
Вопрос о том, должна ли бизнес-система типа OLTP использовать централизованную базу данных или распределенную базу данных, часто задается при преобразовании отечественных баз данных: для развития и развития технической архитектуры или для обеспечения необходимой поддержки в долгосрочной перспективе. В перспективе развития действующего бизнеса этот вопрос имеет дискуссионное значение. В контексте распределенной архитектуры кажется, что любая архитектура нуждается в распределенных возможностях. Так ли это на самом деле? Подробный анализ и пояснения будут приведены ниже.
Автор: Ван Хуэй
Статья взята из публичного аккаунта WeChat «Basic Technology Research».
1. Анализ текущего использования
В 2022 году отечественных производителей баз данных будет более 200. Традиционными централизованными базами данных являются в основном Renmin Jincang и Dameng. Существуют также новые базы данных, такие как PolarDB. Распределенные базы данных включают GaussDB, Kingwow, TDSQL, GoldenDB и OceanBase и т. д. Фактически, большинство из этих баз данных есть два режима развертывания: централизованный и распределенный.То есть деньги, которые вы тратите на распределенные базы данных, также могут быть использованы для централизованного развертывания, которое может удовлетворить различные потребности вашего бизнеса.
Здесь следует отметить, что некоторые поставщики распределенных баз данных используют централизованное развертывание, и приложениям по-прежнему необходимо подключаться к вычислительным узлам. Подключите следующие узлы данных через вычислительный узел (CN). Это может быть связано с соображениями унифицированной архитектуры, а также с тем, что вычислительный узел может воспринимать автоматическое переключение и быть прозрачным для приложения, когда база данных переключается между активным и резервным режимами. Однако это непреднамеренно добавляет уровень анализа, что приведет к определенной потере производительности. Некоторые поставщики баз данных напрямую подключаются к базе данных через свои собственные драйверы JDBC/ODBC или VIP, что позволяет избежать подобных проблем.
С точки зрения технической архитектуры базы данных, используемые в финансовой отрасли, по-прежнему в основном централизованы, а распределенные базы данных составляют прочное дополнение в средних и крупных финансовых учреждениях. Данные исследования из «Отчета о развитии безопасности цепочки поставок баз данных финансовой отрасли (2022 г.)» показывают, что на централизованные базы данных по-прежнему приходится 89% всей финансовой отрасли, из которых 80% составляют банки, а на отрасли ценных бумаг и страхования приходится более 90%. % Централизованные базы данных играют важную роль в процессе цифровизации финансовых технологий. Общая доля распределенных баз данных в финансовой отрасли достигает 7%, в банковской сфере превышает 17%, а в отраслях ценных бумаг и страхования относительно низка. Другими словами, для большей части нашего бизнеса вполне удовлетворительно использовать централизованную базу данных.
2. Действительно ли необходимо распространение?
Поскольку централизованная база данных имеет только один основной узел данных, она, естественно, имеет такие преимущества, как простая архитектура, удобство эксплуатации и обслуживания, хорошая совместимость и высокая стоимость.
Однако существуют и такие проблемы, как неспособность преодолеть аппаратные ограничения одной машины, невозможность горизонтального расширения, а также существование узких мест в производительности и емкости.
Поэтому, когда централизованная база данных не может удовлетворить наши требования к производительности и емкости, распределенная база данных предоставляет нам хорошие технические средства. Когда мы планируем выбрать распределенную систему для решения централизованных задач, перед ее рассмотрением рекомендуется задать следующие вопросы:
- Можно ли решить проблему путем оптимизации самой централизованной базы данных без внесения серьезных архитектурных изменений, таких как оптимизация параметров, оптимизация операторов SQL, оптимизация бизнес-логики и т. д.
- Можно ли решить проблему, увеличив конфигурацию ресурсов хоста, например, увеличив размер ЦП и памяти, или используя метод вертикального расширения, например переключение с виртуальной машины на физическую машину?
- Можно ли решить проблему путем разделения хранилища и вычислений? Если емкость одной машины не может соответствовать требованиям, вы можете рассмотреть возможность использования подключаемого хранилища или принять архитектуру разделения хранилища и вычислений, чтобы решить проблему ограниченной емкости диска одной машины. .
- Можно ли решить эту проблему на уровне приложений, например, изменив бизнес-архитектуру и внедрив микросервисы или унифицированную архитектуру, то есть добиться разделения данных, распределенных транзакций и возможностей горизонтального расширения на уровне приложений, в то время как база данных все еще централизована? Этот метод предъявляет высокие требования к разработчикам и высокие затраты на трансформацию бизнеса, которые необходимо рассматривать комплексно.
- Полностью ли вы понимаете преимущества и недостатки распределенной архитектуры, подготовились ли вы к эксплуатации, обслуживанию и резервному копированию распределенных баз данных и полностью ли вы считаете, что ваш бизнес должен решаться через распределенные базы данных.
3. Когда использовать распределенный?
Раньше существовала поговорка, что таблицу с 20 миллионами строк необходимо разделить, главным образом для базы данных MySQL. Когда таблица типов OLTP превышает 2000 Вт строк, количество конечных слоев B+дерева будет увеличено до 4 посредством расчета по формуле, тем самым увеличивая количество операций ввода-вывода. Однако при обновлении оборудования или внедрении технологии кэширования влияние ввода-вывода можно практически игнорировать. Поэтому в настоящее время принято использовать индикаторы TPS или QPS, чтобы определить, необходимо ли распределенное преобразование, например, когда узкое место TPS в одной точке достигает 4000, QPS достигает 8 Вт или объем данных достигает 2 ТБ. В обычных обстоятельствах горизонтальное расширение требуется для устранения узких мест в производительности или емкости, что относительно разумно. Однако здесь не существует фиксированной формулы. В основном необходимо принимать решения на основе собственных бизнес-сценариев. Мы также должны учитывать потребности будущего роста бизнеса, например, сможет ли он удовлетворить потребности роста бизнеса через 3-5 лет, делать прогнозы пиковых значений и заранее планировать, чтобы избежать вторичной трансформации. В то же время обратитесь к нескольким упомянутым выше проблемам, чтобы понять, нужно ли их решать с помощью распределенной базы данных.
Экспериментальные данные один (нахождение точки перегиба)
Аппаратный ресурс — среда виртуальной машины Kunpeng на базе архитектуры ARM. Конкретная конфигурация — 16C64G. Победившей заявкой является операционная система Kirin v10 и обычный SSD-диск.
На рисунке ниже показаны результаты тестирования отечественной распределенной базы данных.Распределение — 4 шарда, единица измерения: секунды.

Для одноточечных запросов на основе индекса пробела практически нет. Для полного сканирования таблицы и ассоциаций двух таблиц (связанные таблицы равномерно содержат 2 миллиона строк и основаны на сегментных ключах в качестве условий ассоциации) это число уже примерно в 5 раз. когда объем данных составляет 5 миллионов. Произошло значительное улучшение. Честно говоря, я повернул этот угол немного раньше. На самом деле, для большей точности это еще нужно проверить на основе ваших собственных бизнес-сценариев.
Для объемов данных менее 5 миллионов вы можете проверить это самостоятельно на основе вашего бизнеса. Конечно, может быть точка перегиба при 300 Вт или ниже. Надеюсь, вы сможете привести здесь дополнительные результаты испытаний. Экспериментальные данные могут иметь определенные отклонения из-за различных факторов. Пожалуйста, поправьте меня. Мы также надеемся, что каждый сможет разместить результаты своих тестов в области комментариев, чтобы каждый мог проверить точки перегиба производительности распределенных и централизованных систем. Это может дать более подробную информацию. Точная База данных служит ориентиром для выбора.
Экспериментальные данные два
Изображение ниже — результат стресс-теста производителя на основе инструмента sysbench:

Видно, что когда использование ресурсов централизованной базы данных достигает 75% в конфигурации среднего размера, максимальное значение TPS, которого можно достичь, составляет 4595, задержка — 5 мс, а параллелизм — 400. Это ориентировочное значение, которое является основой для разделения упомянутого выше базового TPS, если оно превышает 5000. Конечно, если ваши ресурсы достаточно велики, это значение может быть больше. Но точнее всего нам необходимо проверить значение TPS посредством стресс-тестирования в реальной среде для принятия суждений.
4. Как эффективно использовать распределенные
Как следует из названия, он распределен, в нем работают несколько человек, и он обладает такими преимуществами, как высокая доступность, высокая масштабируемость, высокая производительность и возможности гибкого расширения и сжатия.
По мере увеличения количества узлов данных и компонентов базы данных неизбежно возникнут такие проблемы, как сложная архитектура, сложная эксплуатация и обслуживание, а также высокие затраты.В то же время большинство распределенных баз данных не поддерживают специальные объекты, такие как хранимые процедуры и пользовательские функции.
Распространение — это палка о двух концах, и очень важно то, как мы правильно его используем, не причиняя вреда.
1. Выбор шард-ключа
Выбор ключа шардирования очень важен: значение поля, выбранного в качестве ключа шардирования, должно быть относительно дискретным, чтобы данные могли быть равномерно распределены на каждом узле данных. Если одно поле не может удовлетворять дискретным условиям, вы можете рассмотреть возможность использования нескольких полей вместе в качестве ключей сегментирования. В общем, вы можете рассмотреть возможность выбора первичного ключа таблицы в качестве ключа сегментирования. Например, выберите идентификационный номер в качестве ключа распределения в таблице сведений о персонале. И большинство распределенных баз данных не поддерживают и не рекомендуют модифицировать ключи сегментов.
2. Выбор способа распространения
Распространенным выбором является распределение хеша, которое распределяется относительно более равномерно.Есть также разделы, такие как диапазон и список.Конечно, в конечном итоге нам нужно сделать выбор на основе конкретных бизнес-сценариев. Кроме того, некоторые часто используемые таблицы с информацией о конфигурации или небольшие таблицы для связанных запросов необходимо определить как глобальные таблицы, чтобы обеспечить возможность их получения на одном узле данных и избежать взаимодействия данных между узлами.
3. Стандартизируйте написание операторов SQL.
Ключ сегментирования следует выбрать в качестве условия запроса, а ключ сегментирования следует использовать в качестве условия запроса ассоциации нескольких таблиц. Если ключи сегментирования не используются, произойдет передача данных между узлами. Некоторые распределенные базы данных объединяют все данные в вычислительные узлы для сводной и корреляционной сортировки. Когда данные большие, ресурсы вычислительных узлов будут заполнены мгновенно, что приведет к сбою базы данных. быть не в состоянии быть предоставленным внешнему миру.
4. Избегайте передачи данных между узлами
Как упоминалось выше, использование условий запроса в качестве ключей сегментирования позволяет в наибольшей степени избежать передачи данных между узлами. Поскольку передача данных между узлами основана на сети, существует большой разрыв в производительности передачи, чтения и записи в сети. по сравнению с диском, поэтому производительность будет очевидно снижаться, и могут даже возникнуть ситуации, когда результаты никогда не появятся.
5. Избегайте распределенных транзакций
Распределенная обработка транзакций имеет длинный путь.Это определяется ее природой.Большинство баз данных реализованы по принципу 2PC.Поэтому мы должны в наибольшей степени избегать распределенных транзакций.Как правило, они должны контролироваться в пределах 10% всех транзакций. Слишком большое количество распределенных транзакций определенно повлияет на нашу производительность, а также создаст проблемы с согласованностью бизнес-данных.
5. Углубленный анализ: является ли распространение решением для базы данных или прикладным решением?
Распределенная реализация может быть решена с помощью баз данных (распределенные базы данных) или с помощью приложений. Большинство разработчиков, особенно финансовые учреждения, такие как традиционные отрасли или городские коммерческие банки, имеют меньшие возможности разработки, чем крупные банки, и ограниченный штат сотрудников. Они предпочитают, чтобы база данных делала больше вещей, такие как реализация распределенных транзакций и разделение данных, и максимально прозрачны для разработчиков. Поэтому они будут напрямую использовать распределенные базы данных, взяв в качестве примера унифицированную архитектуру, как показано ниже:
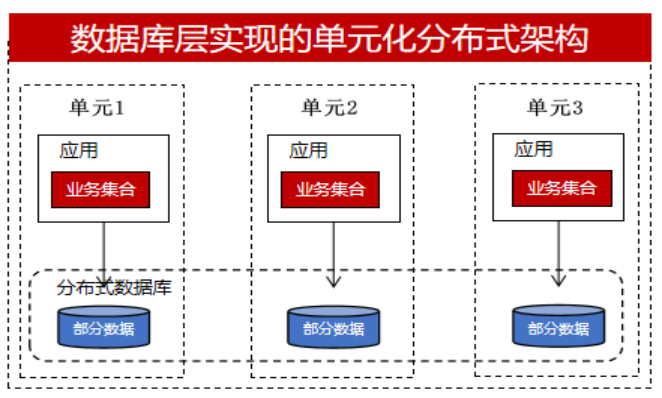
Однако некоторые важные бизнес-системы или группы с определенными возможностями разработки рассмотрят возможность реализации их на уровне приложений. Они хотят получить больше контроля. Если в распределенной транзакции произойдет аномалия, если она будет реализована на уровне базы данных, это будет черным ящиком для разработчика. Он может только рассчитывать на возможности обработки распределенных транзакций базы данных. и они не могут вмешаться. Но если это реализовано на бизнес-уровне, они могут использовать информацию журнала, полученную из очередей сообщений, TCC, саги и т. д., и использовать механизм компенсации данных для выполнения соответствующей обработки. Таким образом, они достигнут распределения на уровне приложений, а база данных будет использовать централизованный подход. Каждая база данных хранит часть бизнес-данных с унифицированной архитектурой, как показано на рисунке ниже:
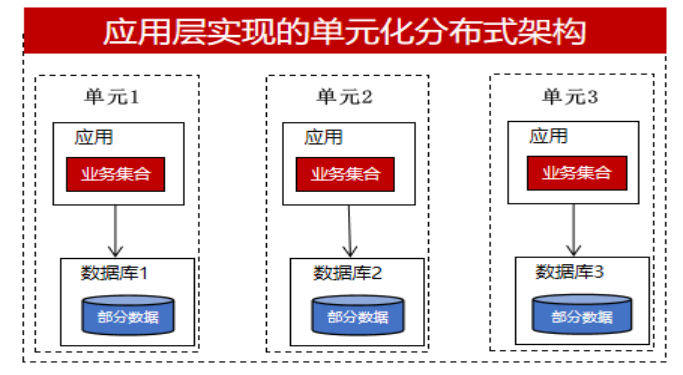
Различия между централизованными и распределенными базами данных при реализации распределенных методов резюмируются следующим образом:
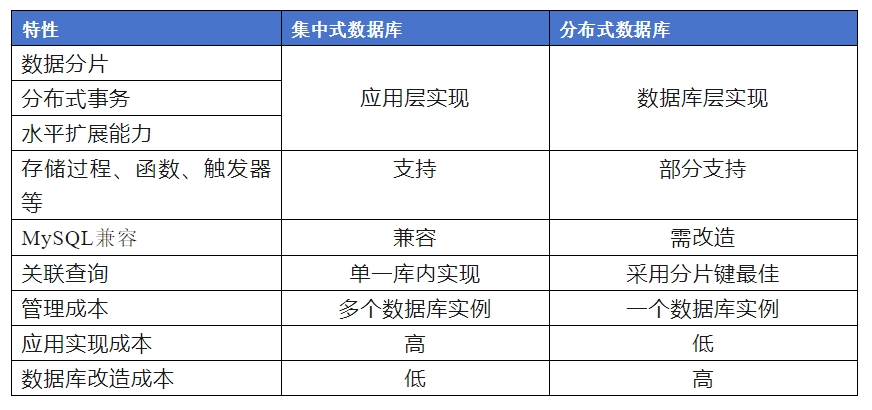
При использовании централизованной базы данных уровень приложений предъявляет более высокие требования к распределенным приложениям для достижения распределенных характеристик. Однако на уровне базы данных относительно мало модификаций, поскольку совместимость централизованных баз данных лучше, чем распределенных.
При использовании распределенной базы данных приложению не требуется реализовывать распределенные функции, и оно прозрачно для приложения. Однако распределенная база данных имеет плохую совместимость или даже не поддерживает специальные объекты, такие как хранимые процедуры и функции. Это требует от приложения адаптации к база данных.
6. Резюме
На форуме за круглым столом, посвященном инновациям в области баз данных, мой коллега-учитель сказал, что централизованная база данных подобна овце, послушной и простой в управлении, тогда как распределенная база данных — это дикая лошадь, неуправляемая и трудноуправляемая. Это напоминает мне книгу Сон Донъе «Донг». Как поется в песне «Мисс», «Я влюбилась в дикую лошадь, но в моем доме нет луга, и это приводит меня в отчаяние…». Дикую лошадь распределенной базы данных можно приручить и позволить вам скакать по прерии, иначе она заставит вас страдать и бороться. Фактически, большинство разработчиков все еще надеются, что база данных будет делать больше, разработчики будут вносить меньше изменений, а база данных будет более прозрачной, простой и даже умной.
В заключение хотелось бы сказать, что нашей отечественной базе данных предстоит долгий путь: ведь заказчиков больше волнует улучшение базовых функций, чем добавление новых. Если мы сможем хорошо поработать с основным механизмом хранения базы данных и экологией, то мы не будем подробно обсуждать эту тему в базе данных OLTP.
Если в статье есть какие-то неточные или непрофессиональные выражения, пожалуйста, поправьте меня.Спасибо.
Дополнительные технические статьи можно найти на странице https://opensource.actionsky.com/ .
О SQLE
SQLE — это комплексная платформа управления качеством SQL, которая охватывает аудит и управление SQL от среды разработки до производственной среды. Он поддерживает основные базы данных с открытым исходным кодом, коммерческие и отечественные базы данных, обеспечивает возможности автоматизации процессов разработки, эксплуатации и обслуживания, повышает онлайн-эффективность и качество данных.
SQLE получить
| тип | адрес |
|---|---|
| Репозиторий | https://github.com/actiontech/sqle |
| документ | https://actiontech.github.io/sqle-docs/ |
| выпускать новости | https://github.com/actiontech/sqle/releases |
| Документация по разработке плагина аудита данных | https://actiontech.github.io/sqle-docs/docs/dev-manual/plugins/howtouse |