

Автор | Сяосинь, Челизи
Введение
Статическое сканирование кода (SA) позволяет быстро выявлять дефекты кода, такие как доступ к нулевому указателю, выход за пределы массива и т. д., обеспечивая качество и повышая эффективность доставки с более высокой рентабельностью инвестиций. Текущие возможности сканирования в основном опираются на искусственный опыт создания правил, который имеет слабую способность к обобщению и запаздывание итераций, что приводит к утечкам. В этой статье предлагается решить проблему того, чему учиться машина, на основе графа знаний кода, и решить проблему того, как машина учится на основе модели большого кода, чтобы компьютер мог понимать код, как человек. и автоматически обнаруживать дефекты в коде и давать советы для достижения лучших результатов.Небольшие затраты на рабочую силу, лучшее обобщение эффекта и более высокий уровень отзыва проблем.
Полный текст составляет 3519 слов, расчетное время чтения — 9 минут.
01 Общие сведения об обнаружении дефектов кода
Статическое сканирование кода (SA) означает, что в разработке программного обеспечения после того, как программисты пишут исходный код, они анализируют и проверяют программу, не запуская компьютерную программу. Вмешавшись в SA на этапе кодирования перед тестированием кода, можно заранее обнаружить и устранить проблемы в коде, что эффективно сокращает время тестирования и повышает эффективность исследований и разработок.Чем позже обнаруживается ОШИБКА, тем выше стоимость ее устранения.

Возможности MEG SA были созданы в 2018 году. Он поддерживает C++, GO и другие языки и имеет более 100 правил, охватывающих большинство модулей MEG, обеспечивая в определенной степени онлайн-качество. Текущее обнаружение в основном опирается на правила, созданные вручную, что приводит к высоким затратам на написание вручную, слабым возможностям обобщения и задержке итераций, что приводит к утечке проблем. Во втором квартале 2022 года наша команда попытается внедрить большие модели: с помощью больших моделей языка кода машины смогут автономно обнаруживать дефекты, улучшать возможности обобщения и эффективность итераций, а также снижать затраты на написание правил вручную. Далее я представлю вам соответствующие введения.
02 Основные проблемы обнаружения дефектов кода на основе правил
По мере увеличения числа правил дефектов и увеличения охватываемых языков и модулей возникают две нерешенные проблемы, которые необходимо срочно решить:
1. Каждое правило требует ручного обслуживания на основе опыта и последующего анализа утечек, что является дорогостоящим. Если взять в качестве примера сценарий с нулевым указателем, код правила, написанный вручную, составляет 4439 строк, и в общей сложности поддерживается 227 случаев регрессии, но есть все еще 3 во втором квартале. Утекла ошибка. Как мы можем внедрить большие модели, чтобы снизить затраты на разработку и повысить качество и эффективность?
2. Эффективность низкая, возможности сканирования ограничены (например, неработающие ссылки, гарантированные непустые кадры, трудность идентификации статических сложных сцен и т. д.), а приемлемость рисков различна. Некоторые из просканированных проблем с высоким риском низкая готовность к ремонту, что беспокоит пользователей.Как мы можем использовать модель, чтобы учиться на исторических ложных срабатываниях, фильтровать их, уменьшать перебои и улучшать отзыв?
03 Решение
Для решения двух болевых точек предлагаются соответствующие решения.
3.1 Автоматическое сканирование дефектов на основе крупных моделей
Как заставить компьютер понимать код как человек, автоматически находить дефекты в коде и давать подсказки. Чтобы позволить компьютерам самостоятельно обнаруживать дефекты, необходимо решить две основные технические проблемы:
[Что изучать] Какой контент вводить в компьютер, может заставить компьютер учиться быстрее и лучше; он в основном опирается на граф знаний кода для извлечения фрагментов, связанных с целевыми переменными, уменьшая размер выборки, необходимый для машинного обучения, и повышая точность обучения.
[Как учиться] Основываясь на входном содержании, какой алгоритм следует использовать, чтобы машина могла читать несколько языков программирования, как человек, и выполнять задачи обнаружения? Используется метод глубокого обучения, который в основном включает предварительное обучение и тонкая настройка. Технология предварительного обучения позволяет компьютерам изучать общую семантику кода на нескольких языках из огромных немаркированных выборок.В этом проекте в основном используются предварительно обученные большие модели с открытым исходным кодом. Технология точной настройки вводит образцы обнаружения дефектов в большую модель, чтобы получить большую модель, которая адаптируется к сцене, позволяя машине самостоятельно выявлять дефекты.
