

Автор | Синь
Введение
Группа модельной архитектуры отдела поисковой архитектуры Baidu стремится предоставить новейшие технологии искусственного интеллекта сотням миллионов пользователей Baidu по более низкой цене. Этот процесс столкнется со многими проблемами системного и инженерного уровня.Даже в области моделей глубокого обучения мы видим все больше и больше работы, которая не ограничивается самой инженерией.
Полный текст составляет 5361 слово, расчетное время чтения — 14 минут.
01 Поиск модели глубокого обучения и эволюция бизнеса и архитектуры
Как показано на рисунке ниже, мы запросили длину реки, и результаты поиска точно вернули длину реки вместо того, чтобы возвращать веб-ссылки с информацией об ответе, чтобы пользователи могли выполнять последовательный поиск. Для этого жизненно важную роль играет глубокое обучение: модель находит, оценивает и перехватывает точные ответы из корпуса, а затем представляет их пользователю. Кроме того, пользователи могут ввести изображение и спросить, о чем оно.
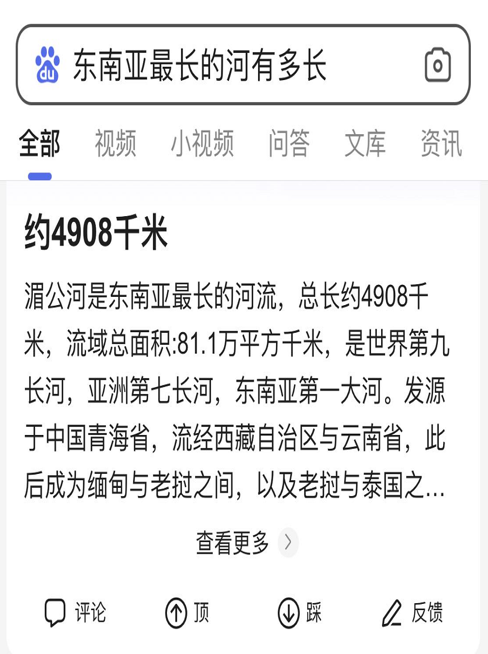

1.1 Поиск пути семантического поиска
На протяжении всего процесса разработки поиска, от первоначальных искусственных функций до поверхностных моделей машинного обучения и постоянно углубляющихся моделей глубокого обучения, наша способность понимать потребности пользователей и контент-кандидат продолжала улучшаться, и наши возможности улучшились до в определенной степени влияют на архитектурные изменения. В последние годы одним из крупнейших изменений в архитектуре стало внедрение крупномасштабных моделей и систем обучения глубоким знаниям.

Традиционная идея пути поиска — это инвертированный индекс. Под индексированием мы обычно понимаем сначала получение текста, а затем подсчет частоты ключевых слов в тексте. Что такое инверсия? Пользователь ищет слово, а мы смотрим тексты, в которых оно встречается. Однако в китайском контексте семантика всего предложения резко изменится из-за изменения одного или двух слов. Например, «Горные персики красные» и «Горные персиковые цветы красные». Первое описывает Плоды горного персика (последний относится к цвету цветков горного персика).
Инвертированному поиску трудно уловить такого рода изменения, а семантическое индексирование очень хорошо помогает в решении такого рода проблем.
Итак, что такое семантическое индексирование? Мы встраиваем запрос пользователя в вектор (размерность 128/256), затем извлекаем весь сетевой контент и сопоставляем встраивание с векторным пространством. Мы можем думать об этом векторном пространстве как о семантическом пространстве. Чем ближе мы к векторному пространству, тем более схожей будет семантика, и мы сможем вернуть пользователю более удовлетворительные результаты.
1.2 Поиск моделей глубокого обучения
Во многих случаях поиск и рекомендация имеют определенное сходство, но имеют и много различий.Здесь я их сравню.
В модели семантического понимания поиска широко используется структура класса преобразования. В качестве признака используется текст. Диапазон словарного запаса обычно <200 000. Модель глубокая и требует большого количества вычислений.
