Векторное представление звука
принцип
- Вектор x ∈ RN x \ in R ^ Nx∈RN представляет звуковой сигнал на временном интервале , xi x_ixi представляет звуковое давление, когда t = hit = h_it = hi xi = α p (hi), i = 1, ..., N x_i = \ alpha p (h_i), i = 1, ..., Nxi = αp (hi), i = 1, ..., N
- Каждый xi x_ixi называется выборкой
- h (> 0) - время выборки
- 1 / ч - частота дискретизации , типичная частота дискретизации - 1 / ч = 44100 / сек 1 / ч = 44100 / сек 1 / ч = 44100 / сек или 48000 / сек 48000 / сек 48000 / сек
- α \ alphaα называется коэффициентом отношения
Используйте библиотеку python librosa для чтения аудиосигналов и отображения сигналов с помощью matplotlib
y,sr = librosa.load("MUSIC STEM.wav",sr=None) #y为长度等于采样率sr*时间的音频向量
plt.figure()
librosa.display.waveplot(y, sr) #创建波形图
plt.show() #显示波形图
- 1
- 2
- 3
- 4
результат

анализ
Каждый бит аудиосигнала соответствует точке дискретизации, количество битов равно «частота дискретизации * продолжительность звука (в секундах)», при которой записывается информация об амплитуде звука для каждого отсчета.
Аудиосигнал масштабирования
принцип
Громкость звука определяется абсолютным значением каждой выборки звукового сигнала, поэтому алгебраическое умножение звукового сигнала может увеличивать или уменьшать громкость звука.
Функция алгебраического умножения, предоставляемая массивом numpy, может использоваться для увеличения или уменьшения громкости звука, а также использовать библиотеку librosa для записи аудио вектора обратно в файл.
y=2*y #增加一倍振幅
y=0.5*y #减小振幅为原来一半
y=-y #翻转振幅
y=10*y #大幅增加振幅
librosa.output.write_wav(dir,y,sr) #将音频向量写回文件
- 1
- 2
- 3
- 4
- 5
результат
Осциллограммы результатов четырех операций показаны на рисунке.
