Описание проблемы:
Возникает ошибка при использовании yolov5 для обучения набора данных, который я сделал.Предыстория
:
Набор данных представляет собой набор данных формата yolo, сделанный мной.Картинка большая и не была изменена.Разрешение 4000*3000 Можно предположить, что в наборе данных появляется вопрос
Поиск сообщений об ошибках в Интернете:
Решение первое:
img = Image.open(путь_изображения) 改为
img = Image.open(путь_изображения).convert('RGB')。
Решение второе:
问题1::RuntimeError: Рабочий процесс DataLoader (pid XXX) завершается сигналом: ошибка шины
причины проблемы:
Как правило, такая проблема возникает в докере, поскольку по умолчанию общая память докера составляет 64 МБ, при большом количестве воркеров места не хватает, и возникает ошибка.
Решение:
1. Саморазрушительные боевые искусства
- будет
num_workersустановлено на 0
2. Решить проблему
Настройте большую общую память при создании докера, добавьте параметры --shm-size="15g"и установите общую память 15g (установите в соответствии с реальной ситуацией):
nvidia-docker run -it --name [container_name] --shm-size="15g" ...
- просмотрев
df -h_
дф-ч
# df -h
Filesystem Size Used Avail Use% Mounted on
overlay 3.6T 3.1T 317G 91% /
tmpfs 64M 0 64M 0% /dev
tmpfs 63G 0 63G 0% /sys/fs/cgroup
/dev/sdb1 3.6T 3.1T 317G 91% /workspace/tmp
shm 15G 8.1G 7.0G 54% /dev/shm
tmpfs 63G 12K 63G 1% /proc/driver/nvidia
/dev/sda1 219G 170G 39G 82% /usr/bin/nvidia-smi
udev 63G 0 63G 0% /dev/nvidia3
tmpfs 63G 0 63G 0% /proc/acpi
tmpfs 63G 0 63G 0% /proc/scsi
tmpfs 63G 0 63G 0% /sys/firmware
- Где shm — разделяемое пространство памяти
问题2 RuntimeError: Рабочий процесс DataLoader (pid(s) ****) неожиданно завершился
причины проблемы:
Поскольку загрузчик данных использует многопоточные операции, если в программе есть другие многопоточные операции с некоторыми проблемами, это может привести к тому, что потоки будут вложены друг в друга, что может привести к взаимоблокировкам.
решение:
1. Самопроигрышные боевые искусства
будут num_workersустановлены на 0
2. Решить проблему
__getitem__Отключите многопоточность opencv в методе загрузчика данных :
def __getitem__(self, idx):
import cv2
cv2.setNumThreads(0)
Решение третье:
При инкапсуляции загрузчика данных последний оставшийся элемент меньше одного размера пакета! У встроенного даталоадера будет такое явление
.
batch_size_s = len(targets) #不足一个batch_size直接停止训练
if batch_size_s < BATCH_SIZE:
break
Решение четвертое:
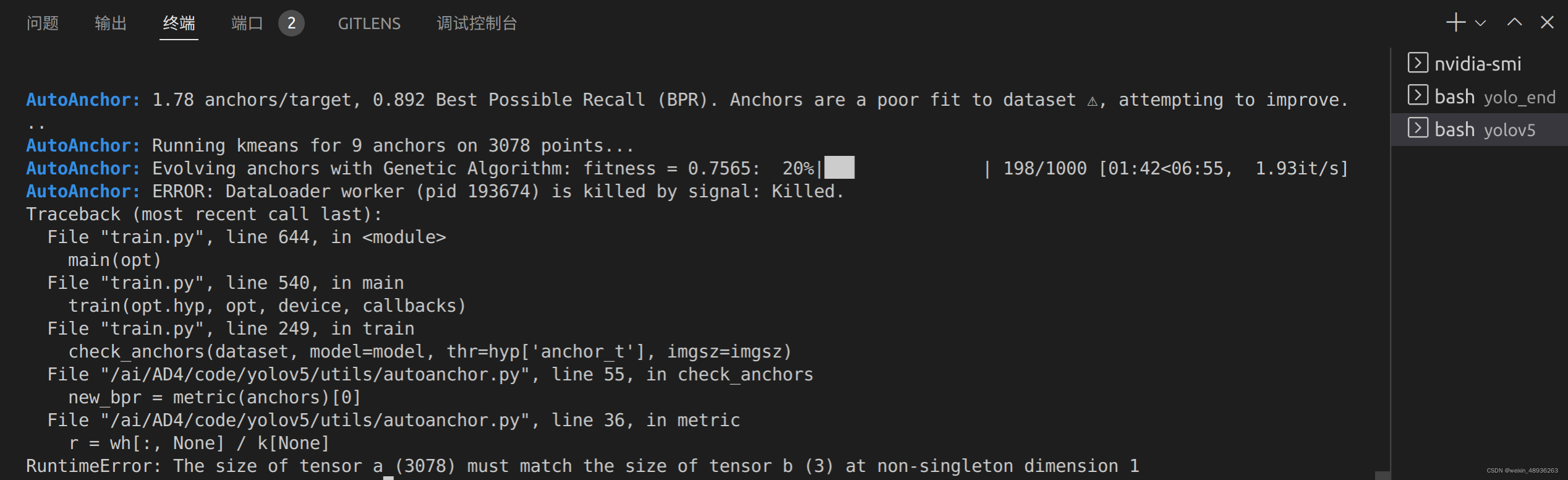
Прослеживая причину вверх, моя причина такова:
AutoAnchor: Running kmeans for 9 anchors on 3078 points...
AutoAnchor: Evolving anchors with Genetic Algorithm: fitness = 0.7565: 20%|██▉ | 198/1000 [01:42<06:55, 1.93it/s]
AutoAnchor: ERROR: DataLoader worker (pid 193674) is killed by signal: Killed.
Итак, непосредственно уменьшите партию до 32, а параметры обучения будут следующими:
python train.py --img 640 \
--batch 32 \
--epochs 300 \
--data /ai/AD4/code/yolov5/data/waterpipewire_yolo.yaml \
--weights /ai/AD4/code/yolov5/models/model/yolov5s.pt
Начать обучение!
Ссылки:
1. Ошибка загрузчика данных Pytorch «Рабочий DataLoader (pid xxx) убит сигналом». Решение
2. Ошибка выполнения: размер тензора a (128) должен соответствовать размеру тензора b (16) в неодноэлементном размере.