Модель рекомендаций включает в себя большое количество пользовательских и материальных функций и функций взаимодействия, а размер словарного запаса равен TB, который является широким и поверхностным.
Особенности модели поиска:
1. Исходный текст/изображение->встраивание
2、URL-адрес запроса/заголовок/содержание
3. Глубокая модель
4. Предварительное обучение в автономном режиме и многоэтапная онлайн-оценка.
5. Вычислительная нагрузка -> гетерогенное оборудование.
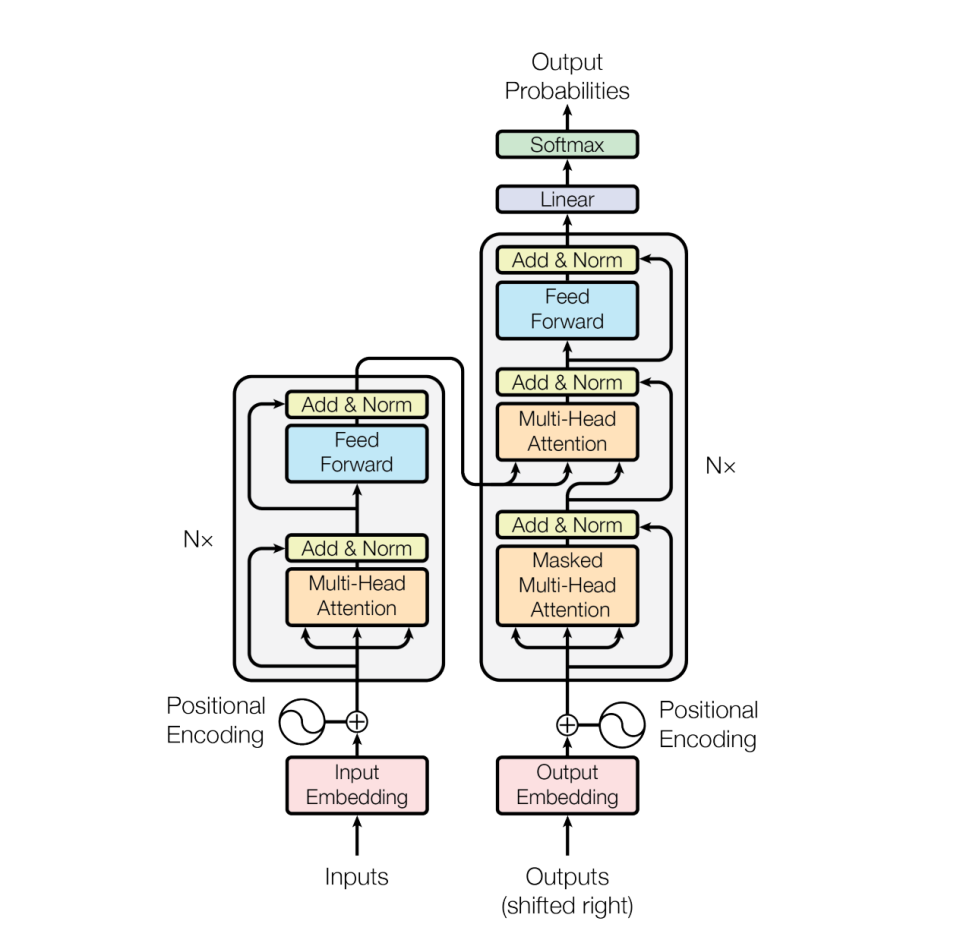
△图片来源: Васвани А., Шазир Н., Пармар Н. и др. Внимание — это все, что вам нужно[J]. Достижения в области нейронных систем обработки информации, 2017, 30.