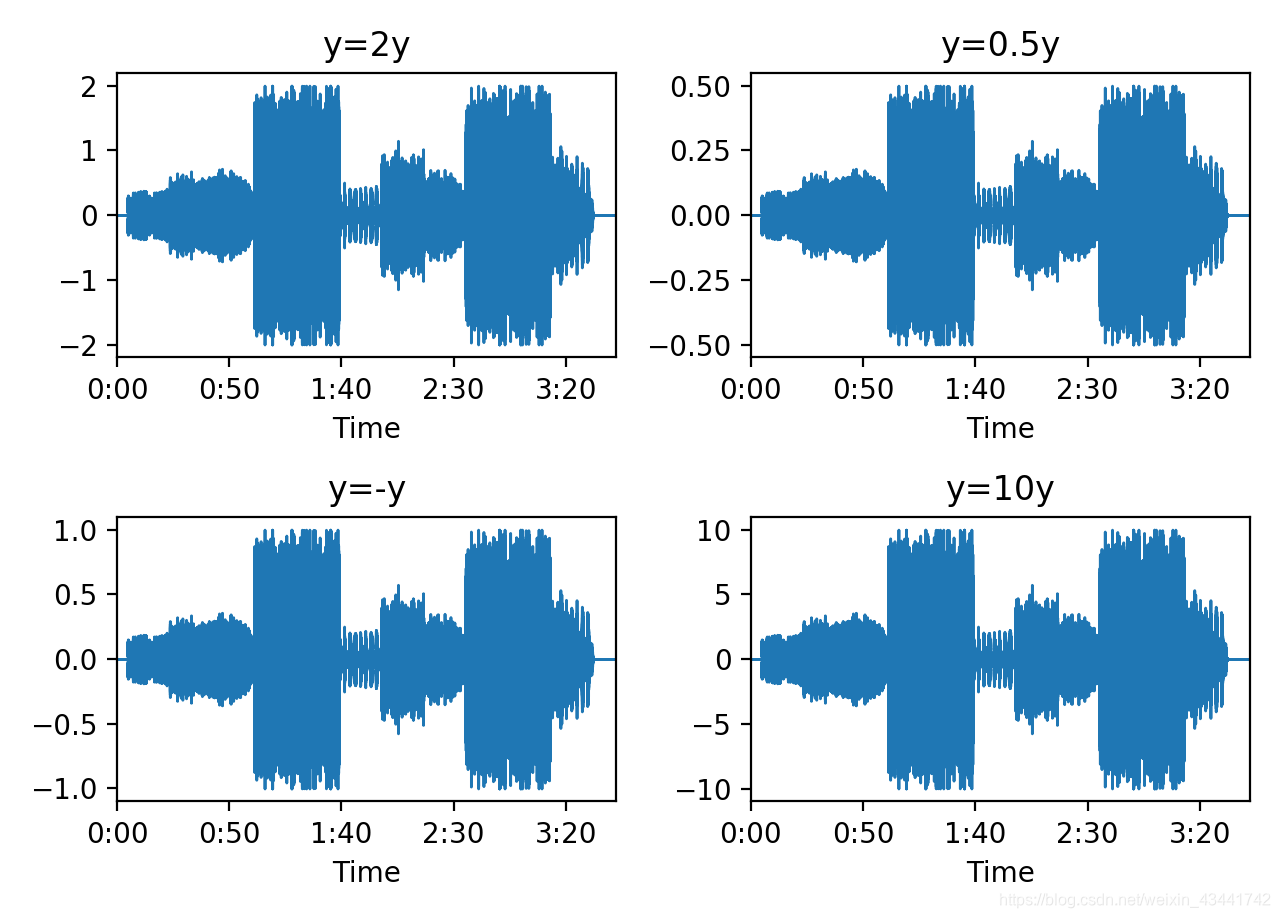
- Когда y = 2 * y, полученная громкость звука немного больше, чем у исходного звука.
- Когда y = 0,5 * y, полученная громкость звука немного меньше, чем у исходного звука.
- Когда y = -y, полученная громкость звука соответствует исходному звуку.
- Когда y = 10 * y, полученная громкость звука намного больше, чем у исходного звука.
анализ
- Значение каждого отсчета звукового сигнала отражает расстояние вибрации от точки равновесия, то есть амплитуду. Чем больше амплитуда , тем больше энергия звука и тем громче звук.
- Умножьте значение выборки.Если абсолютное значение коэффициента умножения больше 1, громкость звука увеличится, а если абсолютное значение коэффициента умножения меньше 1, громкость звука уменьшится.
- Поскольку расстояние вибрации от точки равновесия является абсолютной величиной, эффект, когда коэффициент умножения отрицательный, такой же, как когда коэффициент умножения является противоположным числом.
Линейное комбинирование и смешивание
принцип
-
Выполнение линейных операций с несколькими аудиосигналами y = a 1 x 1 + a 2 x 2 + ... + Akxky = a_1x_1 + a_2x_2 + ... + a_kx_ky = a1 x1 + a2 x2 + ... + ak Xk может добиться смешивания
-
В это время каждый звуковой сигнал xk x_kxk называется звуковой дорожкой.
-
Смешанный результат y называется смешанным.
-
Каждый коэффициент ak a_kak - это вес звуковой дорожки в миксе.
Функция линейной операции, предоставляемая массивом numpy, может использоваться для достижения смешивания
Попробуйте еще раз смешать вокал и аккомпанемент. Возьмите вокальную дорожку и дорожку аккомпанемента и назначьте веса (0,25, 0,75), (0,5, 0,5), (0,4, 0,6) линейному микшированию.
