Благодаря технологиям искусственного интеллекта интеллектуальные разговорные роботы постепенно стали важными инструментами повышения эффективности в нашей работе и жизни и даже партнерами, особенно предлагая предприятиям самую оригинальную и интуитивно понятную реализацию «снижения затрат и повышения эффективности».
Как разработчик, задумывались ли вы когда-нибудь о создании интеллектуального разговорного робота на основе голосовых технологий?
Эта статья шаг за шагом научит вас деталям технической реализации.
Для начала давайте проанализируем, что нужно умному разговорному роботу:
1. Голосовой ввод. Если вы хотите вести интеллектуальный диалог, вам обязательно понадобится голосовой ввод и вывод.
2. Распознавание речи: распознавание речи в текст.
3. Интеллектуальная служба вопросов и ответов. Введите результаты распознавания речи в службу и получите результаты.
4. Синтез речи: генерация звука из интеллектуальных ответов на вопросы и ответы.
5. Голосовая трансляция: вопросы, на которые отвечает интеллектуальная служба вопросов и ответов, будут транслироваться вам в виде голоса.
блок-схема:
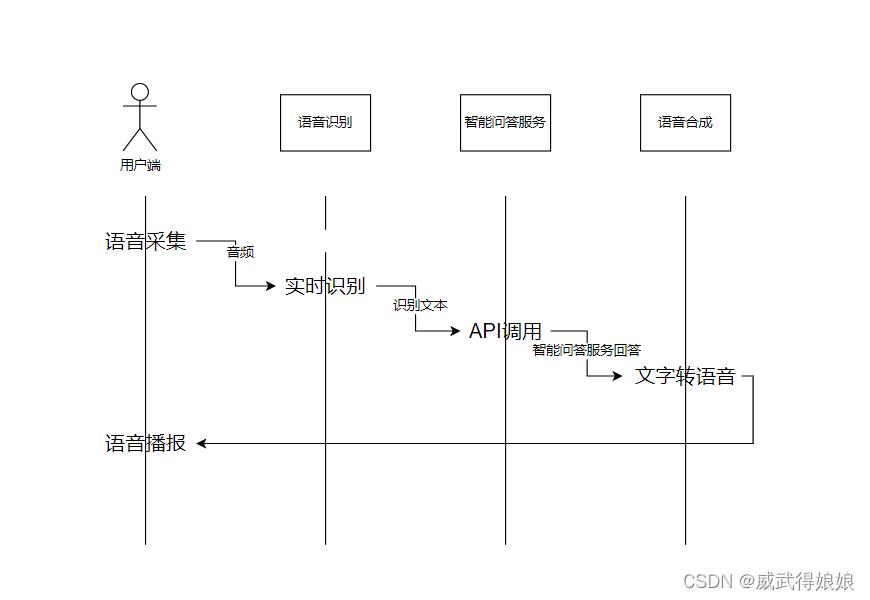
Сборник голосов:
1. Используйте SDK, предоставленный Tencent Cloud Speech Recognition (Android, IOS, апплет WeChat).
2. Вы можете использовать аппаратное записывающее оборудование для самостоятельной записи звука.
3. Настройте записывающее устройство на терминале (IOS, Android и т. д.) для сбора звука.
Технический процесс:
1. Сначала соберите аудио
2. Вызов системы распознавания речи Tencent Cloud (ASR) с данными аудиопотока.
3. Вызовите текстовые данные распознавания речи в интеллектуальную службу вопросов и ответов.
4. Используйте ответ из интеллектуального сервиса вопросов и ответов, чтобы позвонить в Tencent Cloud Speech Synthesis (TTS).
5. Наконец, верните звук, сгенерированный синтезатором речи, в конец для воспроизведения.
1. Подготовительные работы
1.1 Активируйте услугу распознавания речи
Автор использует распознавание речи Tencent. Сначала активируйте услугу. Нажмите здесь на консоли Tencent Cloud Speech Recognition Console и нажмите «Активировать сейчас», чтобы активировать услугу.
Вы можете нажать здесь, чтобы получить пакет ресурсов для новичков: Распознавание речи_Распознавание речи в реальном времени_Распознавание файлов_Запись речи в текстовый сервис — Tencent Cloud
1.2 Получите API-ключ для вызова сервиса
Для доступа к сервисам Tencent Cloud требуется секретный ключ. На странице управления ключами API приложения Tencent Cloud Access Management вы можете создать новый секретный ключ. Он должен храниться в надлежащем состоянии и не подлежит утечке, иначе он будет украден другими. Секретный ключ мы воспользуемся позже.
