Сегодня я поделюсь некоторыми советами по сбору трех краулерных веб-сайтов. Надеюсь, это будет вам полезно~
查看网页源代码和检查元素
requests使用
BeautifulSoup使用
Просмотр исходного кода веб-страницы и проверка элементов

Не думайте, что это очень просто, эти два трюка лежат в основе краулеров. Если вы знакомы с этими двумя приемами, вы изучите половину простого сканера веб-сайтов.
Вообще говоря, все, что вы видите в проверяемом элементе, появляется в исходном коде веб-страницы. Пример, который я выбрал сегодня, имеет особую ситуацию: содержимое проверочного элемента появится в исходном коде веб-страницы.

Например, поднимитесь на дневную и ночную температуру в Пекине.
Веб-сайт погоды в Пекине:
http://www.weather.com.cn/weather1d/101010100.shtml
Ниже исходный код, я его прокомментирую, читайте вместе с ним
Talk is cheap. Show you the code
# -*- coding: utf-8 -*-
__author__ = 'duohappy'
import requests # 导入requests模块
from bs4 import BeautifulSoup # 从bs4包中导入BeautifulSoup模块
# 设置请求头
# 更换一下爬虫的User-Agent,这是最常规的爬虫设置
headers = {
"User-Agent":'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)Chrome/57.0.2987.110 Safari/537.36'}
# 需要爬取的网址
url ="http://www.weather.com.cn/weather1d/101010100.shtml"
# 发送请求,获取的一个Response对象
web_data = requests.get(url,headers=headers)
# 设置web_data.text会采用web_data.encoding指定的编码,一般情况下不需要设置,requests会自动推断
# 鉴于网页大部分都是采取utf-8编码的,所以设置一下,省去一些麻烦
web_data.encoding = 'utf-8'
# 得到网页源代码
content = web_data.text
# 使用lxml解析器来创建Soup对象
soup = BeautifulSoup(content, 'lxml')
# 为什么要创建一个Soup对象,还记得浏览器中的检查元素功能嘛
# Soup对象可以方便和浏览器中检查元素看到的内容建立联系,下面会有动画演示
# 使用css selector语法,获取白天和夜间温度,下面有动画演示
tag_list = soup.select('p.tem span')
# tag_list[0]是一个bs4.element.Tag对象
# tag_list[0].text获得这个标签里的文本
day_temp = tag_list[0].text
night_temp = tag_list[1].text
print('白天温度为{0}℃n晚上温度为{1}℃'.format(day_temp, night_temp))
Что означает «Объект Soup можно легко связать с содержимым, видимым, проверив элемент в браузере»? Что это значит?
Простое объяснение состоит в том, что элемент проверки выглядит аналогично элементу объекта Soup (это всего лишь упрощенное понимание).

синтаксис селектора CSS
Стоит отметить, что при поиске "p.temem" есть ровно 2 совпадающих объекта, соответствующих дневной температуре и ночной температуре соответственно. Это очень важно. Если количество совпадений больше или меньше 2, то это означает, что ваш селектор CSS пишет неправильно!