y=0.25*x1+0.75*x2
y=0.5*x1+0.5*x2
y=0.6*x1+0.4*x2
- 1
- 2
- 3
результат
Диаграмма формы сигнала выглядит следующим образом: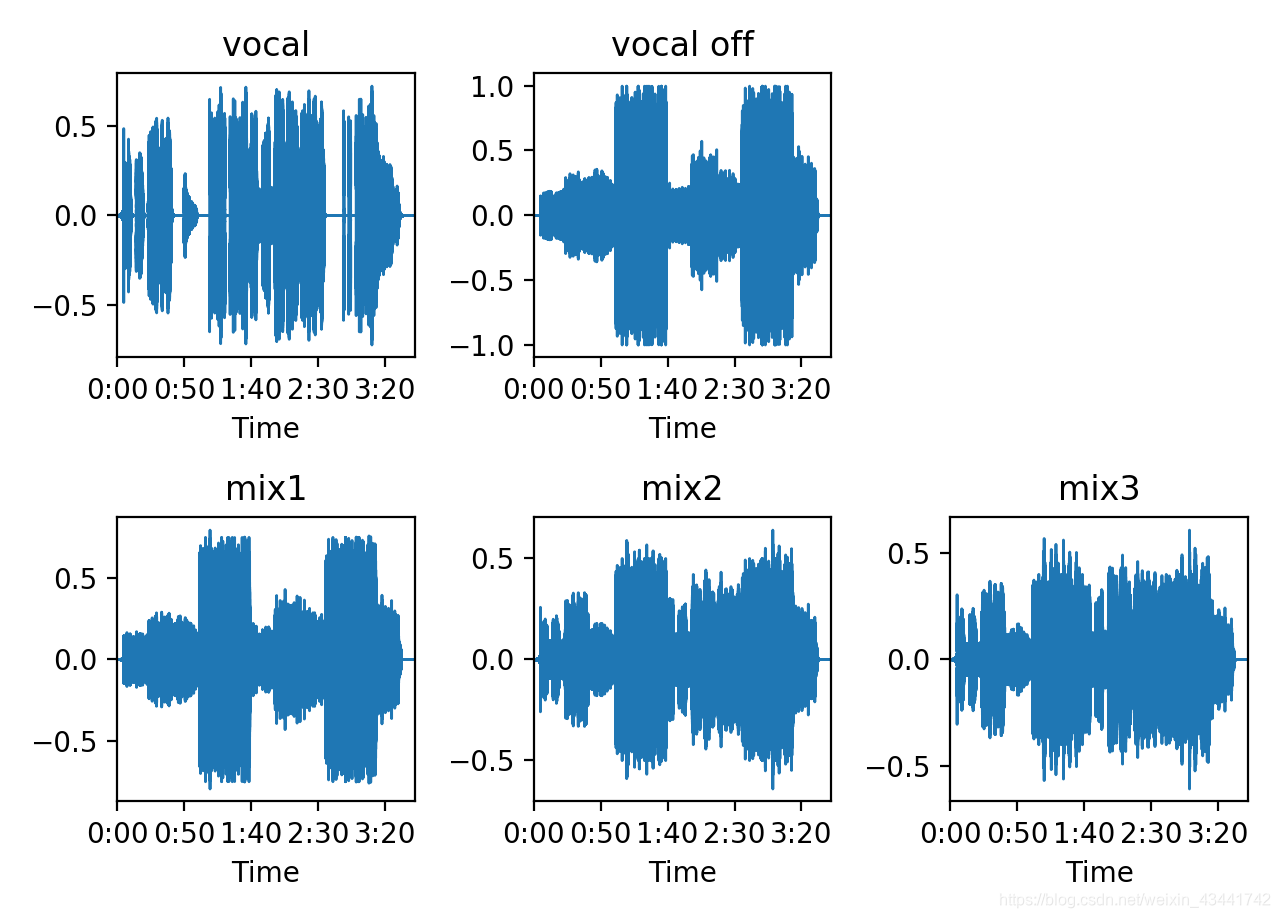
Полученный звук - это эффект добавления вокала к аккомпанементу.
анализ
-
Звук добавляется линейно, и результирующий график формы волны нельзя визуально различить между человеческим голосом и аккомпанементом, но поскольку гармонические составляющие каждой частоты в человеческом голосе и аккомпанементе отличаются от таковых в аккомпанементе, каждой частотной гармонике назначается линейное сложение. в частотной области. Так что на спектрограмме можно четко различить
-
Чтобы получить достаточно чистый смешанный звук, вам необходимо постоянно изменять вес каждой смешанной звуковой дорожки, чтобы получить наиболее подходящий режим микширования.
