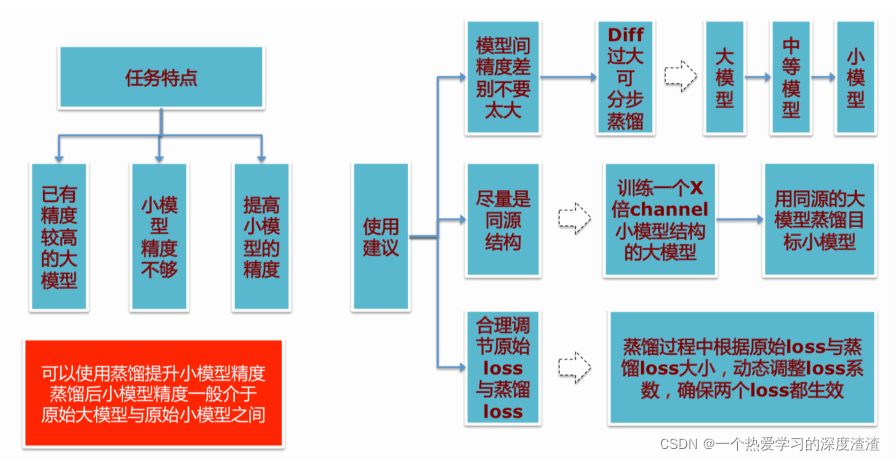
I. Обзор
Одним предложением : передать предсказательную силу сложной модели в меньшую сеть;
(сложные модели называются моделями учителей, меньшие модели называются моделями учеников)
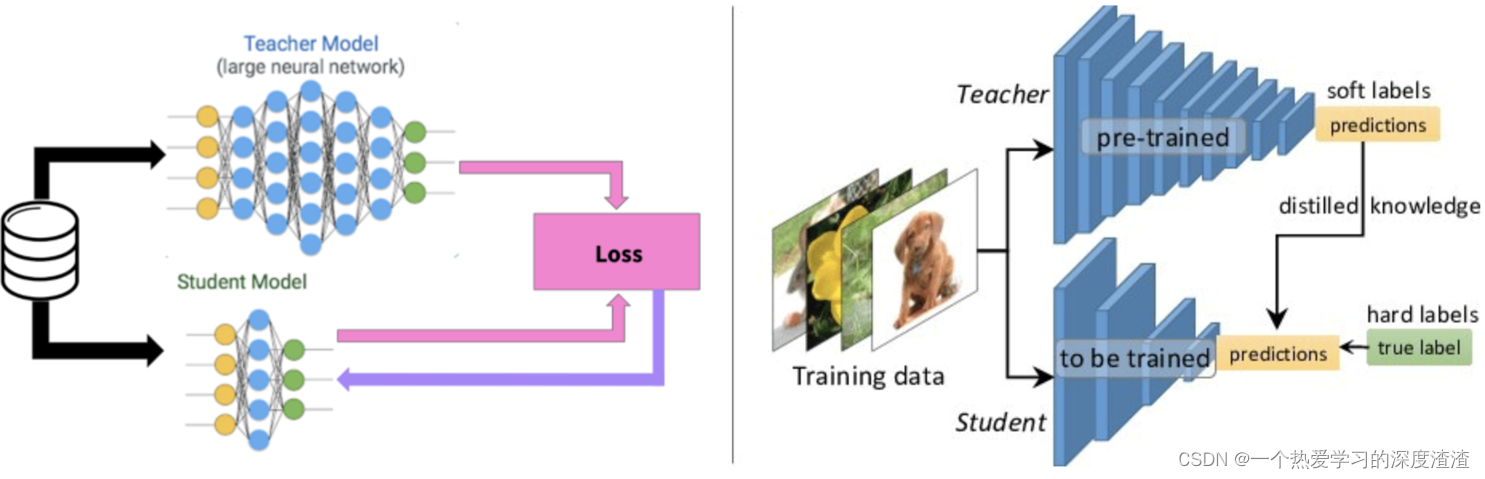
Концепция учителя и ученика:
- «Дистиллировать» знания, полученные большой сетью, и передать их в маленькую сеть, и производительность маленькой сети может быть близка к производительности большой сети;
- Модель дистилляции (ученик) обучена имитировать выходные данные большой сети (учитель), а не просто обучаться непосредственно на исходных данных Таким образом, небольшая сеть может изучить способность к абстрактным функциям и способность к обобщению большой сети. ;
Во-вторых, подробный процесс
метод первый
Простой процесс выглядит следующим образом:
1. Обучите сеть учителей на наборе данных;
2. Обучить студенческую сеть «имитировать» учительскую сеть;
3. Пусть маленькая сеть моделирует логиты большой сети (следуя объяснению);
Преимущества: Учитель может помочь отфильтровать некоторые шумовые метки.Для учащихся изучение непрерывного значения более эффективно, чем 0, 1 метки, а объем усвоенной информации больше;
Что означают логиты?
