifyAll.Метод ожидания заставляет текущий поток ждать блокировки объекта.Текущий поток должен быть владельцем объекта, то есть он имеет блокировку объект. Метод wait() ожидает, пока блокировка не будет получена или прервана. wait(long timeout) устанавливает интервал тайм-аута и возвращает значение, если блокировка не получена в течение указанного времени. После вызова этого метода текущий поток переходит в состояние сна до тех пор, пока не произойдут следующие события: 1) Другие потоки вызывают метод notify или метод notifyAll объекта; 2) Другие потоки вызывают прерывание, чтобы прервать поток; 3) Временной интервал истек. . В это время поток можно запланировать. Если он будет прерван, будет выброшено InterruptedException. Метод notify может разбудить поток, ожидающий объекта, а метод notifyAll может разбудить все потоки, ожидающие объекта. (6) метод Finalize Этот метод используется для освобождения ресурсов. Прежде чем сборщик мусора будет готов освободить пространство памяти, занимаемое объектом, он сначала вызовет метод Finalize(). Не рекомендуется использовать метод Finalize или переопределять метод Finalize . Это происходит главным образом потому, что в Java сборщик мусора в основном автоматически перерабатывается, поэтому нет никакой гарантии, что метод Finalize будет выполнен вовремя (время переработки объектов мусора не определено), а также не может быть гарантировано, что они будут выполнены (при условии, что программа запускается с начала) Сборка мусора в итоге не сработала). Поскольку время вызова метода Finalize() не определено, время, которое проходит с момента, когда объект становится недоступным, до момента выполнения метода Finalize(), является сколь угодно длинным, поэтому вы не можете полагаться на то, что метод Finalize() будет способны своевременно перерабатывать занятые ресурсы. Если сборщик мусора не запустится до того, как ресурсы будут исчерпаны, метод Finalize() не будет выполнен. В этом сценарии обычным подходом является предоставление явного метода close(), чтобы клиент мог вызывать его вручную. Кроме того, переопределение метода Finalize() означает, что при перезапуске объектов потребуется больше операций, тем самым продлевая время перезапуска объектов.
Подробное объяснение hashCode
При определении того, существует ли элемент (содержится) в коллекции (выполнение метода containsXXX или метода put) , вы можете использовать метод равенства. Но если элементов слишком много, использование метода равенства для оценки приведет к проблемам с производительностью.
Эффективный способ — сравнить хеши, чтобы элемент можно было заменить целым числом. Если взять в качестве примера HashMap, то процесс его реализации выглядит следующим образом:
(1) При добавлении элемента использовать его хеш-код для вычисления индекса внутреннего массива (так называемого ведра)
(2) Если неравные элементы имеют одинаковый хэш code , затем они помещаются в одну корзину и объединяются вместе, как список для обработки коллизий хэшей.
(3) При выполнении операции содержимого используйте хеш-код с элементом поиска для расчета значения сегмента (значения индекса). Если в соответствующем значении индекса нет элемента, верните его напрямую, в противном случае сравните экземпляры с равными.
Используя этот метод, количество выполнения равных можно значительно сократить.
Равные элементы должны иметь одинаковое значение хеш-функции . Обратное утверждение таково: если хэш-код отличается, соответствующие элементы должны быть разными .
Поэтому, переписывая метод равенства, обязательно перепишите метод hashCode .
Генерация хэш-кода
Метод hashCode в Java отображает информацию, связанную с объектом (например, адрес хранения объекта, поля объекта и т. д.), в значение в соответствии с определенными правилами. Это значение называется хеш-значением.
Рекомендации по хэш-коду
Общие соглашения hashCode:
(1) При вызове одного и того же объекта в приложении Java метод hashCode всегда должен возвращать одно и то же целое число. Это целое число не обязательно должно быть одинаковым в разных приложениях Java.
(2) Согласно методу Equals(Object), если два объекта равны, вызов метода hashCode для обоих объектов должен привести к одному и тому же результату.
(3) Согласно методу Equals(Object), если два объекта не равны, то вызов метода hashCode для двух объектов не обязательно приведет к получению разных целочисленных результатов.
Метод hashCode объекта является собственным методом. В комментариях описано, что hashCode возвращает значение, преобразованное из адреса хранения объекта .
public native int hashCode();
Реализация исходного кода Java (Java 8) записана здесь:
static inline intptr_t get_next_hash(Thread * Self, oop obj) {
intptr_t value = 0 ;
if (hashCode == 0) {
// 根据Park-Miller伪随机数生成器生成的随机数
value = os::random() ;
} else if (hashCode == 1) {
// 此类方案将对象的内存地址,做移位运算后与一个随机数进行异或得到结果
intptr_t addrBits = cast_from_oop<intptr_t>(obj) >> 3 ;
value = addrBits ^ (addrBits >> 5) ^ GVars.stwRandom ;
} else if (hashCode == 2) {
value = 1 ; // 返回固定的1
} else if (hashCode == 3) {
value = ++GVars.hcSequence ; // 返回一个自增序列的当前值
} else if (hashCode == 4) {
value = cast_from_oop<intptr_t>(obj) ; // 对象地址
} else {
// 通过和当前线程有关的一个随机数+三个确定值
unsigned t = Self->_hashStateX ;
t ^= (t << 11) ;
Self->_hashStateX = Self->_hashStateY ;
Self->_hashStateY = Self->_hashStateZ ;
Self->_hashStateZ = Self->_hashStateW ;
unsigned v = Self->_hashStateW ;
v = (v ^ (v >> 19)) ^ (t ^ (t >> 8)) ;
Self->_hashStateW = v ;
value = v ;
}
value &= markOopDesc::hash_mask;
if (value == 0) value = 0xBAD ;
assert (value != markOopDesc::no_hash, "invariant") ;
TEVENT (hashCode: GENERATE) ;
return value;
}
Реализация перезаписи hashCode в String выглядит следующим образом:
/* The hash code for a
* {@code String} object is computed as
* <blockquote><pre>
* s[0]*31^(n-1) + s[1]*31^(n-2) + ... + s[n-1]
*/
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
hash = h = isLatin1() ? StringLatin1.hashCode(value)
: StringUTF16.hashCode(value);
}
return h;
}
Введение в класс String
Java использует класс String для представления строк. Все строковые литералы в Java (например, «abc») используют этот тип реализации. Строки являются константами, их значения не могут быть изменены после создания. Строковые буферы поддерживают изменяемые строки. Поскольку объекты String неизменяемы, их можно использовать совместно.
Неизменяемость строк
В Java String является неизменяемым, что в основном отражается в трех аспектах: (1) класс String модифицируется с помощью ключевого слова Final, указывающего, что он не наследуется; (2) Класс String использует байтовые массивы для хранения данных и использует последняя модификация ключевого слова означает, что ссылочный адрес этого поля является неизменяемым после его создания; (3) Разрешение доступа к этому массиву символов является частным, что означает, что к нему нельзя получить доступ извне, а String не предоставляет внешних методов для изменения этот атрибут. Ключевой исходный код выглядит следующим образом:
public final class String implements java.io.Serializable, Comparable<String>, CharSequence {
@Stable
private final byte[] value;
// ...
}
Обратите внимание, что базовая реализация строк использует хранилище байтовых массивов. Преимущество использования номеров байтов вместо массивов символов заключается в том, что массив байтов остается согласованным с базовым хранилищем данных, не требуя дополнительных преобразований. Использование массивов байтов гарантирует использование указанных методов кодирования и декодирования, скрывая различия в базовых устройствах. Для сценариев сетевой передачи дополнительное преобразование не требуется (передача данных по сети использует потоки байтов).
Основные причины создания неизменяемой строки следующие:
(1) Из соображений производительности. Несколько переменных могут ссылаться на один и тот же экземпляр строки в куче памяти, чтобы избежать накладных расходов на создание. Поскольку String используется так часто, разработчики библиотеки классов JAVA внесли небольшое изменение в реализацию, то есть использовали режим приспособленца . Всякий раз, когда генерируется строка с новым содержимым, они добавляются в общий пул. экземпляр строки с тем же содержимым генерируется снова во второй раз, этот объект используется совместно вместо создания нового объекта. Обратите внимание, что этот метод применяется только к объектам String, созданным оператором "=".
(2) Из соображений безопасности. Благодаря неизменяемости String можно гарантировать, что он не будет изменен после создания (конечно, это не абсолютно, значение объекта все равно можно изменить с помощью отражения).
(3) Предотвращение утечек памяти. Ключ HashMap имеет тип String. Если объект String является изменяемым, ключ невозможно удалить вручную, что приведет к утечке памяти.
(4) В целях безопасности параллелизма. Благодаря неизменяемости String несколько потоков могут безопасно совместно использовать объекты String, не беспокоясь об их изменении.
Создание строки
При создании экземпляра String его можно разделить на две категории в зависимости от того, используются ли для его создания операторы: (1) Прямое присвоение для создания строки; (2) Использование конструктора для создания строки.
(1) Прямое присваивание для создания строки.
Прямое присвоение для создания строки заключается в использовании операторов для прямого присвоения значений. К операторам, которые можно использовать, относятся знак равенства и знак плюс. Пример кода выглядит следующим образом:
String strWithEqualOperator = "foo";
String strWithAddOperator = strWithEqualOperator + "test";
При создании строки прямым присвоением существующая строка сначала будет получена из пула строковых констант. Если она не существует, вновь созданная строка будет добавлена в пул констант для облегчения следующего использования. Пул строковых констант — это особое применение шаблона «легковес», который будет представлен позже.
Обратите внимание, что здесь используется синтаксис оператора "+". На этапе компиляции Java переменные будут заменены реальными строками и объединены.
(2) Используйте конструктор для создания строки.
Помимо непосредственного присвоения значений для создания строки, вы также можете использовать конструктор для создания строки. Класс String поддерживает создание нескольких сценариев. Например, массивы байтов, массивы символов, экземпляры StringBuilder и т. д., которые здесь не будут перечислены.
Следует отметить, что при использовании метода конструктора для создания строкового объекта пул строковых констант не будет использоваться повторно. Если два строковых объекта создаются конструктором с использованием одного и того же строкового литерала и сравниваются с помощью операции знака равенства, поскольку это два разных объекта, хотя их значения одинаковы, они не равны. Примеры следующие:
String str1 = new String("foo");
String str2 = new String("foo");
// 打印false
System.out.println(str1 == str2);
Поэтому при сравнении строк старайтесь использовать метод равенства вместо оператора равенства.
Сравнение строк
Существует два варианта сравнения строк на равенство: с помощью оператора == и с помощью метода равенства. Для языка Java оператор == сравнивает их значения для «типов значений» и «нулевых типов», для «ссылочных типов» он сравнивает адрес хранения объекта в памяти , то есть указывает ли он на одно и то же объект. . Для метода равенства класса Object его функция аналогична оператору ==, но класс String переопределяет этот метод, чтобы он мог выполнять сравнение на равенство значений. Ключевой исходный код выглядит следующим образом:
public class Object {
//...
public boolean equals(Object obj) {
return (this == obj);
}
}
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
// ...
public boolean equals(Object anObject) {
if (this == anObject) {
return true;
}
if (anObject instanceof String) {
String aString = (String)anObject;
// 优先比较hashCode是否相等
if (coder() == aString.coder()) {
return isLatin1() ? StringLatin1.equals(value, aString.value)
: StringUTF16.equals(value, aString.value);
}
}
return false;
}
}
Поэтому при сравнении строк на равенство, чтобы уменьшить возможное влияние оптимизации базового хранилища строки, попробуйте использовать метод равенства. Более подробную информацию о различиях между методом равенства и оператором == можно найти в предыдущей статье автора .
Помимо сравнения на равенство, класс String также реализует интерфейс Comparable для поддержки пользовательских сравнений. Код ключа следующий:
public int compareTo(String anotherString) {
byte v1[] = value;
byte v2[] = anotherString.value;
if (coder() == anotherString.coder()) {
return isLatin1() ? StringLatin1.compareTo(v1, v2)
: StringUTF16.compareTo(v1, v2);
}
return isLatin1() ? StringLatin1.compareToUTF16(v1, v2)
: StringUTF16.compareToLatin1(v1, v2);
}
String、StringBuilder、StringBuffer、StringConcatFactory
Манипулирование строками — часто выполняемая операция при кодировании.
Объект String является неизменяемым объектом, поэтому каждый раз, когда вы меняете String, это фактически эквивалентно созданию нового объекта String и последующему указанию указателя на новый объект String. Поэтому лучше не использовать String для представления строк, содержимое которых часто меняется.
Чтобы упростить конкатенацию строк, Java переписывает оператор + для поддержки конкатенации строк. Нижний уровень сращивания String + реализуется StringBuilder. Весь процесс представляет собой добавление StringBuilder с последующим добавлением toString. (Java9 изменен на Invokedynamic, StringConcatFactory.makeConcatWithConstants)
StringBuffer является потокобезопасным , а метод добавления и другие методы модифицируются с помощью Synchronized, интерфейса, предоставляемого версией 1.0.
При использовании StringBuffer каждая строковая операция работает с самим объектом StringBuffer, а не создает новый объект и затем изменяет ссылку на объект. Если строковые объекты часто изменяются, рекомендуется использовать StringBuffer.
java.lang.StringBuilder, переменная последовательность символов, появилась в версии 5.0. Этот класс предоставляет API-интерфейс, совместимый со StringBuffer, но не гарантирует синхронизацию. Этот класс предназначен для использования в качестве замены StringBuffer, когда строковый буфер используется одним потоком (что является распространенной ситуацией). Если возможно, рекомендуется отдавать предпочтение этому классу, поскольку в большинстве реализаций он быстрее, чем StringBuffer.
В Java 9 для вызова метода StringConcatFactory.makeConcatWithConstants для оптимизации сращивания строк используется метод ignoreDynamic. По сравнению с Java 8, в котором оптимизация осуществляется путем преобразования в StringBuilder, Java 9 предоставляет на выбор множество STRATEGY . Эти STRATEGY имеют BC_SB (эквивалент метода оптимизации в Java 8). ), BC_SB_SIZED, BC_SB_SIZED_EXACT, MH_SB_SIZED, MH_SB_SIZED_EXACT, MH_INLINE_SIZED_EXACT, значение по умолчанию — MH_INLINE_SIZED_EXACT.
Рекомендации по использованию String, StringBuilder, StringBuffer и StringConcatFactory следующие:
(1) Для статического и простого объединения строк сцены используйте +
(2) Для сцен объединения циклов используйте StringBuilder. Если это Java 9 или выше, замените его. с помощью StringConcatFactory.
(3) Преобразование коллекций в String и другие операции элегантно реализованы с помощью потока и StringJoiner
(4) String +, Joiner и StringJoiner реализованы с помощью StringBuilder
(5) StringBuffer — это потокобезопасная версия StringBuilder
(6) String + сращивание в сценарии статической строки. Компилятор оптимизирует, и сгенерированный байт-код представляет собой объединенную строку.
Java-коллекции
Массив Java (массив)
Массивы в языке Java используются для хранения элементов фиксированного размера одного и того же типа. Java не предоставляет класс массива, поэтому вы можете напрямую использовать встроенный в язык метод объявления. Далее мы познакомим вас с использованием массивов в Java с нескольких аспектов, таких как объявление массива, создание, инициализация и обход.
Объявление массива
Вам необходимо объявить массив перед его использованием. Общие массивы включают одномерные массивы, двумерные массивы и трехмерные массивы (используются реже). Пример кода выглядит следующим образом:
// 声明一个一维数组
dataType[] arrayRefVar1;
// 声明一个二维数组
dataType[][] arrayRefVar2;
// 声明一个三维数组
dataType[][][] arrayRefVar3;
Следует отметить, что Java также поддерживает методы в форме «dataType arrayRefVar[]». Этот стиль заимствован из языка C/C++ и не рекомендуется .
Создание массива
Объявление массива не выделяет для массива пространство памяти, вам также необходимо создать массив. В языке Java для создания массива используется оператор new.Пример кода выглядит следующим образом:
// 创建一个一维数组
arrayRefVar1 = new dataType[arraySize];
// 创建一个二维数组
arrayRefVar2 = new dataType[firstLevelSize][secondLevelSize];
// 创建一个三维数组
arrayRefVar3 = new dataType[firstLevelSize][secondLevelSize][thirdLevelSize];
Конечно, вы также можете создать массив при его объявлении. Пример кода выглядит следующим образом:
// 声明并创建一个一维数组
dataType[] arrayRefVar1 = new dataType[arraySize];
// 声明并创建一个二维数组
dataType[][] arrayRefVar2 = new dataType[firstLevelSize][secondLevelSize];
// 声明并创建一个三维数组
dataType[][][] arrayRefVar3 = new dataType[firstLevelSize][secondLevelSize][thirdLevelSize];
Кроме того, язык Java поддерживает присвоение инициализированных данных во время объявления. Пример кода выглядит следующим образом:
// 声明并初始化一维数组
dataType[] arrayRefVar1 = {
value0, value1, ..., valuek};
// 声明并初始化二维数组
dataType[][] arrayRefVar2 = {
{
value00, value01,...,value0n,},
{
value10, value11,...,value1n},
...,
{
valuem0, valuem1,...,valuemn}
};
// 三维数组就是在二维数组的基础上,进一步赋值初始化数据,这里不再展示(使用较少)
Обход массива
Тип элемента массива и размер массива определяются, поэтому при обходе массива обычно можно использовать базовый цикл или цикл For-Each. Примеры следующие:
int[] arrayRefVar1 = {
1, 2, 3};
int[][] arrayRefVar2 = {
{
1, 2, 3},
{
4, 5, 6}
};
int[][][] arrayRefVar3 = {
{
{
1,2,3}, {
4,5,6}, {
7,8,9}},
{
{
10,11,12}, {
13,14,15}, {
16,17,18}},
{
{
19,20,21}, {
21,22,23},{
24,25,26}}
};
for (int i = 0; i < arrayRefVar1.length; i++) {
System.out.print(arrayRefVar1[i]);
}
System.out.println();
// JDK 1.5 引进的循环类型,被称为 For-Each 循环或者加强型循环,它能在不使用下标的情况下遍历数组
for (int element : arrayRefVar1) {
System.out.print(element);
}
System.out.println();
for (int i = 0; i < arrayRefVar2.length; i++) {
for (int j = 0; j < arrayRefVar2[i].length; j++) {
System.out.print(arrayRefVar2[i][j] + " ");
}
System.out.println();
}
System.out.println();
for (int i = 0; i < arrayRefVar3.length; i++) {
for (int j = 0; j < arrayRefVar3[i].length; j++) {
for (int k = 0; k < arrayRefVar3[i][j].length; k++) {
System.out.print(arrayRefVar3[i][j][k] + " ");
}
System.out.println();
}
System.out.println();
}
Следует отметить, что для многомерных массивов (больше или равных двум измерениям), таких как двумерные массивы, он не обязательно является регулярным. Так что же такое нерегулярный массив? Если взять в качестве примера двумерный массив, то если количество столбцов в каждой строке массива одинаково, он является регулярным; если количество столбцов в каждой строке не совсем одинаково, он нерегулярен. Примеры следующие:
// 规则的二维数组
int[][] arrayRefVar1 = {
{
1, 2, 3},
{
4, 5, 6}
};
// 不规则的二维数组
int[][] arrayRefVar2 = {
{
1, 2, 3},
{
4, 5}
};
В случае нерегулярных массивов обратите внимание на проблемы выхода за пределы массива, которые могут возникнуть при их использовании (приведенный выше пример кода для обхода массива совместим с нерегулярными сценариями).
