

«Нужна ли мне обычная база данных SQL в дополнение к векторной базе данных?»
Это вопрос, который нам часто задают. Если помимо векторных данных у пользователей есть другая информация о скалярных данных, их бизнесу может потребоваться выполнить поиск семантического сходства (https://zilliz.com.cn/glossary/%E8%AF%AD%E4%B9%89 %E6). %90%9C%E7%B4%A2-%EF%BC%88semantic-search%EF%BC%89) сначала фильтруйте данные по определенным условиям, например:
В юридической сфере может возникнуть необходимость поиска соответствующих юридических терминов только в конкретной базе данных;
В розничной торговле вам может понадобиться поискать мужскую обувь определенного размера;
При поиске изображений вы можете искать постеры к фильмам, выпущенным в период с 2010 по 2016 год и имеющим рейтинг фильмов на IMDB выше 7,0.
На это наш ответ – нет. С векторной базой данных Milvus или полностью управляемым сервисом Milvus — Zilliz Cloud нет необходимости поддерживать дополнительную базу данных SQL для хранения скаляров. Используя всего одну систему, пользователи могут отправлять гибридные запросы, реализующие «векторный поиск + скалярную фильтрацию», для получения более точных результатов поиска.
Среди них Milvus (https://zilliz.com/what-is-milvus) позволяет пользователям выполнять условную фильтрацию на основе скалярных данных при выполнении векторного поиска.Атрибутами данных могут быть любые поля, кроме векторов. Milvus создаст векторный индекс для векторного поля и проведет поиск по сходству векторов, а также может выполнять фильтрацию метаданных результатов поиска через выражения. Просто введите выражение фильтра при поиске, и Milvus автоматически сделает за вас и то, и другое.
В этом руководстве используются Zilliz Cloud Pipelines (https://zilliz.com/zilliz-cloud-pipelines) — встроенная функция Zilliz Cloud для кодирования неструктурированных данных в векторы внедрения с поддержкой прямого текста и выражений фильтра. Вектор поиска. Мы продемонстрируем, как использовать скалярную фильтрацию для вызова только тех фрагментов документа, которые соответствуют определенным критериям, например, определенному URL-адресу источника или определенному имени файла. Вы также можете использовать аналогичные идеи для вызова документов с определенными тегами, такими как год публикации, номер версии и т. д.
Демонстрация Zilliz Cloud Pipelines
01.
Создание коллекций и конвейеров
Для этого руководства требуется бесплатная версия Zilliz Cloud (международная версия). Zilliz Cloud — это полностью управляемый сервис Milvus, который развертывает базу данных пользователя на бессерверном облачном сервере, но мы по-прежнему можем использовать векторную базу данных Zilliz Cloud локально, вызвав интерфейс API PyMiluvs.Следующий текст, используемый для тестирования, взят из документации PyMilvus.
1. Откройте https://cloud.zilliz.com/ и создайте кластер версий «Начальная».

2. Добавьте имя коллекции и нажмите «Создать коллекцию и кластер».
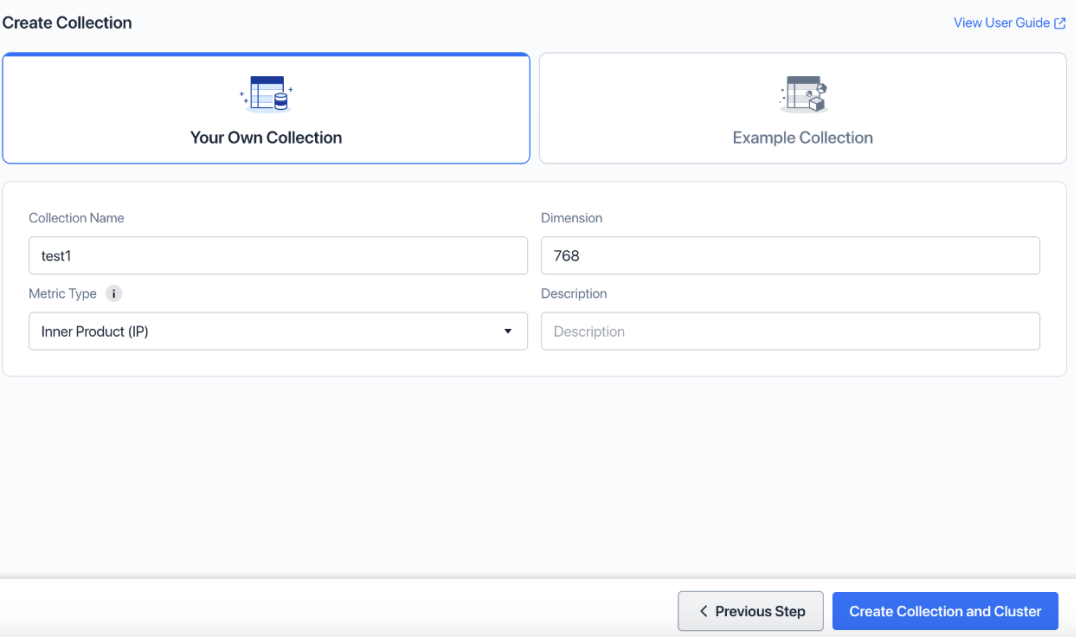
По умолчанию при создании кластера Zilliz Cloud создается 1 коллекция, которая не будет использоваться в этом руководстве. Когда мы позже создадим Zilliz Cloud Pipelines, автоматически будет создана еще одна коллекция. Обратите внимание, что эти две коллекции не одинаковы.