Использование вероятности, сгенерированной большой моделью, в качестве «мягкой цели» маленькой модели может передать способность большой модели к обобщению маленькой модели. На этом этапе передачи тот же обучающий набор или отдельный набор данных может использоваться для обучить большую модель;
Когда энтропия мягкой цели высока, она может предоставить больше информации и меньшую дисперсию градиента, чем жесткие цели во время обучения, поэтому небольшие модели обычно могут использовать меньшее количество обучающих выборок и более высокие скорости обучения;
Примечание . Мягкая цель здесь представляет определенное значение вероятности, а вывод значений 0 и 1 обычно называется жесткой целью;
Рассмотрим схему тренировочного процесса:
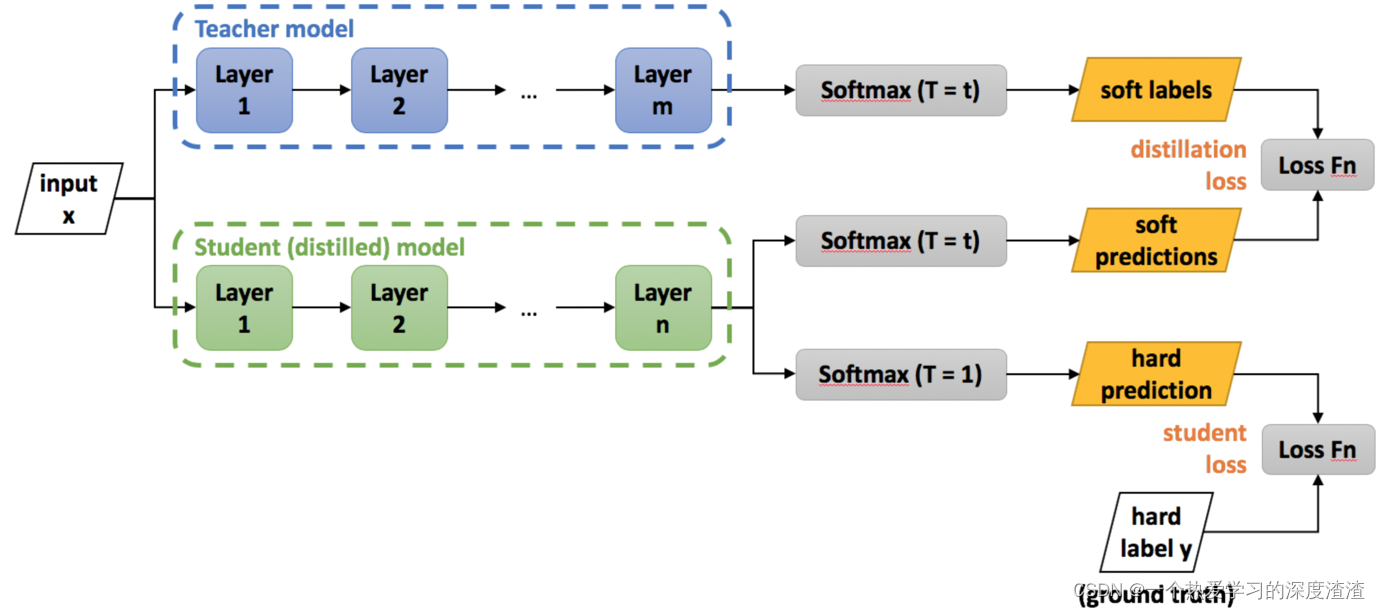
проиллюстрировать:
1. Выход сети учителя используется как программная метка сети ученика, то есть программная метка, а выходное значение является непрерывным значением;
2. Выход студенческой сети имеет две ветви: одна — это мягкие прогнозы, а другая — жесткие прогнозы, где «жесткий» означает жесткую метку, а выходное значение находится в горячей форме;
3. Окончательная потеря - это результат студенческой сети, программных меток сети учителя и фактических жестких меток для расчета значения потери и, наконец, объединения двух значений потерь;
Трюк про софтмакс:
Для задачи дистилляции знаний улучшена формула выходной функции softmax;
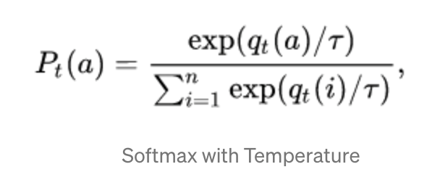
Объяснение: добавляется весовая переменная T. При большом T вероятность всех категорий почти одинакова, а вероятность будет мягче. При малом T вероятность категории с наибольшим ожидаемым вознаграждением приближается к 1; процесс дистилляции. Увеличивайте значение T до тех пор, пока модель учителя не создаст подходящий набор мягких целей, а затем используйте то же значение T для сопоставления этих мягких целей при обучении модели ученика;
На рисунке ниже приведен практический пример:

Способ второй
Фитнеты:
Принцип: учащийся использует информацию промежуточного скрытого уровня от учителя, чтобы добиться лучших результатов;
FitNets - это студенческая сеть, более узкая, но более глубокая, чем сеть учителей, добавляющая к студенческой сети «уровень руководства», то есть обучение на скрытом уровне в сети учителей;
Давайте посмотрим на эффект эксперимента:

3. Анализ состояния
1. Исследования по дистилляции знаний стали обширными и специфичными в некоторых областях, так что трудно оценить обобщающую эффективность метода;