Список
Список — одна из часто используемых коллекций. Иерархия классов List следующая:
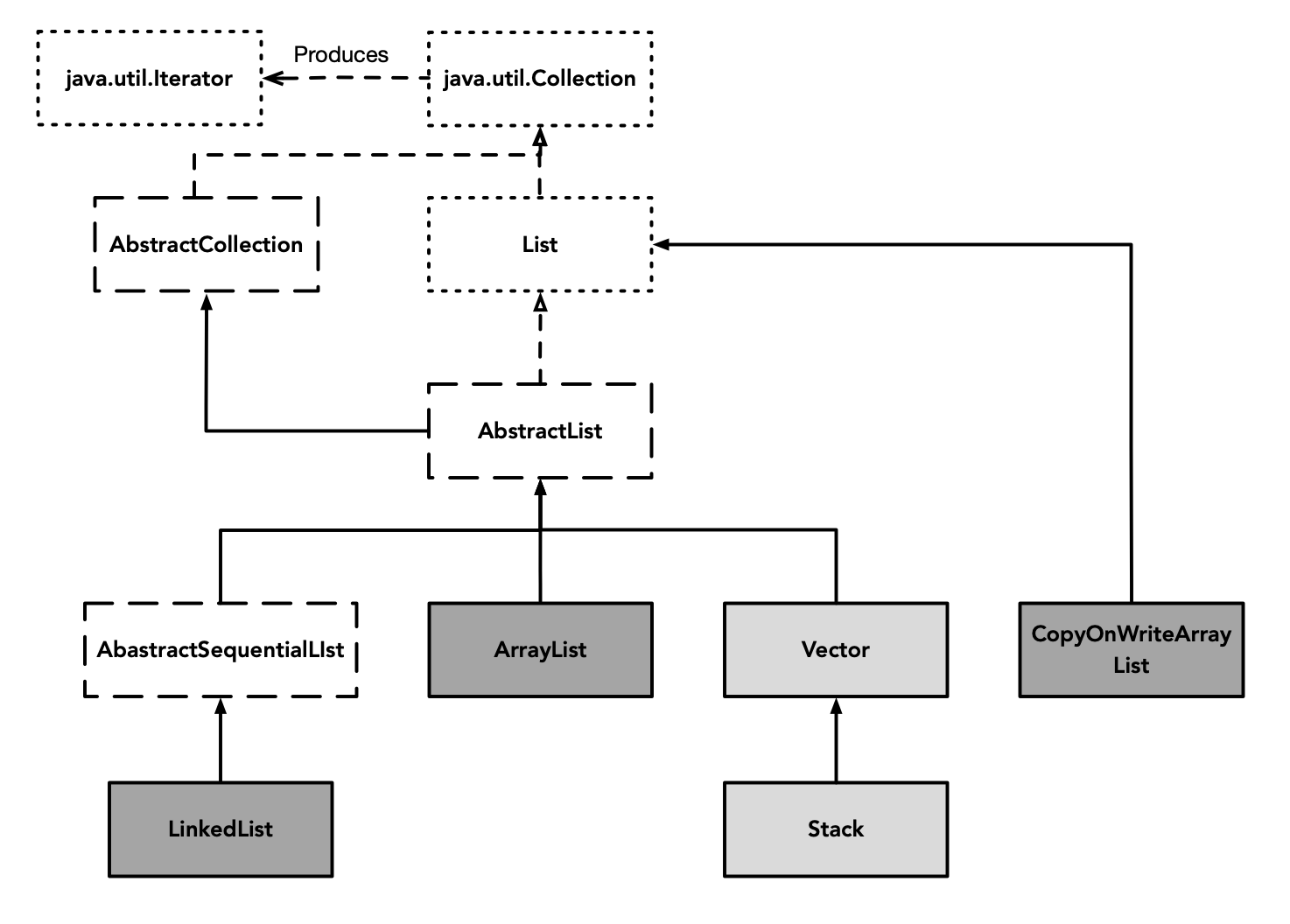
Среди них Vector и Stack устарели и имеют лишь историческое значение, нужно только понять их принцип реализации. В сценариях, не поддерживающих потокобезопасность, можно выбрать ArrayList и LinkedList. Для сценариев с потокобезопасностью можно выбрать CopyOnWriteArrayList.
Вектор
Vector — это класс контейнера синхронизации, предоставляемый JDK 1.0 и реализующий интерфейс Collection в JDK 1.2. С постоянным обновлением версий JDK этот класс постепенно устарел.
1 Вектор реализован на основе динамического массива
Вектор реализован на основе динамического массива Его структура следующая:
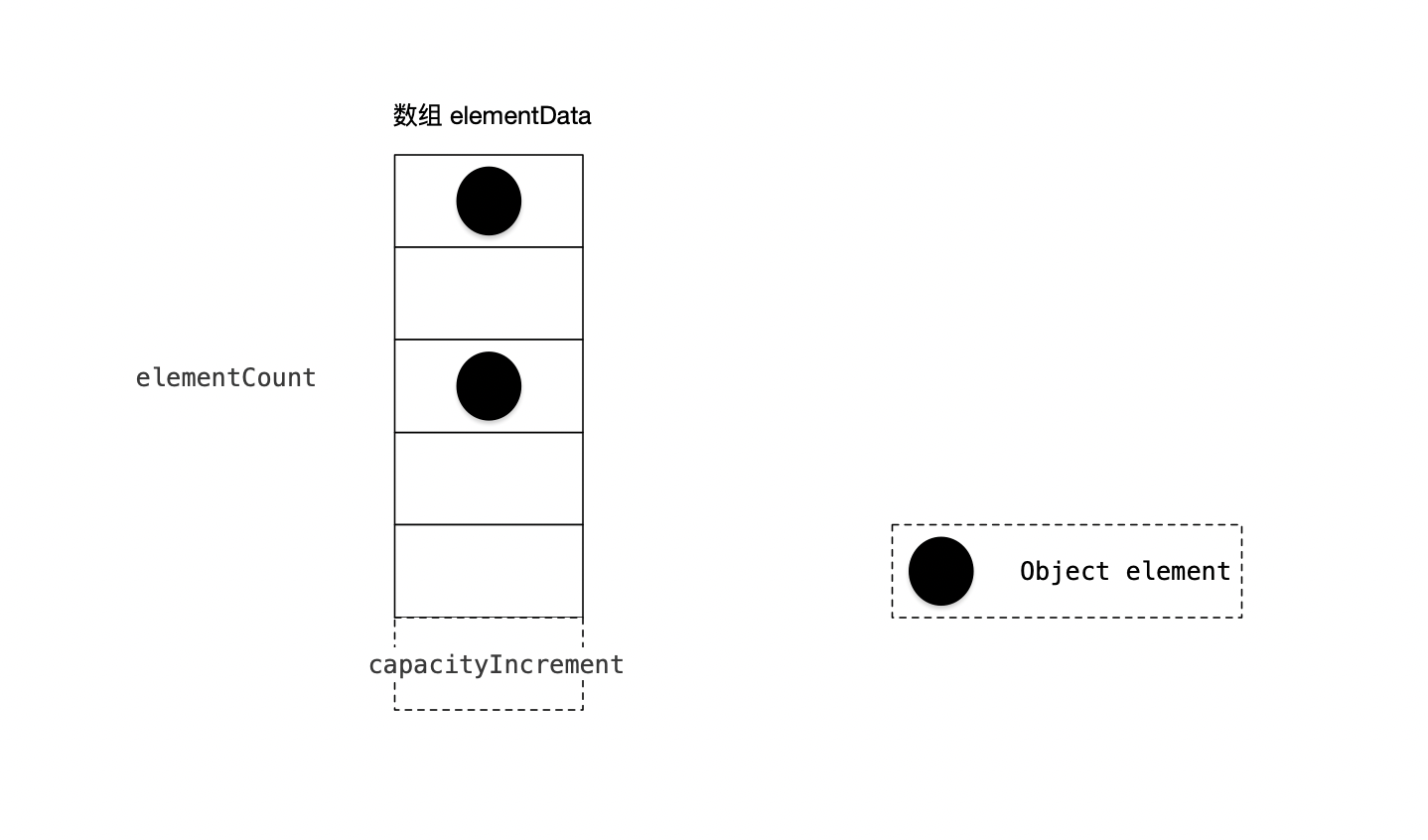
(1) Массив Object[] elementData хранит элементы, добавленные в вектор. elementData — это динамический массив с размером по умолчанию 10. По мере увеличения элементов вектора емкость вектора также будет динамически увеличиваться в соответствии с емкостьюIncrement. Поскольку во время расширения необходимо обеспечить непрерывное пространство памяти, исходные данные будут скопированы во вновь использованное пространство памяти.
(2) elementCount — это фактический размер массива.
(3) емкостьIncrement — коэффициент роста динамического массива. При создании вектора вы можете указать размер емкостиIncrement. Если значение емкостиIncrement меньше или равно 0 или не установлено, вектор удваивается (по умолчанию).
(4) Функция клонирования Vector клонирует все элементы в массив.
private void grow(int minCapacity) {
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + ((capacityIncrement > 0) ?
capacityIncrement : oldCapacity);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
elementData = Arrays.copyOf(elementData, newCapacity); // 将全部元素克隆到新数组
}
2 Vector является потокобезопасным.
Vector — класс синхронизированного контейнера. Запечатывая состояние и синхронизируя каждый общедоступный метод, только один поток может одновременно получить доступ к состоянию контейнера (модифицируется с помощью ключевого слова Synchronized).
Пример кода выглядит следующим образом:
public class Vector<E>
extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{
protected Object[] elementData;
protected int elementCount;
protected int capacityIncrement;
// 公有方法均使用 synchronized 修饰
public synchronized int capacity() {
return elementData.length;
}
public synchronized int size() {
return elementCount;
}
// 其他公共方法
...
}
3. Некоторые составные операции в Vector имеют проблемы, не связанные с безопасностью потоков.
Как класс синхронизированного контейнера, Vector не может гарантировать «абсолютную потокобезопасность» (синхронные классы контейнеров требуют дополнительных клиентских блокировок для защиты при выполнении составных операций в определенных сценариях), а также параллельные операции. не поддерживаются.
Общие составные операции с контейнерами включают итерацию (многократный доступ к элементам и активный обход всех элементов в контейнере), переход (поиск следующего элемента текущего элемента в указанном порядке), условные операции и т. д. В синхронном классе контейнера может возникнуть неожиданное поведение, если контейнер одновременно изменяется несколькими потоками. Пример следующий: Vector инкапсулирует два метода: getLast и deleteLast, оба из которых сначала
выполняют операции проверки, а затем выполняют операции. Полный код выглядит следующим образом:
public static Object getLast(Vector vec){
int lastIndex=vec.size()-1;
return vec.get(lastIndex);
}
public static Object deleteLast(Vector vec){
int lastIndex=vec.size()-1;
return vec.remove(lastIndex);
}
С точки зрения вызова метода, если поток A вызывает getLast для 10 элементов, поток B вызывает deleteLast. Когда поток B выполняется после того, как поток A читает LastIndex, когда поток A выполняет getLast, будет выдано исключение ArrayIndexOutOfBoundsException (массив выходит за пределы).
Следовательно, класс контейнера синхронизации должен следовать стратегии синхронизации, то есть блокировки клиента . Пример кода выглядит следующим образом:
public static Object getLast(Vector vec){
synchronized(vec){
int lastIndex=vec.size()-1;
return vec.get(lastIndex);
}
}
public static Object deleteLast(Vector vec){
synchronized(vec){
int lastIndex=vec.size()-1;
return vec.remove(lastIndex);
}
}
Куча
Стек наследует вектор и инкапсулирует только некоторые интерфейсы стека. Ключевой исходный код выглядит следующим образом:
public class Stack<E> extends Vector<E> {
public E push(E item) {
addElement(item);
return item;
}
public synchronized E pop() {
E obj;
int len = size();
obj = peek();
removeElementAt(len - 1);
return obj;
}
public synchronized E peek() {
int len = size();
if (len == 0)
throw new EmptyStackException();
return elementAt(len - 1);
}
}
ArrayList
ArrayList — динамический массив. По сравнению со встроенными массивами в Java его емкость может динамически расти .
ArrayList наследует AbstractList и реализует List. Это очередь массива, которая предоставляет связанные функции, такие как добавление, удаление, изменение и перемещение.
ArrayList реализует интерфейс RandmoAccess, который обеспечивает функцию произвольного доступа. RandmoAccess используется в Java для реализации List для обеспечения быстрого доступа к List. В ArrayList мы можем быстро получить объект элемента по серийному номеру элемента; это быстрый произвольный доступ.
1 ArrayList реализует функцию динамического массива на основе динамического массива.
ArrayList реализует функцию динамического массива . ArrayList реализует динамические массивы на основе массивов. Соответствующие определения следующие:
transient Object[] elementData; // non-private to simplify nested class access
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
// 动态增长为原来的一半
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
По сравнению с удвоением роста Map, длина динамического роста ArrayList составляет половину его предыдущей длины .
Длина ArrayList по умолчанию равна 10.
/**
* Default initial capacity.
*/
private static final int DEFAULT_CAPACITY = 10;
Поскольку это динамический массив, ArrayList теоретически не будет иметь массив за пределами.
2 ArrayList не является потокобезопасным.
ArrayList не является потокобезопасным, то есть несколько потоков могут одновременно писать в ArrayList в любое время, что может привести к несогласованности данных.
Связанный список
LinkedList реализует интерфейс Queue . LinkedList предоставляет интерфейс работы со стеком .
1 LinkedList реализован на основе двусвязного списка
(1) LinkedList использует Node для хранения информации об узлах.
Node определяется следующим образом:
private static class Node<E> {
E item;
// 下一个节点
Node<E> next;
// 上一个节点
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
(2) LinkedList может быстро получить доступ к головному и хвостовому узлу.
LinkedList основан на связанном списке и не может обеспечить быстрый поиск на основе индексов. Однако LinkedList записывает информацию о головном и хвостовом узлах и может быстро найти головной и хвостовой узлы.
/**
* Pointer to first node.
* Invariant: (first == null && last == null) ||
* (first.prev == null && first.item != null)
*/
transient Node<E> first;
/**
* Pointer to last node.
* Invariant: (first == null && last == null) ||
* (last.next == null && last.item != null)
*/
transient Node<E> last;
(3) LinkedList реализует интерфейс двусторонней очереди.
LinkedList реализует интерфейс двусторонней очереди (Deque) и поддерживает его использование в качестве двусторонней очереди.
(4) LinkedList можно использовать в качестве очереди.
Java не реализует напрямую класс сущности Queue, но реализует интерфейс Queue в LinkedList.
(5) LinkedList можно использовать в качестве стека.
По сравнению со Stack, реализованным на основе Vector, хотя LinkedList не поддерживает синхронизацию потоков, его производительность доступа намного выше в немногопоточных сценариях. Таким образом, в немногопоточных сценариях LinkedList является лучшим выбором для стеков.
** 2 LinkedList не является потокобезопасным**
LinkedList не является потокобезопасным, то есть несколько потоков могут одновременно записывать HashMap в любое время, что может привести к несогласованности данных.
КопироватьонзаписьArrayList
CopyOnWriteArrayList — это потокобезопасная версия ArrayList. CopyOnWriteArrayList копирует копию данных при выполнении операции записи, а затем после записи устанавливает в нее новые данные. CopyOnWriteArrayList подходит для одновременного чтения и нескольких сценариев записи .
1. Используйте технологию COW + реентерабельную блокировку для обеспечения потокобезопасности.
CopyOnWriteArrayList использует ReentrantLock для поддержки параллельных операций, а массив — это объект массива, который фактически хранит данные. ReentrantLock — это эксклюзивная блокировка, поддерживающая повторный вход. Только одному потоку разрешено получить блокировку в любой момент времени, поэтому он может безопасно записывать массивы одновременно. Соответствующие переменные-члены следующие:
// 重入锁保证写操作互斥
final transient ReentrantLock lock = new ReentrantLock();
// volatile保证读可见性
private transient volatile Object[] array;
При добавлении элементов в CopyOnWriteArrayList можно обнаружить, что нужно блокировать их при добавлении, иначе при многопоточной записи будет скопировано N копий.
public boolean add(E e) {
final ReentrantLock lock = this.lock;
// 加锁,保证只有一个线程进入
lock.lock();
try {
// 获得当前数组对象
Object[] elements = getArray();
int len = elements.length;
// 拷贝到一个新的数组中
Object[] newElements = Arrays.copyOf(elements, len + 1);
// 追加新元素
newElements[len] = e;
// 使用新数组对象更新当前数组的引用
setArray(newElements);
return true;
} finally {
// 解锁
lock.unlock();
}
}
Нет необходимости блокировать во время операции чтения.Если несколько потоков добавляют данные в ArrayList при чтении, чтение все равно будет читать старые данные ( может произойти грязное чтение ), поскольку старый ArrayList не будет заблокирован при записи.
public E get(int index) {
return get(getArray(), index);
}
2 CopyOnWriteArrayList является потокобезопасным.
карта
Карта — одна из часто используемых коллекций. Иерархия классов Map следующая:
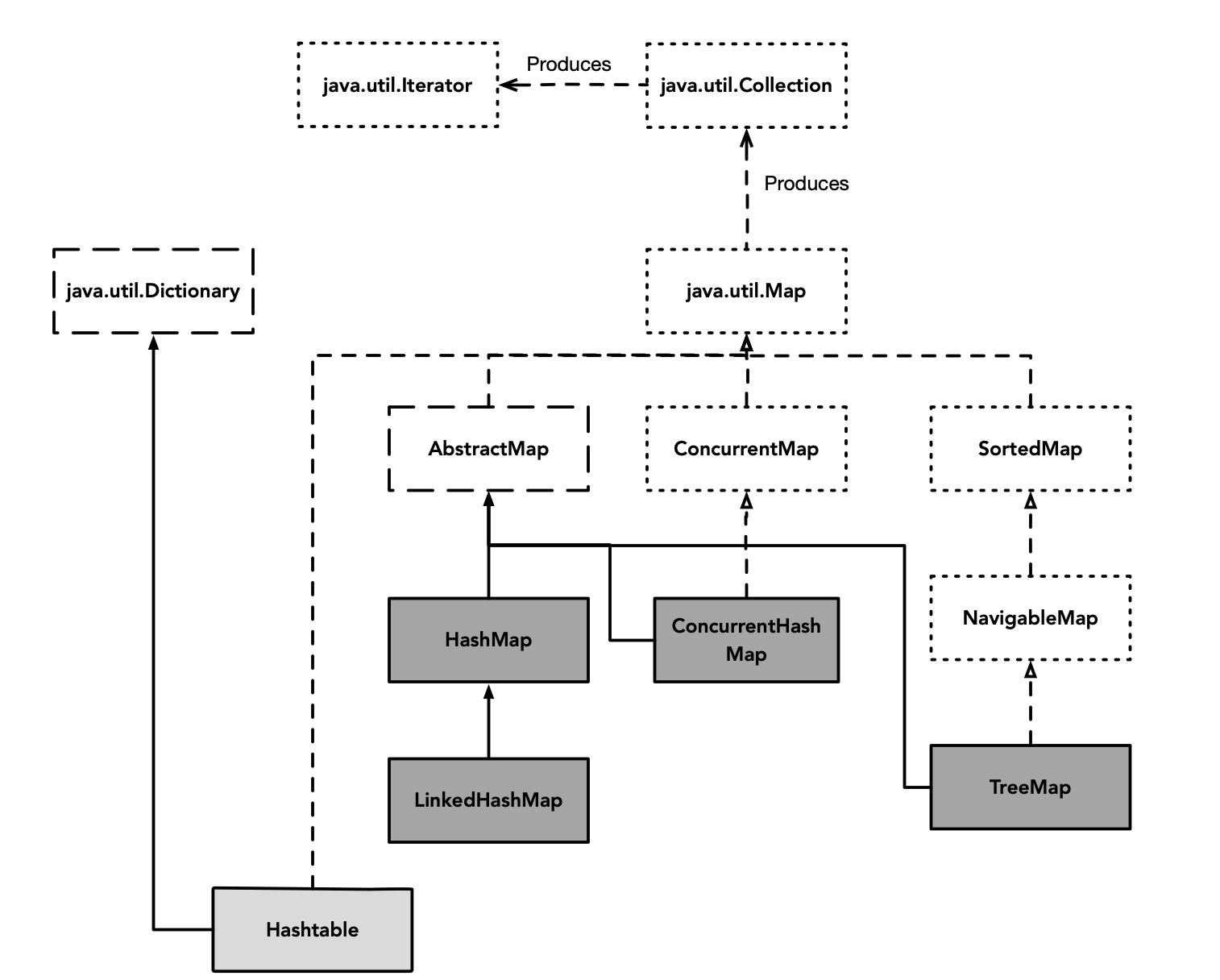
Среди них Hashtable устарел и имеет лишь историческое значение.Вам нужно только понять принцип его реализации. В сценариях, не поддерживающих потокобезопасность, вы можете выбрать HashMap, а в сценариях с потокобезопасностью — ConcurrentHashMap. Если вам необходимо обеспечить упорядоченную вставку или упорядоченный доступ, вы можете выбрать LinkedHashMap. Если вам нужно обеспечить порядок ключей, вы можете выбрать TreeMap.