расширять
Хотя под аккомпанемент и вокал существенно различных гармонических составляющих, но с добавлением на той же частоте , может легко привести к возникновению частоты столкновений, так что смешение вокала и сопровождение неразличимой, так и для двухканального аудио, мы часто используем смещение из Метод, установите разные веса для вокала и аккомпанемента в двух каналах (обычно один канал громче, другой - громче)
Многочисленный массив формы (2, n) может использоваться для размещения двухканальных аудиосигналов. Два канала смешиваются с весами (0,4, 0,6) и (0,6, 0,4) соответственно, а формы сигналов выглядят следующим образом: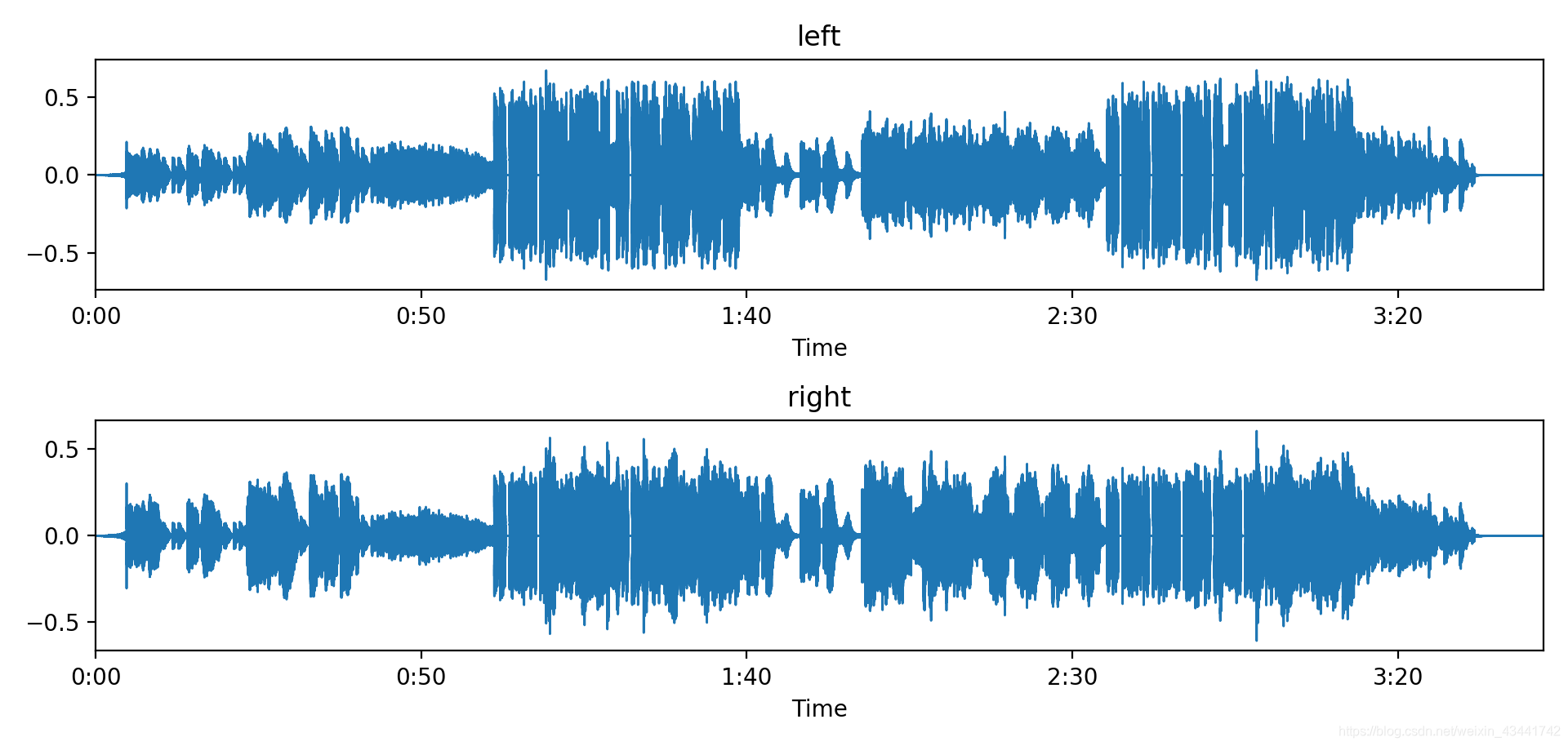
Музыка
- Для звукового сигнала p (t), если p (t + T) ≈ p (t) p (t + T) \ приблизительно p (t) p (t + T) ≈p (t), период T принимает значение Между 0,0005 секунды и 0,01 секунды p считается музыкальным тоном.
- Длина периода (определяет частоту и) определяет высоту тона.
- Характеристики формы волны в каждом цикле определяют тембр
- Энергия музыкального звука определяет громкость , то есть звуковое давление.
подача
- f = 440 Гц zf = 440 Гц f = 440 Гц - центр A
- На одну октаву удвоена частота
- В двенадцати равных темпераментах каждый полутон повернут на 2 1/12 2 ^ {1/12} 21/12 раз по частоте.
- Расстояние в каждый полутон - это расстояние между двумя клавишами на черной и белой клавишах. От до до восходящего до разница между белыми клавишами является полной, наполовину полной и полной, а полутоны в каждом полном тоне делятся на черные. ключ
- Расстояние между любыми двумя звуками называется интервалом. Единица измерения - градус . Интервал между одним и тем же звуком составляет 1 градус. После этого каждая разница в уровне звука увеличивается на 1 градус.
Экспериментальные шаги:
- Установите основную частоту f на 440 Гц и используйте numpy для генерации синусоидальной функции на 440 Гц.
- Установите точку дискретизации каждые 1/44100 с и генерируйте синусоидальную волну 1 с 440 Гц каждые 1 с.
- Исходя из этого, в n-м поколении частота единиц будет 440 2 (n - 1) / 12 Гц z 440 · 2 ^ {(n-1) / 12} Гц 440 ± 2 (n − 1) / 12 Гц. Синусоидальная волна линейно добавляется к исходной синусоиде для исполнения аккорда, тем самым моделируя все интервалы от второстепенной секунды до чистой октавы.
x=np.empty((0,)) #生成空数组
for i in range(0,13):
x1=np.linspace(0,1, num=44100, endpoint=True, dtype=float) #生成采样点
x1=5*np.sin(2*np.pi*440*np.power(2,i/12)*x1)+5*np.sin(2*np.pi*440*x1) #生成波形与和弦
x2=np.zeros((44100,)) #留空部分
x=np.concatenate((x,x1,x2),axis=0) #连接数组
- 1
- 2
- 3
- 4
- 5
- 6
В сгенерированном звуке длиной 26 сек есть 13 аккордов с разными интервалами, некоторые аккорды звучат гармонично, а некоторые - диссонирующими.
- Второстепенные интервалы (разница в один полутон) и большие седьмые интервалы (разница в пять полных шагов и один полутон) являются крайне несовместимыми интервалами.
- Основные секундные интервалы (разница в один полный шаг), второстепенные седьмые интервалы (разница в пять полных шагов) и три полных шага (три полных шага) являются несовместимыми интервалами.
