Автор: Модель больших данных
Эта статья взята из мероприятия по подаче эссе «Используйте TDengine, напишите TDengine» 2022 года.
В связи с работой в последние годы я сталкивался с различными отечественными базами данных, но не могу забыть TDengine. Среди многих баз данных выделяется TiDB, OceanBase происходит из известного семейства, openGauss поддерживается Huawei, и только TDengine дает людям ощущение себя героем. на postgreSQL 9.2.4.Даже OceanBase был построен на основе внутренних требований приложения, только TDengine был разработан самостоятельно, без использования какого-либо программного обеспечения с открытым исходным кодом или стороннего программного обеспечения. Кроме того, это не база данных общего назначения, у нее есть свои уникальные сценарии социального применения, в основном обслуживающие промышленную сеть.
Основываясь на определении и понимании TDengine, автор подробно расскажет, какие проблемы может решить TDengine, его преимущества и особенности, а также его отличия от других баз данных в этой статье, надеясь помочь тем, кто интересуется TDengine buddy.
«В отличие от баз данных общего назначения, TDengine выбрасывает бесполезный багаж»
Если база данных хочет добиться отличного чтения и записи, основной возможностью является индексация.Как правило, продукты баз данных имеют возможности прямого индексирования. Так называемый прямой индекс заключается в использовании идентификаторов в записях документа в качестве ключевых слов, и идентификаторам ключей больше не нужно сканировать весь диск. Хотя существуют различия между индексом B-дерева, хэш-индексом и индексом растрового изображения, общее направление принадлежит прямому индексу.
В дополнение к прямому индексу существует также обратный индекс [также известный как инвертированный индекс].Обратный индекс в основном используется для полнотекстового поиска, такого как ElasticSearch, и большинство баз данных являются прямыми индексами. TDengine также использует прямой индекс, особенностью которого является то, что идентификатор должен содержать метку времени, а также данные индикатора измерения, чтобы сформировать четкое описание значения данных — каково значение данных определенного объекта индикатора в определенное время.
С точки зрения механизма хранения организации данных нижний уровень базы данных можно разделить на механизм B-дерева и механизм LSM, Эти два механизма не самые лучшие, и у каждого есть свои преимущества и недостатки:
Самое большое преимущество B-дерева заключается в его способности непрерывно увеличивать производительность чтения данных, даже если уровень данных увеличивается, их чтение не увеличивается. Секрет заключается в предельном постоянном хранении данных, B-дерево хранится на жестком диске в упорядоченной и регулярной структуре данных . Таким образом, по мере того, как данные становятся все больше и больше, они по-прежнему сохраняют упорядоченную и регулярную функцию Столкнувшись с тысячами операций чтения, они могут выполняться в соответствии с условиями, уменьшая или избегая поведения увеличения чтения.
В отличие от механизма B-дерева, механизм LSM уменьшает и избегает усиления записи. Механизм LSM полностью использует память, открывает пространство в памяти, сначала записывает данные в память, записывает и напрямую возвращает успех пользователя, вместо того, чтобы писать один как дерево B, я хочу узнать, кто старше меня и кто больше меня Маленький, пока достаточно памяти, просто залейте его прямо в память.Когда память достигает определенного порога, данные в памяти будут записываться на жесткий диск партиями и последовательно за один раз, и память будет сброшена и очищена для обслуживания новых запросов записи .
Традиционные базы данных MySQL и Oracle используют механизм B-дерева, в то время как TiDB и OceanBae используют оптимизированный механизм LSM, тогда как TDengine использует механизм B-дерева + LSM, где B-дерево хранит метаданные [в основном данные штампа времени + индекса], Механизм LSM хранит определенные данные, метаданные хранятся в упорядоченной структуре таблицы, а определенные данные записываются в виде добавления, что позволяет избежать больших операций чтения и записи.