3. Нажмите «Конвейеры» на левой панели навигации, следуйте подсказкам интерфейса, чтобы создать конвейеры и загрузить данные:
А. Сначала выберите «Конвейер приема».
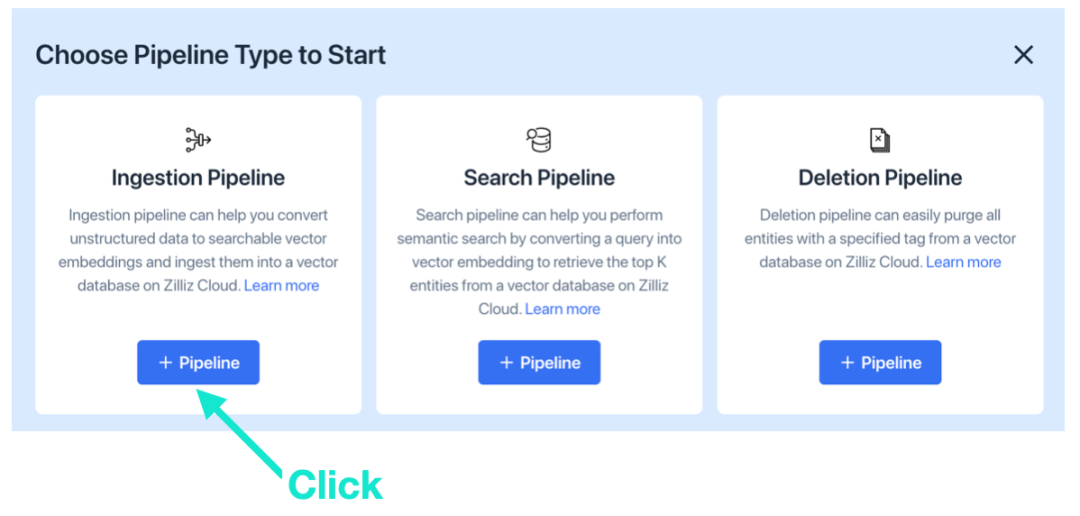
Б. Выберите только что созданный бессерверный кластер, введите имена коллекции и конвейера соответственно и нажмите «Добавить функцию».
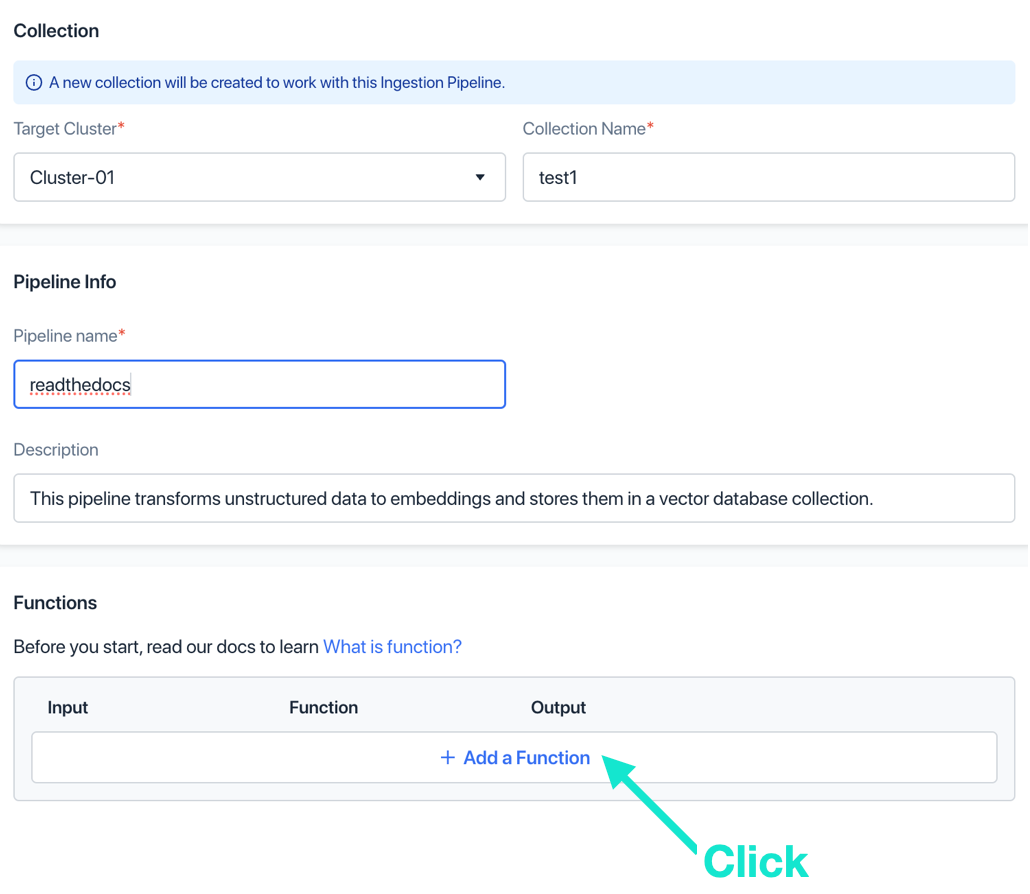
в. Выберите функцию INDEX_DOC, введите имя функции, оставьте остальные значения параметров по умолчанию и нажмите «Добавить». Эта функция разрежет документ на векторы.