2. В отличие от других методов сжатия моделей, дистилляция не обязательно должна иметь структуру, аналогичную исходной сети, что также означает, что извлечение знаний является очень гибким и теоретически может быть адаптировано к широкому кругу задач;
Анализ преимуществ и недостатков:
Преимущества: при наличии хорошо обученной сети учителей требуется меньше обучающих данных для обучения небольшой сети учеников, и чем меньше сеть, тем выше скорость; нет необходимости поддерживать структурное единство между сетями учителей и учеников;
Недостатки: при отсутствии предварительно обученной сети учителей требуется больший набор данных и больше времени для перегонки;
4. Кодовый регистр
Прежде всего, мы сначала вычисляем среднее значение и дисперсию набора данных, что также является значением, часто используемым в Normal;
Пример кода:
def get_mean_and_std(dataset):
"""计算数据集(训练集)的均值和标准差"""
dataloader = torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=True, num_workers=2)
# 创建两个矩阵保存均值和标准差
mean = torch.zeros(3)
std = torch.zeros(3)
print('==> Computing mean and std..')
for inputs, targets in dataloader:
# 这里要注意是三个通道,所以要遍历三次
for i in range(3):
mean[i] += inputs[:, i, :, :].mean()
std[i] += inputs[:, i, :, :].std()
# 最后用得到的总和除以数据集数量即可
mean.div_(len(dataset))
std.div_(len(dataset))
return mean, std
Ниже приведен простой пример дистилляции знаний;
фон:
модель учителя: VGG16;
Студенческая модель: пользовательская модель, которая уменьшает количество слоев по сравнению с VGG16;
Набор данных: набор данных cifar10;
Этапы загрузки двух моделей в процессе дистилляции здесь не показаны, в частности, в определении функции потерь:
# 默认交叉熵损失
def _make_criterion(alpha=0.5, T=4.0, mode='cse'):
# targets为teacher网络的输出,labels为student网络的输出
def criterion(outputs, targets, labels):
# 根据传入模式用不同的损失函数
if mode == 'cse':
_p = F.log_softmax(outputs/T, dim=1)
_q = F.softmax(targets/T, dim=1)
_soft_loss = -torch.mean(torch.sum(_q * _p, dim=1))
elif mode == 'mse':
_p = F.softmax(outputs/T, dim=1)
_q = F.softmax(targets/T, dim=1)
_soft_loss = nn.MSELoss()(_p, _q) / 2
else:
raise NotImplementedError()
# 还原原始的soft_loss
_soft_loss = _soft_loss * T * T
# 用softmax交叉熵计算hard的loss值
_hard_loss = F.cross_entropy(outputs, labels)
# 将soft的loss值和hard的loss值加权相加
loss = alpha * _soft_loss + (1. - alpha) * _hard_loss
return loss
return criterion
Приведенный выше код является наиболее важной частью дистилляции знаний.
5. Расширение
Вы можете обратиться к сводным статьям по дистилляции знаний за последние годы :
Подведем итог
Несколько советов по использованию дистилляции знаний: