13. MapReduce 프레임워크의 원리
13.3셔플 메커니즘
13.3.2파티션 파티션
13.3.2.3 사용자 정의 파티셔너 단계
13.3.2.3.1 사용자 정의 클래스는 Partitioner를 상속하고 getPartition() 메서드를 재정의합니다.
public class CustomPartitioner extends Partitioner<Text, FlowBean> {
@Override
public int getPartition(Text key, FlowBean value, int numPartitions) {
// 控制分区代码逻辑
… …
return partition;
}
}
13.3.2.3.2 작업 드라이버에서 사용자 정의 파티셔너 설정
job.setPartitionerClass(CustomPartitioner.class);
13.3.2.3.3 Partition을 커스터마이즈한 후, 커스텀 Partitioner의 로직에 따라 해당하는 ReduceTask 수를 설정한다.
job.setNumReduceTasks(5);
13.3.2.4 파티션 요약
(1) ReduceTasks의 개수 > getPartition의 결과 개수인 경우 몇 개의 빈 출력 파일 part-r-000xx가 더 생성될 것입니다.
(2) 1 < ReduceTasks의 개수 < getPartition의 결과 개수인 경우 일부 파티션 (3) ReduceTask의 개수가
1인 경우 MapTask 측에서 출력되는 파티션 파일의 수와 상관없이 최종 결과는 이 ReduceTask에 전달되며 결과 파일은 part-r-
(4) 파티션 번호는 0부터 시작하여 하나씩 누적되어야 합니다 .
13.3.2.5 사례 연구
예: 사용자 정의 파티션 수가 5개라고 가정하면
(1) job.setNumReduceTasks(1);가 정상적으로 실행되지만 출력 파일이 생성됩니다
(2) job.setNumReduceTasks(2); 오류를 보고합니다
(3 ) job.setNumReduceTasks(6), 5보다 크면 프로그램이 정상적으로 실행되고 빈 파일이 생성됩니다.
13.3.3 파티션 파티션 사례 실습
13.3.3.1 요구 사항
휴대폰이 속한 지역에 따라 통계 결과를 다른 파일(구분)로 출력
(1) 데이터 입력
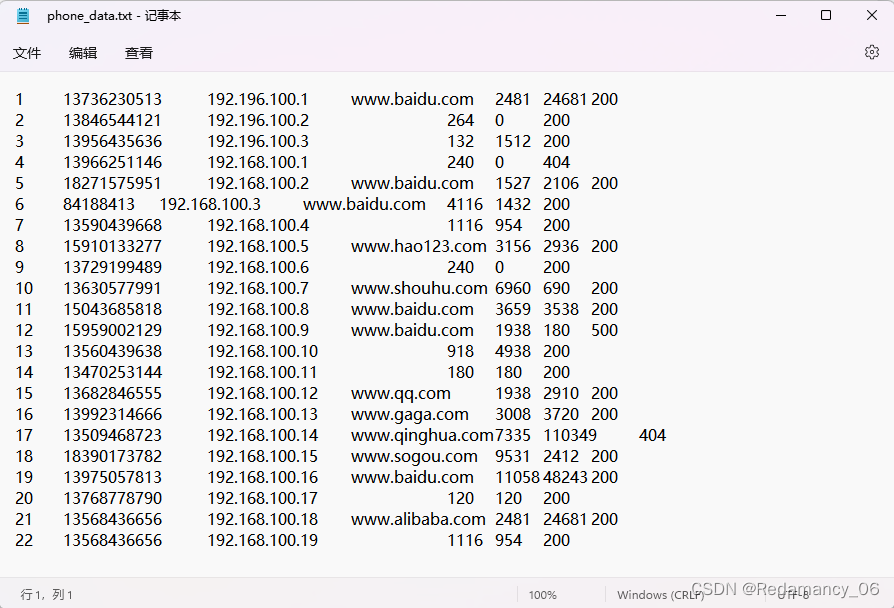
1 13736230513 192.196.100.1 www.baidu.com 2481 24681 200