Хеш-таблица
Хотя Hashtable устарела, как самая ранняя (JDK 1.1) структура данных карты, анализ ее структуры и реализации по-прежнему имеет справочную ценность. Hashtable наследует от Dictionary и реализует интерфейсы Map (начиная с JDK 1.2), Cloneable и java.io.Serializable.
1 Hashtable реализован на основе массива + связанного списка (JDK1.2 реализует интерфейс Map)
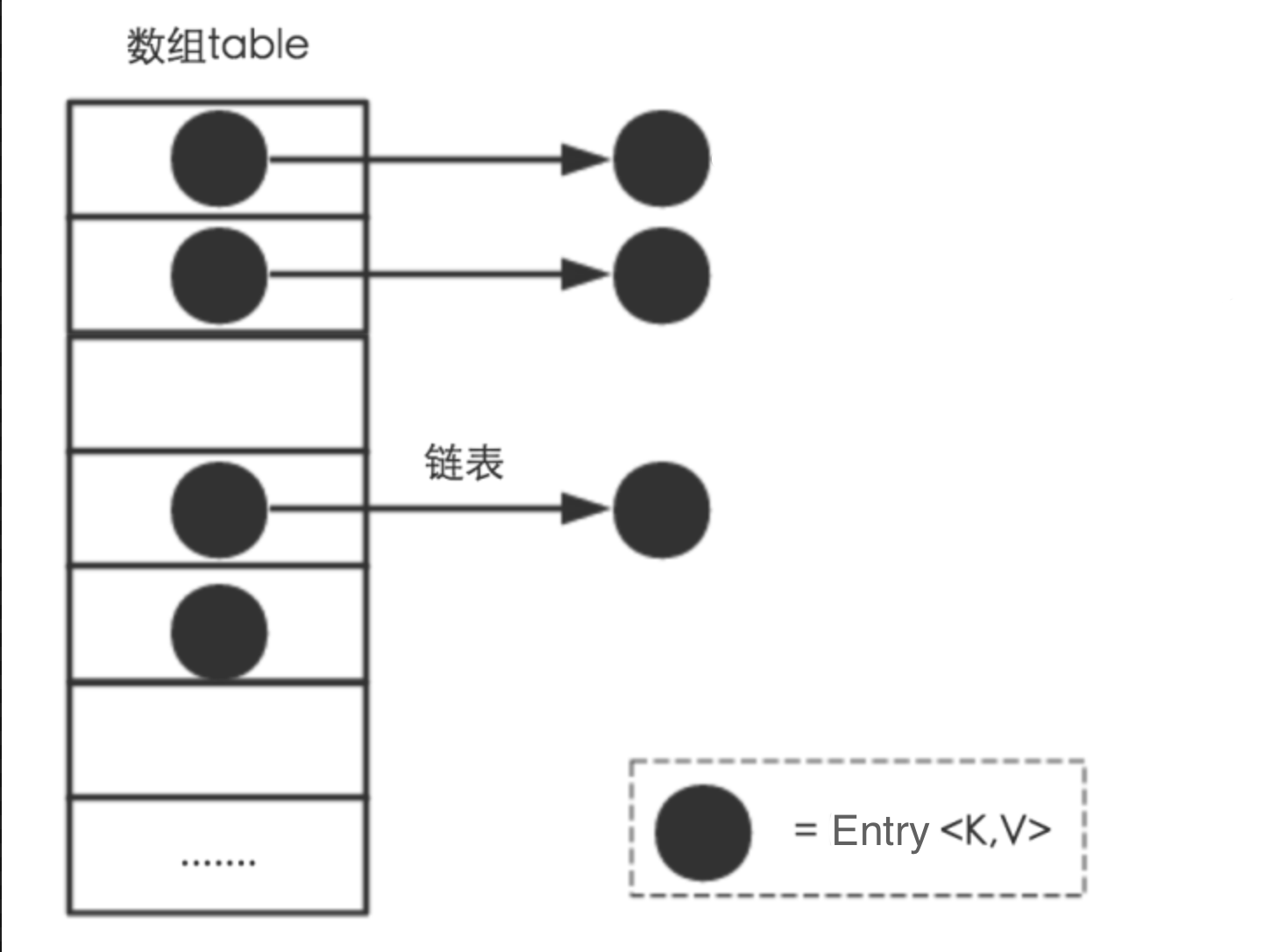
(1) Hashtable использует таблицу Entry[] (массив хеш-корзины) для хранения пар ключ-значение.
Структура объекта Entry выглядит следующим образом:
/**
* Hashtable bucket collision list entry
*/
private static class Entry<K,V> implements Map.Entry<K,V> {
// 用来定位数组索引位置
final int hash;
final K key;
V value;
// 链表的下一个entry, 使用链表处理哈希冲突
Entry<K,V> next;
protected Entry(int hash, K key, V value, Entry<K,V> next) {
... }
// Map.Entry Ops
public K getKey() {
... }
public V getValue() {
... }
public V setValue(V value) {
... }
public boolean equals(Object o) {
... }
public int hashCode() {
... }
public String toString() {
... }
}
(2) Hashtable использует связанные списки для разрешения конфликтов.
Hashtables не может избежать конфликтов. Для разрешения конфликтов Hashtable использует метод цепочки адресов для решения проблемы (другие методы обработки конфликтов включают в себя: открытую адресацию, повторное хеширование, создание общедоступной области переполнения и т. д.). Метод цепного адреса заключается в добавлении структуры связанного списка к каждому элементу массива.После хеширования данных и получения индекса массива данные помещаются в связанный список, соответствующий элементу индекса.
(3) Hashtable поддерживает автоматическое расширение (повторное хэширование).Длина
инициализации (длина) таблицы Entry[] по умолчанию в Hashtable равна 11, значение по умолчанию коэффициента загрузки (коэффициент загрузки) составляет 0,75, а максимальная емкость ( порог) — это то, что может Hashtable. Количество записей (пар ключ-значение), которые могут вместить максимальный объем данных, порог = длина * коэффициент загрузки.
Когда данные, хранящиеся в HashMap, превышают пороговое значение, необходимо выполнить повторное хеширование для достижения расширения.Расширенная емкость HashMap в два раза превышает предыдущую емкость . Затем хэшируйте исходный код следующим образом:
protected void rehash() {
int oldCapacity = table.length;
Entry<?,?>[] oldMap = table;
// overflow-conscious code
int newCapacity = (oldCapacity << 1) + 1;
if (newCapacity - MAX_ARRAY_SIZE > 0) {
if (oldCapacity == MAX_ARRAY_SIZE)
// Keep running with MAX_ARRAY_SIZE buckets
return;
newCapacity = MAX_ARRAY_SIZE;
}
Entry<?,?>[] newMap = new Entry<?,?>[newCapacity];
modCount++;
threshold = (int)Math.min(newCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
// 使用newMap
table = newMap;
// 迁移oldMap中数据到newMap
for (int i = oldCapacity ; i-- > 0 ;) {
for (Entry<K,V> old = (Entry<K,V>)oldMap[i] ; old != null ; ) {
Entry<K,V> e = old;
old = old.next;
int index = (e.hash & 0x7FFFFFFF) % newCapacity;
e.next = (Entry<K,V>)newMap[index];
newMap[index] = e;
}
}
}
Обратите внимание, что коэффициент загрузки по умолчанию, равный 0,75, представляет собой сбалансированный выбор между эффективностью использования пространства и времени . Рекомендуется не изменять его, за исключением особых обстоятельств времени и пространства. Если имеется большой объем памяти и высокие требования к эффективности использования времени. , нагрузку можно уменьшить.Значение коэффициента Load Factor; наоборот, если объем памяти ограничен и временная эффективность невысока, можно увеличить значение коэффициента загрузки loadFactor, которое может быть больше 1. .
Кроме того, HashMap использует размер для представления фактического количества пар ключ-значение.
2 Hashtable является потокобезопасным
Hashtable является потокобезопасным, то есть, когда несколько потоков могут одновременно записывать данные в Hashtable в любое время, проблем с несогласованностью данных не возникнет. Поскольку Hashtable использует взаимоисключающую стратегию синхронизации для реализации потокобезопасности, возникают проблемы с производительностью , поэтому в сценариях многопоточного доступа вместо этого используется ConcurrentHashMap .
Хэшмап
JDK1.8 оптимизирует базовую реализацию HashMap, например, путем введения красно-черной древовидной структуры данных, оптимизации реализации расширения и т. д. В этой статье объединены различия между JDK1.7 и JDK1.8 для более глубокого изучения структурной реализации и функциональных принципов HashMap.
1 HashMap реализован на основе массива + связанного списка + красно-черного дерева (JDK1.8 добавляет красно-черную часть дерева)
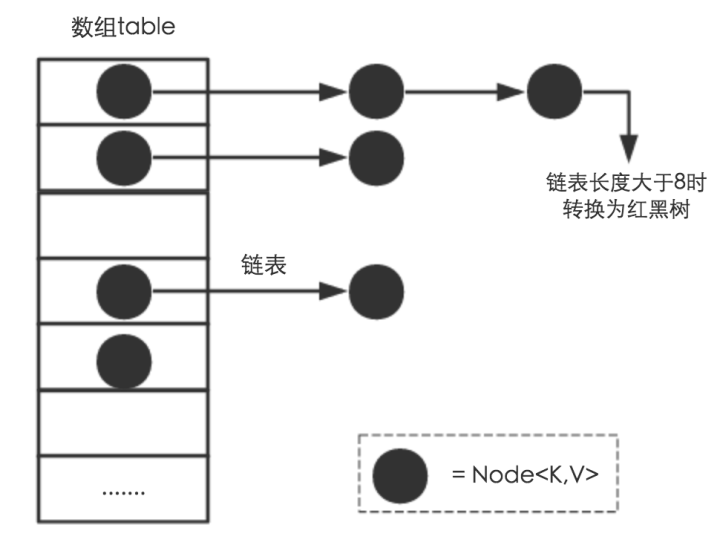
(1) HashMap использует таблицу Node[] (массив хеш-корзины) для хранения пар ключ-значение.
Структура сущности узла: следующее:
static class Node<K,V> implements Map.Entry<K,V> {
final int hash; //用来定位数组索引位置
final K key;
V value;
Node<K,V> next; //链表的下一个node, 使用链表处理哈希冲突
Node(int hash, K key, V value, Node<K,V> next) {
... }
public final K getKey(){
... }
public final V getValue() {
... }
public final String toString() {
... }
public final int hashCode() {
... }
public final V setValue(V newValue) {
... }
public final boolean equals(Object o) {
... }
}
(2) HashMap использует связанные списки для разрешения конфликтов.Хеш
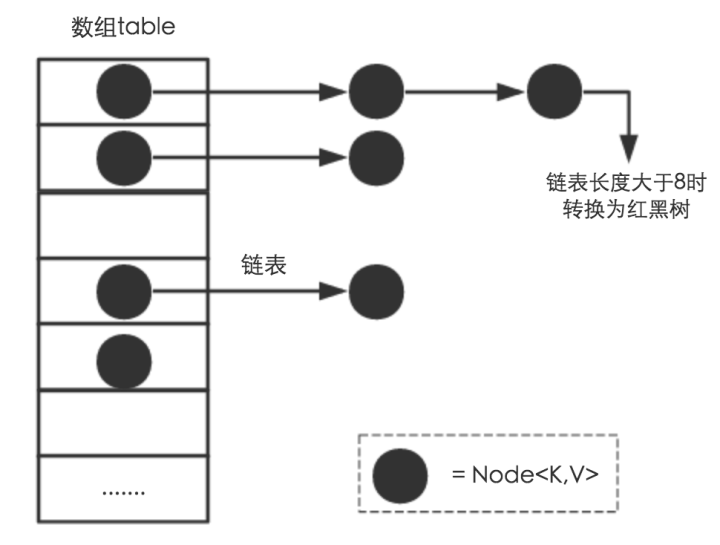
-таблицы не могут избежать конфликтов. Для разрешения конфликтов HashMap использует метод цепочки адресов для решения проблемы (другие методы обработки конфликтов включают в себя: метод открытой адресации, метод повторного хэширования, создание общедоступной области переполнения и т. д.). Метод цепного адреса заключается в добавлении структуры связанного списка к каждому элементу массива.Когда данные хешируются, получается индекс массива, и данные помещаются в связанный список, соответствующий элементу индекса.
(3) HashMap использует красно-черные деревья для решения проблемы слишком длинных связанных списков.
Даже если коэффициент загрузки (коэффициент загрузки) и алгоритм хеширования разработаны разумно, невозможно избежать проблемы слишком длинных связанных списков, которые могут обрабатывать конфликты. Когда связанный список слишком длинный, производительность Hash снизится (с O(1) до O(n)). Чтобы уменьшить проблемы с производительностью, вызванные связанными списками в этом сценарии, JDK1.8 вводит красно-черные деревья.
Когда длина связанного списка слишком велика ( TREEIFY_THRESHOLD = 8 ), связанный список преобразуется в красно-черное дерево.
Красно-черное дерево представляет собой специально упорядоченное двоичное дерево. Его временная сложность для вставки, удаления и поиска равна O (логарифм N). Поскольку оно поддерживает самобалансировку, его производительность лучше, чем у упорядоченного двоичного дерева в худшем случае. . Дополнительные принципы работы красно-черной древовидной структуры данных можно найти по ссылке .
Обратите внимание, что размер красно-черного дерева слишком мал ( UNTREEIFY_THRESHOLD = 6 ), и красно-черное дерево будет преобразовано в связанный список.
(4) HashMap поддерживает автоматическое расширение.Длина
инициализации (длина) по умолчанию таблицы Node[] в HashMap равна 16, значение по умолчанию коэффициента загрузки (коэффициент загрузки) составляет 0,75, а максимальная емкость (порог) является максимальной объем данных, который может разместить HashMap.Количество узлов (пары ключ-значение), пороговое значение = длина * коэффициент загрузки.
Когда данные, хранящиеся в HashMap, превышают пороговое значение, их необходимо изменить (расширить).Расширенная емкость HashMap в два раза превышает предыдущую емкость . В HashMap длина таблицы должна быть равна 2 в n-й степени (должно быть составным числом). Это нетрадиционный дизайн. Традиционный дизайн заключается в том, чтобы размер корзины был простым числом. Условно говоря, вероятность конфликта, вызванного простыми числами, меньше, чем у составных чисел. Конкретное доказательство можно найти по ссылке . Начальный размер сегмента Hashtable равен 11, что представляет собой приложение, в котором размер сегмента рассчитан на простое число (нет никакой гарантии, что Hashtable по-прежнему будет простым числом после расширения). HashMap> использует эту нетрадиционную конструкцию, в основном для оптимизации модуля и расширения. В то же время, чтобы уменьшить конфликты, HashMap также добавляет старшие биты для участия в операции при позиционировании позиции индекса хеш-корзины .
Обратите внимание, что коэффициент загрузки по умолчанию, равный 0,75, представляет собой сбалансированный выбор между эффективностью использования пространства и времени. Рекомендуется не изменять его, за исключением особых обстоятельств времени и пространства. Если имеется большой объем памяти и высокие требования к эффективности использования времени. , нагрузку можно уменьшить.Значение коэффициента Load Factor; наоборот, если объем памяти ограничен и временная эффективность невысока, можно увеличить значение коэффициента загрузки loadFactor, которое может быть больше 1. .
Кроме того, HashMap использует размер для представления фактического количества пар ключ-значение.
2. HashMap не является потокобезопасным.
HashMap не является потокобезопасным. То есть несколько потоков могут одновременно писать HashMap в любое время, что может привести к несогласованности данных. Если вам необходимо обеспечить потокобезопасность, вы можете обернуть HashMap методом SynchronizedMap Collections, чтобы сделать его потокобезопасным, или использовать ConcurrentHashMap .
ConcurrentHashMap
Заменив синхронные контейнеры параллельными контейнерами, можно значительно улучшить масштабируемость (по мере увеличения количества параллелизма среднее время ответа постепенно стабилизируется) и снизить риски.
ConcurrentHashMap наследует от AbstractMap (согласно HashMap) и реализует интерфейс ConcurrentMap.
1 ConcurrentHashMap реализован на основе массива + связанного списка + красно-черного дерева (JDK1.8 добавляет красно-черную часть дерева).
ConcurrentHashMap был представлен в JDK 1.5 и оптимизирован в JDK 1.8. В обеих версиях структура данных, используемая ConcurrentHashMap, такая же, как и у HashMap. Отличается только реализация параллельной обработки .
Далее мы сосредоточимся на реализации ConcurrentHashMap в JDK 1.5 и JDK 1.8.
(1) Совместное использование данных на основе механизма блокировки сегментов.
JDK 1.5 использует технологию блокировки сегментов (Lock Striping) для реализации более детального механизма блокировки для достижения большего совместного использования.
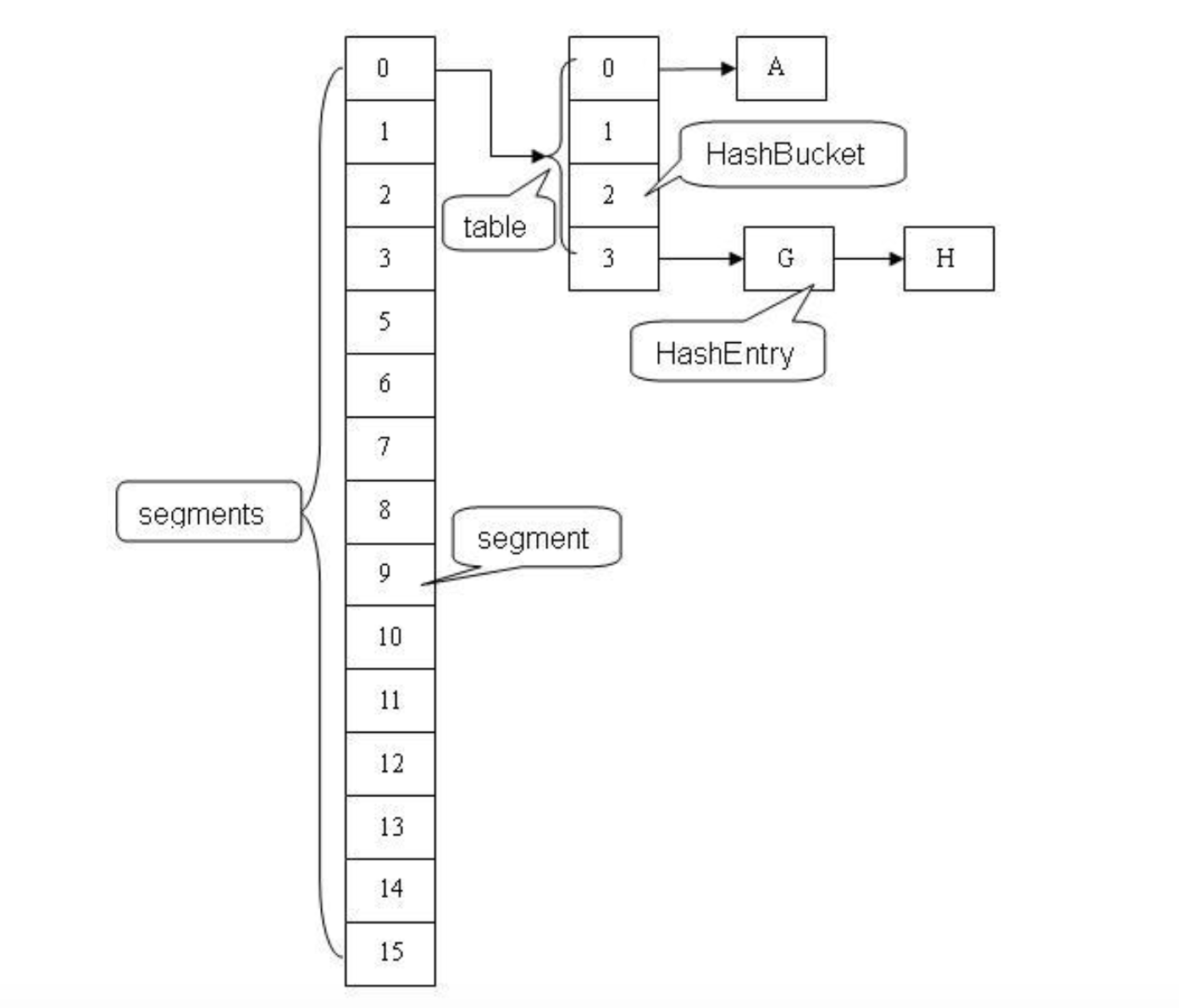
ConcurrentHashMap хранит данные в сегментах и назначает блокировку (сегмент) каждому сегменту. Когда поток занимает блокировку (сегмент) для доступа к одному сегменту данных, данные в других сегментах все еще могут быть доступны другим потокам. По умолчанию выделить 16 сегментов .
Здесь Segment наследуется от класса ReentrantLock. Итак, суть блокировки сегмента заключается в том, что объект Segment действует как блокировка .
Сегмент определяется следующим образом:
static final class Segment<K,V> extends ReentrantLock implements Serializable {
/**
* 在本 segment 范围内,包含的 HashEntry 元素的个数
* 该变量被声明为 volatile 型
*/
transient volatile int count;
/**
* table 被更新的次数
*/
transient int modCount;
/**
* 当 table 中包含的 HashEntry 元素的个数超过本变量值时,触发 table 的再散列
*/
transient int threshold;
/**
* table 是由 HashEntry 对象组成的数组
* 如果散列时发生碰撞,碰撞的 HashEntry 对象就以链表的形式链接成一个链表
* table 数组的数组成员代表散列映射表的一个桶
* 每个 table 守护整个 ConcurrentHashMap 包含桶总数的一部分
* 如果并发级别为 16,table 则守护 ConcurrentHashMap 包含的桶总数的 1/16
*/
transient volatile HashEntry<K,V>[] table;
/**
* 装载因子
*/
final float loadFactor;
Segment(int initialCapacity, float lf) {
loadFactor = lf;
setTable(HashEntry.<K,V>newArray(initialCapacity));
}
/**
* 设置 table 引用到这个新生成的 HashEntry 数组
* 只能在持有锁或构造函数中调用本方法
*/
void setTable(HashEntry<K,V>[] newTable) {
// 计算临界阀值为新数组的长度与装载因子的乘积
threshold = (int)(newTable.length * loadFactor);
table = newTable;
}
/**
* 根据 key 的散列值,找到 table 中对应的那个桶(table 数组的某个数组成员)
*/
HashEntry<K,V> getFirst(int hash) {
HashEntry<K,V>[] tab = table;
// 把散列值与 table 数组长度减 1 的值相“与”,
// 得到散列值对应的 table 数组的下标
// 然后返回 table 数组中此下标对应的 HashEntry 元素
return tab[hash & (tab.length - 1)];
}
}
(2) Совместное использование данных на основе механизма CAS.
JDK 1.8 использует технологию CAS + синхронизированное ключевое слово для достижения большего совместного использования.
public V put(K key, V value) {
return putVal(key, value, false);
}
/** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent) {
// ConcurrentHashMap 不允许插入null键,HashMap允许插入一个null键
if (key == null || value == null) throw new NullPointerException();
// 计算key的hash值
int hash = spread(key.hashCode());
int binCount = 0;
// for循环的作用:因为更新元素是使用CAS机制更新,需要不断的失败重试,直到成功为止。
for (Node<K,V>[] tab = table;;) {
// f:链表或红黑二叉树头结点,向链表中添加元素时,需要synchronized获取f的锁。
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
// 通过hash定位Node[]数组的索引坐标,
// 是否有Node节点,如果没有则使用CAS进行添加(链表的头结点),添加失败则进入下次循环。
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
// 检查到内部正在移动元素(Node[] 数组正在扩容)
else if ((fh = f.hash) == MOVED)
// 帮助扩容
tab = helpTransfer(tab, f);
else {
V oldVal = null;
// 使用synchronized加锁链表或红黑树头结点
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
// 如果链表长度已经达到临界值(默认是8),就把链表转换为树结构
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}
2 ConcurrentHashMap является потокобезопасным
ConcurrentHashMap является потокобезопасным и может быть заменен ConcurrentHashMap в сценариях многопоточного доступа .
LinkedHashMap
HashMap неупорядочен. В некоторых сценариях вам необходимо использовать упорядоченный HashMap ( порядок вставки или порядок доступа ). LinkedHashMap реализует упорядоченный HashMap. LinkedHashMap наследует HashMap.
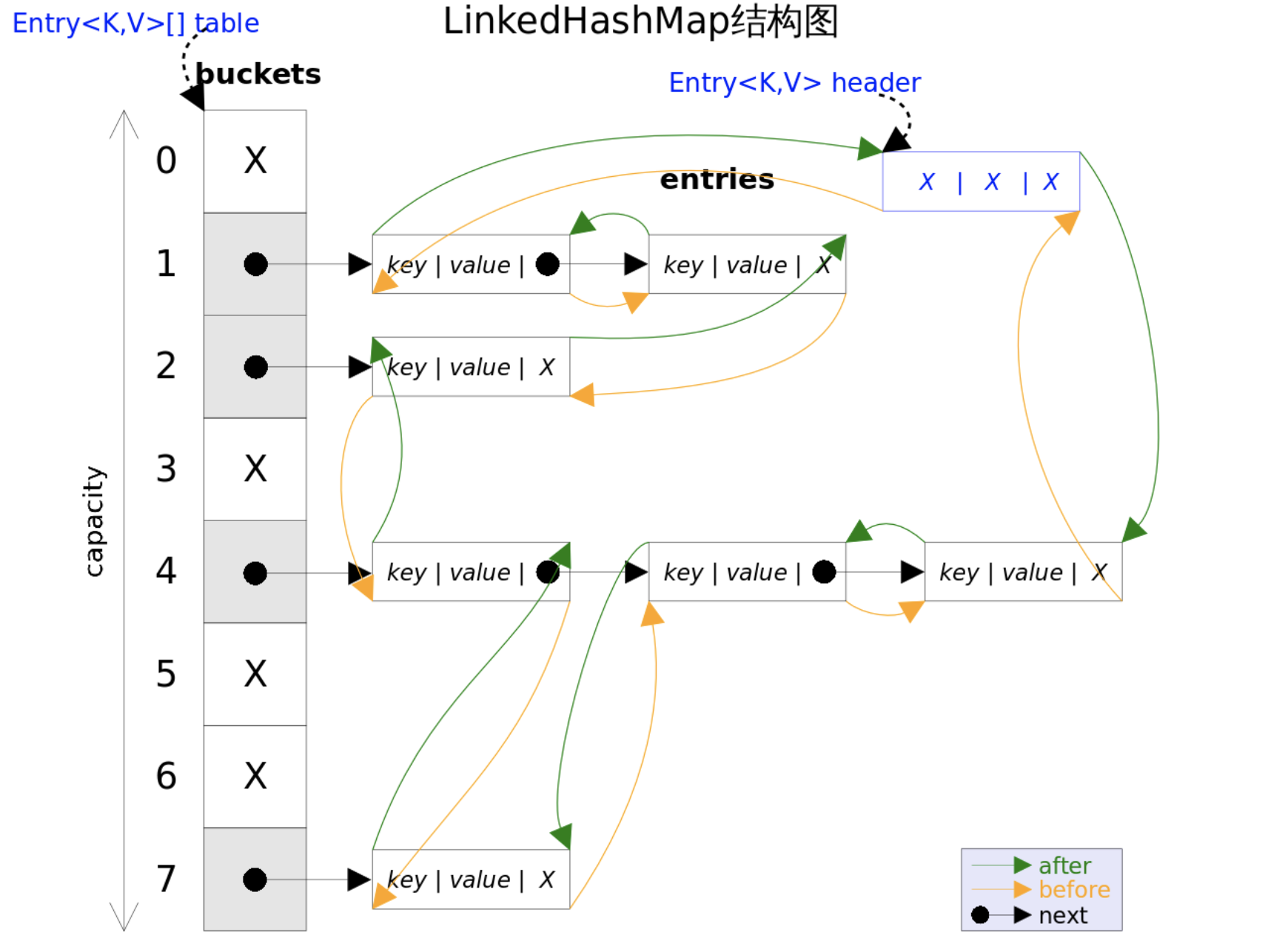
1 LinkedHashMap реализован на основе HashMap + двусвязного списка.
LinkedHashMap поддерживает двусвязный список на основе структуры данных HashMap для записи последовательности вставки данных или последовательности доступа для обеспечения упорядоченного доступа.
(1) Используйте двусвязный список для обеспечения упорядоченности.
Структура данных использования двусвязного списка для поддержания порядка HashMap выглядит следующим образом:
private static class Entry<K,V> extends HashMap.Entry<K,V> {
// These fields comprise the doubly linked list used for iteration.
Entry<K,V> before, after;
Entry(int hash, K key, V value, HashMap.Entry<K,V> next) {
super(hash, key, value, next);
}
...
}
Чтобы обеспечить порядок при использовании Iterator для обхода LinkedHashMap, LinkedHashMap также перезаписывает итератор LinkedHashIterator.
(2) Поддержка заказа на размещение или
порядка доступа. Заказ может быть либо заказом на размещение, либо порядком доступа. Реализация LinkedHashMap по умолчанию сортирует по порядку вставки. Вы можете установить порядок вставки или порядок доступа при создании экземпляра LinkedHashMap. Соответствующий конструктор LinkedHashMap выглядит следующим образом:
public LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
2 LinkedHashMap не является потокобезопасным
. Как и HashMap, LinkedHashMap также не является потокобезопасным. То есть несколько потоков могут писать LinkedHashMap одновременно в любое время, что может привести к несогласованности данных. Если вам необходимо обеспечить потокобезопасность, вы можете обернуть LinkedHashMap методом SynchronizedMap Collections, чтобы сделать его потокобезопасным.
ДеревоКарта
TreeMap — это упорядоченная карта, которая использует красно-черное дерево для достижения порядка.
TreeMap наследует от AbstractMap, поэтому это Map, то есть коллекция значений ключа.
TreeMap реализует интерфейс NavigableMap, что означает поддержку ряда методов навигации. Например, верните упорядоченную коллекцию ключей.
TreeMap реализует интерфейс Cloneable, что означает, что его можно клонировать.
TreeMap реализует интерфейс java.io.Serializable, что означает поддержку сериализации.
Поскольку он реализован с использованием древовидной структуры, временная сложность основных операций TreeMap, таких как containsKey, получение, размещение и удаление, равна log(n).
1 TreeMap реализован на основе красно-черных деревьев
(1) TreeMap использует красно-черные деревья для хранения пар ключ-значение.
Структура и реализация функций красно-черных деревьев не будут подробно рассмотрены в этом POST. Для получения дополнительных знаний о красном -черные деревья, см. «Структуру данных» (Ян Вейминь) или «Введение в алгоритм» Кормена Лейзерсона.
Структура узла красно-черного дерева определяется следующим образом:
static final class Entry<K,V> implements Map.Entry<K,V> {
K key;
V value;
// 左孩子
Entry<K,V> left;
// 右孩子
Entry<K,V> right;
// 父节点
Entry<K,V> parent;
// 树节点默认颜色是黑色
boolean color = BLACK;
public K getKey() {
... }
public V getValue() {
... }
public V setValue(V value) {
...}
public boolean equals(Object o) {
... }
public int hashCode() {
... }
public String toString() {
... }
}
(2) Упорядоченные по TreeMap
ключи TreeMap по умолчанию сортируются в лексикографическом порядке (по возрастанию), но могут быть отсортированы в соответствии с компаратором, предоставленным при создании.
TreeMap реализует интерфейс NavigableMap, придавая ему упорядоченную функцию.
Для получения дополнительной информации об использовании упорядоченных функций Tree обратитесь к ссылке
2. TreeMap
не является потокобезопасным, то есть несколько потоков могут одновременно писать в TreeMap в любое время, что может привести к несогласованности данных.
Набор
По сравнению со List и Map Set используется реже. Иерархия классов Set такова:

все три реализации (HashSet, LinkedHashSet и TreeSet), с которыми мы познакомились до сих пор, не являются потокобезопасными реализациями. По умолчанию используется HashSet. Используйте LinkedHashSet, когда вам нужно обеспечить упорядоченную вставку или упорядоченный доступ. Если вам нужно обеспечить порядок ключей, вы можете выбрать TreeMap.
Хэшсет
HashSet реализует интерфейс Set, который не допускает дублирования элементов в наборе.
1. HashSet реализован на основе HashMap.
HashSet создает коллекцию без повторяющихся элементов путем объединения HashMap.
(1) HashSet использует только ключи HashMap.
Значения, добавленные в HashSet, работают как ключи в объекте HashMap, а их значения используют одни и те же константы (поэтому значения всех ключей в ключе-значении пары одинаковые).
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable {
static final long serialVersionUID = -5024744406713321676L;
private transient HashMap map;
// Constructor - 1
// All the constructors are internally creating HashMap Object.
public HashSet()
{
// Creating internally backing HashMap object
map = new HashMap<>();
}
// Constructor - 2
public HashSet(int initialCapacity)
{
// Creating internally backing HashMap object
map = new HashMap<>(initialCapacity);
}
// Dummy value to associate with an Object in Map
private static final Object PRESENT = new Object();
}
Глядя на метод добавления элемента в HashSet, вы можете видеть, что значение пары ключ-значение, добавленной к объекту-члену карты, является тем же постоянным объектом. Соответствующий код выглядит следующим образом:
public boolean add(E e)
{
return map.put(e, PRESENT) == null;
}
2 HashSet не является потокобезопасным.
HashSet реализован на основе HashMap, поэтому HashSet также не является потокобезопасным.
LinkedHashSet
1 LinkedHashSet реализован на основе LinkedHashMap.
LinkedHashSet наследуется от HashSet. Если мы покопаемся в исходном коде HashSet, мы увидим, что базовый уровень реализован с использованием LinkedHashMap. Ключевой исходный код выглядит следующим образом:
public class LinkedHashSet<E>
extends HashSet<E>
implements Set<E>, Cloneable, java.io.Serializable {
/**
* Constructs a new, empty linked hash set with the default initial
* capacity (16) and load factor (0.75).
*/
public LinkedHashSet() {
super(16, .75f, true);
}
}
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable {
static final long serialVersionUID = -5024744406713321676L;
private transient HashMap<E,Object> map;
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
/**
* Constructs a new, empty linked hash set. (This package private
* constructor is only used by LinkedHashSet.) The backing
* HashMap instance is a LinkedHashMap with the specified initial
* capacity and the specified load factor.
*
*/
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
}
2 LinkedHashSet не является потокобезопасным.
LinkedHashSet реализован на основе LinkedHashMap, поэтому LinkedHashSet также не является потокобезопасным.
TreeHashSet
TreeHashSet реализует интерфейс NavigableSet, который гарантирует, что элементы набора сохраняются в порядке ключей (если указан компаратор, они сохраняются в порядке сравнения).
1 TreeHashSet реализован на основе TreeMap.Исходный код ключа следующий:
public class TreeSet<E> extends AbstractSet<E>
implements NavigableSet<E>, Cloneable, java.io.Serializable
{
/**
* The backing map.
*/
private transient NavigableMap<E,Object> m;
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
TreeSet(NavigableMap<E,Object> m) {
this.m = m;
}
public TreeSet() {
this(new TreeMap<>());
}
public TreeSet(Comparator<? super E> comparator) {
this(new TreeMap<>(comparator));
}
}
2 TreeHashSet не является потокобезопасным.
TreeHashSet реализован на основе TreeMap. Поскольку TreeMap не является потокобезопасным, TreeHashSet также не является потокобезопасным.
Очередь
Иерархия классов Queue выглядит следующим образом:
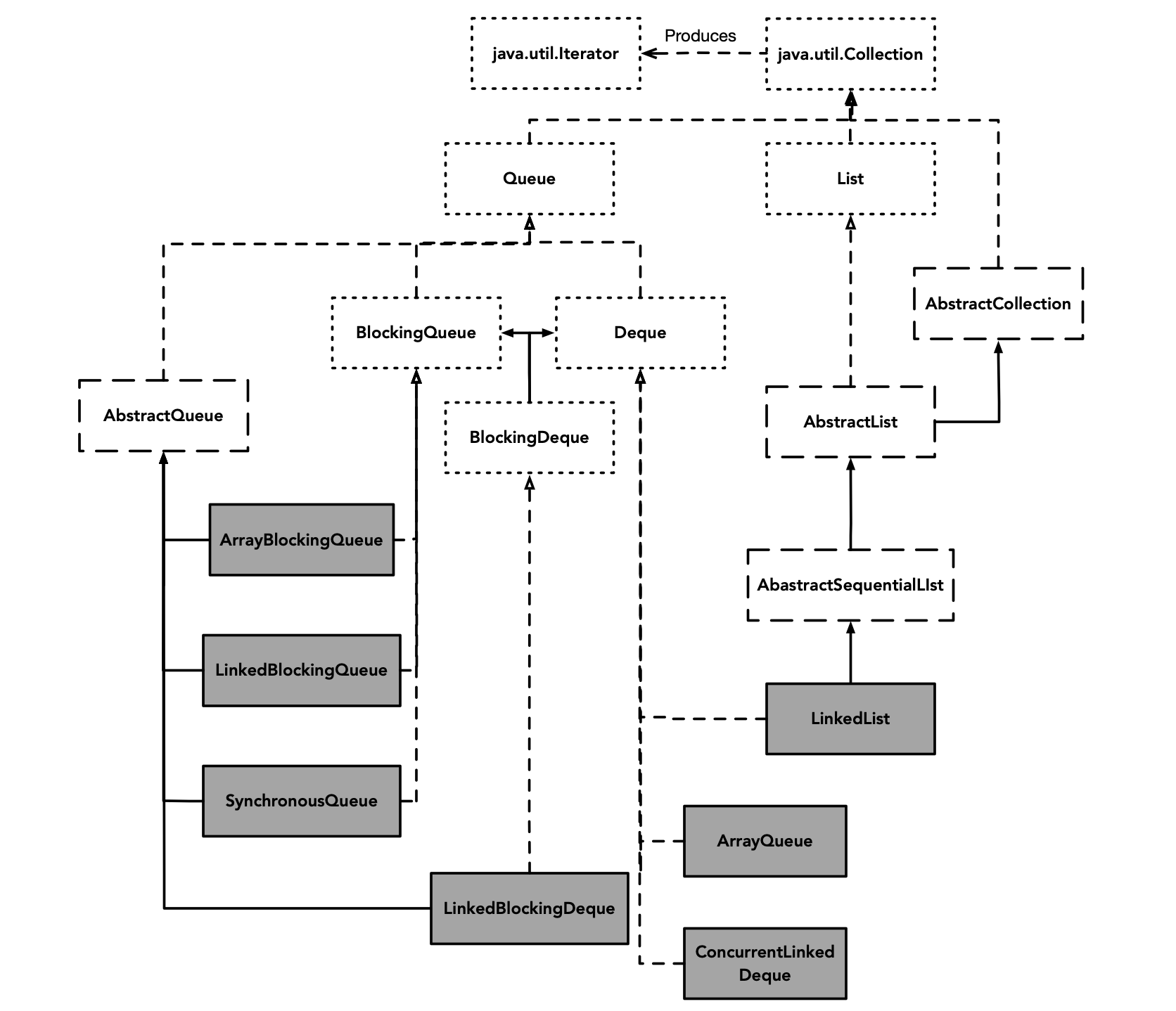
Когда Java реализует Queue, она в основном делит ее на три категории: Deque (двунаправленная очередь), BlockingQueue (блокирующая очередь) и BlockingDeque (двунаправленная блокирующая очередь).