CTR/рекомендуемые характеристики модели:
1. Многомерные дискретные признаки -> встраивание
2. Извлечение характеристик сращивания образцов инженерных характеристик
3. Неглубокий DNN
4. Своевременность->онлайн-обучение
5. Высокая пропускная способность->ЦП+PS
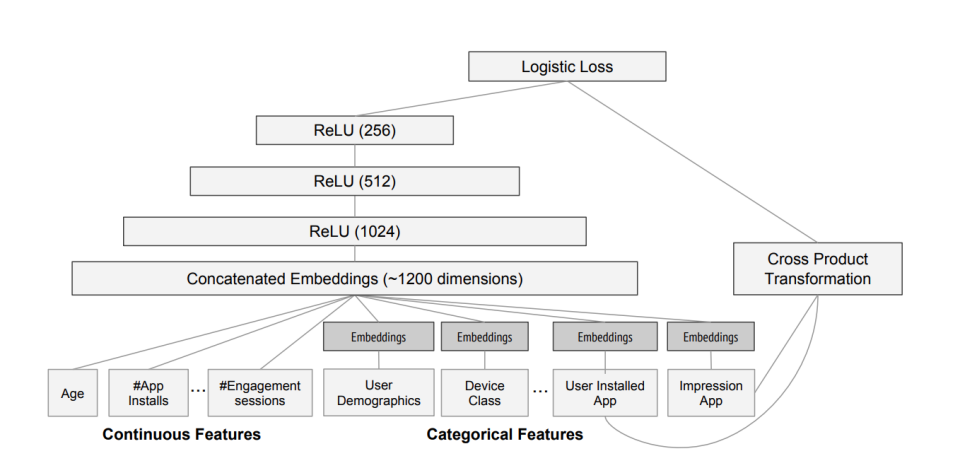
Схематическая диаграмма классической модели △ctr Wide&Deep (Источник изображения: Cheng HT, Koc L, Harmsen J и др. Широкое и глубокое обучение для рекомендательных систем[C])
1.3 Применение модели глубокого обучения поиска в пути семантического поиска
Путь семантического поиска в основном включает в себя автономный путь (левая часть рисунка ниже) и онлайн-путь (правая часть рисунка ниже). Мы видим, что модель глубокого обучения ERNIE используется как оффлайн, так и онлайн .

△Классификация: Лю Ю, Лу В, Ченг С и др. Предварительно обученная языковая модель для поиска в масштабе Интернета в Baidu Search[C]
Что касается офлайн-стороны, то во всей сети очень много текстов, и все их необходимо извлечь в нашу базу данных для встраивания, для этой работы необходимо заранее рассчитать оффлайн-путь и сохранить его в базе данных.
В онлайн-режиме, когда пользователь вводит текст запроса, он вводит как традиционный путь поиска (обработка запросов), так и путь семантического поиска (кодировщик запросов). В пути семантического поиска пользовательский запрос вычисляет вектор через модель глубокого обучения (модель ERNIE на картинке ), а затем сравнивает его с векторами в библиотеке, чтобы быстро найти текст, максимально близкий к запросу. вектор. Это первый шаг, и впереди еще много сложной работы.
02 Поиск сверхкрупномасштабных онлайн-систем вывода
2.1 Онлайн-системы и около-лайновые/оффлайн-системы
Система онлайн-обоснования поиска выполняет вычисления в режиме реального времени и возвращает результаты на основе запросов пользователей.Модель в основном разделена на три части: анализ спроса/переписывание запросов, корреляция/сортировка и классификация.
(1) Анализ требований/переписывание запроса заключается в возврате запроса с аналогичной семантикой через модель глубокого обучения.
Когда пользователь спрашивает: «Что означает автоматический выключатель?», который содержит разговорные выражения, возвращается запрос с похожей семантикой путем вызова глубокой модели: «Что означает автоматический выключатель?», чтобы сделать вызванные ответы более богатыми и точными.
(2) Релевантность/ранжирование требует использования грубой модели ранжирования/точного ранжирования для объединения информации веб-страницы, связанной с пользовательским запросом и заголовком, и позволяет модели вычислить корреляцию. Полученная оценка определяет рейтинг при возврате пользовательских результатов.