2 13846544121 192.196.100.2 264 0 200
3 13956435636 192.196.100.3 132 1512 200
4 13966251146 192.168.100.1 240 0 404
5 18271575951 192.168.100.2 www.baidu.com 1527 2106 200
6 84188413 192.168.100.3 www.baidu.com 4116 1432 200
7 13590439668 192.168.100.4 1116 954 200
8 15910133277 192.168.100.5 www.hao123.com 3156 2936 200
9 13729199489 192.168.100.6 240 0 200
10 13630577991 192.168.100.7 www.shouhu.com 6960 690 200
11 15043685818 192.168.100.8 www.baidu.com 3659 3538 200
12 15959002129 192.168.100.9 www.baidu.com 1938 180 500
13 13560439638 192.168.100.10 918 4938 200
14 13470253144 192.168.100.11 180 180 200
15 13682846555 192.168.100.12 www.qq.com 1938 2910 200
16 13992314666 192.168.100.13 www.gaga.com 3008 3720 200
17 13509468723 192.168.100.14 www.qinghua.com 7335 110349 404
18 18390173782 192.168.100.15 www.sogou.com 9531 2412 200
19 13975057813 192.168.100.16 www.baidu.com 11058 48243 200
20 13768778790 192.168.100.17 120 120 200
21 13568436656 192.168.100.18 www.alibaba.com 2481 24681 200
22 13568436656 192.168.100.19 1116 954 200
(2) 예상 출력 데이터
휴대폰 번호 136, 137, 138, 139는 모두 별도의 4개 파일에 배치되고 나머지는 하나의 파일에 배치됩니다.
13.3.3.2 요구사항 분석
1. 수요: 통계 결과를 휴대폰이 속한 지역에 따라 다른 파일(파티션)로 출력합니다.
2. 데이터 입력
13630577991 6960 690
13736230513 2481 24681
13846544121 264 0
13956435636 132
6912 13360439
3. 예상 데이터 출력
파일 1
파일 2
파일 3
파일 4
파일 5
4. ProvincePartitioner 파티션
136 파티션 0
137 파티션 1
138 파티션 2
139 파티션 3
기타 파티션 4 추가
5. 드라이버 드라이버 클래스
//사용자 지정 데이터 파티션 지정
job.setPartitionerClass(ProvincePartitioner.class);
//동시에 해당하는 reduceTask 수 지정
job.setNumReduceTasks (5);
13.3.3.3 파티션 파티션 사례 데모
 partitioner2 폴더를 만들고 쓰기 가능한 4개의 Java 코드를 동시에 partitioner2에 복사합니다.
partitioner2 폴더를 만들고 쓰기 가능한 4개의 Java 코드를 동시에 partitioner2에 복사합니다.
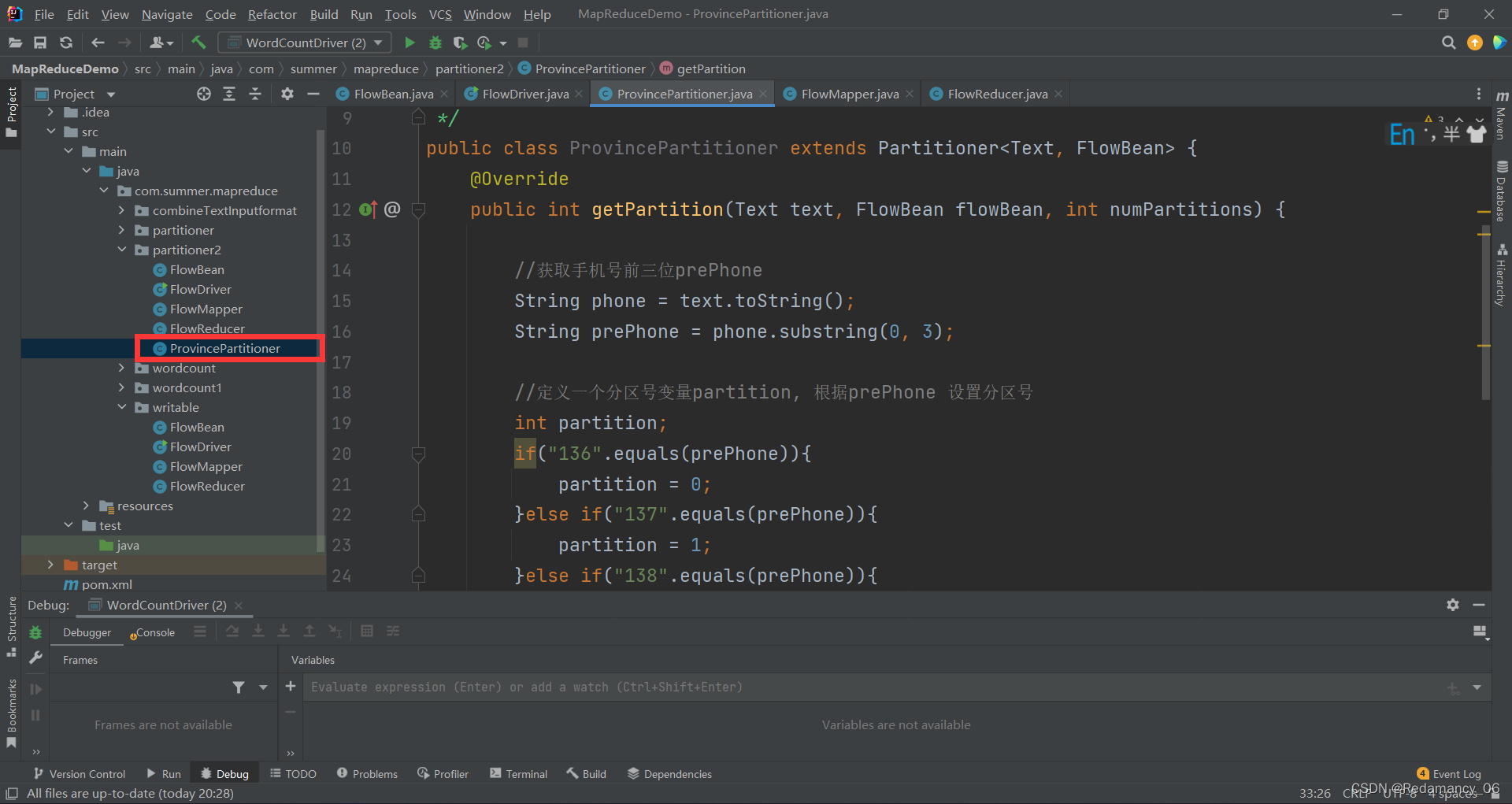
쓰기 가능한 경우를 기준으로 파티션 클래스를 추가합니다.
