На лицевой стороне написано чушь:
Для плотоядных употребление мяса может быть непосильным занятием! Специально для мяса на гриле, наблюдения за тем, как куски мяса медленно готовятся, и прослушивания звука «зизи» на гриле, такого предвкушения не может вызвать ни одна другая еда. Если десерт «радует с первого взгляда», то мясо «не надоедает».

Чтобы воспользоваться «контролем барбекю», сегодня я буду использовать Python для сканирования данных городских барбекю-ресторанов и выбора наиболее подходящего!
Готов к работе
Окружающая среда
- питон 3.6
- пичарм
- запросы >>> отправить запросы запросы на установку pip
- csv >>> сохранить данные
Понять самые основные идеи рептилий
1. Анализ источников данных
- Определить, какой контент мы сканируем
?
Узнайте, откуда берутся эти
вещи- отправить запрос, отправить запрос для найденных пакетов
- Получить данные на основе данных ответа, возвращенных вам сервером
- Проанализируйте данные, извлеките данные контента, которые мы хотим
- сохранить данные, сохранить в файл csv
- Многостраничное сканирование, изменения в соответствии с параметрами URL-адреса
процесс реализации кода
- послать запрос
url = 'https://apimobile.某tuan.com/group/v4/poi/pcsearch/70'
data = {
'uuid': '6e481fe03995425389b9.1630752137.1.0.0',
'userid': '266252179',
'limit': '32',
'offset': 32,
'cateId': '-1',
'q': '烤肉',
'token': '4MJy5kaiY_0MoirG34NJTcVUbz0AAAAAkQ4AAF4NOv8TNNdNqymsxWRtJVUW4NjQFW35_twZkd49gZqFzL1IOHxnL0s4hB03zfr3Pg',
}
# 请求头 都是可以从开发者工具里面直接复制粘贴
# ser-Agent: 浏览器的基本信息
headers = {
'Referer': 'https://chs.某tuan.com/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36'
}
# 发送请求
response = requests.get(url=url, params=data, headers=headers)
200 означает, что запрос был выполнен успешно, а код состояния — 403. У вас нет прав доступа
2. Получить данные
print(response.json())
3. Проанализируйте данные
result = response.json()['data']['searchResult']
# [] 列表 把里面每个元素都提取出来 for循环遍历
for index in result:
# pprint.pprint(index)
# f'{}' 字符串格式化
index_url = f'https://www.某tuan.com/meishi/{index["id"]}/'
# ctrl + D
dit = {