Вообще говоря, чтобы улучшить производительность управления параллелизмом, продукты OLTP должны иметь функции копирования при записи или MVCC.Хотя копирование при записи и MVCC гарантируют согласованность данных, они увеличивают нагрузку на операции ввода-вывода . TDengine не нужно изменять данные, поэтому нет необходимости рассматривать проблему согласованности данных.Данные записываются в упорядоченной и дополненной форме.Поскольку есть только чтение и запись, нет необходимости в защите от блокировки, и некоторые бесполезные элементы выбрасываются.Бремя, вы можете сосредоточиться на оптимизации других мест, таких как столбцовые таблицы.
Общие базы данных в отрасли содержат таблицы на основе строк, таблицы на основе столбцов и даже полные библиотеки памяти для различных предприятий.Для хранения конкретных данных TDengine использует полное хранилище на основе столбцов на жестком диске, а индикаторы измерений хранятся в строках. на основе памяти . Поскольку TDengine сталкивается с данными машины, машина работает 24 часа, чтобы производить данные каждую миллисекунду.Чтобы хранить больше данных, TDengine использует метод сосуществования строк и столбцов и разделения целей.
Вообще говоря, документальные записи каждой строки в базе данных очень важны, даже если информация, записанная в этой строке, не имеет ничего общего с транзакциями, а является лишь базовой информацией пользователя, ее плотность значений очень высока. Но база данных временных рядов (база данных временных рядов) отличается.Плотность значений однострочных записей документа низкая, поскольку за одну секунду может быть сгенерировано 10 000 записей, и данные должны быть агрегированы, чтобы отразить значение данных. Быстро и эффективно агрегируйте обычные данные, чтобы превратить их в данные с высокой плотностью значений, что также является важной особенностью, отличающей базы данных временных рядов от других баз данных.
В настоящее время TDengine предоставляет три версии продуктов: версию для сообщества, корпоративную версию и облачную версию для удовлетворения потребностей рынка и индивидуальных разработчиков.
«Демонтаж базы данных временных рядов, анализ нескольких основных характеристик продукта»
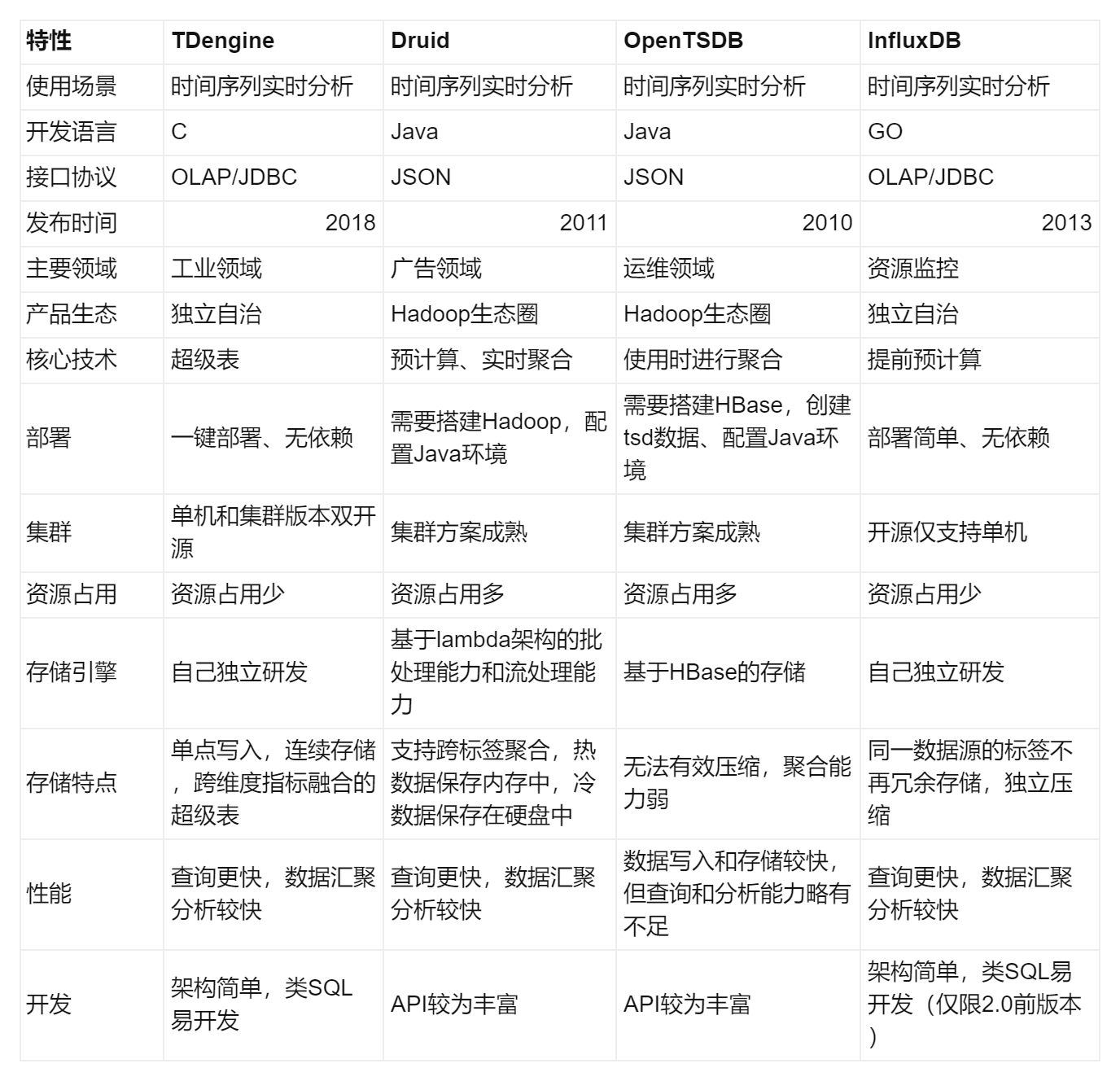
Технически TDengine представляет собой распределенную платформу для анализа массивных данных, ориентированную на область временных рядов. Его конкурентов можно разделить на прямых конкурентов и косвенных конкурентов.К косвенным конкурентам относятся отечественные TiDB, OceanBase, GaussDB и зарубежные Oracle, MySQL и т. д. Хотя они не сравниваются с TDengine с точки зрения комплексной технологии, анализ используется и имеет связь с временными рядами, вот где TDengine пригодится. Конкуренты, которые напрямую конкурируют с TDengine, включают Druid, OpenTSDB и InfluxDB, все из которых являются предшественниками анализа временных рядов.
Druid — это распределенная система, использующая архитектуру Lambda, которая способствует полному использованию памяти, а также сохраняет исторические данные на жесткий диск, агрегирует данные в соответствии с определенной степенью детализации по времени и разделяет обработку данных в реальном времени и пакетную обработку данных. . Обработка в реальном времени предназначена для сценариев с большим количеством операций записи и меньшим количеством операций чтения и в основном обрабатывает добавочные данные в потоковом режиме. Druid опирается на Hadoop.В кластере принята архитектура "без совместного использования".Каждый узел имеет свои собственные вычислительные мощности и возможности хранения.Вся система координируется через Zookeeper. Для повышения производительности вычислений будут использоваться приблизительные методы вычислений, включая HyperLoglog, некоторые базовые расчеты DataSketch.
OpenTSDB — это база данных временных рядов с открытым исходным кодом, которая поддерживает хранение сотен миллиардов точек данных и предоставляет точные запросы. Она написана на языке Java и обеспечивает горизонтальное расширение за счет хранилища на основе HBase. OpenTSDB широко используется для мониторинга и измерения серверов, в том числе сеть и мониторинг в реальном времени серверов, датчиков, IoT и финансовых данных. Идея дизайна OpenTSDB состоит в том, чтобы использовать ключ HBase для хранения некоторой информации о тегах и хранить данные за один и тот же час в одной строке, чтобы повысить скорость запроса. OpenTSDB предварительно определяет теги измерений и т. д. и помещает их в HBase в сложной форме организации данных. Быстрые запросы можно выполнять с помощью keyRange HBase. Однако эффективность OpenTSDB будет снижаться при организации запросов любого измерения.