Когда пользователь задает вопрос: «Рекомендации по обязательному посещению туристических достопримечательностей в Сиане», чем выше оценка, присвоенная моделью, тем ближе веб-страница к потребностям пользователя, и возвращается «float: 0,876».
(3) Классификация , то есть идентификация типа через модель и тип возвращаемого значения.
Когда пользователь спрашивает: «Джей Чоу Даосян», модель понимает, что это требование к музыке, и мы можем отображать пользователю карточки с типами музыки.
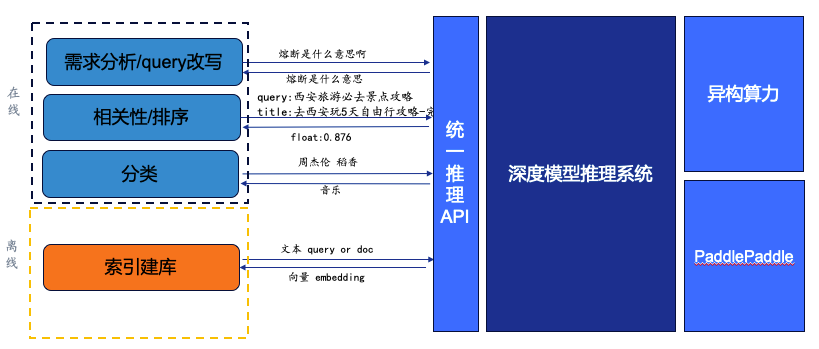
Найдите автономные системы для обработки задач, не зависящих от времени. Использование пользователем поиска будет показывать очевидные пики и спады, особенно во второй половине ночи, когда пользовательский трафик очень низкий. Избыточные ресурсы можно использовать для автономных расчетов, а результаты расчетов сохраняются в корпусе. Например, что касается высоты Эвереста, упомянутой в начале статьи, глубокая модель может получить ответ непосредственно из корпуса. Есть также некоторые чисто автономные задачи: мы используем пакетное создание базы данных и пакетную очистку базы данных, чтобы получить индекс и сохранить его в базе данных.
2.2 Система рассуждений глубокой модели
Глубокие модели используются во многих задачах поисковой системы. Мы надеемся, что все пользователи и бизнес-стороны смогут использовать один и тот же набор API для вызова глубоких моделей. Именно это мы и делаем.
После системы глубокого вывода ее серверная часть требует от нас развертывания службы глубокого вывода моделей, поскольку типы, размеры и размеры моделей у всех разные, включая гетерогенную вычислительную мощность.
Итак, если количество параллелизма увеличится, как мы сможем добиться равномерного планирования и сделать систему стабильной и надежной?
Во-первых, это единообразное планирование. На рисунке ниже показано типичное решение для развертывания внутренней модели компании. Компьютер, который получает каждый из нас, называется автономной машиной. Однако степень детализации одной машины выше, и для предоставления услуг ее необходимо виртуализировать и разделить на более мелкие части. , расширять и сжимать и т. д. Мы называем их экземплярами.
При предоставлении услуг внешнему миру одна машина с несколькими экземплярами не может поддерживать огромный объем параллелизма, поэтому необходимо расширить несколько машин с несколькими экземплярами.Поиск на Baidu такого сценария с большим количеством пользователей, таких сервисов будет развернут в нескольких компьютерных залах в разных местах. Смысл единообразного планирования заключается в том, что при генерации большого количества одновременных запросов необходимо равномерно использовать минимальную степень детализации экземпляров в различных местах, при этом некоторые машины не могут быть перегружены, а некоторые машины не используются.