Блокирующая очередь
BlockingQueue — это новый контейнер в Java 5.0. Библиотека классов содержит несколько реализаций BlockingQueue. Например, ArrayBlockingQueue и LinkedBlockingQueue — это очереди FIFO. Они похожи на ArrayList и LinkedList соответственно, но имеют лучшую производительность параллелизма, чем синхронизированный список. PriorityBlockingQueue — это очередь с приоритетом, которая очень полезна, когда вы хотите обрабатывать элементы в определенном порядке. SynchronousQueue не является настоящей очередью, поскольку в ней не предусмотрено место для хранения элементов очереди. Он поддерживает набор потоков, ожидающих добавления или удаления элементов из очереди.
Блокирующие очереди часто используются в сценариях производителя и потребителя.Производитель — это поток, который добавляет элементы в очередь, а потребитель — это поток, который берет элементы из очереди. Очередь блокировки — это контейнер, в котором производитель хранит элементы, а потребитель только забирает элементы из контейнера. Кроме того, в пуле потоков рабочая очередь, используемая ThreadPoolExecutor, также является очередью блокировки.
BlockingQueue является потокобезопасным . Метод BlockingQueue использует внутренние блокировки и другие формы стратегий управления параллелизмом для обеспечения безопасности потоков. Однако для пакетных операций это не обязательно потокобезопасная операция. Например, операция addAll© завершится неудачно, если можно добавить только некоторые элементы в c.
1. ArrayBlockingQueue
ArrayBlockingQueue — это фиксированная (емкость не может быть изменена после установки, а динамическое расширение не поддерживается) ограниченная блокирующая очередь, реализованная с использованием массива. ArrayBlockingQueue поддерживает справедливый и несправедливый доступ, а по умолчанию используется несправедливый доступ (см. исходный код JDK 1.8). (Каждый поток может ждать в очереди при получении блокировки. Если запрос потока, который первым получил блокировку, должен быть удовлетворен первым с точки зрения времени ожидания, то блокировка является справедливой. В противном случае блокировка является несправедливой. Справедливое получение блокировки. означает, что поток, ожидающий в данный момент дольше всех, получает блокировку первым).
ArrayBlockingQueue предоставляет несколько реализаций для операций вставки и удаления. Здесь мы сосредоточимся на методе put и методе take (чаще используются методы блокировки).
Когда поток вызывает метод put для вставки данных в очередь блокировки, и если он обнаруживает, что очередь блокировки заполнена, он будет ждать, пока очередь не заполнится, или завершит работу в ответ на прерывание. При выполнении метода put, если очередь заполнена, текущий поток будет добавлен в очередь ожидания объекта условия notFull. Он не будет пробужден для выполнения операции добавления, пока очередь не заполнится. Если очередь не заполнена, напрямую вызовите метод enqueue(e), чтобы добавить элементы в очередь. Следовательно, можно сделать вывод, что когда операция удаления элемента выполняется в очереди блокировки, поток, ожидающий очереди объекта условия notFull, будет разбужен, когда удаление будет успешным.
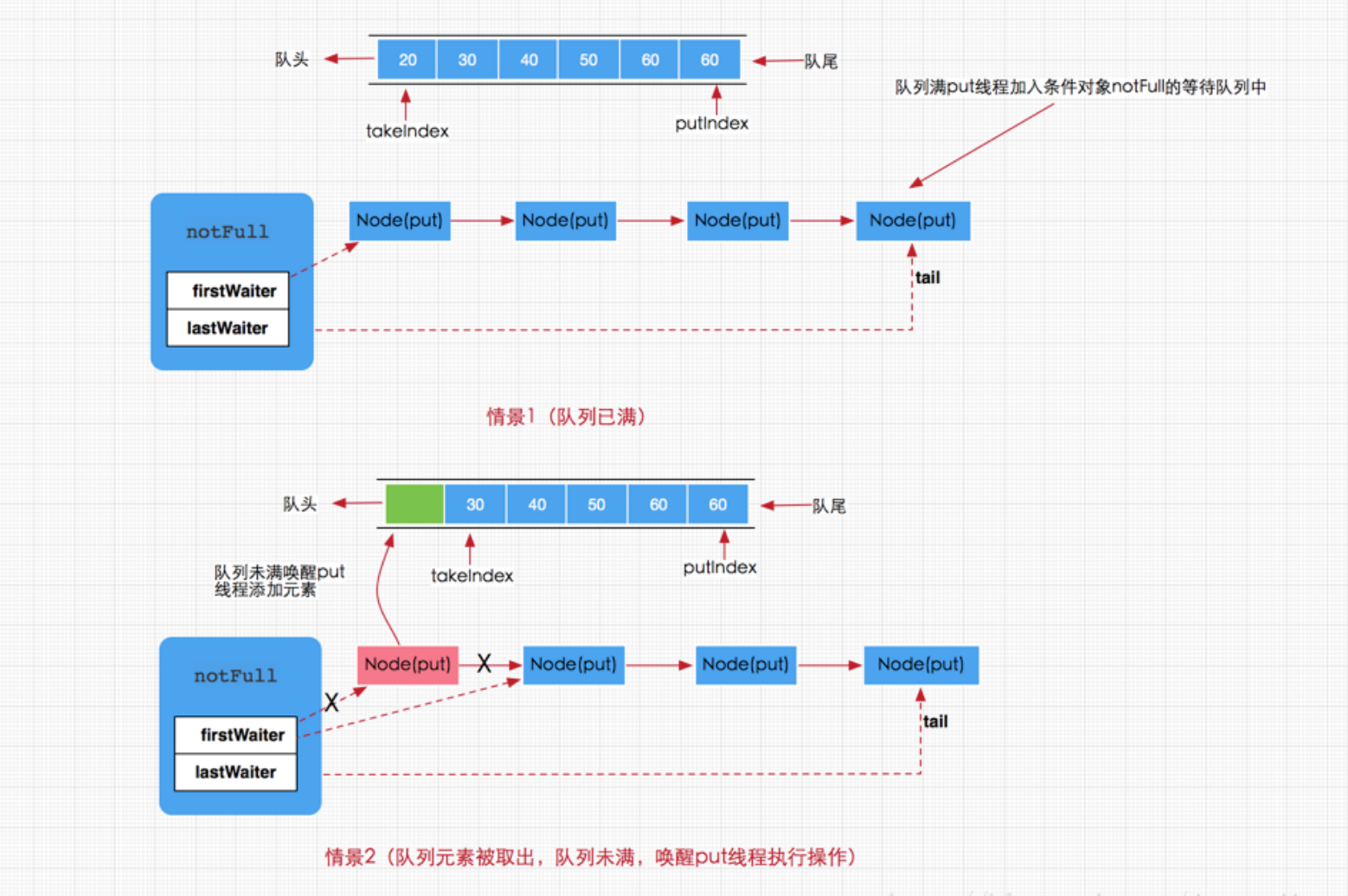
Когда поток вызывает метод take для удаления данных из очереди блокировки, если он обнаруживает, что очередь блокировки пуста, он будет ждать, пока очередь не станет пустой, или завершит работу в ответ на прерывание. Если при выполнении метода take очередь пуста, текущий поток будет добавлен в очередь ожидания объекта notEmpty Condition и не будет пробужден для выполнения операции удаления, пока очередь не станет пустой. Если очередь не пуста, вызовите метод dequeue() напрямую, чтобы удалить элемент из начала очереди. Следовательно, можно сделать вывод, что при добавлении элемента в блокирующую очередь поток, ожидающий очереди объекта notEmpty Condition, будет разбужен при успешном добавлении.
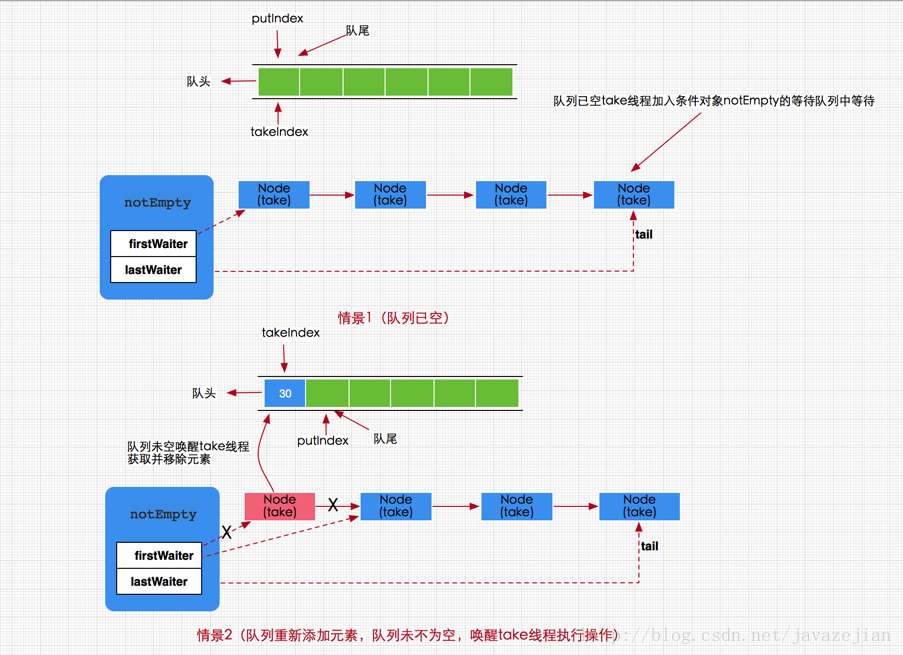
Анализ исходного кода ArrayBlockingQueue показывает, что безопасность потоков ArrayBlockingQueue достигается с помощью ReentrantLock для обеспечения монопольного доступа потока.
2 LinkedBlockingQueue
LinkedBlockingQueue — это ограниченная очередь, состоящая из структуры связанного списка. Максимальная длина этой очереди по умолчанию — Integer.MAX_VALUE (ее можно рассматривать как неограниченную очередь). При использовании LinkedBlockingQueue вы также можете указать его емкость во время инициализации. Очередь LinkedBlockingQueue сортируется в порядке «первым пришел — первым обслужен» (FIFO).
Поскольку LinkedBlockingQueue реализует интерфейс BlockingQueue, он также предоставляет несколько реализаций для операций вставки и удаления. Как и в случае с ArrayBlockingQueue, здесь мы фокусируемся на методе put и методе take (чаще используются блокирующие методы вызова).
Анализируя исходный код метода put LinkedBlockingQueue, мы можем обнаружить, что поток его обработки соответствует идее ArrayBlockingQueue: когда поток вызывает метод put для вставки данных в очередь блокировки, если он обнаруживает, что очередь блокировки заполнена, он будет ждать, пока очередь не заполнится или ответ не будет прерван. Когда поток вызывает метод take для удаления данных из очереди блокировки, если он обнаруживает, что очередь блокировки пуста, он будет ждать, пока очередь не станет пустой, или завершит работу в ответ на прерывание.
3 PriorityBlockingQueue
PriorityBlockingQueue — это неограниченная очередь (динамический массив), которая поддерживает сортировку по приоритету потоков. По умолчанию она сортируется в соответствии с естественным порядком. Вы также можете настроить метод CompareTo(), чтобы указать правила сортировки элементов, но порядок элементов с одинаковый приоритет не может быть гарантирован.
Поскольку PriorityBlockingQueue реализует интерфейс BlockingQueue, он также предоставляет несколько реализаций для операций вставки и удаления. Как и в случае с ArrayBlockingQueue, здесь мы фокусируемся на методе put и методе take (чаще используются блокирующие методы вызова).
Анализируя исходный код метода put PriorityBlockingQueue, мы можем обнаружить, что, поскольку PriorityBlockingQueue — это неограниченная очередь, блокировки не будет (происходит только OOM), а ее реализация — это передача метода Offer. Дальнейший анализ исходного кода метода Offer показывает, что PriorityBlockingQueue использует динамические массивы для хранения элементов и поддерживает пользовательские компараторы. Анализируя исходный код метода take PriorityBlockingQueue, мы можем обнаружить, что, поскольку очередь не может быть полной, он не будет оценивать, заполнена ли очередь.
Синхронная очередь
SynchronousQueue — это блокирующая очередь, в которой не сохраняются элементы . Каждая операция put должна ожидать операции take, иначе элементы не могут быть добавлены. Поддерживает справедливые и нечестные блокировки (по умолчанию — несправедливые). Один из сценариев использования SynchronousQueue находится в пуле потоков. Executors.newCachedThreadPool() использует SynchronousQueue. Этот пул потоков создает новые потоки по мере необходимости (при поступлении новых задач). Если есть простаивающие потоки, они будут использоваться повторно. Потоки будут перезапущены после простоя в течение 60 секунд.
Справедливый режим SynchronousQueue (FIFO, «первым пришел — первым обслужен») может уменьшить конфликты между потоками и обеспечить более высокую производительность в сценариях с частой конкуренцией, в то время как нечестный режим (LIFO, «последним пришел — первым обслужен») позволяет лучше поддерживать потоки. Локальность (локальность потока) уменьшает накладные расходы на переключение контекста потока.
Хотя SynchronousQueue реализует интерфейс BlockingQueue, он не поддерживает все методы, объявленные в интерфейсе. Например, метод peek всегда возвращает значение null. Перед использованием следует прочитать понятную реализацию интерфейса, чтобы не повлиять на корректность программы.
SynchronousQueue определяет абстрактный класс Transferer, который абстрагирует реализацию структур данных Dual Stack и Dual Queue. Он определяется следующим образом:
abstract static class Transferer<E> {
abst
ract E transfer(E e, boolean timed, long nanos);
}
Операции удаления из очереди и постановки в очередь SynchronousQueue делегируются интерфейсу передачи Transferer. Этот метод получает 3 параметра, где параметр e представляет значение элемента, которое будет добавлено в очередь. Для операции удаления из очереди e равно нулю; параметр timed используется. Чтобы установить, имеет ли текущая операция политику тайм-аута, если да, вам необходимо использовать параметр nanos (единица измерения: наносекунды), чтобы указать период тайм-аута.
1 Dual Stack
Для структуры данных Dual Stack SynchronousQueue реализует класс TransferStack. TransferStack наследует абстрактный класс Transferer и определяет класс SNode для записи информации об узлах в стек. Анализируя исходный код интерфейса передачи TransferStack, мы можем обнаружить:
(1) Когда стек пуст или режим работы ожидающего потока в стеке совпадает с режимом работы текущего потока, попробуйте поместить узел в стек и позвольте текущему потоку ожидать на узле.
(2) Когда режим работы потока, ожидающего в стеке, дополняет текущий поток (можно просто понять, что потоки, ожидающие в стеке, являются производителями, а текущий поток является потребителем), и ни один поток не выполняет операции сопоставления в это время, затем Текущий поток переходит в фазу сопоставления.
(3) Когда режим работы потока, ожидающего в стеке, дополняет текущий поток, и в это время поток выполняет операцию сопоставления, это означает, что сопоставление выполняется.
SynchronousQueue на основе Dual Stack всегда выполняет операции постановки в очередь и удаления из очереди на вершине стека, а потоки, которые присоединяются к очереди позже, будут сопоставлены первыми. Это также объясняет, почему SynchronousQueue на основе Dual Stack является несправедливым. Потенциальная проблема SynchronousQueue на основе Dual Stack заключается в том, что потоки, которые первыми присоединяются к очереди, не могут быть сопоставлены в течение длительного времени и голодать.Преимущество состоит в том, что он может лучше поддерживать локальность потока (локальность потока) и уменьшать накладные расходы. переключения контекста потока.
2 Dual Queue
Для структуры данных Dual Queue SynchronousQueue реализует класс TransferQueue. TransferQueue также наследуется от абстрактного класса Transferer и определяет класс QNode для описания узлов в очереди. Анализируя исходный код интерфейса передачи TransferStack, мы можем обнаружить, что:
(1) Когда очередь пуста или режим работы потока, ожидающего в очереди, такой же, как режим работы текущего потока, в это время: узел необходимо поместить в очередь, и текущий поток должен находиться на узле.
(2) Когда режим работы потока, ожидающего в очереди, дополняет текущий поток, он переходит в фазу сопоставления.
SynchronousQueue, основанный на Dual Queue, выполняет операции удаления из очереди в начале очереди и выполняет операции постановки в очередь в конце очереди. Поток, который первым присоединяется к очереди, обычно будет сопоставлен первым, что также объясняет, почему SynchronousQueue, основанный на Dual Queue, является справедливым. SynchronousQueue, основанный на Dual Queue, имеет более высокую производительность, чем нечестный режим, в сценариях с частой конкуренцией, поскольку конфликт между постановкой в очередь и удалением из нее относительно невелик.
Поэтому
В Java 6 добавлен контейнер Deque (произносится как «колода»). Deque (Deque — аббревиатура от «Double Ended Queue») — это двусторонняя очередь, которая реализует эффективную вставку и удаление начала и конца очереди. Библиотека классов содержит несколько реализаций Deque, таких как ArrayDeque и LinkedList , которые реализуют разные Deque.Они похожи на ArrayList и LinkedList соответственно. Кроме того, существует потокобезопасная реализация — ConcurrentLinkedDeque .
Deque объявляет 12 основных методов, а именно:
| Тип операции\имя метода | Элемент заголовка – выдает исключение | Элемент заголовка – возвращает специальное значение | Конечный элемент — выдает исключение | Конечный элемент — возвращает специальное значение |
|---|---|---|---|---|
| вставлять | addFirst(е) | предложениеПервый | добавитьПоследний (е) | предложениеПоследние(а) |
| Удалять | удалитьFirst()() | опросFirst() | удалить Ласт() | опросПоследний() |
| исследовать | getFirst()() | peekFirst() | getLast() | peekLast() |
Видно, что, хотя предварительное условие не выполнено, операция, зависящая от состояния, имеет следующие четыре дополнительные операции: она может генерировать исключение или возвращать статус ошибки (позволить вызывающей стороне разобраться с этой проблемой), или она может оставаться заблокированной. пока объект не перейдет в правильное состояние , или продолжайте блокировать до истечения времени ожидания . Но Deque не обеспечивает поддержку операций блокировки.