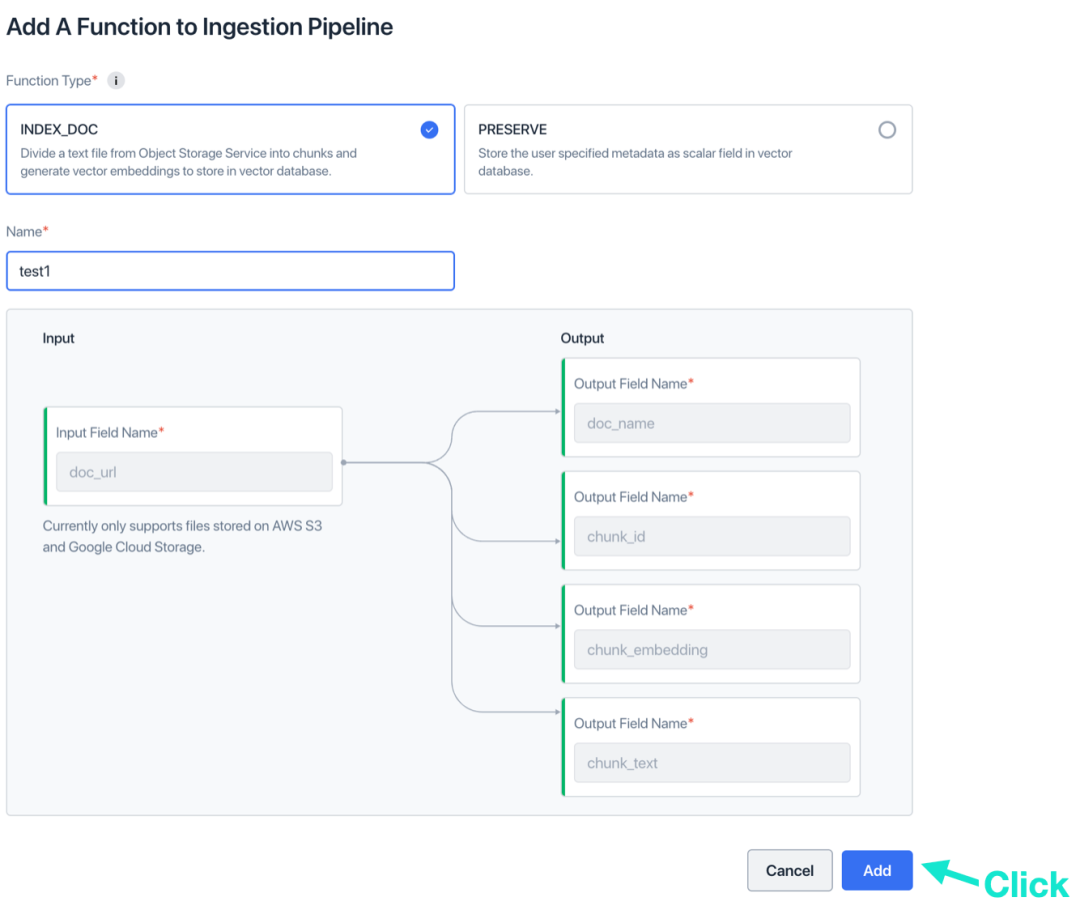
г. (Необязательно) Еще раз нажмите «Добавить функцию».