Измеряйте дневную и ночную температуру в нескольких городах, ищите информацию о погоде в разных городах и наблюдайте за изменением URL-адресов. Наблюдение за изменениями URL-адресов — один из самых важных навыков сканеров~
# -*- coding: utf-8 -*-
__author__ = 'duohappy'
import requests
from bs4 import BeautifulSoup
headers = {
"User-Agent":'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)Chrome/57.0.2987.110 Safari/537.36'}
# 建立城市和网址特殊部分的对应关系
weather_code = {
'北京':'101010100','上海':'101020100','深圳':'101280601', '广州':'101280101', '杭州':'101210101'}
city = input('请输入城市名:') # 仅仅能输入北京,上海,广州,深圳,杭州
url ="http://www.weather.com.cn/weather1d/{}.shtml".format(weather_code[city])
web_data = requests.get(url,headers=headers)
web_data.encoding = 'utf-8'
content = web_data.text
soup = BeautifulSoup(content, 'lxml')
tag_list = soup.select('p.tem span')
day_temp = tag_list[0].text
night_temp = tag_list[1].text
print('白天温度为{0}℃n晚上温度为{1}℃'.format(day_temp, night_temp))
КрасиваяСуп
BeautifulSoup — это сторонний набор инструментов для анализа веб-страниц HTML, предоставляемый Python. Для URL-адреса вы можете использовать функции-члены объекта beautifulSoup, чтобы напрямую найти содержимое соответствующего компонента. Что касается такого контента, как текст и информация, то он часто записывается непосредственно в текстовый код веб-страницы. Используя инструменты разработчика браузера Google, мы можем напрямую прочитать исходный код веб-страницы:
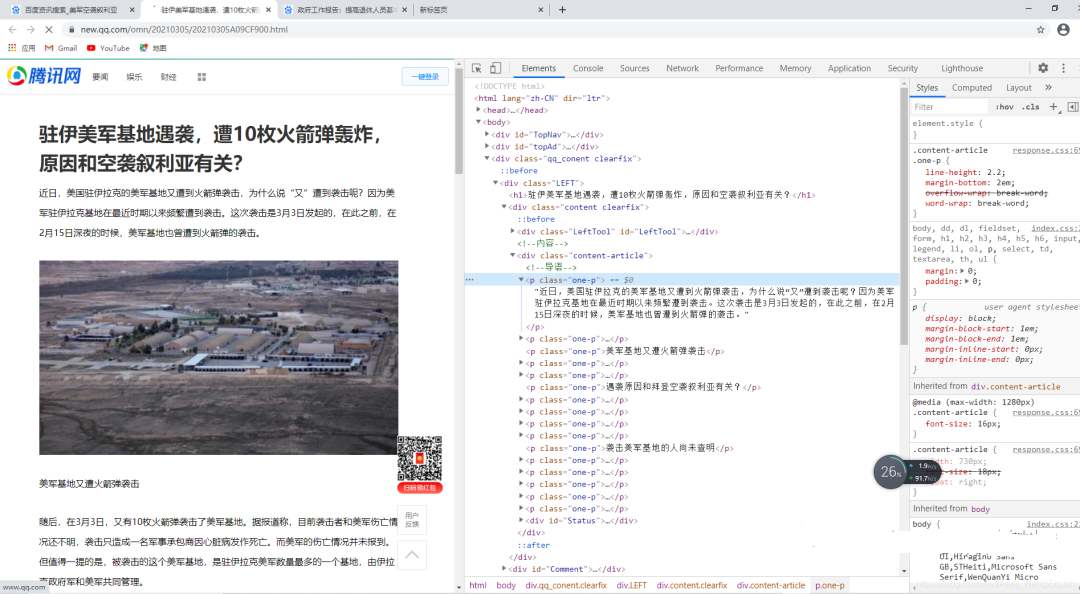
Вы можете использовать маленькую стрелку справа, чтобы напрямую найти позицию, которую необходимо просканировать, и обнаружить, что информация записана непосредственно в исходном коде справа. Текстовую информацию не нужно обновлять в режиме реального времени, а удобный способ хранения данных отсутствует.
Используйте объект bs для поиска и обработки, чтобы мы могли написать простой код:
1.bs = BeautifulSoup(html_news,'html.parser')
2.title = bs.find('h1').text
3.content= bs.find('div',class_='content-article').text //注意参数带下划线
4.content_str = "".join(re.findall('[0-9\u4e00-\u9fa5]', content))
Но мы видим, что все абзацы находятся в компоненте p, поэтому код можно написать и так: код будет такой (пример):
1.cur_str = ""
2.bs = BeautifulSoup(html_news,'html.parser')
3.title = bs.find('h1').text
4.paras = bs.find_all('p',class_='one-p') //返回一个列表
5.for para in paras:
6.cur_str += "".join(re.findall('[0-9\u4e00-\u9fa5]', para.text))
Здесь используются регулярные выражения для извлечения текста и чисел. Обратите особое внимание на то, что функция find находит элемент, а find_all возвращает список. re.find_all находит также список. При возврате необходимо использовать "".join для объединения его в строку. Фактически, нижний уровень BeautifulSoup — это регулярные выражения, поэтому функции-члены также схожи.