Интерфейс Deque расширяет (наследует) интерфейс Queue. При использовании дека в качестве очереди вы получаете поведение FIFO (первым пришел — первым обслужен). Добавляет элементы в конец двухсторонней очереди и удаляет элементы из начала двухсторонней очереди. Методы, унаследованные от интерфейса Queue, полностью эквивалентны методу Deque, сравнение следующее:
| Метод очереди | Метод дека |
|---|---|
| добавить(е) | добавитьПоследний (е) |
| предложение(е) | предложениеПоследние(а) |
| удалять() | удалитьFirst()() |
| голосование() | опросFirst()() |
| элемент() | getFirst()() |
| заглянуть() | пикфирст()() |
Здесь предполагается, что элементы входят справа и выходят слева (согласованы разные направления входа и выхода, и соответствующие методы различны).
Дек также может использоваться как стек LIFO (последним пришел — первым ушел). Этот интерфейс следует использовать вместо устаревших классов Stack. При использовании дека в качестве стека элементы помещаются и извлекаются из начала дека. Метод stack полностью эквивалентен методу Deque, как показано в следующей таблице:
| Метод стека | Метод дека |
|---|---|
| толчок(е) | addFirst(e)/offerFirst(e) |
| поп() | удалитьFirst()/pollFirst() |
| заглянуть() | getFirst()/peek()First() |
Здесь предполагается, что элементы входят и выходят с левой стороны Deque.
Deque интегрирует интерфейс Queue, поэтому Deque можно использовать как обычную очередь (один конец входит, а другой конец выходит). Кроме того, Deque также объявляет интерфейс, необходимый для двусторонней очереди (оба конца могут входить и выходить) . Вы также можете использовать двустороннюю очередь, настроив ее поведение в виде стека (первым пришел, последним ушел)**.
1 ArrayDeque
ArrayDeque — это особая реализация интерфейса Deque. ArrayDeque реализован на основе динамических массивов. ArrayDeque не имеет ограничений по емкости и может автоматически расширяться в соответствии с потребностями. Обратите внимание, что ArrayDeque не поддерживает нулевые элементы. Потокобезопасность ArrayDeque не гарантируется. Для потокобезопасных сценариев рекомендуется использовать ConcurrentLinkedDeque.
Длина ArrayDeque по умолчанию равна 16. Динамически растущая длина ArrayDeque будет использовать разные стратегии в зависимости от текущей емкости. В частности, когда емкость меньше 64, она каждый раз растет в геометрической прогрессии, а когда емкость больше или равна 64, она растет вдвое.
Deque поддерживает множество операций, но есть три операции, которые невозможно обойти: вставка, удаление и проверка. Здесь мы выбираем репрезентативный метод addFirst(), метод removeFirst() и метод getFirst().
/**
* Circularly decrements i, mod modulus.
* Precondition and postcondition: 0 <= i < modulus.
*/
static final int dec(int i, int modulus) {
if (--i < 0) i = modulus - 1;
return i;
}
public void addFirst(E e) {
if (e == null)
throw new NullPointerException();
final Object[] es = elements;
es[head = dec(head, es.length)] = e;
if (head == tail)
grow(1);
}
Анализируя исходный код addFirst(), мы можем обнаружить, что при добавлении элемента в ArrayDeque будет выдано исключение, если элемент имеет значение null (элемент с нулевым значением не поддерживается), поэтому будьте внимательны при его использовании (другая вставка методы также вынесут такое суждение).
Анализируя исходный код addFirst(), мы также можем обнаружить, что массив, хранящий элементы, используется как кольцо. Обычно после добавления элемента в начало очереди, если массив выходит за пределы, элемент будет вставлен вперед с конца очереди (если элемент уже существует, он будет перезаписан).
Когда обнаруживается, что начало и конец очереди указывают на один и тот же элемент, это означает, что емкость занята и ее можно расширить.
/**
* Circularly increments i, mod modulus.
* Precondition and postcondition: 0 <= i < modulus.
*/
static final int inc(int i, int modulus) {
if (++i >= modulus) i = 0;
return i;
}
public E removeFirst() {
E e = pollFirst();
if (e == null)
throw new NoSuchElementException();
return e;
}
public E pollFirst() {
final Object[] es;
final int h;
E e = elementAt(es = elements, h = head);
if (e != null) {
es[h] = null;
head = inc(h, es.length);
}
return e;
}
Анализируя исходный код метода removeFirst(), мы можем обнаружить, что это всего лишь модуляция метода pollFirst(). Копаясь в исходном коде метода pollFirst(), мы можем обнаружить, что процесс удаления элемента — это процесс установки его значения в значение null и одновременного обновления указателя заголовка.
/**
* Returns element at array index i.
* This is a slight abuse of generics, accepted by javac.
*/
@SuppressWarnings("unchecked")
static final <E> E elementAt(Object[] es, int i) {
return (E) es[i];
}
public E getFirst() {
E e = elementAt(elements, head);
if (e == null)
throw new NoSuchElementException();
return e;
}
Метод getFirst() — это процесс получения элементов из массива без специальной обработки.
2 LinkedList LinkedList был представлен
ранее . Здесь мы дополнительно проанализируем LinkedList с точки зрения Deque. LinkedList — это конкретная реализация интерфейса Deque. LinkedList реализован на основе связанного списка. В отличие от ArrayDeque, LinkedList поддерживает нулевые элементы. Как и ArrayDeque, LinkedList не может гарантировать потокобезопасность. Для потокобезопасных сценариев также рекомендуется использовать ConcurrentLinkedDeque. 3 ConcurrentLinkedDeque ConcurrentLinkedDeque — это особая реализация интерфейса Deque. ConcurrentLinkedDeque основан на связанном списке. ConcurrentLinkedDeque может обеспечить безопасность потоков. В отличие от LinkedList, ConcurrentLinkedDeque не допускает нулевых элементов. ConcurrentLinkedDeque реализует потокобезопасность внутри CAS. Вообще говоря, если вам нужно использовать потокобезопасную двустороннюю очередь, рекомендуется использовать этот класс.
public class ConcurrentLinkedDeque<E>
extends AbstractCollection<E>
implements Deque<E>, java.io.Serializable {
private transient volatile Node<E> head;
private transient volatile Node<E> tail;
// 双链表
static final class Node<E> {
volatile Node<E> prev;
volatile E item;
volatile Node<E> next;
}
}
При использовании ConcurrentLinkedDeque обратите внимание:
(1) Используйте метод size() с осторожностью, результат метода size может быть неточным. Поскольку ConcurrentLinkedDeque использует CAS для обеспечения потокобезопасности , возвращаемое значение метода size не обязательно является точным (несколько потоков могут одновременно работать с элементами в ConcurrentLinkedDeque).
(2) Пакетные операции не могут гарантировать атомарность . Для пакетных операций, таких как addAll, RemoveAll, continueAll, containsAll, Equals, toArray и т. д., ConcurrentLinkedDeque не может гарантировать атомарность этих операций.
(3) При использовании итератора для обхода ConcurrentLinkedDeque, поскольку это двусвязный список, возникают ситуации, когда элементы могут быть удалены, но все равно доступны через итератор (слабо согласованный обход).
4. Принципы выбора для ArrayDeque, LinkedList и ConcurrentLinkedDeque
. В непотокобезопасных сценариях можно выбрать ArrayDeque или LinkedList. Из-за особенностей Deque критерии выбора для ArrayDeque и LinkedList отличаются от критериев выбора для стандартных массивов и списков. Поскольку деятельность Deque сосредоточена на «голове» или «хвосте» команды, у LinkedList есть естественное преимущество. В реализации Deque рекомендуется выбирать LinkedList.
Согласно комментариям исходного кода ArrayDeque, при использовании в качестве очереди его производительность выше, чем у LinkedList (только в сценариях, где известно количество элементов).
This class is likely to be faster than {@link Stack} when used as a stack, and faster than {@link LinkedList} when used as a queue.
В потокобезопасных сценариях вы можете выбрать ConcurrentLinkedDeque.
БлокированиеDeque
В Java 6 добавлен контейнер BlockingDeque, который расширяет BlockingQueue. BlockingDeque - блокирующая двусторонняя очередь. Помимо функции двусторонней очереди, она также имеет функцию блокирующей очереди - когда элементы не могут быть вставлены, она блокирует поток, пытающийся вставить элементы; когда элементы не могут быть вставлены. быть извлечен, он заблокирует поток, пытающийся извлечь; потокобезопасен; элементы с нулевыми значениями не допускаются и т. д. Конкретная реализация — LinkedBlockingQueue. Исходный код BlockingDeque прокомментирован следующим образом:
Like any BlockingQueue, a BlockingDeque is thread safe, does not permit null elements, and may (or may not) be capacity-constrained.
BlockingDeque наследует BlockingQueue и Deque, поэтому BlockingDeque поддерживает как операции BlockingQueue, так и операции Deque.
Как и BlockingQueue, BlockingDeque также является потокобезопасным и использует стратегию управления параллелизмом внутренних блокировок (непустые блокировки и неполные блокировки) для обеспечения потокобезопасности. В то же время для пакетных операций это не обязательно поток. -безопасная эксплуатация.
BlockingDeque можно применять как к сценариям BlockingQueue, так и к сценариям Deque. Но чаще всего BlockingDeque предназначен не для замены BlockingQueue или Deque, а для решения сценариев, в которых BlockingQueue и Deque необходимо использовать одновременно. Например, сценарий извлечения рабочего секрета
1. LinkedBlockingDeque
LinkedBlockingDeque — это конкретная реализация интерфейса BlockingDeque. LinkedBlockingDeque реализован на основе двусвязного списка.При создании экземпляра LinkedBlockingDeque можно указать емкость. LinkedBlockingDeque использует объекты lock + Condition для обеспечения потокобезопасного доступа. LinkedBlockingDeque не позволяет вставлять нулевые элементы.
BlockingQueue、Deque、BlockingDeque
Точно так же, как очереди блокировки подходят для модели производитель-потребитель, двусторонние очереди блокировки подходят для модели кражи работы (Work Stealing). В модели производитель-потребитель все потребители имеют общую рабочую очередь, и все потребители конкурируют за ресурсы в общей рабочей очереди. При выборке работы каждый потребитель имеет свой собственный дек. Если потребитель завершает всю работу в своей собственной очереди, он может получить работу с конца очереди других потребителей (обратите внимание, не из головы очереди, чтобы уменьшить конкуренцию в очереди).
Рабочие секреты идеально подходят для решения проблем как потребителей, так и производителей — при выполнении определенной работы может появиться больше работы.
Операторы и выражения
== и равно
==Бинарный оператор и метод равенства
В зависимости от типа данных (тип значения, ссылочный тип, нулевой тип) оператор == сравнивает их значения для «типов значений» и «нулевых типов», для «ссылочных типов» сравнивает их содержимое в памяти . адрес , то есть указывает ли он на тот же объект.
Все классы в Java наследуются от Object. Класс Object определяет метод Equals.Первоначальное поведение этого метода заключается в сравнении адресов памяти объектов . Реализация следующая:
public boolean equals(Object obj) {
return (this == obj);
}
Однако некоторые библиотеки классов переписали этот метод, например String, Integer, Date и т. д., вместо сравнения адреса хранения в куче памяти.
Нить
Строка перезаписывает равенство, чтобы сравнить, равны ли значения. Реализация следующая:
public boolean equals(Object anObject) {
if (this == anObject) {
return true;
}
if (anObject instanceof String) {
String aString = (String)anObject;
if (coder() == aString.coder()) {
return isLatin1() ? StringLatin1.equals(value, aString.value)
: StringUTF16.equals(value, aString.value);
}
}
return false;
}
Поскольку String переопределяет метод равенства, следующий код возвращает true.
String str1 = new String("123");
String str2 = new String("123");
// true
str1.equals(str2);
Поскольку оператор == сравнивает только то, указывает ли он на одну и ту же память для «ссылочных типов» , два экземпляра new String не равны. Пример кода выглядит следующим образом:
String str1 = new String("123");
String str2 = new String("123");
// false
str1 == str2;
Обертка String поддерживает буквальное присваивание. При создании строки в виде: stringInstance="xxx" программа сначала будет искать объект с таким же значением в пуле строковых буферов. Если в пуле нет объекта с таким же значением, пул, он добавит ценность в пул. Итак, следующие значения кода равны:
String str1 = "123";
// true
str1 == "123";
Но следует также отметить, что если вы используете new для создания примера строки , использование == будет считать обе стороны неравными. Пример кода выглядит следующим образом:
String str1 = new String("123");
// false
str1 == "123";
Таким образом, для сравнения строк на равенство строго используйте интерфейс равенства . Обертка (аналогично Integer)
Целое число
Чтобы повысить производительность таких оболочек, как Integer, Java вводит пулы кэша. Integer имеет два метода экземпляра: new Integer(xxx) и Integer.valueOf(xxx). Разница между ними заключается в том, что новый метод Integer(xxx) будет каждый раз создавать новый объект; Integer.valueOf(123) будет использовать объект в пуле , а несколько вызовов получат ссылку на один и тот же объект. В Java 8 размер целочисленного буферного пула по умолчанию составляет -128~127. Попав за пределы этого диапазона, целочисленные значения не кэшируются. Исходный код valueOf выглядит следующим образом:
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}
Короткий и длинный
Short и Long также предоставляют пулы кэша.
public static Short valueOf(short s) {
final int offset = 128;
int sAsInt = s;
if (sAsInt >= -128 && sAsInt <= 127) {
// must cache
return ShortCache.cache[sAsInt + offset];
}
return new Short(s);
}
public static Long valueOf(long l) {
final int offset = 128;
if (l >= -128 && l <= 127) {
// will cache
return LongCache.cache[(int)l + offset];
}
return new Long(l);
}
Плавающее и двойное
Float и Double не обеспечивают реализацию пула кэша. Обратите особое внимание при его использовании. Реализации, связанные с плавающей точкой, следующие:
public static Float valueOf(float f) {
return new Float(f);
}
public Double(double value) {
this.value = value;
}
контроль над процессом
Последовательные операторы, условные операторы, операторы цикла
объектно-ориентированный
копия объекта
Копирование объекта — это создание копии объекта. По глубине копирования копии объектов можно разделить на две категории: поверхностные и глубокие копии.
В языке Java, если вам необходимо реализовать глубокое клонирование, вы можете сделать это, переопределив метод clone() класса Object или с помощью сериализации (Serialization) и других методов. (Если ссылочный тип также содержит множество ссылочных типов или класс внутреннего ссылочного типа содержит ссылочные типы, будет затруднительно использовать метод клонирования. В настоящее время мы можем использовать сериализацию для достижения глубокого клонирования объекта.) Резюме:
(1) Реализуйте интерфейс Cloneable и переопределите метод clone() в классе Object.
(2) Внедрить интерфейс Serializable и реализовать клонирование посредством сериализации и десериализации объектов, что позволит достичь настоящего глубокого клонирования.
Объектно-ориентированный – три основные характеристики
Также известен как «три основные характеристики» и «три элемента». Инкапсуляция, наследование, полиморфизм
Инкапсуляция
Инкапсуляция имеет два значения:
языковая структура, которая облегчает объединение данных с методами (или другими функциями), которые работают с этими данными. (Инкапсуляция объектов)
Языковой механизм для ограничения прямого доступа к определенным компонентам объекта. (Контроль доступа)
Инкапсуляцию Java можно понимать как: инкапсуляцию данных и методов (определение классов) , управление правами доступа (добавление модификаторов доступа) .
Контроль доступа часто называют «сокрытием реализации». Упаковка данных и методов в классы и сокрытие конкретных реализаций часто вместе называются «инкапсуляцией». (Идеи программирования на Java)
Дополнительная информация
Чтобы объединить данные и методы работы с этими данными, объектно-ориентированные языки, такие как Java, реализуют эту функцию путем введения «классов». При этом для ограничения прямого доступа предусмотрены модификаторы доступа.
Наследование
Наследование — это языковой механизм создания одного объекта или класса на основе другого объекта (наследование на основе прототипа) или класса (наследование на основе классов). Этот языковой механизм не только сохраняет реализацию существующих классов (суперклассов или базовых классов) при создании новых классов (подклассов), но и формирует иерархию классов. Больше информации
Одиночное наследование и множественное наследование
Простое сравнение одинарного и множественного наследования не имеет смысла. И язык Java, основанный на одиночном наследовании, и язык C++, основанный на множественном наследовании, добились больших успехов в определенных областях. Основное внимание здесь уделяется причинам, по которым язык Java выбирает одиночное наследование и отказывается от множественного наследования. Чтобы понять технический выбор одинарного и множественного наследования в Java, вы должны сначала понять цели проектирования языка Java:
Simple, object oriented, and familiar
Robust and secure
Architecture neutral and portable
High performance
Interpreted, threaded, and dynamic
Множественное наследование классов отличается особой гибкостью, но его сложная семантика затрудняет его понимание и использование. С другой стороны, множественное наследование используется редко (Rarely Used), и многие функции могут быть достигнуты посредством « одиночного наследования + множественного наследования интерфейсов + комбинации ». ссылка1 ссылка2
Java реализует множественное наследование
Внутренние классы Java: наследуйте внутренний класс, а затем создайте экземпляр внутреннего класса во внешнем классе. Суть заключается в комбинационном механизме.
Полиморфизм
Полиморфизм — это использование одного интерфейса для обозначения разных типов объектов или использование одного символа для представления нескольких разных типов. Полиморфизм — это предоставление единого интерфейса для сущностей разных типов или использование одного символа для представления нескольких разных типов.
В Java это означает вызов методов родительского класса во время кодирования и динамическое связывание методов подкласса во время выполнения. Поэтому полиморфизм также называют «динамическим связыванием», «поздним связыванием» и «привязкой во время выполнения» .
Раннее связывание и позднее связывание
Так называемая «привязка» — это процесс связывания вызова метода с телом метода.
Так называемое «раннее связывание» означает, что метод и соответствующее тело метода уточняются до выполнения программы . (Язык C поддерживает только раннее связывание.)
Так называемое «динамическое связывание» означает, что во время работы программы соответствующее тело метода может быть привязано в соответствии с типом объекта. ( Java поддерживает динамическое связывание, и, за исключением статических методов и финальных методов (все частные методы являются окончательными), все остальные методы являются поздним связыванием ).
Полиморфизм и масштабируемость
Полиморфный механизм обеспечивает масштабируемость программы.
Основные принципы объектно-ориентированного
В области программирования SOLID (единственная ответственность, принцип открытости и закрытости, замена Лискова, изоляция интерфейса и инверсия зависимостей) — это мнемоническая аббревиатура, введенная Робертом К. Мартином в начале 21 века для обозначения пяти основных принципов объектно-ориентированного подхода. программирования и объектно-ориентированного проектирования. Когда эти принципы применяются вместе, они позволяют программисту разработать систему, которую легко поддерживать и расширять. Принципы, содержащиеся в SOLID, представляют собой рекомендации, которые можно применять, когда программное обеспечение является ясным, читаемым и масштабируемым, побуждая программистов проводить рефакторинг исходного кода программного обеспечения, чтобы убрать запахи кода программного обеспечения. Это справочная ссылка.
Однако в реальном процессе объектно-ориентированной разработки также используются «Закон Димитера» и «Принцип повторного использования композиции/агрегации».
После того, как вы познакомитесь с «основными принципами объектно-ориентированного подхода», вы сможете понимать его как цель «высокой связанности и слабой связи».
1. Принцип единой ответственности
Каждый класс должен сосредоточиться на выполнении одного дела.
Этот принцип относится к «Принципу сплоченности» «Структурного анализа и спецификации системы».
В процессе кодирования для следования этому принципу часто используется идея «разделения обязанностей».
Справочная ссылка
2. Принцип открытия-закрытия
Открыт для расширения, закрыт для модификации.
Этот принцип является стремлением к кодированию. Чрезмерное соблюдение «принципа открытия и закрытия» приведет к усложнению функции и системы.
Справочная ссылка
3. Принцип замены Лискова.
Везде, где существует базовый класс, его можно заменить подклассом.