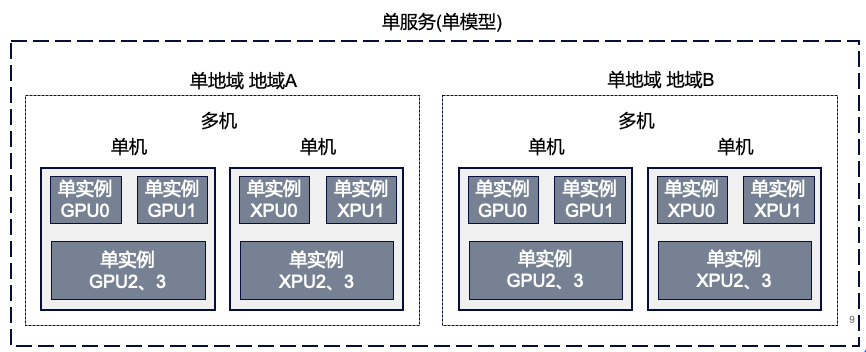
Кроме того, он стабилен и надежен. В области архитектуры есть очень известное высказывание: «Работа над архитектурой заключается в построении стабильной системы на нестабильном оборудовании». Когда количество наших экземпляров и машин увеличивается, аппаратный сбой становится неизбежным. Нам нужно обеспечить то, как обнаружить сбои и своевременно их перенести, чтобы обеспечить удобство работы пользователей.
Кроме того, мы также надеемся, что вся система вывода будет достаточно быстрой, имеет достаточно высокую пропускную способность и максимально сократит затраты ресурсов. Как показано на рисунке ниже, запрос системы вывода вводится через brpc. brpc вызывается через сеть между различными модулями внутри компании, что позволяет пользователям вызывать другие службы, используя метод, аналогичный локальным функциям. После получения запроса система определит информацию в запросе на вывод, в том числе к какой модели обращаться, к какой версии обращаться, что вводить и т. д., а затем войдет в конвейер обработки.
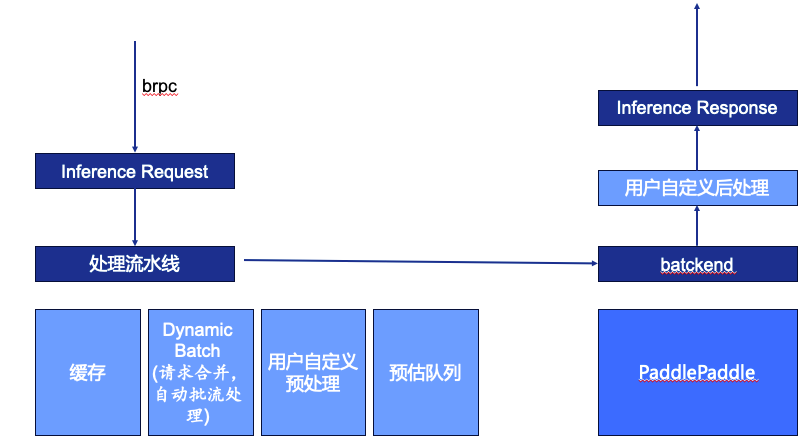
Конвейер обработки состоит из четырех частей:
(1) Кэш. Если тот же запрос был рассчитан в течение определенного периода времени, он будет возвращен пользователю напрямую через кеш без вызова графического процессора.
(2) Динамическая пакетная обработка. Многие онлайн-модули рассчитываются на основе триггерной модели Batch=1, но пакет=1 не полностью использует аппаратное обеспечение, а некоторые вычислительные блоки также станут узкими местами в полосе пропускания из-за небольшого размера пакета. Чтобы в полной мере использовать оборудование, мы сделаем пакет настолько большим, насколько это позволяет задержка, поэтому мы объединим запросы в определенном временном окне или другим правилам, чтобы сделать вывод в виде пакетов, а затем разделим их вернуть пользователю.
(3) Пользовательская предварительная обработка, соответствующая модели обработки естественного языка, преобразует открытый текст в идентификатор. Зачем нужна предварительная обработка, определяемая пользователем? В большей степени это связано с бизнес-направлением стыковки поиска: у каждой бизнес-стороны разные методы предварительной обработки данных, поэтому целесообразнее оставить настройку пользователю.