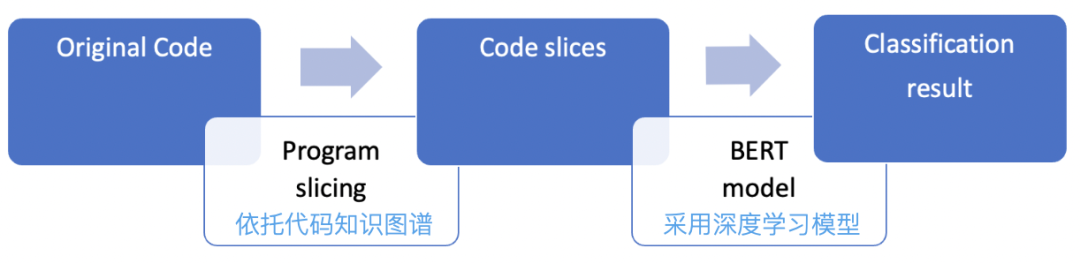
3.1.1 Фрагменты извлечения графа знаний кода
Чтобы сбалансировать производительность и ресурсы модели, разные большие модели допускают разные величины входных токенов. Например, модель Берта ограничивает количество токенов 512. Поэтому входные данные необходимо уменьшить. Граф знаний кода — это сеть знаний кода «белого ящика» программного обеспечения, построенная на основе методов анализа программ после нечеткого или точного лексического анализа, синтаксического анализа и семантического анализа бизнес-исходного кода в сочетании с анализом зависимостей, анализом взаимосвязей и другими средствами. Graph предоставляет различные методы доступа к данным, позволяя пользователям получать доступ к данным кода по низкой цене.
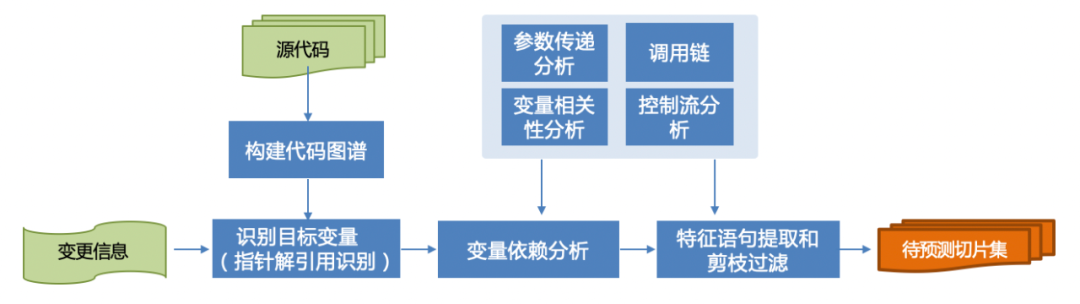
С помощью возможностей графа знаний кода можно сформулировать различные возможности контекстного получения исходного кода, связанные с целевыми переменными или целевыми сценариями, в соответствии с различными сценариями.Ключевые этапы извлечения включают в себя:
-
Построить граф знаний анализируемого кода
-
Обнаружение и идентификация целевой переменной: идентифицируйте целевую переменную в измененном коде как переменную, подлежащую обнаружению.
-
Анализ зависимостей переменных: анализ зависимых переменных, связанных с целевыми переменными, на основе потока управления и потока данных.
-
Извлечение и обрезка характерных предложений
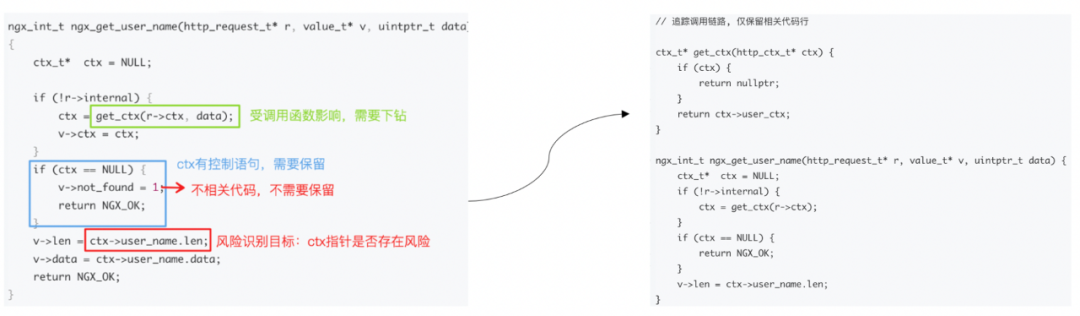
Взяв в качестве примера обнаружение риска нулевого указателя, мы наконец получаем следующий пример информации о фрагментах кода:
3.1.2 Использование алгоритма обучения большой модели для прогнозирования дефектов
Есть две идеи по обнаружению дефектов в больших моделях:
1. Один из них – выявить наличие дефектов и тип дефектов с помощью дискриминантного метода;
2. Один из них — использовать генеративный метод для построения подсказок и позволить программе автоматически сканировать все связанные дефекты.