Прямым применением принципа замены Лискова является полиморфизм (динамическое связывание).
4. Принцип разделения интерфейса
Клиентам следует предоставлять минимально возможные отдельные интерфейсы, а не большой общий интерфейс. Этот принцип гласит, что клиент не должен зависеть от методов, которые он не использует. Это также один из способов достижения «высокой сплоченности». Этот принцип также используется для разделения системы, чтобы облегчить ее реконструкцию.
Справочная ссылка
5. Принцип инверсии зависимостей
Также известен как «принцип инверсии зависимостей», «принцип инверсии зависимостей».
Этот принцип относится к особой форме разделения (традиционные зависимости создаются на высоких уровнях, а определенные параметры политики применяются к модулям низкого уровня), чтобы модули высокого уровня не зависели от модулей низкого уровня. перевернутый (инвертированный), так что модули более низкого уровня зависят от абстракции требований модулей более высокого уровня. Этот принцип предусматривает:
(1) Модули высокого уровня не должны зависеть от модулей низкого уровня, оба должны зависеть от абстрактных интерфейсов. (Интерфейсно-ориентированное программирование)
(2) Абстрактные интерфейсы не должны зависеть от конкретных реализаций (экземпляров классов). Конкретная реализация должна опираться на абстрактный интерфейс (реализация должна максимально полагаться на абстракцию, а не на конкретную реализацию)
Ссылка 1
Ссылка 2
6. Закон Деметры
Также называемый «принципом наименьшего количества знаний», программный объект должен как можно меньше взаимодействовать с другими объектами . (Я называю это «Наименее известным принципом»).
Этот принцип является одним из принципов, которым следуют для достижения слабой связи (Loose Coupling).
Справочная ссылка 1
7. Принцип повторного использования композитов/агрегатов (CARP)
Принцип повторного использования композиции/агрегации (CARP), также известный как принцип повторного использования комбинации. Семантическое описание этого принципа таково: используйте композицию/агрегацию как можно больше, чтобы добиться повторного использования, и как можно меньше используйте наследование.
Обратите внимание, что этот принцип не является панацеей, поскольку наследование нельзя полностью заменить композицией. Это всего лишь предупреждение использовать «наследование» с осторожностью.Как только наследование будет использовано, оно приведет к тесной связи между «подклассом» и «родительским классом» .
Реализация: ссылка на объект другого класса в одном классе.
Справочная ссылка 1
Знакомство с классом
В объектно-ориентированных языках класс чаще всего используется для представления нового типа, и в Java также используется это ключевое слово.
статическое ключевое слово и последнее ключевое слово
Инициализация и очистка
При кодировании программ на языке C многие ошибки возникают из-за того, что программисты забывают инициализировать переменные и освободить память. **C++ и Java вводят конструкторы, гарантирующие возможность инициализации каждого объекта. А через механизм сбора мусора обеспечить очистку объектов. **В Java «инициализация» и «создание» связаны вместе, и их нельзя разделить.
метод финализации()
Функция 1: В качестве дополнения к механизму сборки мусора освободите пространство памяти, занимаемое объектами, не созданными на основе нового метода (например, пространство памяти, выделенное локальными методами, вызывающими C или C++). Функция 2: Выполните работу по очистке
, кроме сбор мусора, например закрытие дескрипторов файлов. ).
Контроль доступа
Java предоставляет модификаторы доступа разработчикам библиотек классов, чтобы указать клиентским программистам, доступны или недоступны члены.
упаковка
Пакет содержит набор классов, организованных в одном пространстве имен. (аналогично пространству имен C#), имена пакетов пишутся строчными буквами и разделяются точками.
Создайте уникальное имя пакета: поместите все файлы в подкаталог, а затем определите уникальное имя каталога (например, имя домена Интернета).
Используйте ClassPath, чтобы указать путь, где находится файл .class, или место хранения пакета jar (c:\access\java\grape.jar).
Доступ к пакету
Права доступа по умолчанию. Все члены в одном пакете доступны автоматически, но для всех классов вне пакета эти члены являются закрытыми.
общественный
частный
защищенный
Разрешения на доступ к классу
Разрешения доступа внешних классов могут быть только общедоступными и разрешениями доступа к пакету: к частным и защищенным классам нельзя получить доступ извне. Если этот класс является внутренним классом (классом-членом), можно использовать все четыре модификатора доступа.
инкапсуляция
Управление правами доступа часто называют сокрытием реализации . Упаковка данных и методов в классы и сокрытие конкретной реализации часто вместе называются инкапсуляцией.
Существует два аспекта инкапсуляции: инкапсуляция данных и методов (определение классов) и управление разрешениями доступа (добавление модификаторов доступа).
повторное использование
Существует много форм повторного использования. В частности, их можно разделить на три категории: наследование, комбинация и прокси.
комбинация
Поместите ссылку на объект в новый класс. (Создайте объект существующего класса в новом классе или используйте статический метод существующего класса.)
Компилятор не создает объект по умолчанию для каждой ссылки. Эти ссылки необходимо инициализировать вручную.
Наследование (наследование с одним корнем)
Создавайте новые классы на основе существующих классов.
действующий
Поместите объект в создаваемый класс (аналоговая композиция), но в то же время откройте все методы объекта-члена в новом классе (аналоговое наследование). Видно, что прокси — это комбинация + ручное наследование .
Выбор наследования и состава
Больше используйте композицию и меньше наследование . Используйте наследование только тогда, когда необходимо повышающее преобразование.
Методы композиции обычно используются, когда вам нужно использовать функциональность существующего класса, а не его интерфейс.
Наследование используется, когда вам нужно использовать интерфейс существующего класса.
Полиморфизм
Полиморфизм достигается за счет динамического связывания, поэтому характеристики подкласса можно показать при вызове метода родительского класса.
Так называемая привязка заключается в том, чтобы связать вызов метода с одним и тем же телом метода . По времени возникновения связывания его разделяют на раннее связывание и позднее связывание.
Раннее связывание
Привязка перед выполнением программы. В языке C есть только один вызов метода — раннее связывание .
Позднее связывание (динамическое связывание/привязка во время выполнения)
Привязка выполняется во время выполнения в зависимости от типа объекта. За исключением статических методов и финальных методов (частные методы — это тип финального метода), все остальные методы в Java имеют позднее связывание.
Конструкторы и полиморфизм
Старайтесь не использовать методы позднего связывания в конструкторе, чтобы избежать неопределенности, вызванной полиморфизмом.
внутренний класс
В Java другой класс, помещенный внутри класса, называется внутренним классом. В зависимости от различных используемых модификаторов и места определения внутренние классы можно разделить на: внутренние классы-члены (без модификатора static), статические внутренние классы (с модификатором static), локальные внутренние классы (с именем класса), анонимные внутренние классы. четыре типа классов (без имен классов). Сценарии использования внутренних классов имеют приоритет и постепенно заменяются выражениями Lamda (от локальных внутренних классов к анонимным внутренним классам).
Введение внутренних классов в язык Java в основном включает в себя следующие два соображения:
(1) Улучшение возможностей множественного наследования языка Java . Язык Java имеет единый механизм наследования (все подклассы имеют общий родительский класс). Такая конструкция значительно упрощает использование языка, но в некоторых сценариях по-прежнему требуется механизм множественного наследования. Целью введения внутренних классов в язык Java является улучшение возможностей множественного наследования языка Java. Каждый внутренний класс может независимо наследовать класс. Независимо от того, унаследовал ли внешний класс класс или нет, это не влияет на внутренний класс. При разработке и проектировании будут возникать некоторые проблемы, которые сложно решить с помощью интерфейсов, но классы могут наследовать только один родительский класс. В настоящее время вы можете использовать внутренние классы для наследования других родительских классов и реализации нескольких интерфейсов для решения проблемы.
(2) Улучшите свойства упаковки . Внутренние классы могут быть скрыты снаружи в разной степени в зависимости от прав доступа. Это сочетает в себе принципы высокой связности и низкой связанности объектно-ориентированного мышления. Скрытие внутренних классов во внешних классах также может улучшить читаемость и удобство обслуживания кода.
Разделение внутренних классов может относиться к классификации переменных-членов класса. Внутренние классы можно разделить следующим образом в зависимости от различных используемых модификаторов и места определения:
(1) Уровень члена, определенного во внешнем классе.
Внутренний класс элемента (без статического модификатора)
Статический внутренний класс (со статическим модификатором).
(2 ) ) , определенный в теле метода/блоке кода внешнего класса, локального
внутреннего класса (с именем класса),
анонимного внутреннего класса (без имени класса)
член внутреннего класса
Нестатический внутренний класс , определенный внутри внешнего класса, называется внутренним классом-членом. Пример кода для создания внутреннего класса-члена выглядит следующим образом:
// OuterClass.java
public class OuterClass {
private String privateField;
String defaultField;
protected String protectedField;
public String publicField;
class DefaultInnerClass {
private String privateField;
String defaultField;
protected String protectedField;
public String publicField;
}
}
Объявление внутреннего класса-члена во внешнем классе можно рассматривать как обработку класса-члена как переменной-члена или метода-члена. Например, внутренний класс в приведенном выше примере кода имеет разрешение доступа по умолчанию (разрешение пакета). В то же время он также поддерживает модификацию с помощью частных, защищенных, общедоступных, конечных, статических и других символов или модификаторов управления доступом.
Обратите внимание, что не рекомендуется изменять внутренние классы с помощью public. Это связано с тем, что это нарушит функцию, которую внутренние классы используют для сокрытия деталей. Если вам действительно необходимо использовать общедоступную модификацию, вам следует определить ее отдельно и использовать внешние классы путем их комбинирования.
При использовании внутренних классов-членов особое внимание необходимо уделять доступу между внутренними и внешними классами. Внутренний класс-член может напрямую обращаться к внешнему классу, а внешний класс должен обращаться к экземпляру внутреннего класса по ссылке.
статический внутренний класс
Статический внутренний класс , определенный внутри внешнего класса, называется статическим внутренним классом. Статические внутренние классы также называются вложенными классами, а вложенные классы относятся конкретно к статическим внутренним классам. Пример кода для создания статического внутреннего класса выглядит следующим образом:
// OuterClass.java
public class OuterClass {
private String privateField;
private static String privateStaticField;
static class StaticInnerClass {
private String privateField;
private static String privateStaticField;
}
}
При использовании статических внутренних классов обратите внимание на доступ между статическими внутренними и внешними классами. Статические внутренние классы могут напрямую обращаться к статическим членам или членам экземпляров внешних классов, а внешние классы могут напрямую обращаться к статическим членам статических внутренних классов или получать доступ к экземплярам внутреннего класса по ссылке.
локальный внутренний класс
Нестатический внутренний класс , определенный в методе внешнего класса, называется локальным внутренним классом (Local Inner Class). Пример кода для создания локального внутреннего класса выглядит следующим образом:
// OuterClass.java
public class OuterClass {
private String privateField;
private void visitLocalInnerClass() {
class LocalInnerClass {
private String privateField;
}
LocalInnerClass localInnerClass = new LocalInnerClass();
System.out.println(localInnerClass.privateField);
}
}
При использовании локальных внутренних классов вам также необходимо обратить внимание на доступ между локальными внутренними и внешними классами. Локальный внутренний класс может напрямую обращаться к статическим членам или членам экземпляра внешнего класса, но внешний класс не может получить доступ к локальному внутреннему классу вне метода (локальный внутренний класс определен внутри метода, что ограничивает вступление в силу только внутреннего класса). в этом методе).
Сценариев, где локальные внутренние классы используются напрямую (автор не видел соответствующего кода), не так много, а вместо них чаще используются лямда-выражения. Просто поймите локальные внутренние классы.
анонимный внутренний класс
В методе внешнего класса определен нестатический внутренний класс без имени класса , который называется анонимным внутренним классом (Anonymous Inner Class). Пример кода для создания анонимного внутреннего класса выглядит следующим образом:
// OuterClass.java
public class OuterClass {
private String privateField;
private void visitAnonymousInnerClass() {
Runnable runnable = new Runnable() {
private String privateField;
@Override
public void run() {
System.out.println(privateField);
}
};
}
}
При использовании анонимных внутренних классов вам также необходимо обратить внимание на доступ между анонимными внутренними и внешними классами. Анонимные внутренние классы — это особенность локальных внутренних классов, поэтому они следуют правилам локальных внутренних и внешних классов. Позвольте мне повторить здесь объяснение: анонимные внутренние классы могут напрямую обращаться к статическим членам или членам экземпляров внешних классов, но внешние классы не могут получать доступ к анонимным внутренним классам вне метода (анонимные внутренние классы определяются внутри методов, а внутренний класс ограничен метод).эффективен в). Анонимные внутренние классы можно упростить с помощью лямда-выражений.Упрощенный эффект вышеупомянутых анонимных внутренних классов заключается в следующем:
private void visitAnonymousInnerClass(String input) {
int localNumber = 0;
Runnable runnable = () -> {
System.out.println(localNumber);
System.out.println(input);
System.out.println(OuterClass.this.privateField);
OuterClass outerClass = new OuterClass();
System.out.println(outerClass.privateField);
};
runnable.run();
}
Анонимные внутренние классы подходят для сценариев локальных внутренних классов, которые используются только один раз. При создании анонимного внутреннего класса немедленно создается объект экземпляра класса. Анонимные внутренние классы нельзя использовать повторно, поскольку у них нет имени класса.
Анонимные внутренние классы — это особый случай локальных внутренних классов (анонимный означает, что компилятор автоматически присваивает имя анонимному внутреннему классу). Как и локальные внутренние классы, анонимные внутренние классы также рискуют быть заменены выражениями Lamda. Для устаревшего кода некоторые анонимные методы написания внутренних классов по-прежнему сохраняются, но для нового кода попробуйте использовать выражения Lamda.
Java-ИО
Поток — это упорядоченная последовательность данных. Программы Java выполняют ввод/вывод через потоки, и весь ввод/вывод обрабатывается в форме потоков.
Поток ввода-вывода Java является основой для реализации ввода/вывода. Он позволяет легко реализовать операции ввода/вывода данных. Различные источники ввода/вывода (клавиатура, файл, сеть и т. д.) абстрактно представлены в Java как потоки. Это упрощает обработку ввода/вывода. Поток ввода-вывода Java включает более 40 классов, как показано на рисунке ниже:
Классификация потока ввода-вывода
Потоки ввода-вывода в Java делятся по функциям: входной поток (input) и выходной поток (output). Разделяется по типу: поток байтов и поток символов.
Разница между потоком байтов и потоком символов заключается в том, что поток байтов передается в 8-битном формате, а данные вводятся и выводятся в байтах.Поток символов передается в 16-битном формате, а данные вводятся и выводятся в байтах. единицы характера.
поток байтов
Байтовый поток, основной единицей передачи данных являются байты. Байтовые данные представлены в двоичной форме. Чтобы преобразовать их в обычные символы, которые мы можем распознать, нам необходимо выбрать правильный метод кодирования. Проблема искаженного кода, с которой мы сталкиваемся в нашей жизни, вызвана неправильным выбором метода кодирования байтовых данных.
В Java 1.0 разработчик библиотеки классов сначала определил, что все классы, относящиеся к вводу, должны наследовать от InputStream, а все классы, относящиеся к выводу, должны наследовать от OutputStream. Среди них InputStream используется для представления классов, которые генерируют входные данные из разных источников данных. OutputStream определяет место назначения, куда должен идти вывод: массив байтов, файл или канал.
поток символов
Поток символов, основной единицей передачи данных являются символы. В зависимости от метода кодирования символов один и тот же символ может занимать разное количество байт. Например, символы в кодировке ASCLL занимают один байт; в то время как символы в кодировке UTF-8 требуют один байт для английского символа и три байта для китайского символа.
Java 1.1 внесла существенные изменения в базовую библиотеку потоков ввода-вывода. Обратите внимание, что Reader и Writer не предназначены для замены InputStream и OutStream. Хотя некоторые из исходных «потоковых» библиотек больше не используются (и вы получите предупреждение компилятора, если вы их используете), InputStream и OutputStream по-прежнему могут представлять большую ценность для байт-ориентированного ввода-вывода. Функции Reader и Writer предоставляют Совместимые с Unicode и символьно-ориентированные функции ввода-вывода .
Преобразование между потоком байтов и потоком символов
Хотя Java поддерживает потоки байтов и потоки символов, иногда необходимо преобразовать потоки байтов в потоки символов. InputStreamReader и OutputStreamWriter, эти два класса представляют собой классы для преобразования между потоками байтов и потоками символов. InputSreamReader используется для декодирования байтов в потоке байтов в символы. Есть два конструктора:
// 功能:用默认字符集创建一个InputStreamReader对象
InputStreamReader(InputStream in);
// 功能:接收已指定字符集名的字符串,并用该字符创建对象
InputStreamReader(InputStream in,String CharsetName);
OutputStream используется для кодирования записанных символов в байты и записи их в поток байтов. Также есть два конструктора:
// 功能:用默认字符集创建一个OutputStreamWriter对象;
OutputStreamWriter(OutputStream out);
// 功能:接收已指定字符集名的字符串,并用该字符集创建OutputStreamWrite对象
OutputStreamWriter(OutputStream out,String CharSetName);
Чтобы избежать частого преобразования потоков байтов и потоков символов, два вышеуказанных класса инкапсулированы. Класс BufferedWriter инкапсулирует класс OutputStreamWriter; класс BufferedReader инкапсулирует класс InputStreamReader; формат инкапсуляции следующий:
BufferedWriter out=new BufferedWriter(new OutputStreamWriter(System.out));
BufferedReader in= new BufferedReader(new InputStreamReader(System.in);
Разница между потоком байтов и потоком символов
(1) Потоки байтов обычно используются для обработки файлов изображений, видео, аудио, PPT, Word и других типов. Потоки символов обычно используются для обработки простых текстовых файлов, таких как файлы TXT, но не могут обрабатывать нетекстовые файлы, такие как изображения и видео. Одним предложением: потоки байтов могут обрабатывать все файлы, а потоки символов — только текстовые файлы.
(2) Сам поток байтов не имеет буфера.По сравнению с потоком байтов, буферизованный поток байтов имеет очень высокое повышение эффективности. Сам поток символов имеет буфер, и повышение эффективности буферизованного потока символов не так уж велико по сравнению с потоком символов.
BIO и NIO и AIO – модель IO
BIO: Блокирующий ввод-вывод Синхронный блокирующий ввод-вывод — это традиционный ввод-вывод, который мы обычно используем. Он характеризуется простым режимом, удобством использования и низкими возможностями одновременной обработки.
NIO: NIO был представлен в Java 1.4. Значение, данное на официальном сайте Java, — «Новый ввод-вывод», но основное внимание по-прежнему уделяется реализации неблокирующего ввода-вывода. Синхронный неблокирующий ввод-вывод — это модернизация традиционного ввода-вывода.Клиент и сервер взаимодействуют через Channel (канал), реализуя мультиплексирование .
AIO: в JDK 1.7 добавлено несколько новых API, связанных с файловым (сетевым) вводом-выводом. Эти API называются AIO (асинхронный ввод-вывод). Асинхронный ввод-вывод — это обновление NIO (улучшение синхронного неблокирующего ввода-вывода (NIO), предложенного в JDK1.4), также называемого NIO2, которое реализует асинхронный неблокирующий ввод-вывод . Операции AIO основаны на событиях и механизмах обратного вызова. .
БИО
BIO (блокирующий ввод-вывод): режим синхронной блокировки ввода-вывода, чтение и запись данных должны блокироваться в потоке, ожидающем своего завершения. Когда количество активных соединений не особенно велико (менее 1000 на одной машине), эта модель относительно хороша. Она позволяет каждому соединению сосредоточиться на своем собственном вводе-выводе и имеет простую модель программирования, не беспокоясь слишком сильно. о перегрузке системы, ограничении тока и других вопросах. Пул потоков сам по себе представляет собой естественную воронку, которая может буферизовать некоторые соединения или запросы, которые система не может обработать. Однако перед лицом сотен тысяч или даже миллионов соединений традиционная модель BIO бессильна. Следовательно, нам нужна более эффективная модель обработки ввода-вывода, чтобы справиться с более высоким уровнем параллелизма.