(4) Очередь прогнозирования. Предварительно обработанные запросы попадают в очередь. Эта очередь по порядку поступает в внутренний механизм прогнозирования. После расчета механизмом прогнозирования он поступает в настроенную пользователем постобработку. Постобработка может выводить результаты оптимизируются, а затем возвращаются в восходящий поток.
Выше представлен обзор сверхкрупномасштабных онлайн-систем вывода.
03 Практика глубокой оптимизации модели
3.1 Узкое место оптимизации модели
Наша глубокая оптимизация модели на самом деле направлена на оптимизацию определенных узких мест. Модели графических процессоров обычно сталкиваются с тремя типами узких мест: узкие места ввода-вывода, узкие места ЦП и узкие места графического процессора. Как показано на рисунке ниже, весь процесс обучения включает в себя: чтение данных, прямой вывод и обратное распространение.Наш процесс рассуждения можно разделить на две части: чтение данных и прямой вывод.
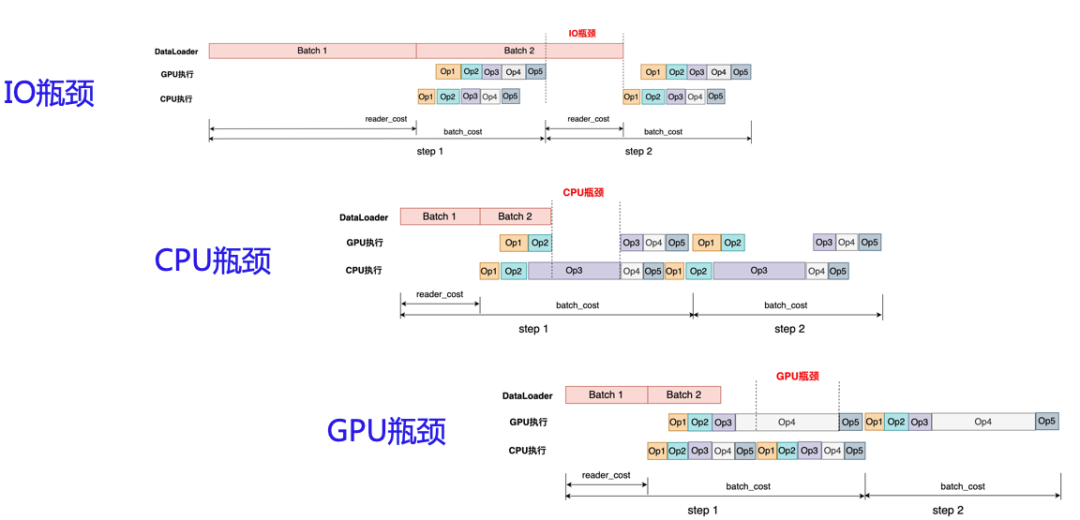
(1) узким местом ввода-вывода является интервал между обработкой данных пакетов 1 и 2, что требует увеличения скорости чтения данных;
(2) Узкое место ЦП — это ситуация, когда загрузка графического процессора недостаточна из-за небольшой рабочей нагрузки, распределяемой ЦП на графический процессор. Сценарий заключается в том, что глубокая модель с несколькими операциями разбивается на последовательности из нескольких операций на графическом процессоре для расчета. Перед этим сначала необходимо обработать процессор. Операция графического процессора завершена, но процессор еще не запустил следующую задачу;
(3) Узкое место графического процессора. Если возникает узкое место графического процессора, это означает, что загрузка графического процессора относительно достаточна, что является лучшим состоянием.
3.2 Работа по оптимизации модели
Работа по оптимизации модели разделена на три аспекта: обучение, вывод и миниатюризация.
3.2.1 Оптимизация обучения
(1) Чтение данных
Оптимизируем чтение данных по сценарию. Причина в том, что по мере того, как модель продолжает расти, мы продолжаем пытаться сегментировать модель и обучать несколько карточек на одной машине или даже на нескольких машинах.Различные методы сегментации также приводят к обработке данных, которая часто не обеспечивает глубокой адаптации. на сцену.