1.3 Получите SDK для распознавания и синтеза речи
Приобретение SDK для распознавания речи: Распознавание речи, распознавание речи в реальном времени (веб-сокет) — API-документация — Центр документов — Tencent Cloud
Получите пакет Speech Synthesis SDK: Speech Synthesis Basic Speech Synthesis-API Documentation-Center-Tencent Cloud

Получите клиентский SDK:
1.IOS: вход в облако Tencent
2. Android: вход в Tencent Cloud
3. Мини-программа WeChat: Tencent Cloud Intelligent Voice | Плагин мини-программы | Публичная платформа WeChat

1.4. Доступ к интеллектуальному сервису вопросов и ответов.
WeLM: - WeLM
Здесь вы также можете использовать другие интеллектуальные службы вопросов и ответов, такие как ChatGPT.
2. Разработка кода
Логика включает в себя:
1. Запросить идентификацию ASR в реальном времени.
2. Запросите интеллектуальную службу вопросов и ответов.
3. Запросить синтез речи TTS и получить звук.
Компиляция кода:
1. Выполните команду для создания среды go.mod go mod init demo.
2.go сборка, компиляция
3. Выполните ./demo -e 16k_zh -f test аудио адрес формата 1
Примечание. Этот код включает только серверную часть. Вы можете самостоятельно подключиться к SDK для потоковой передачи звука на сервер для распознавания.
package main
import (
"encoding/base64"
"flag"
"fmt"
ttsCommon "github.com/tencentcloud/tencentcloud-sdk-go/tencentcloud/common"
"github.com/tencentcloud/tencentcloud-sdk-go/tencentcloud/common/errors"
"github.com/tencentcloud/tencentcloud-sdk-go/tencentcloud/common/profile"
tts "github.com/tencentcloud/tencentcloud-sdk-go/tencentcloud/tts/v20190823"
"github.com/tencentcloud/tencentcloud-speech-sdk-go/asr"
"github.com/tencentcloud/tencentcloud-speech-sdk-go/common"
"os"
"sync"
"time"
)
var (
AppID = "输入appid"
SecretID = "输入密钥ID"
SecretKey = "输入密钥key"
EngineModelType = "16k_zh"
SliceSize = 16000
)
// MySpeechRecognitionListener implementation of SpeechRecognitionListener
type MySpeechRecognitionListener struct {
ID int
}
// OnRecognitionStart implementation of SpeechRecognitionListener
func (listener *MySpeechRecognitionListener) OnRecognitionStart(response *asr.SpeechRecognitionResponse) {
}
// OnSentenceBegin implementation of SpeechRecognitionListener
func (listener *MySpeechRecognitionListener) OnSentenceBegin(response *asr.SpeechRecognitionResponse) {
}
// OnRecognitionResultChange implementation of SpeechRecognitionListener
func (listener *MySpeechRecognitionListener) OnRecognitionResultChange(response *asr.SpeechRecognitionResponse) {
}
// OnSentenceEnd implementation of SpeechRecognitionListener
func (listener *MySpeechRecognitionListener) OnSentenceEnd(response *asr.SpeechRecognitionResponse) {
fmt.Printf("语音识别结果: %s \n", response.Result.VoiceTextStr)
ConversationalRobot(response.Result.VoiceTextStr)
}
// OnRecognitionComplete implementation of SpeechRecognitionListener
func (listener *MySpeechRecognitionListener) OnRecognitionComplete(response *asr.SpeechRecognitionResponse) {
}
// OnFail implementation of SpeechRecognitionListener
func (listener *MySpeechRecognitionListener) OnFail(response *asr.SpeechRecognitionResponse, err error) {
fmt.Printf("%s|%s|OnFail: %v\n", time.Now().Format("2006-01-02 15:04:05"), response.VoiceID, err)
}
var proxyURL string
var VoiceFormat *int
var e *string
func main() {
var f = flag.String("f", "test.pcm", "audio file")
var p = flag.String("p", "", "proxy url")
VoiceFormat = flag.Int("format", 0, "voice format")
e = flag.String("e", "", "engine_type")
fmt.Println("input-", *e, "-input")
flag.Parse()
if *e == "" {
panic("please input engine_type")
}
if *VoiceFormat == 0 {
panic("please input voice format")
}
proxyURL = *p
var wg sync.WaitGroup
wg.Add(1)
go processOnce(1, &wg, *f)
fmt.Println("Main: Waiting for workers to finish")
wg.Wait()
fmt.Println("Main: Completed")
}