InfluxDB — очень популярная база данных временных рядов, разработанная на языке Go, сообщество очень активно, технические функции поддерживают любое количество столбцов, удаление шаблонов, интегрированный сбор данных, хранение и визуальное хранение, а также использует алгоритмы с высокой степенью сжатия для поддержки эффективное хранилище, принимает внутренний механизм хранения TIME SERIES MERGE TREE и поддерживает языки, подобные SQL (версия 2.0 больше не поддерживает его) .
Для бизнес-фона временных рядов предварительное агрегирование обычно выполняется в сценариях OLAP для уменьшения объема данных Основные факторы, влияющие на предварительное агрегирование, можно резюмировать следующим образом:
Количество показателей измерения
Количество метрик измерения
Степень комбинации показателей размерности
Крупнозернистые и детализированные метрики измерения времени
Для достижения эффективной предварительной агрегации секретом TDengine является супертаблица.Druid заранее определит предварительные вычисления.InfluxDB также имеет собственный метод непрерывных запросов, который сращивается только при использовании HBase.Поэтому HBase будет медленнее, если он включает в себя разные запросы индекса измерения.
Понятно, что отчет о тестировании TDengine на основе TSBS будет выпущен в ближайшем будущем.В первом отчете проводится подробный сравнительный анализ уровня производительности InfluxDB и TimeScaleDB.Заинтересованные партнеры могут в последнее время уделять больше внимания содержанию официальной учетной записи.
«Сегодня TDengine должен быть первым выбором»
Мое знание и понимание TDengine начинается с прошлого проектного опыта.Опираясь на 2018 год, я расскажу вам историю о предсказании плохих и неисправных деталей в отрасли.
При быстром росте бизнеса компании и постоянном увеличении количества новых заводов в известной группе все виды ценных данных не могут быть хорошо интегрированы, проанализированы и извлечены по их должной ценности. В это время развитие компании вступило в очередной виток «боевой» стратегии. Оперативное реагирование и точный прогноз являются ключом к развитию бизнеса. Ключевую роль в нем играют большие данные. Для интеграции данных из различных систем используются методы научного анализа и продвигать фабричный производственный интеллект.Развитие модернизации стало неотложной задачей.
В текущем производственном процессе на заводе возникла такая же особая проблема со стеклом.Качество стекла неравномерно по разным причинам, и может быть даже стекло ненадлежащего качества. В процессе обнаружения этих аномальных стекол невозможно определить причину аномалии.Если причина аномалии не может быть быстро обнаружена, будет вызвано больше аномальных стекол, что серьезно повлияет на производство. Конкретные средства реагирования включают:
Через стекло с аномальным качеством найдите коэффициент корреляции, вызывающий эту аномалию. Такие как: машины, материалы, транспортные средства, параметры и т.д.
Обнаружение аномального стекла и раннее предупреждение с помощью математического моделирования факторов, которые приводят к аномальному качеству, позволяет прогнозировать аномальное стекло, которое отклоняется от нормального диапазона, и заблаговременно предупреждать.