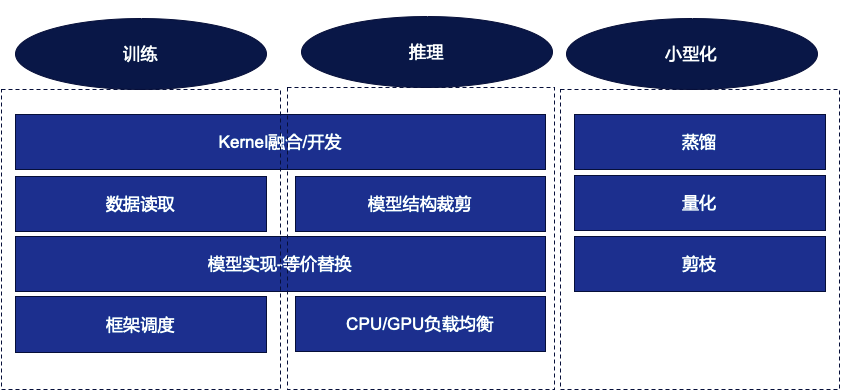
(2) Рамочное планирование
В процессе обучения модели мы обычно проводим оценку после обучения нескольких шагов. В реальной работе мы обнаружили, что многие фреймворки обучаются на нескольких картах, но оценка действительно происходит на одной карте, что оставляет место для оптимизации.
(3) Интеграция/разработка ядра
Это задача, которая будет встречаться как в сценариях обучения, так и в сценариях вывода. Объединение ядер может снизить нагрузку на запуск ЦП. Кроме того, одноядерная задача графического процессора также относительно увеличится, что снижает вероятность возникновения узких мест ЦП.
После выявления ядра, которое недостаточно эффективно, мы разработаем слияние ядер.
(4) Замена, эквивалентная реализации модели
Независимо от того, используете ли вы платформу весла или другие, вам будет предоставлено множество ОП. Если вы хотите реализовать функцию, вы можете использовать разные ОП для достижения одной и той же функции, что дает пользователям очень высокую степень свободы. Однако различные операции неэффективны и действенны в реальном исполнении, поэтому часть нашей работы — выявить и заменить их более эффективными реализациями.
3.2.2 Оптимизация вывода
Помимо слияния/разработки ядра, эквивалентной замены и т. д., оптимизация вывода также включает в себя балансировку нагрузки графического процессора/процессора и адаптацию структуры модели.
(1) Балансировка нагрузки графического процессора/процессора
В сценарии вывода рабочая нагрузка ЦП не слишком велика, включая предварительную обработку, обед ядра и постобработку. Мы можем разместить на ЦП некоторые задачи, с которыми графический процессор не справляется, включая задачи с относительно высоким доступом к памяти. но низкая вычислительная нагрузка.оп, разумнее поставить на ЦП.
(2) Адаптация структуры модели
В бизнес-моделях могут быть вычислительные части, которые необходимы во время обучения, но не во время вывода. Ненужные части можно удалить в процессе экспорта модели.
3.2.3 Миниатюризация модели
Миниатюризация делится на три направления: дистилляция, количественная оценка и обрезка.
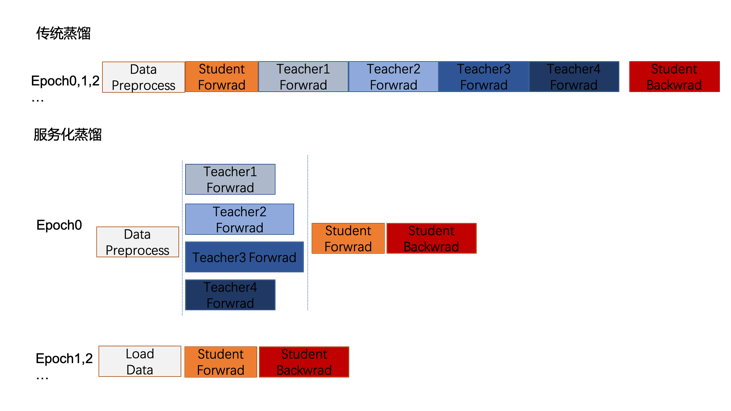
(1) Сервисная дистилляция
Дистилляция — это метод сжатия модели, который передает знания сложной большой модели (учителя) другой меньшей и простой модели (ученику). Маленькие модели могут поддерживать такие же результаты обучения, как и большие модели.