package com.summer.mapreduce.partitioner;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
public class ProvincePartitioner extends Partitioner<Text, FlowBean> {
@Override
public int getPartition(Text text, FlowBean flowBean, int numPartitions) {
//获取手机号前三位prePhone
String phone = text.toString();
String prePhone = phone.substring(0, 3);
//定义一个分区号变量partition,根据prePhone设置分区号
int partition;
if("136".equals(prePhone)){
partition = 0;
}else if("137".equals(prePhone)){
partition = 1;
}else if("138".equals(prePhone)){
partition = 2;
}else if("139".equals(prePhone)){
partition = 3;
}else {
partition = 4;
}
//最后返回分区号partition
return partition;
}
}

드라이버 기능에서 사용자 지정 데이터 파티션 설정 및 ReduceTask 설정 추가
package com.summer.mapreduce.partitioner;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class FlowDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//1 获取job对象
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
//2 关联本Driver类
job.setJarByClass(FlowDriver.class);
//3 关联Mapper和Reducer
job.setMapperClass(FlowMapper.class);
job.setReducerClass(FlowReducer.class);
//4 设置Map端输出数据的KV类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(FlowBean.class);
//5 设置程序最终输出的KV类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
//8 指定自定义分区器
job.setPartitionerClass(ProvincePartitioner.class);
//9 同时指定相应数量的ReduceTask
job.setNumReduceTasks(5);
//6 设置输入输出路径
FileInputFormat.setInputPaths(job, new Path("D:\\inputflow"));
FileOutputFormat.setOutputPath(job, new Path("D\\partitionout"));
//7 提交Job
boolean b = job.waitForCompletion(true);
System.exit(b ? 0 : 1);
}
}
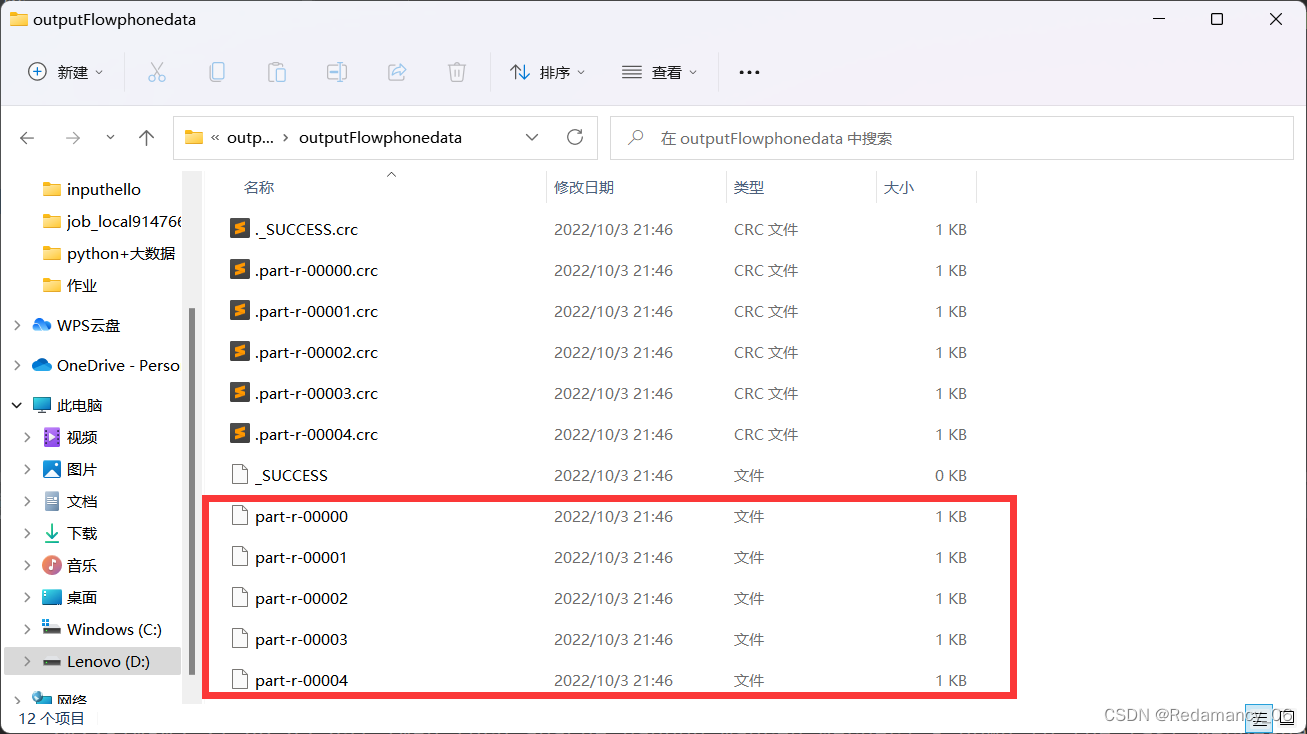
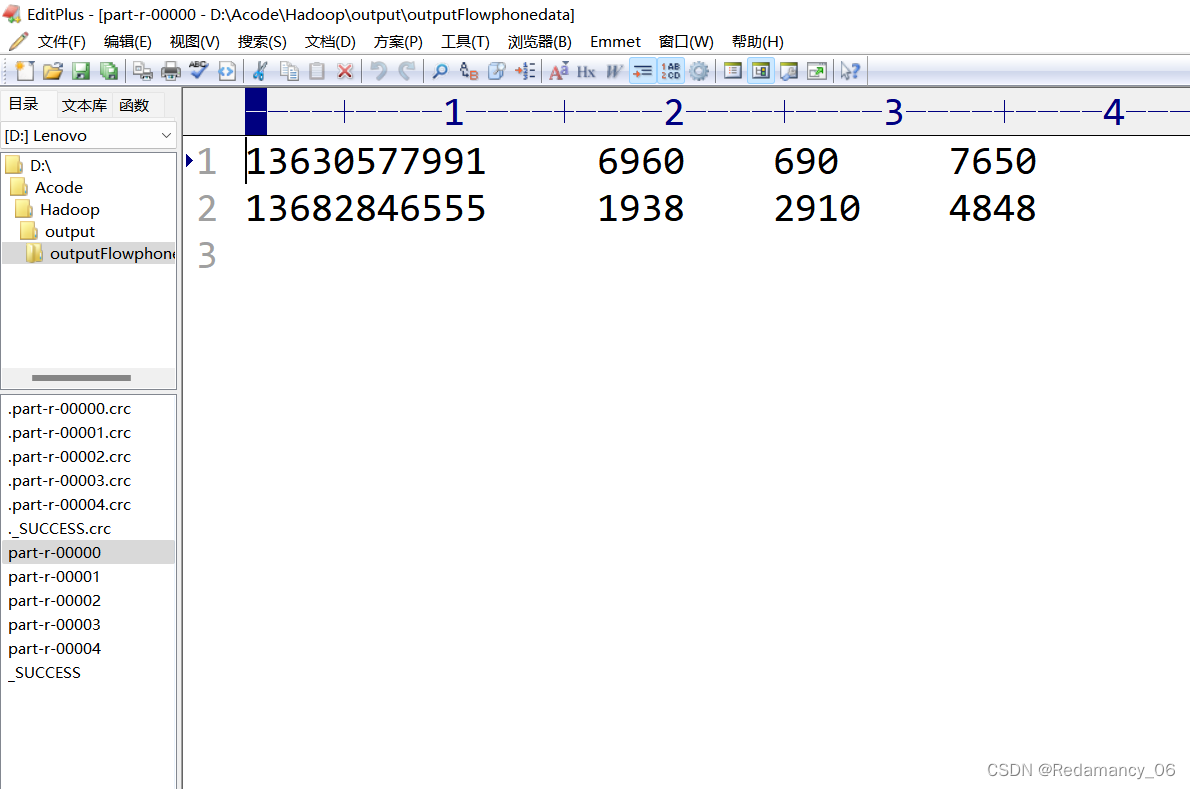
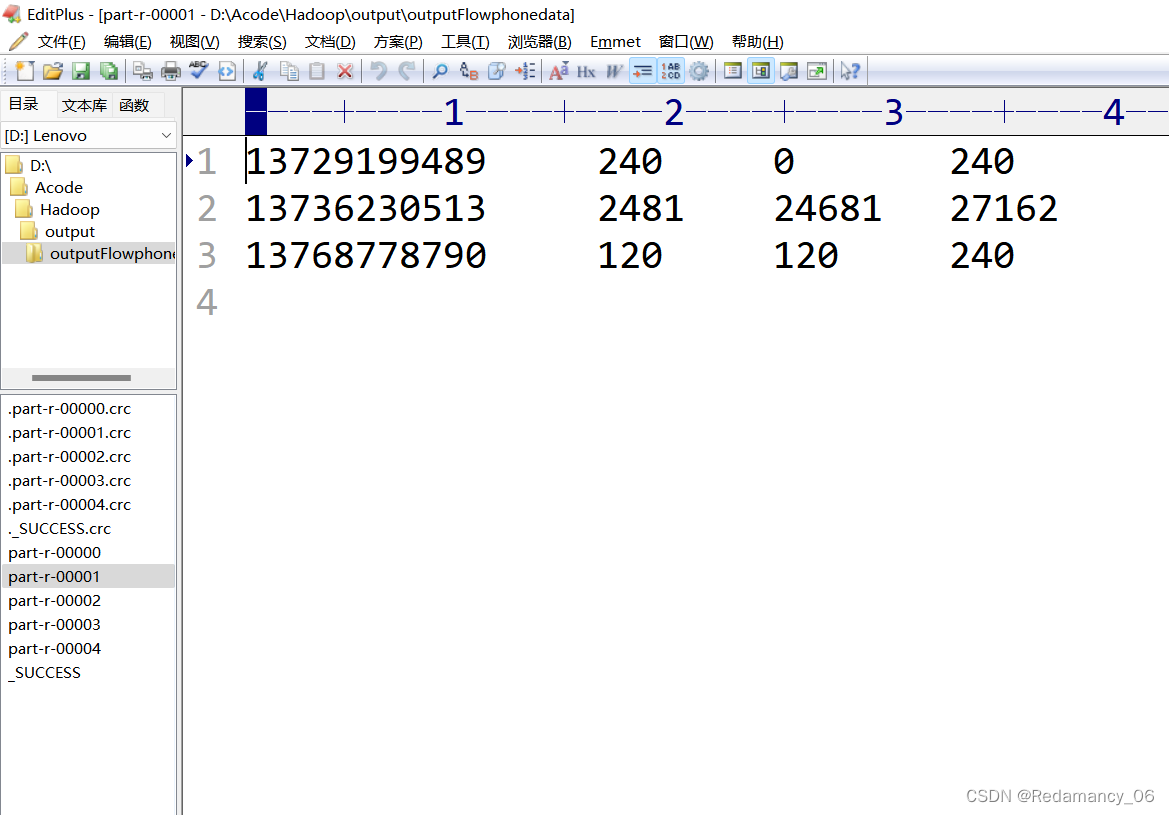
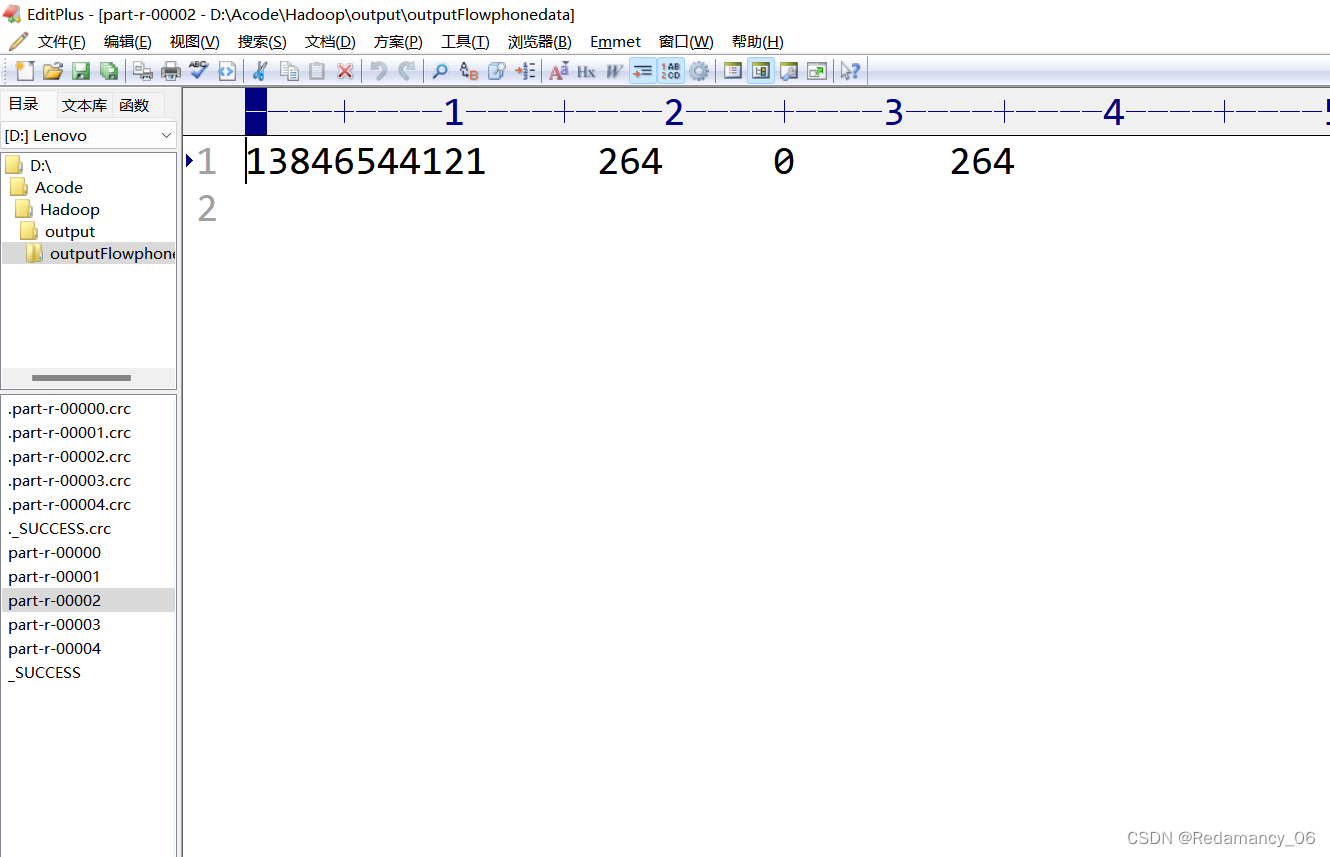
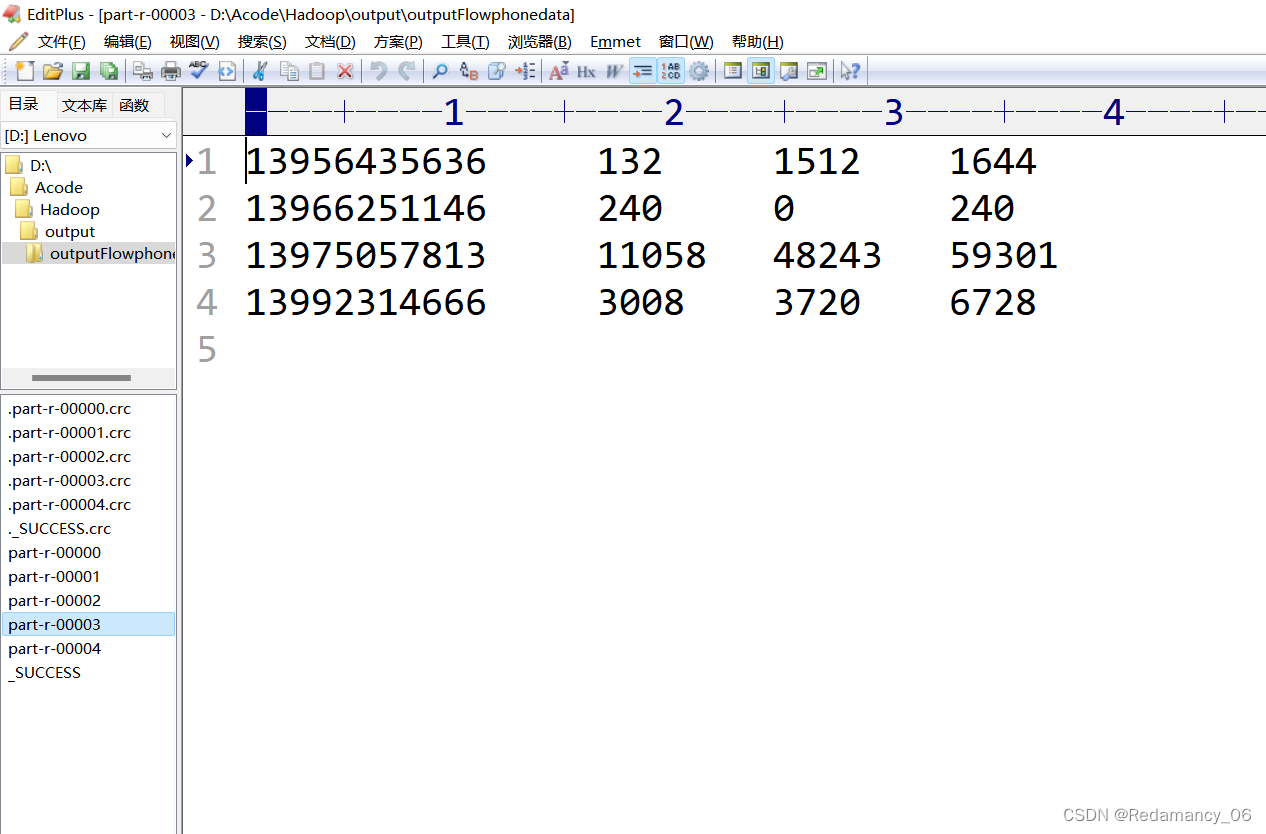
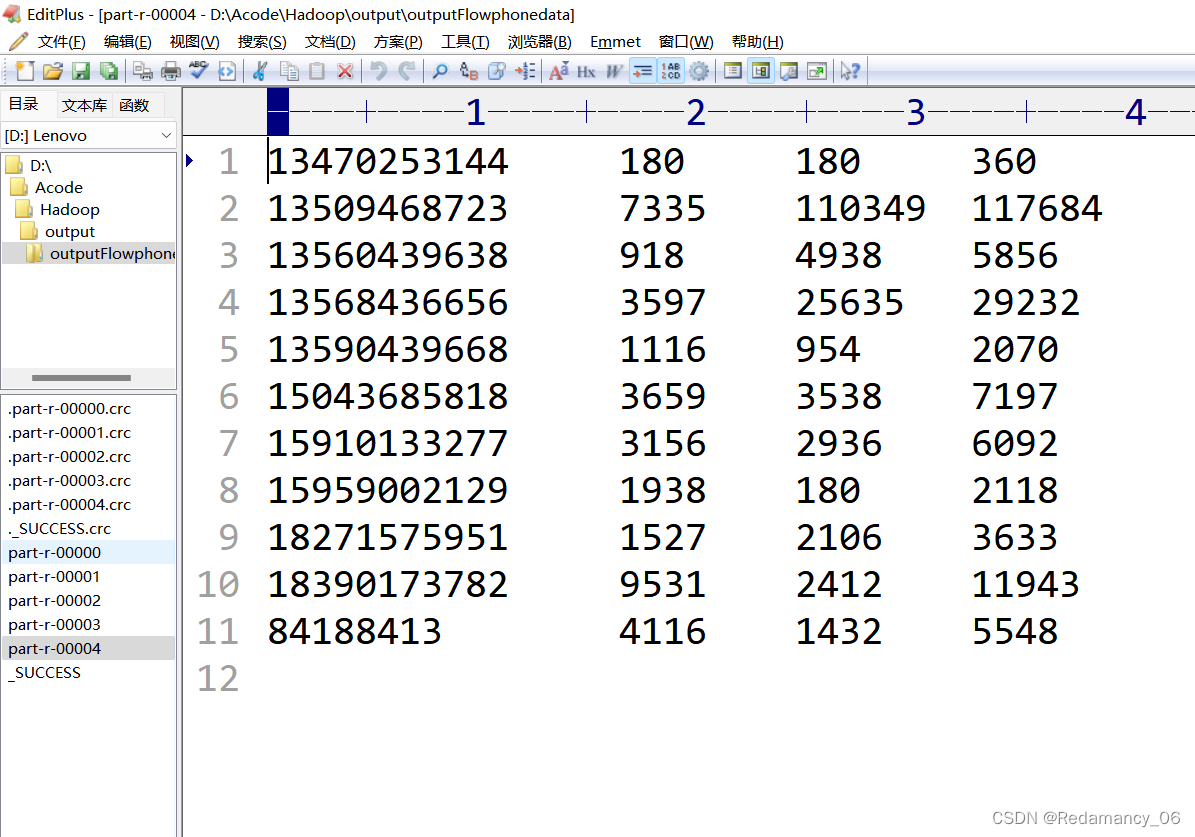
실행 후 예상대로 5개의 파티션이 완성되었습니다!