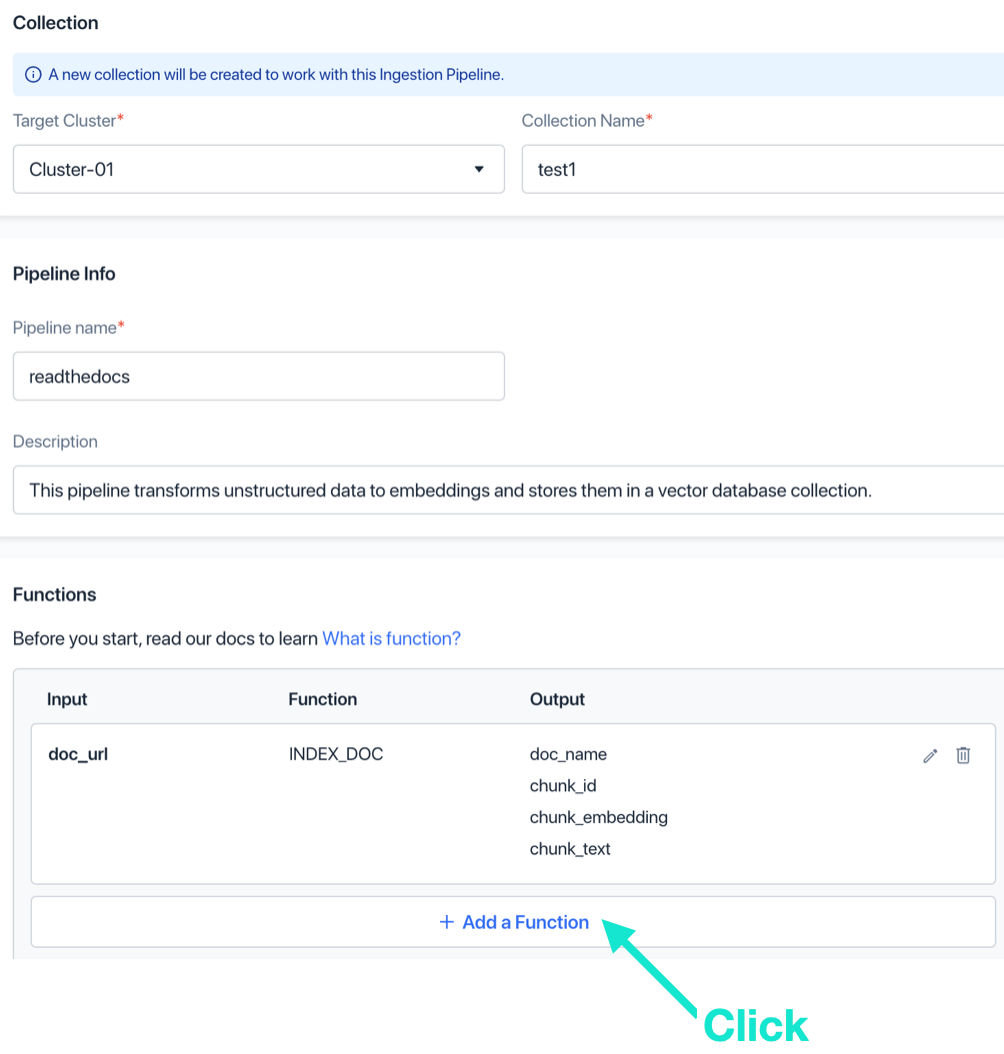
д. (Необязательно) Выберите функцию СОХРАНИТЬ, назовите ее и нажмите «Добавить». Эта функция используется для сохранения информации тега документа.

4. Нажмите «Создать конвейер приема». Теперь мы закончили создание конвейера приема и коллекции.