func processOnce(id int, wg *sync.WaitGroup, file string) {
defer wg.Done()
process(id, file)
}
func process(id int, file string) {
audio, err := os.Open(file)
defer audio.Close()
if err != nil {
fmt.Printf("open file error: %v\n", err)
return
}
listener := &MySpeechRecognitionListener{
ID: id,
}
credential := common.NewCredential(SecretID, SecretKey)
EngineModelType = *e
fmt.Println("engine_type:", EngineModelType)
recognizer := asr.NewSpeechRecognizer(AppID, credential, EngineModelType, listener)
recognizer.ProxyURL = proxyURL
recognizer.VoiceFormat = *VoiceFormat
err = recognizer.Start()
if err != nil {
fmt.Printf("%s|recognizer start failed, error: %v\n", time.Now().Format("2006-01-02 15:04:05"), err)
return
}
data := make([]byte, SliceSize)
//这里的data可以换成实时端上传输过来的音频流
for n, err := audio.Read(data); n > 0; n, err = audio.Read(data) {
if err != nil {
if err.Error() == "EOF" {
break
}
fmt.Printf("read file error: %v\n", err)
break
}
//一句话识别结束会回调上面OnSentenceEnd方法
err = recognizer.Write(data[0:n])
if err != nil {
break
}
time.Sleep(20 * time.Millisecond)
}
recognizer.Stop()
}
func ConversationalRobot(text string) {
//调用智能问答服务,获取回答
Result := SendToGPTService(text)
//把智能问答服务的文案转成音频文件
audioData := TextToVoice(Result)
//将音频文件返回给端上播放
ResponseAudioData(audioData)
}
func ResponseAudioData(audioData []byte) {
//把音频数据audioData推到端上播放
}
func SendToGPTService(text string) string {
// API 调用智能问答服务
// 获取智能问答服务返回结果
result := "智能问答服务返回结果"
fmt.Println("智能问答服务 API调用")
return result
}
func TextToVoice(text string) []byte {
fmt.Println("语音合成调用")
// 实例化一个认证对象,入参需要传入腾讯云账户 SecretId 和 SecretKey,此处还需注意密钥对的保密
// 代码泄露可能会导致 SecretId 和 SecretKey 泄露,并威胁账号下所有资源的安全性。以下代码示例仅供参考,建议采用更安全的方式来使用密钥,请参见:https://cloud.tencent.com/document/product/1278/85305
// 密钥可前往官网控制台 https://console.cloud.tencent.com/cam/capi 进行获取
credential := ttsCommon.NewCredential(
SecretID,
SecretKey,
)
// 实例化一个client选项,可选的,没有特殊需求可以跳过
cpf := profile.NewClientProfile()
cpf.HttpProfile.Endpoint = "tts.tencentcloudapi.com"
// 实例化要请求产品的client对象,clientProfile是可选的
client, _ := tts.NewClient(credential, "ap-beijing", cpf)
// 实例化一个请求对象,每个接口都会对应一个request对象
request := tts.NewTextToVoiceRequest()
request.Text = ttsCommon.StringPtr(text)
request.SessionId = ttsCommon.StringPtr("f435g34d23a24y546g")
// 返回的resp是一个TextToVoiceResponse的实例,与请求对象对应
response, err := client.TextToVoice(request)
if _, ok := err.(*errors.TencentCloudSDKError); ok {
fmt.Printf("An API error has returned: %s", err)
return nil
}
if err != nil {
panic(err)
}
// 输出json格式的字符串回包
audioData, _ := base64.StdEncoding.DecodeString(*response.Response.Audio)
fmt.Println("语音合成调用结束")
return audioData
}Выше приведены технические подробности реализации интеллектуальных роботов с голосовым диалогом.Заинтересованные студенты также могут попрактиковаться или расширить разработку.
В настоящее время интеллектуальные разговорные роботы вступили в стадию крупномасштабного внедрения в экономической производственной деятельности, такой как контакты с клиентами, маркетинговые операции, оконные услуги и диалоговое взаимодействие человека с компьютером.Благодаря постоянным инновациям в области технологий искусственного интеллекта интеллектуальные разговорные роботы также будут получение продуктов более высокого уровня., более умный режим.
Tencent Cloud Intelligence также предоставляет универсальные услуги голосовых технологий для корпоративных клиентов и разработчиков.Для получения дополнительной информации о продуктах вы также можете посетить официальный сайт Tencent Cloud.
Интеллектуальное распознавание речи Tencent Cloud: Распознавание речи_Распознавание речи в реальном времени_Распознавание файлов_Запись речи в текстовый сервис — Tencent Cloud
Интеллектуальный синтез речи Tencent Cloud: Синтез речи_Настройка голоса_Преобразование текста в речь-Tencent Cloud