分析 glass 的特征值与特征值之间的关联关系,并建立预测模型,提前预测出 glass 的特征值。
分析 glass 相关的电压、电阻、电流、温度、湿度影响。
很明显这是数据挖掘的项目,要分析以上 glass 在生产过程中的环境信息、检测机台资料、量测机台资料、制程参数信息,以及 FDC、OEE 系统的数据,才能找出产生这种问题的原因。第一步是数据收集整合,第二步是数据探索,第三步是模型调校——找出可能性、影响最大的因素的特征因素,第四步是投入生产验证,通过 spark ml 提供预测动力。
当时的技术栈用的是 CDH,首先要通过 Kafka 采集数据,Spark对接 Kafka 进行初步计算去噪并汇总到 Hadoop 里面,以 parquet 的格式保存,如果需要进一步的加工,就通过 impala 进行。这样每天挂起 N 个任务,不停的调度计算。
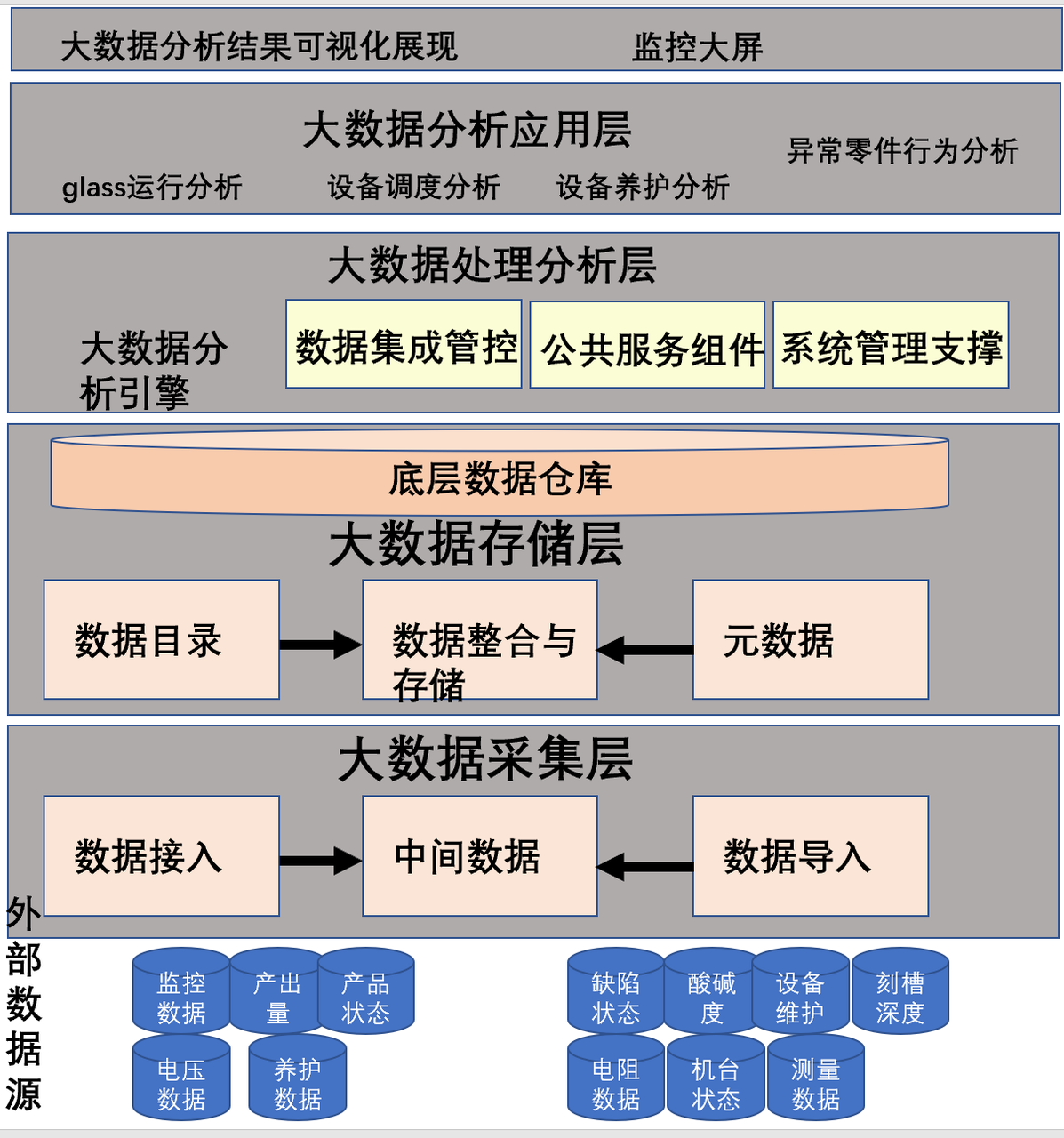
CDH Hadoop 虽然无法做到实时数据分析,但是也还能做些事,聊胜于无,就继续用着。当时这个坏件故障件预测项目有以下痛点,主要是及时性、有效性、准确性的问题:
难以满足用户需求,某些机器数据的聚合计算需要第二天才能出结果,甚至更多的时间才能出来。
经济成本的费用较高,CPU、磁盘、网络都在一个高段的使用状态,针对越来越多的数据需要投入新机器。
维护成本高,你需要维护 Hadoop 所有的机器,各种 HBase、Spark、Zookeeper、HDFS 之类,不但对工程师要求高,而且工作量巨大。
低质量数据,因为数据流程或者错误的逻辑整合,导致机器传感器聚合后数据模型无法正常使用。
无法做到实时监测,机器数据作为宝贵的自变量因素无法及时传输并进行计算,自然会影响因变量。
笔者经历了这个项目,知道这个坏件故障预测与时间序列有紧密的关系。时至今日,时间序列分析也是重要的数据分析技术,尤其面对季节性、周期性变化数据时,传统的回归拟合技术难以奏效,这时就需要复杂的时间序列模型,以时间为特征作为抓手点。这样即使你不太懂业务的前提下,也可以进行数据挖掘的工作。
那这个项目与 TDengine 有什么关系呢? 实际上,这个项目并没有用上 TDengine,后来集团搭建了一个 Hadoop集群试点,这次居然用了 HDP,理由很简单,因为 HDP 默认搭载了时序数据库 Druid。