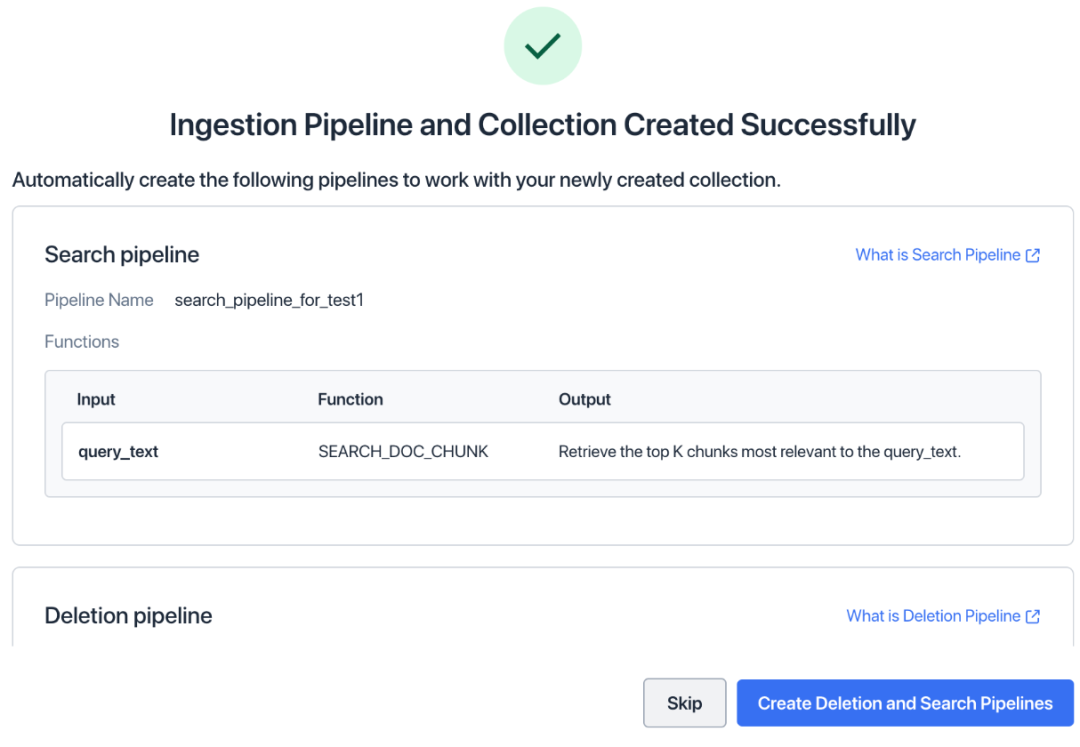
5. Нажмите «Создать конвейер удаления и поиска».
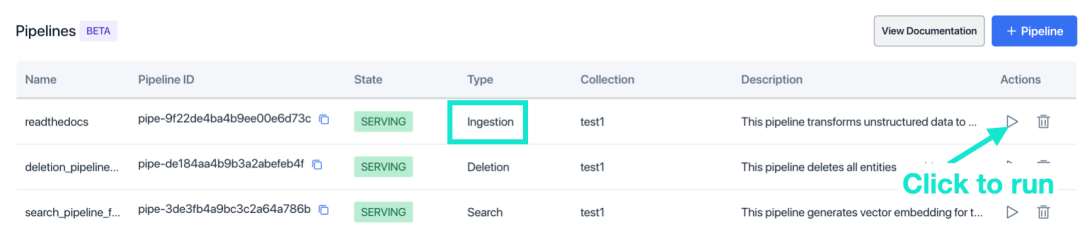
6. Войдите на страницу списка конвейеров и нажмите кнопку «▶️», чтобы запустить конвейер приема.
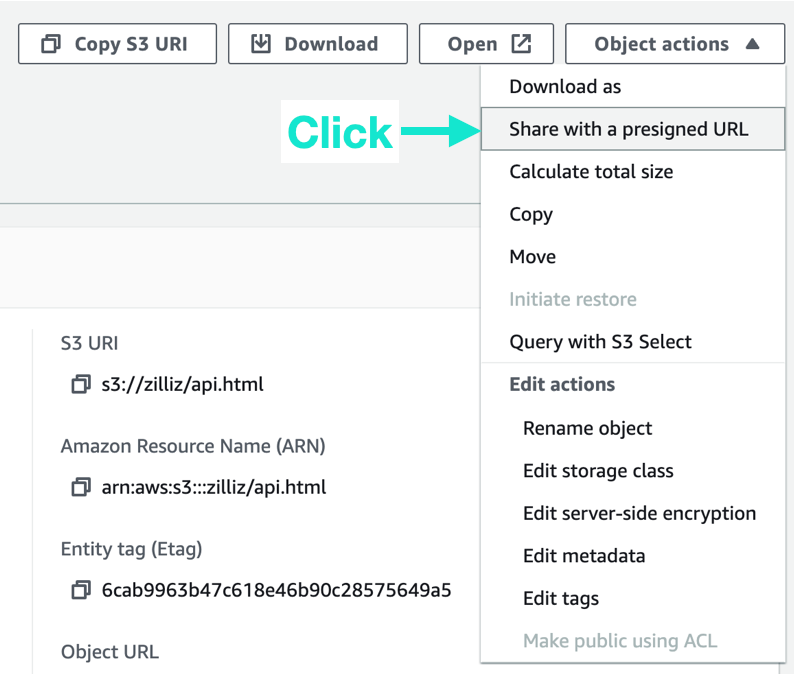
7. Ingestion Pipeline поддерживает загрузку ваших файлов в объектное хранилище (например, AWS S3 и Google Cloud Storage). В этом примере мы загружаем данные в AWS S3. После завершения загрузки нажмите «Поделиться через предварительно подписанный URL-адрес». Скопируйте ссылку для общего доступа (предварительно подписанный URL-адрес). Если объектное хранилище отсутствует, вы можете использовать ссылку на тестовый файл https://publicdataset.zillizcloud.com/milvus_doc.md , предоставленную нами в качестве предварительно подписанного URL-адреса.