Этот проект в основном использует дискриминантный метод и доказал, что этот метод имеет определенную осуществимость на практике. В эксперименте по синхронизации генеративного метода некоторые практики этих двух идей представлены ниже.
3.1.2.1 Дискриминантный метод
Благодаря идее классификации и на основе модели мы изучаем правила на исторических выборках, чтобы предсказать категорию новых выборок. Какой из множества алгоритмов глубокого обучения, таких как TextCNN, LSTM и т. д., следует использовать? Посредством множества сравнительных экспериментов мы наконец выбрали большую модель кода BERT, дающую наилучший эффект.
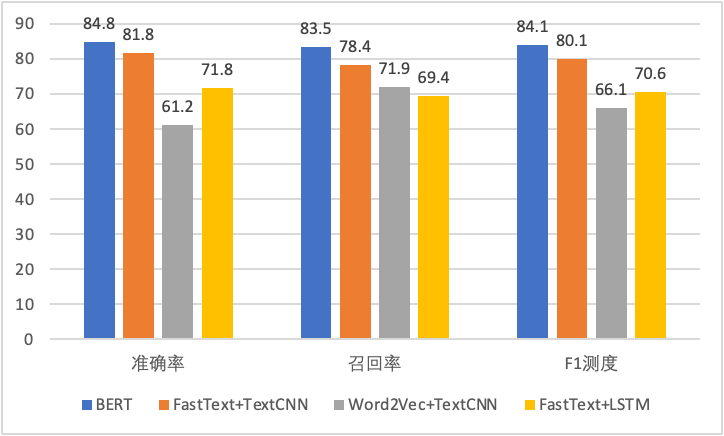
△Эффект модели
Использование BERT для обнаружения дефектов состоит из трех этапов: предварительное обучение, точная настройка и вывод.
-
На этапе предварительного обучения используются большие многоязычные модели с открытым исходным кодом, чтобы лучше изучить семантику нескольких языков программирования.
-
На этапе тонкой настройки в модель вводятся срезы, связанные с точками использования переменных, извлеченными с помощью графа знаний кода, а также метки наличия дефектов или типов дефектов, и таким образом создается точно настроенная модель. что машина имеет возможность выполнять задачи обнаружения. Формат ввода:
{
"slices": [{"line":"行代码内容", "loc": "行号"}],
"mark": {"label":"样本标签", "module_name":"代码库名", "commit_id":"代码版本", "file_path":"文件名", "risk_happend_line":"发生异常的行"}
}
- На этапе вывода анализируются соответствующие фрагменты целевых переменных точек использования и делаются прогнозы путем точной настройки модели, чтобы определить, являются ли точки использования дефектными и тип дефектов.
После того, как модель выходит в Интернет, статус обратной связи пользователя о результатах включает ложные срабатывания и принятие, собираются реальные образцы обратной связи и добавляется автоматическое обучение точно настроенной модели, чтобы достичь цели автоматической итерации и быстрого обучения новые знания.
3.1.2.2 Генеративный метод
Генеративные модели процветают, в том числе модели с закрытым исходным кодом, такие как Chatgpt и Wen XiNYYAN, и модели с открытым исходным кодом, такие как llama, Bloom и Starcode. В основном мы пробовали Вэнь Синьиян, ламу и цветение и исследовали прогнозирующий эффект модели при обнаружении дефектов нулевого указателя посредством подсказки (несколько кадров, введение цепочки мышления, определение абстрактных правил управления) и тонкой настройки. Общая мера f1 невысока, лучшее цветение составляет 61,69%, что значительно отстает от 80% маршрута Берта, а стабильность модели плохая. Поскольку генеративный маршрут имеет свои преимущества, такие как большое количество параметров, интеллектуальная эмерджентность и более сильная способность к рассуждению, позволяющая количеству входных токенов продолжать увеличиваться, что может уменьшить зависимость от очистки срезов и может сочетаться с восстановлением, и т. д., мы прогнозируем, что будут дефекты. Генеративные методы для сценариев обнаружения являются тенденцией. Далее мы продолжим оптимизировать, постоянно пробовать подсказки и тонкую настройку, а также лучше стимулировать потенциал модели посредством более подходящего руководства, тем самым улучшая влияние генеративных методов в сценариях обнаружения.