当时技术负责人认为坏件故障预测模型的数据库基座应该是时序数据库,而不是 Hadoop 不停的进行数据采集、数据转换以及各种批计算,通过时序数据库不但可以实时计算,而且输出的数据质量高。至于选择哪个时序数据库,彼时考虑平稳过渡替换以及学习成本综合因素后他们选择了 Druid。
但当时是 2017 年,TDengine 也还没有面世,如果放到今天,TDengine 必定是选型考虑的首选。
要知道,TDengine 的优势相对 Druid 要多了去了,首先 Druid 不是一个经过开源版本 1.00 正式发布的软件,虽然发展多年,直至 HDP 与 CDH 两家公司融合,HDP 搭配的 Druid 也不是 1.00 版;其次 Druid 依赖 Hadoop,动辄就使用大量的资源以及各种复杂的 Hadoop 组件,最后 Druid 只提供 json 的方式,对传统的 DBA 使用十分不友好。
TDengine 有一个我认为很秀的功能,就是它的超级表的跨指标维度建模思想,目前它仅用于自由组合维度指标,拼接不同的时间粒度进行聚合。在我看来,将来应用于时间序列机器学习模型也会是它的一个亮点,在数据建模方面,针对工厂的设施、设备、机床、机房、车间、测台等必须要做高效准确的定义。我们进行项目规划建设时,都会做大量的数据治理工作,但是在具体实施工作上,还是要使用这些传统工具和技术。TDengine 可以有效汇集各种机器数据源,并且能够高质量的提炼,这个是过去的时序数据产品所不具备的。
“是提速,更是赋能”
中国有句话叫做“长江后浪推前浪,一代新人胜旧人”,IT 世界千变万化,如果你和我一样,一直在关注着 TDengine,就会发现,它这几年崛起的非常迅速。去年 TDengine 推出 3.0 版本,新版本升级成为了一款真正的云原生时序数据库,优化了流计算功能,而且还重新设计了计算引擎,优化工程师对 SQL 的使用,另外增加了 taosX,利用自己的数据订阅功能来解决增量备份、异地容灾,更加方便了企业应用。我对 TDengine 未来的期望是,希望它增加库内机器学习函数,增加 ARIMA 模型、MA 模型等时间相关功能,TDengine 的未来是一个智能学习时间序列数据库,对工业 4. 0 来说不仅是提速,更是赋能。
想了解更多TDengine Database的具体细节,欢迎大家在GitHub上查看相关源代码。