- Второстепенные трети (разница в один шаг и один полутон), большие трети (разница в два целых шага), второстепенные шестые (разница в четыре целых шага) и основные шестые (разница в четыре целых шага и один полутон) неполные согласные интервалы
- Чистый четвертый интервал (разница в два целых шага и полутон) и чистый пятый интервал (разница в три целых шага и полутон) являются полными интервалами согласных.
- Чистая октава (разница в шесть полных тонов) - это очень полный интервал согласных.
Тембр
-
Для периодических сигналов p (t) знак равно ∑ К знак равно 1 K (akcos (2 π fkt) + bksin (2 π fkt)) p (t) = \ displaystyle \ sum_ (k = 1) ^ K (a_kcos (2 \ pi fkt) + b_ksin (2 \ pi fkt)) p (t) = k = 1∑K (ak cos (2πfkt) + bk sin (2πfkt)), каждый разложенный сигнал является гармоническим или обертонным
-
f - частота
-
a и b - гармонические коэффициенты
-
Когда K достаточно велико, любой периодический сигнал может быть преобразован в эту форму путем интегрирования
-
Отношение амплитуд гармоник определяет тон. Для каждой гармоники, частота которой определяется k, ее амплитуда гармоники равна ck = ak 2 + bk 2 c_k = \ sqrt {a_k ^ 2 + b_k ^ 2} ck = ak2 + bk2 , Поэтому амплитуда гармоники может образовывать вектор длины kc = (0,3, 0,4, ...) C = (0,3,0,4, ...) c = (0,3,0,4, ...), достаточное количество гармоник может смешивать с разными значениями амплитуды для формирования разных тембров
Генерация синусоидальных и косинусоидальных сигналов в частотных диапазонах 1, 5, 10, 20 и 50 между 220-11000 Гц и случайное создание гармонических коэффициентов
результат
Диаграмма смешанной формы сигнала при пяти условиях выглядит следующим образом:
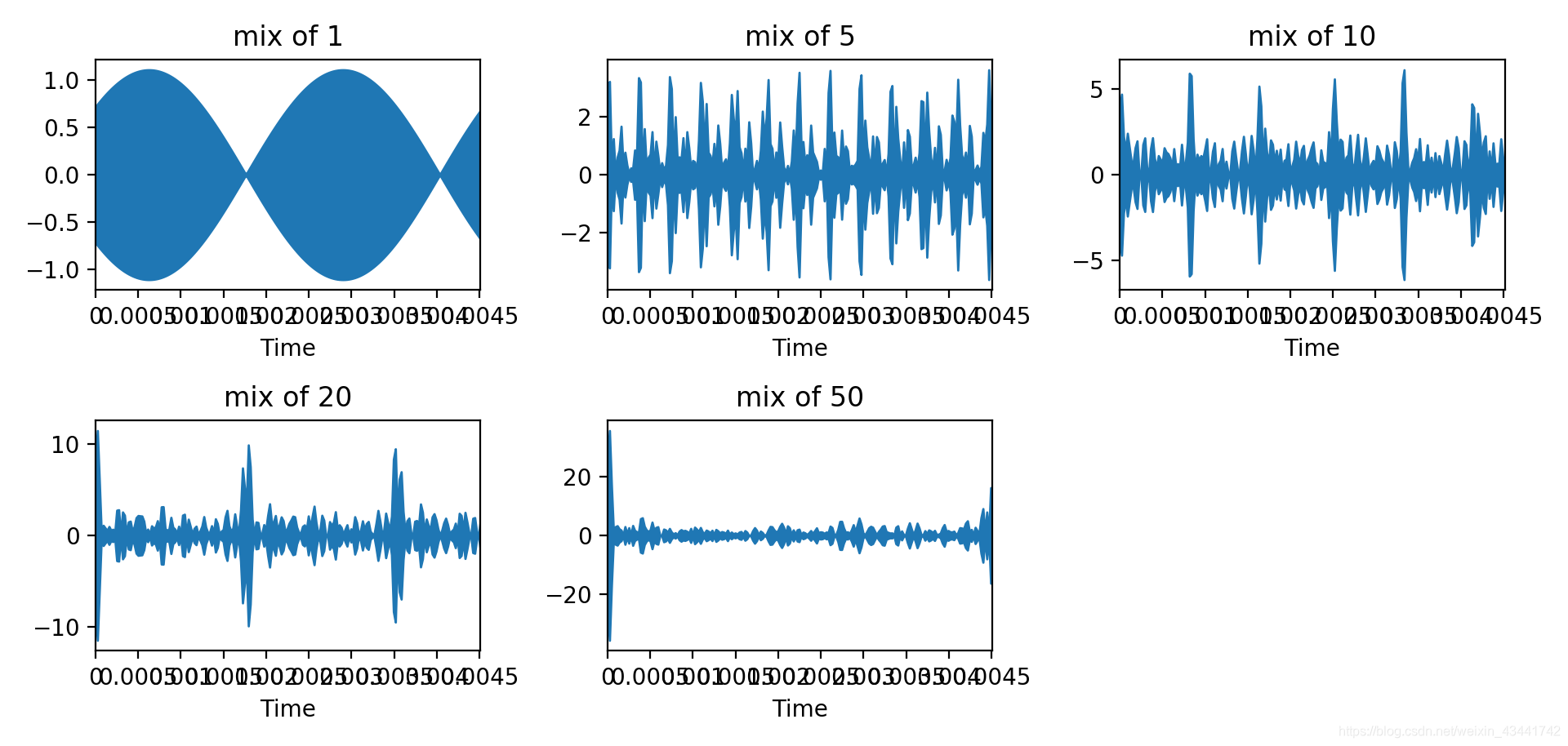
Получите аудиофайл, который воспроизводит звук 1 с с разными тембрами каждые 1 с.
анализ
- Используйте достаточно разные гармоники для смешивания с разными коэффициентами гармоник для формирования звука с разным тембром
- В действительности известные музыкальные инструменты также могут использовать спектральный анализ для извлечения тембральных характеристик для компьютерного воспроизведения.
- Различные электронные синтезаторы могут быть созданы с использованием принципа гармоник для композиторов.