В реальных бизнес-сценариях, поскольку число учителей продолжает расти, процесс дистилляции не может быть распараллелен. Таким образом, с точки зрения инженера, мы ставим учителей на гетерогенную вычислительную мощность для рассуждений. С одной стороны, последовательные рассуждения учителя могут быть распараллелены. С другой стороны, можно использовать простаивающие ресурсы. Как показано на рисунке ниже, общее ускорение. Эффективность дистилляции.
(2) Количественная оценка
В процессе вывода мы надеемся квантовать FLOAT32 до младших битов, таких как INT8, INT4 и т. д., чтобы добиться меньшего использования памяти, меньшего энергопотребления и более высокой скорости вычислений.
С одной стороны, мы стараемся максимально поддерживать развитие количественных инструментов, исследуя различные передовые новые количественные алгоритмы и сводя к минимуму потерю индикаторных эффектов до и после количественной оценки. С другой стороны, мы создаем механизм автоматического количественного анализа, чтобы больше моделей могли оценить повышение скорости, обеспечиваемое количественным анализом.
(3) Обрезка
С точки зрения детализации, обрезка начинается с детальной обрезки одного параметра и сбрасывает неважные веса до 0 в соответствии с определенным шаблоном, но для общего улучшения скорости требуется специальное оборудование.
Детализация немного более грубая.Для моделей трансформаторного типа заголовок внимания можно обрезать, чтобы идентифицировать и удалить заголовки, которые не важны или предоставляют меньше информации. Вы можете даже быть смелее и пропустить некоторые этапы рассуждений.
04 Резюме
Работа группы модельной архитектуры отдела поисковой архитектуры Baidu очень сложна и значима. Мы стремимся предоставить новейшие технологии искусственного интеллекта сотням миллионов пользователей Baidu с меньшими затратами. Мы не только фокусируемся на инженерном применении и оптимизации моделей глубокого обучения в области поиска, но также продолжаем изучать и исследовать новые технические средства для постоянного повышения эффективности и производительности моделей поиска.Мы также пытаемся использовать глубокие модели для изменения формы. архитектура. Если вас интересуют поиск, семантический поиск, глубокая оптимизация и ускорение моделей и т. д., приглашаем вас присоединиться к нашей команде и внести свой вклад в улучшение опыта поиска пользователей.
--КОНЕЦ--
Рекомендуем к прочтению
Масштабная практика Wenshengtu: раскрываем историю поиска Baidu инструментов для рисования AIGC!
Практика применения больших моделей в области обнаружения дефектов кода
Поговорите с InfoQ о высокопроизводительной поисковой системе Baidu с открытым исходным кодом Puck
Краткое обсуждение технологии сценариев уровня представления поиска и практики tanGo.
В Alibaba Cloud произошел серьезный сбой, и все продукты были затронуты (восстановлены).Tumblr охладил российскую операционную систему Aurora OS 5.0.Новый пользовательский интерфейс представил Delphi 12 и C++ Builder 12, RAD Studio 12. Многие интернет-компании срочно нанимают программистов Hongmeng.UNIX time вот-вот вступит эпоха 1,7 миллиардов человек (уже наступила). Meituan набирает войска и планирует разработать системное приложение Hongmeng. Amazon разрабатывает операционную систему на базе Linux, чтобы избавиться от зависимости Android от .NET 8 в Linux. Независимый размер составляет уменьшено на 50% .Выпущен FFmpeg 6.1 "Heaviside".