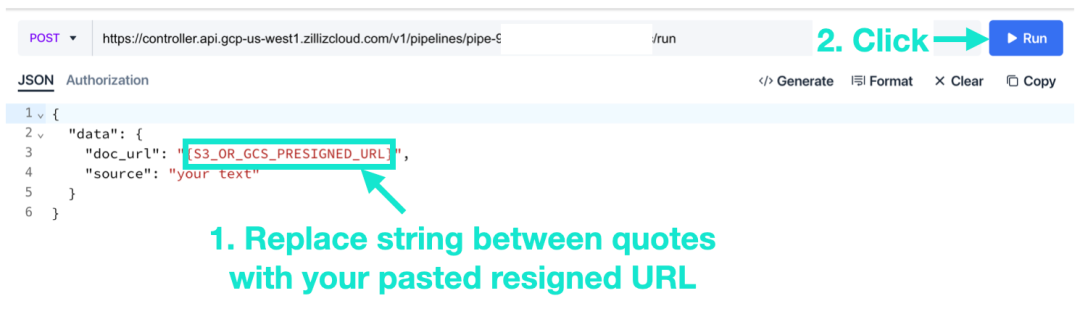
8. Вставьте предварительно подписанный URL-адрес в код и нажмите «Выполнить». На этом этапе файл будет фрагментирован для извлечения векторов и импортирования их в коллекцию базы данных векторов.
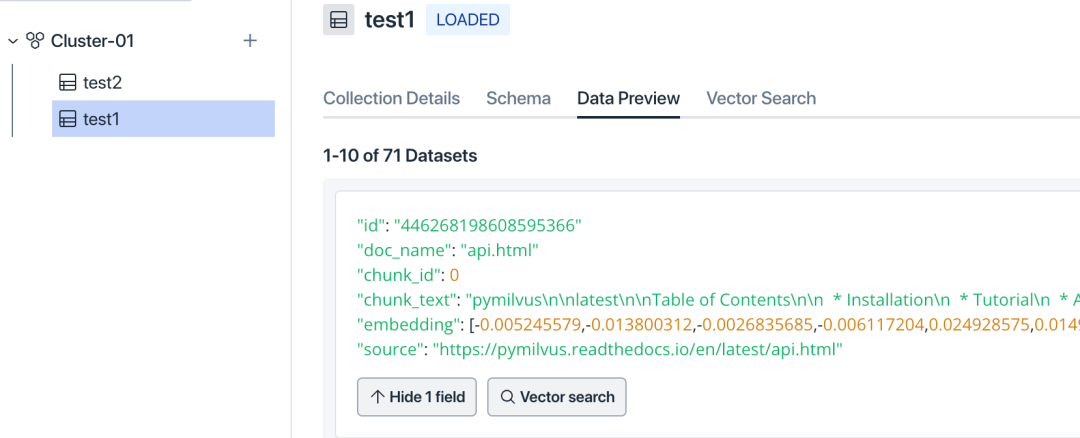
9. Войдите на страницу коллекции и проверьте правильность коллекции и схемы. На этом этапе векторы для фрагментов документа уже должны отображаться в окне предварительного просмотра данных.
После этого данные можно запросить через интерфейс Playground или вызвав API.
02.
Вызов векторов, соответствующих определенной метке, со скалярной фильтрацией
1. Найдите «Поиск конвейера» в списке конвейеров и нажмите кнопку «▶️» справа, чтобы запустить конвейер поиска.