3.2. Используйте правила и машинное обучение для фильтрации ложных срабатываний
Дефекты, выявленные в сценариях обнаружения дефектов, представляют собой риски, и существует проблема принятия. Как отфильтровать проблемы с низким уровнем риска, является сложной проблемой. Анализируя ложные срабатывания и исправленные образцы, мы собираем функции, связанные с ложными срабатываниями, такие как тип указателя, уровень ложных срабатываний модуля, уровень ложных срабатываний файла и другие более 10 функций, связанных с ложными срабатываниями, обучаем модель машинного обучения (логистическую регрессию), и решить, требуется ли фильтрация.
Общая схема архитектуры программы выглядит следующим образом:

04 Реализация бизнеса
Возможности обнаружения дефектов кода на основе искусственного интеллекта могут быть интегрированы в платформу управления кодом.Каждый раз, когда код отправляется, отображаются возможные дефекты кода, блокируется интеграция и собирается обратная связь от разработчиков для облегчения итерации модели.
05 Прибыль и прогноз
5.1 Доход
С помощью теории и практики было доказано, что можно позволить компьютеру самостоятельно изучить язык программирования и выполнить задачу обнаружения дефектов.
1. Метод этого проекта был опубликован на конференции IEEE AITest Conference 2023:
«Использование моделей глубокого обучения для межфункционального обнаружения рисков нулевого указателя» ( https://ieeeaitest.com/accepted-papers/ )。
2. Фактический эффект от реализации: сценарий с нулевым указателем C++ в 2023 году охватил более 1100 модулей и было исправлено 662 проблемы. составил 26,8%, что предварительно доказывает, что возможности отзыва открывают большие модели для обнаружения дефектов кода, а также подтверждают, что большие модели обладают преимуществами расширенного отзыва и низкой стоимостью традиционных правил, а также могут образовывать самозамкнутый цикл маркировка + обучение + обнаружение.
5.2 Перспективы
Основываясь на преимуществах версии 5.1, мы можем с уверенностью использовать большие модели для обнаружения дефектов кода. Мы продолжим совершенствоваться в следующих аспектах:
1. Расширить больше языков и сценариев, таких как деление на ноль, бесконечный цикл и сценарии выхода за пределы массива, а также провести быстрое обучение многоязычному Go, Java и т. д. и опубликовать его;
2. С появлением генеративных моделей будут постепенно накапливаться эффективные данные о проблемах и ремонте, а общие большие модели Wenxin будут использоваться для предварительного обучения и точной настройки для изучения применения генеративных моделей в области интеллектуального обнаружения дефектов и ремонт;
3. В то же время мы изучим более базовые технологии нарезки и получим более богатую и эффективную нарезку кода для повышения точности вызова.
--КОНЕЦ--
Рекомендуем к прочтению
Поговорите с InfoQ о высокопроизводительной поисковой системе Baidu с открытым исходным кодом Puck
Краткое обсуждение технологии сценариев уровня представления поиска и практики tanGo.
Первое знакомство с поиском: первый урок менеджера по поисковому продукту Baidu
Применение технологии интеллектуальных вопросов и ответов в поиске Baidu
В Alibaba Cloud произошел серьезный сбой, и все продукты были затронуты (восстановлены).Tumblr охладил российскую операционную систему Aurora OS 5.0.Новый пользовательский интерфейс представил Delphi 12 и C++ Builder 12, RAD Studio 12. Многие интернет-компании срочно нанимают программистов Hongmeng.UNIX time вот-вот вступит эпоха 1,7 миллиардов человек (уже наступила). Meituan набирает войска и планирует разработать системное приложение Hongmeng. Amazon разрабатывает операционную систему на базе Linux, чтобы избавиться от зависимости Android от .NET 8 в Linux. Независимый размер составляет уменьшено на 50% .Выпущен FFmpeg 6.1 "Heaviside".