'店铺名称': index['title'],
'店铺评分': index['avgscore'],
'评论数量': index['comments'],
'人均消费': index['avgprice'],
'所在商圈': index['areaname'],
'店铺类型': index['backCateName'],
'详情页': index_url,
}
csv_writer.writerow(dit)
print(dit)
4. Сохранить данные
f = open('烤肉数据.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=[
'店铺名称',
'店铺评分',
'评论数量',
'人均消费',
'所在商圈',
'店铺类型',
'详情页',
])
csv_writer.writeheader() # 写入表头
5. Переверните страницу
for page in range(0, 1025, 32):
url = 'https://apimobile.某tuan.com/group/v4/poi/pcsearch/70'
data = {
'uuid': '6e481fe03995425389b9.1630752137.1.0.0',
'userid': '266252179',
'limit': '32',
'offset': page,
'cateId': '-1',
'q': '烤肉',
'token': '4MJy5kaiY_0MoirG34NJTcVUbz0AAAAAkQ4AAF4NOv8TNNdNqymsxWRtJVUW4NjQFW35_twZkd49gZqFzL1IOHxnL0s4hB03zfr3Pg',
}
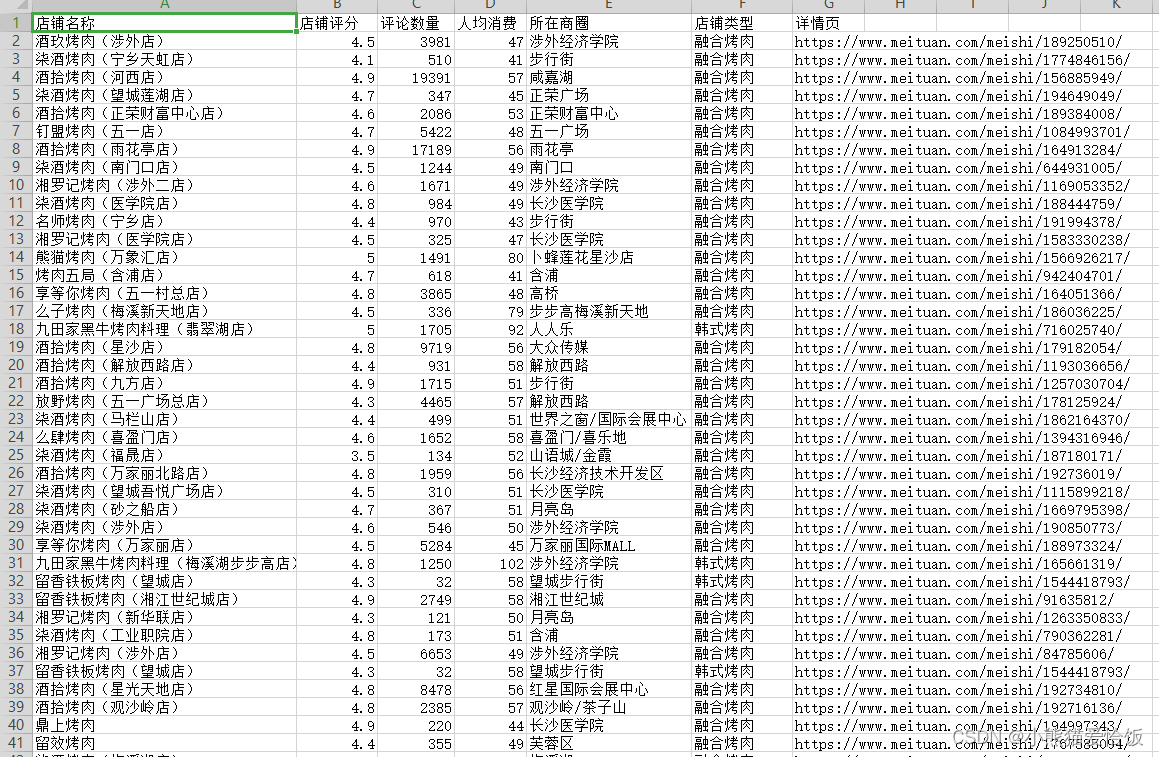
Запустите код, чтобы получить данные

Дополнительную информацию можно добавить в группу Q нажмите здесь
полный код
f = open('烤肉数据1.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=[
'店铺名称',
'店铺评分',
'评论数量',
'人均消费',
'所在商圈',
'店铺类型',
'详情页',
])
csv_writer.writeheader() # 写入表头
for page in range(0, 1025, 32):
url = 'https://apimobile.某tuan.com/group/v4/poi/pcsearch/70'
data = {
'uuid': '6e481fe03995425389b9.1630752137.1.0.0',
'userid': '266252179',
'limit': '32',
'offset': page,
'cateId': '-1',
'q': '烤肉',
'token': '4MJy5kaiY_0MoirG34NJTcVUbz0AAAAAkQ4AAF4NOv8TNNdNqymsxWRtJVUW4NjQFW35_twZkd49gZqFzL1IOHxnL0s4hB03zfr3Pg',
}
headers = {
'Referer': 'https://chs.某tuan.com/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36'
}
# 发送请求
response = requests.get(url=url, params=data, headers=headers)
# 200 表示请求成功 状态码 403 你没有访问权限
result = response.json()['data']['searchResult']
# [] 列表 把里面每个元素都提取出来 for循环遍历
for index in result:
# pprint.pprint(index)
# f'{}' 字符串格式化
index_url = f'https://www.meituan.com/meishi/{index["id"]}/'
# ctrl + D
dit = {
'店铺名称': index['title'],
'店铺评分': index['avgscore'],
'评论数量': index['comments'],
'人均消费': index['avgprice'],
'所在商圈': index['areaname'],
'店铺类型': index['backCateName'],
'详情页': index_url,
}
csv_writer.writerow(dit)
print(dit)