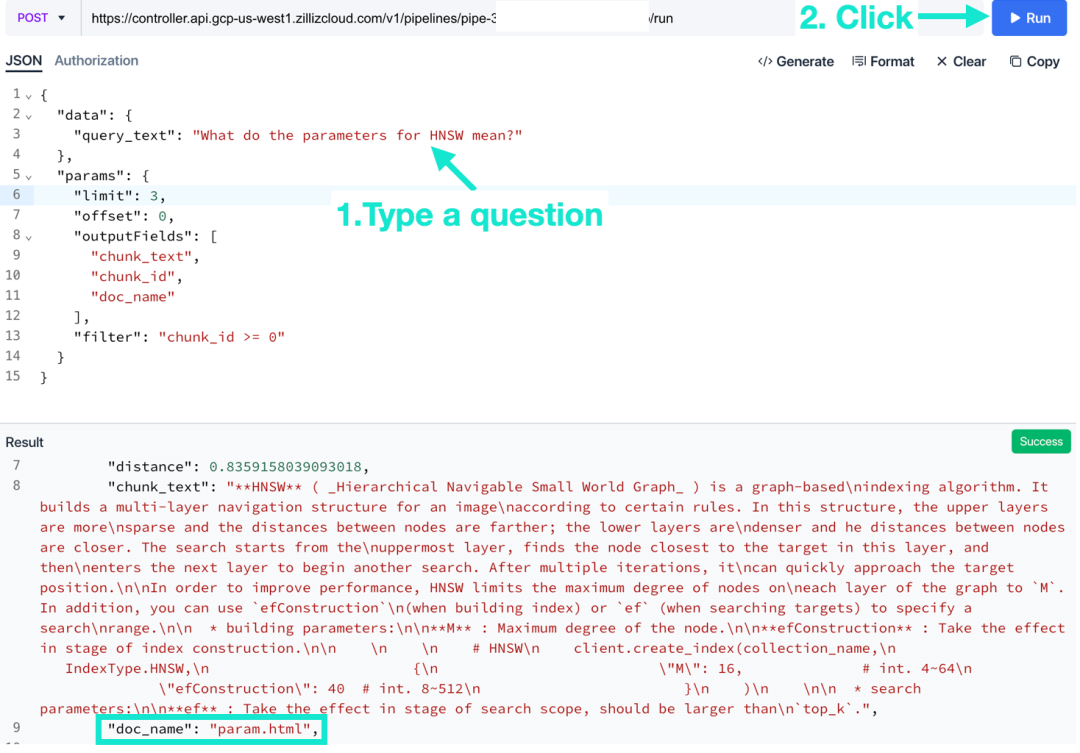
2. В запросе введите вопрос и нажмите «Выполнить».
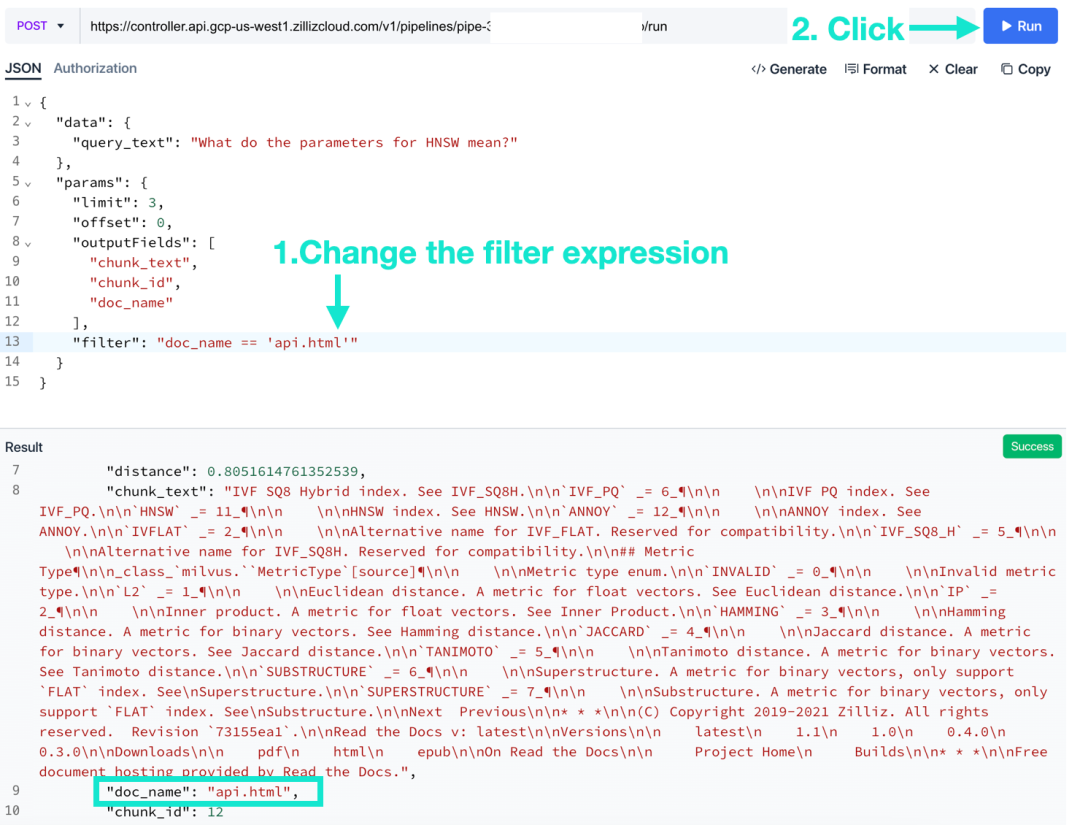
3. Отредактируйте «Условия фильтра». Пожалуйста, используйте логические выражения. После нажатия кнопки «Выполнить» вы увидите, что Zilliz Cloud отфильтровал результаты поиска на основе введенных вами условий.
Фильтровать метаданные с помощью Zilliz Cloud Pipelines — это так просто! Вы можете выполнить условную фильтрацию для всех скалярных полей, кроме векторных, с помощью логических выражений (https://zilliz.com/zilliz-cloud-free-tier).