НИО
NIO (новый ввод-вывод): NIO — это синхронная неблокирующая модель ввода-вывода. Платформа NIO была представлена в Java 1.4 и соответствует пакету java.nio, предоставляя такие абстракции, как канал, селектор и буфер. N в NIO можно понимать как «Неблокирующий», а не просто «Новый». Он поддерживает буферно-ориентированные методы операций ввода-вывода на основе каналов. NIO предоставляет две различные реализации каналов сокетов: SocketChannel и ServerSocketChannel, которые соответствуют Socket и ServerSocket в традиционной модели BIO. Оба канала поддерживают режимы блокировки и неблокировки. Режим блокировки аналогичен традиционной поддержке, которая относительно проста, но производительность и надежность не очень хорошие; режим неблокировки — полная противоположность. Для приложений с низкой нагрузкой и низким уровнем параллелизма синхронный блокирующий ввод-вывод может использоваться для увеличения скорости разработки и улучшения удобства обслуживания; для приложений с высокой нагрузкой и высоким уровнем параллелизма (сетевых) для разработки следует использовать неблокирующий режим NIO.
АИО
AIO (асинхронный ввод-вывод): AIO — это NIO 2. Улучшенная версия NIO, NIO 2, была представлена в Java 7 и представляет собой асинхронную неблокирующую модель ввода-вывода. Асинхронный ввод-вывод реализован на основе событий и механизмов обратного вызова , то есть операция приложения вернется напрямую, не блокируясь там.Когда фоновая обработка завершится, операционная система уведомит соответствующий поток о последующих операциях. AIO — это аббревиатура асинхронного ввода-вывода. Хотя NIO предоставляет неблокирующие методы сетевых операций, поведение ввода-вывода NIO по-прежнему остается синхронным. В случае NIO наш бизнес-поток уведомляется, когда операция ввода-вывода готова, а затем этот поток выполняет операцию ввода-вывода самостоятельно. Сама операция ввода-вывода является синхронной.
Сериализация и десериализация
Сериализация — это процесс преобразования объектов Java в последовательности байтов. Во время сериализации объект Java преобразуется в поток байтов.
Десериализация — это процесс преобразования последовательности байтов обратно в объект Java. Во время десериализации последовательность байтов считывается и преобразуется обратно в исходный объект Java.
Прежде чем разобраться в прикладных сценариях сериализации и десериализации, необходимо прояснить одну вещь: сериализация и десериализация нацелены на объекты, а не на классы. Для сериализации и десериализации обычно используются следующие два сценария:
(1) постоянное сохранение последовательности байтов объекта на жестком диске, обычно в файле, то есть постоянном объекте;
(2) загрузка в сеть последовательности байтов. объекта отправляется, то есть объект сетевой передачи;
кроме того, иногда объект сохраняется в кеше для обеспечения производительности доступа.
В Java, если объект хочет быть сериализованным, он должен реализовать интерфейс Serializable или интерфейс externalizable. Интерфейс externalizable наследуется от интерфейса Serializable.Классы, реализующие интерфейс externalizable, полностью контролируют поведение сериализации самостоятельно, в то время как классы, реализующие только интерфейс Serializable, используют метод сериализации по умолчанию.
Существует множество сторонних компонентов для сериализации и десериализации. Часто используемые из них включают fastjson от Alibaba, компонент сериализации Spring по умолчанию jackson и т. д. Для реализации на основе fastjson или jackson научитесь использовать их самостоятельно.
Дополнительные примеры кода, реализующего сериализацию на основе интерфейса Serializable или реализующего сериализацию на основе интерфейса Externalizable, также можно найти в статье Сериализация и десериализация Java .
Исключение Java
Идеальное время для поиска ошибок — этап компиляции. Однако не все ошибки можно обнаружить при компиляции. Ошибки, которые не могут быть обнаружены во время компиляции, должны быть устранены во время выполнения. Для этого необходимо, чтобы источник ошибки мог каким-либо образом передать соответствующую информацию получателю — получатель знает, как правильно решить проблему.
Улучшенное восстановление ошибок — самый мощный способ обеспечить надежность кода. Java использует исключения для обеспечения согласованной модели отчетов об ошибках, позволяя компонентам надежно сообщать о проблемах с клиентским кодом.
Цель обработки исключений Java — упростить создание больших и надежных программ за счет использования небольшого объема кода и таким образом гарантировать, что в программе не будет необработанных ошибок.
Класс Throwable является базовым классом для всех классов исключений. Throwable можно разделить на два типа (ссылаясь на типы, унаследованные от Throwable): Error используется для представления ошибок времени компиляции и системы; Exception — это базовый тип, который может быть выброшен в библиотеках классов Java, пользовательских методах и ошибках во время выполнения. , Может быть выброшено исключение. Исключения можно разделить на исключения времени выполнения (RuntimeException и его подклассы) и исключения времени компиляции (исключения, отличные от исключений времени выполнения).Различия между ними заключаются в следующем:
RuntimeException: исключение, которое может возникнуть только во время выполнения программы. Обычно это логическая ошибка в коде. Например: ошибка преобразования типа, доступ к индексу массива за пределами, исключение нулевого указателя, указанный класс не может быть найден и т. д.
Исключения, отличные от исключений времени выполнения: исключения, которые можно проверить во время компиляции. Эти исключения должны быть обработаны (перехвачены или переданы вызывающей стороне) при кодировании. Если не обработаны, компиляция не пройдет. Например: IOException, FileNotFoundException и т. д.
Исключения делятся следующим образом:
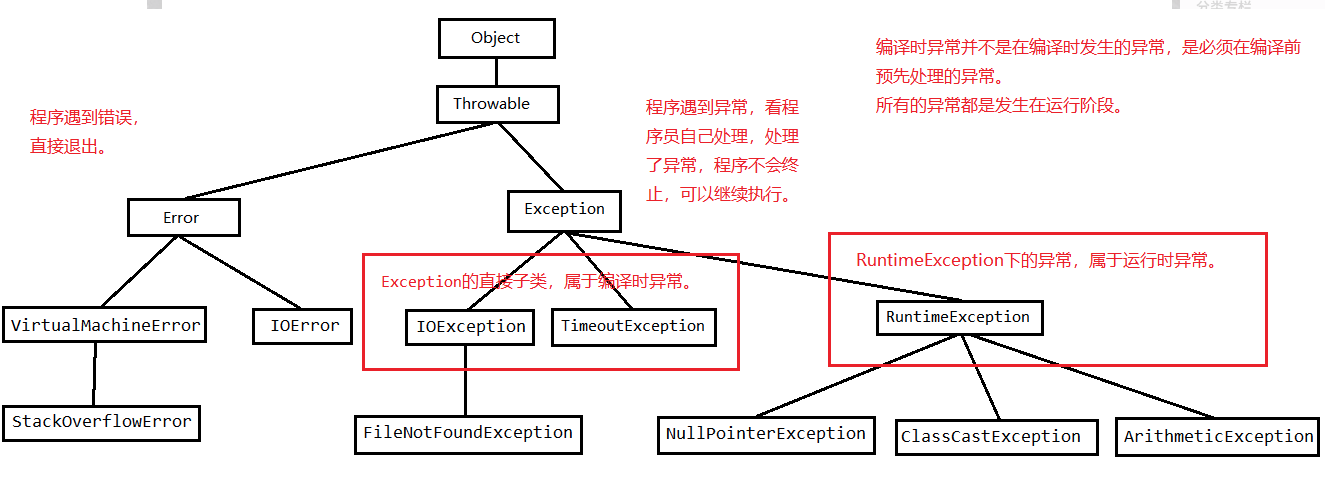
Более подробную информацию об исключениях можно найти в разделе Исключения Java .
Java-аннотации
Аннотации Java, также известные как аннотации Java, представляют собой механизм аннотаций, представленный в JDK 5.0. Это специальные синтаксические метаданные, которые можно добавлять в исходный код (так называемые метаданные — это данные, описывающие данные). Аннотации Java предоставляют формальный метод добавления информации в код , позволяющий нам очень удобно использовать эти данные (с целью использования этих данных) в определенный момент после редактирования (например, во время компиляции, во время выполнения и т. д.).
Классы, методы, переменные, параметры и пакеты на языке Java могут быть аннотированы. Аннотации могут быть встроены в байт-код, когда компилятор генерирует файл класса. В отличие от Javadoc, аннотации Java могут получать содержимое аннотаций посредством отражения . Виртуальная машина Java может сохранять содержимое аннотаций и получать их во время выполнения. Конечно, также поддерживаются пользовательские аннотации.
Роль аннотаций
Annotation — это вспомогательный класс, который широко используется в таких инструментальных средах, как Junit, Struts и Spring (аннотации широко используются в платформах). Основными функциями аннотаций являются:
(1) Проверка компиляции.
Аннотации имеют функцию «позволения компилятору выполнять проверки компиляции». Например, @SuppressWarnings, @Deprecated и @Override имеют функции проверки компиляции. Если взять @Override в качестве примера, если метод помечен @Override, это означает, что метод переопределит метод с тем же именем в родительском классе. Если метод помечен @Override, но в родительском классе нет метода с таким же именем, «отмеченного @Override», компилятор сообщит об ошибке.
(2) Используется в отражении.
В классе, методе, поле и т. д. отражения имеется множество интерфейсов, связанных с аннотациями. Это также означает, что мы можем анализировать и использовать аннотации в отражении.
(3) Создание справочных документов на основе аннотаций.
При добавлении тега @Documented к аннотации аннотации метка аннотации (аннотации могут называться метками, общие термины, такие как маркировка, относятся к использованию аннотации xxx к чему-либо) появляются в середине javadoc.
(4) Расширение функций .
Аннотации поддерживают реализацию некоторых других функций с помощью пользовательских аннотаций.
Чтобы узнать больше об аннотациях, обратитесь к статье «Аннотации Java» .
Дженерики Java
Обобщенные шаблоны Java (дженерики) — это новая функция, представленная в JDK 5. Обобщенные типы предоставляют механизм безопасного обнаружения типов во время компиляции , который позволяет программистам обнаруживать недопустимые типы во время компиляции.
Суть дженериков — параметризованный тип , что означает, что тип данных, с которым осуществляется работа, указан как параметр. Смысл дженериков — повторное использование кода . Дженерики Java реализованы с использованием принципа стирания, поэтому при использовании дженериков любая информация о конкретном типе удаляется.
Дополнительную информацию о дженериках можно найти в статье «Дженериксы Java» .
Дженерики Java реализуются с использованием стирания, что означает, что при использовании дженериков любая информация о конкретном типе будет удалена, и единственное, что вы знаете, это то, что вы используете объект в данный момент. Стирание — это операция, которая делает универсальный тип непригодным для явной ссылки на тип времени выполнения. (Метод стирания удаляет информацию о типе.)
Основная причина введения стирания — добиться преобразования необобщенного кода в обобщенный код и интегрировать дженерики в язык Java без разрушения существующей библиотеки классов. Erasure позволяет продолжать использовать существующие неуниверсальные клиенты без изменений. Это благородный мотив, потому что он не нарушит внезапно весь существующий код.
Код стирания имеет важное значение. Универсальные шаблоны Java нельзя использовать в операциях, которые явно ссылаются на типы времени выполнения, таких как преобразования, операции экземпляра и новые выражения .
Erasure теряет возможность выполнять определенные операции в общем коде. Любая операция, требующая знания точной информации о типе во время выполнения, не будет работать. В этой ситуации стирание можно компенсировать введением тегов типа. Это означает, что объект класса типа должен быть передан явно, чтобы использовать его в выражении типа.
Дополнительную информацию о дженериках можно найти в статье «Дженериксы Java» .
Java-отражение
Концепция отражения была впервые предложена Б.С. Смитом в 1982 году (Процедурное отражение в языках программирования).Она в основном относится к способности программы получать доступ, обнаруживать и изменять свое собственное состояние или поведение.
Java-отражение означает, что в рабочем состоянии для любого класса вы можете знать все свойства и методы этого класса; для любого объекта вы можете вызывать любые его методы и свойства и изменять значения его свойств.
Отражение — это реализация информации о типе времени выполнения (RTTI). Информация о типе во время выполнения позволяет разработчикам программ обнаруживать и использовать информацию о типе во время работы программы.
Основные шаги использования отражения следующие:
(1) Получить объект класса данного типа;
(2) Получить метаданные типа на основе объекта класса: тип конструктора, тип поля, тип метода;
(3) получить доступ к членам на основе Тип конструктора, Тип поля, Тип метода.
Java предоставляет типы классов, типы конструкторов, типы полей и типы методов, которые помогают реализовать доступ во время выполнения к членам экземпляров типов. При получении членов необходимо выбирать различные методы в соответствии с правами доступа члена и позицией объявления, которые можно разделить на две категории:
getXxx получает общедоступный конструктор, поле и метод, включая родительский класс .
getDeclaredXxx Получает все конструкторы, поля и методы текущего класса, которые содержат разрешения частного доступа .
Дополнительную информацию об отражении Java см. в разделах «Обзор отражения Java» и «Отражение Java — практическая глава» .
Динамический прокси Java
Суть динамического прокси — отражение. Существует два распространенных метода реализации динамического прокси: динамический прокси JDK и динамический прокси CGLIB. Прокси-класс ($Proxy0 расширяет Proxy реализует XXX), созданный с помощью технологии динамического прокси JDK, наследует класс Proxy, поэтому динамические прокси-классы JDK не могут реализовать динамическое проксирование классов. Если вам нужно реализовать динамический прокси для класса, вы можете использовать технологию CGlib.
Дополнительную информацию о динамических агентах можно найти в статье Обзор динамических агентов .
ссылка
«Мысли о программировании на Java» (четвертое издание) Брюс Экель [Переведено] Чен Хаопенг
https://github.com/JetBrains/jdk8u_hotspot/blob/master/src/share/vm/runtime/synchronizer.cpp#L560 реализация хэш-кода
https:/ /blog.csdn.net/changrj6/article/details/100043822 Анализ исходного кода Java Object.hashCode()
https://www.sitepoint.com/how-to-implement-javas-hashcode-correctly/hashcode http
:// www.codeceo.com/article/java-hashcode-implement.html Как правильно реализовать метод hashCode в Java
https://www.cnblogs.com/dolphin0520/p/3780005.html Углубленный анализ упаковки и распаковки в Java
https://blog.csdn.net/rmn190/article/details/1492013 Сравнение String, StringBuffer и StringBuilder
https://www.runoob.com/w3cnote/java-dependent-of-string-stringbuffer-stringbuilder.html String, StringBuffer с StringBuilder
https://www.jianshu.com/p/aa4242253645 Оптимизация производительности сращивания строк
https://www.apiref.com/java11-zh/java.base/java/lang/invoke/StringConcatFactory.html Класс StringConcatFactory
https://medium.com/javarevisited/java-compiler-optimization-for-string-concatenation-7f5237e5e6ed Оптимизация компилятора Java для конкатенации строк
https://www.runoob.com/java/java-array.html Java Array
https: //cloud.tencent.com/developer/article/1860151 Определение и использование массивов Java
https://www.jianshu.com/p/cd7a73e6bd78 Подробное объяснение Java CopyOnWriteArrayList
https://zhuanlan.zhihu.com/ p/59601301 Анализ исходного кода CopyOnWriteArrayList
https://blog.jrwang.me/2016/java-collections-deque-arraydeque/
https://www.jianshu.com/p/2f633feda6fb Анализ исходного кода Java-контейнера Deque и ArrayDeque
https ://www.cnblogs.com/msymm/p/9873551.html Подробное введение в вектор Java
https://www.cnblogs.com/skywang12345/p/3308556.html Серия коллекций Java 03 — подробное введение в ArrayList (анализ исходного кода) ) и примеры использования
https://www.cnblogs.com/skywang12345/p/3308807.html Java Collection Series 05 — подробное введение в LinkedList (анализ исходного кода) и примеры использования
Исходный код JDK 1.8
https://www.jianshu.com /p/2dcff3634326 Коллекция Java – полный анализ TreeMap
https://www.cnblogs.com/skywang12345/p/3310928.html#a2 Коллекция Java, серия 12 TreeMap, подробное введение (анализ исходного кода) и примеры использования
https://zhuanlan .zhihu.com/p/21673805 Серия Java 8. Новое понимание HashMap
https://www.lifengdi.com/archives/article/1198#ConcurrentHashMap_ji_cheng_guan_xi Анализ исходного кода общего метода ConcurrentHashMap (jdk1.8)
https://www.cnblogs .com/xiaoxi/p/6170590.html Коллекция Java LinkedHashMap
https://blog.csdn.net/justloveyou_/article/details/71713781 Краткое описание карты (2): Тщательное понимание LinkedHashMap
https://blog.csdn.net/sinat_36246371 /article/details/53366104 HashSet в Java
https://blog.csdn.net/educast/article/details/77102360Блокировка очереди BlockingQueue и блокировка двусторонней очереди BlockingDeque
https://www.cnblogs.com/bjxq-cs88/p/9759571.htmlArctic Planet of the Apes
Блокирующая очередь Java-BlockingQueue
https://my.oschina.net/wangzhenchao/blog/4566195Углубленное понимание JUC: SynchronousQueue
https://www.jianshu.com/p/d5e2e3513ba3 SynchronousQueue
https://blog.csdn.net/devnn/article/details/82716447 Подробное объяснение использования двусторонней очереди Java Deque
https://blog.csdn .net/ryo1060732496/article/details/88890075 Двусторонняя очередь ConcurrentLinkedDeque
https://www.jianshu.com/p/231caf90f30b Подробное объяснение Concurrent-Container-ConcurrentLinkedQueue
https://blog.csdn.net/hanchao5272/article/details/ 79947785 Неблокирующая двусторонняя неограниченная очередь на основе алгоритма CAS Queue ConcurrentLinkedDueue
https://blog.csdn.net/zxc123e/article/details/51841034 Двусторонняя блокирующая очередь (BlockingDeque)
https://blog.csdn.net/qq_38293564 /article/details/80592429 Подробное объяснение очереди блокировки LinkedBlockingDeque
https://www.w3schools.cn/java/java_inner_classes.asp Внутренние классы Java (вложенные классы)
https://blog.csdn.net/liuxiao723846/article/details/ 108006609 Внутренние классы Java
https://blog.csdn.net/xiaojin21cen/article/details/104532199 Статический внутренний класс режима Singleton
https://www.joshua317.com/article/212 Внутренний класс Java
https://www.runoob. com/java/java-inner-class.html Внутренние классы Java
https://developer.aliyun.com/article/726774 Углубленное понимание внутренних классов Java
https://www.cnblogs.com/shenjianeng/p/6409311 .html Краткое описание использования внутренних классов Java
https://blog.csdn .net/liuxiao723846/article/details/108006609 Внутренние классы Java
https://segmentfault.com/a/1190000023832584 Введение в использование внутренних классов JAVA
https ://www.zhihu.com/tardis/bd/ans/672095170?source_id= 1001 Что такое сериализация и десериализация в Java?
https://blog.csdn.net/qq_44543508/article/details/103232007 Подробное объяснение ключевого слова transient в Java
https://www.baidu.com/Baidu AI-поиск
https://www.cnblogs.com/lqmblog/ p /8530108.html Простое понимание сериализации и десериализации
https://www.cnblogs.com/huhx/p/5303024.html Основы Java ----> Использование Serializable
https://www.cnblogs.com/ huhx/ p/sSerializableTheory.html Java Advanced ----> Анализ сериализуемых процессов