03.
Поиск через интерфейс API
Аналогичным образом мы также можем выполнить поиск, вызвав интерфейс API.При использовании API пользователь должен указать следующие два момента:
API-токен Zilliz
Идентификатор конвейера
Мы можем получить токен API на странице сведений о кластере.
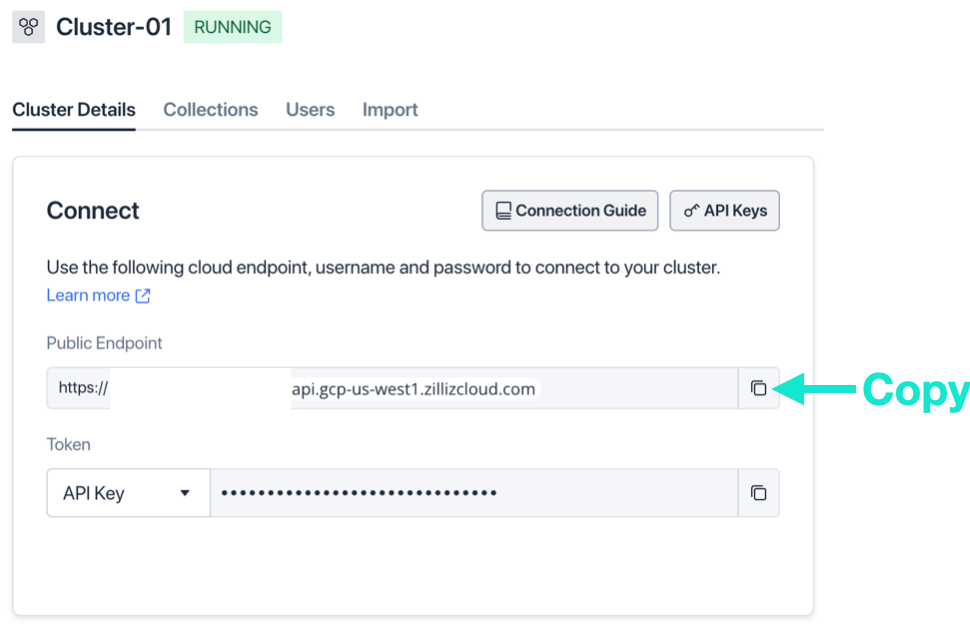
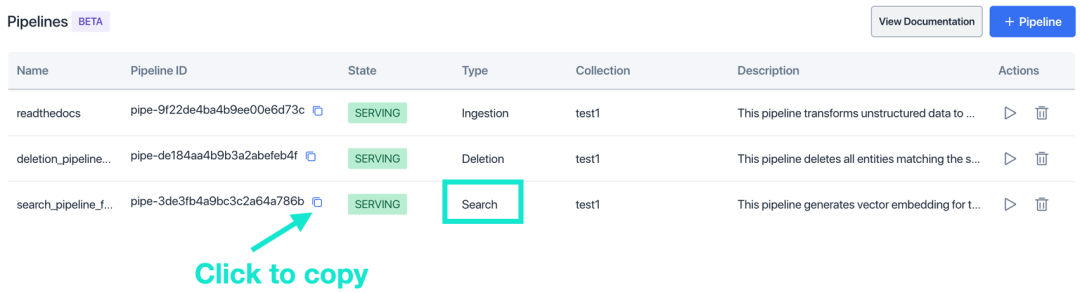
Чтобы получить идентификатор конвейера, сначала найдите конвейер поиска на странице списка конвейеров, а затем скопируйте идентификатор конвейера в столбец «Идентификатор конвейера». Вставьте идентификатор конвейера в URL-адрес при вызове интерфейса API.
import requests, json
url = "https://controller.api.gcp-us-west1.zillizcloud.com/v1/pipelines/pipe-xxxx/run"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {TOKEN}",
}
data = {
"data": {
"query_text": SAMPLE_QUESTION
},
"params": {
"limit": TOP_K,
"offset": 0,
# Any of these fields can be used in filter expression.
"outputFields": ["chunk_text", "chunk_id", "doc_name", "source"],
"filter": "doc_name == 'param.html'"
}
}
# Send the POST request
response = requests.post(url, headers=headers, json=data)
用 API 进行元数据过滤搜索就是这么简单!如果大家有兴趣了解更多 Zilliz Cloud Pipelines 的使用方法,可以参考 Notebook(https://github.com/milvus-io/bootcamp/blob/master/bootcamp/RAG/zilliz_pipeline_rag_advanced.ipynb) 用 Pipelines 搭建一个有标签过滤功能的 RAG 问答机器人,欢迎上手尝试。



本文分享自微信公众号 - ZILLIZ(Zilliztech)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。