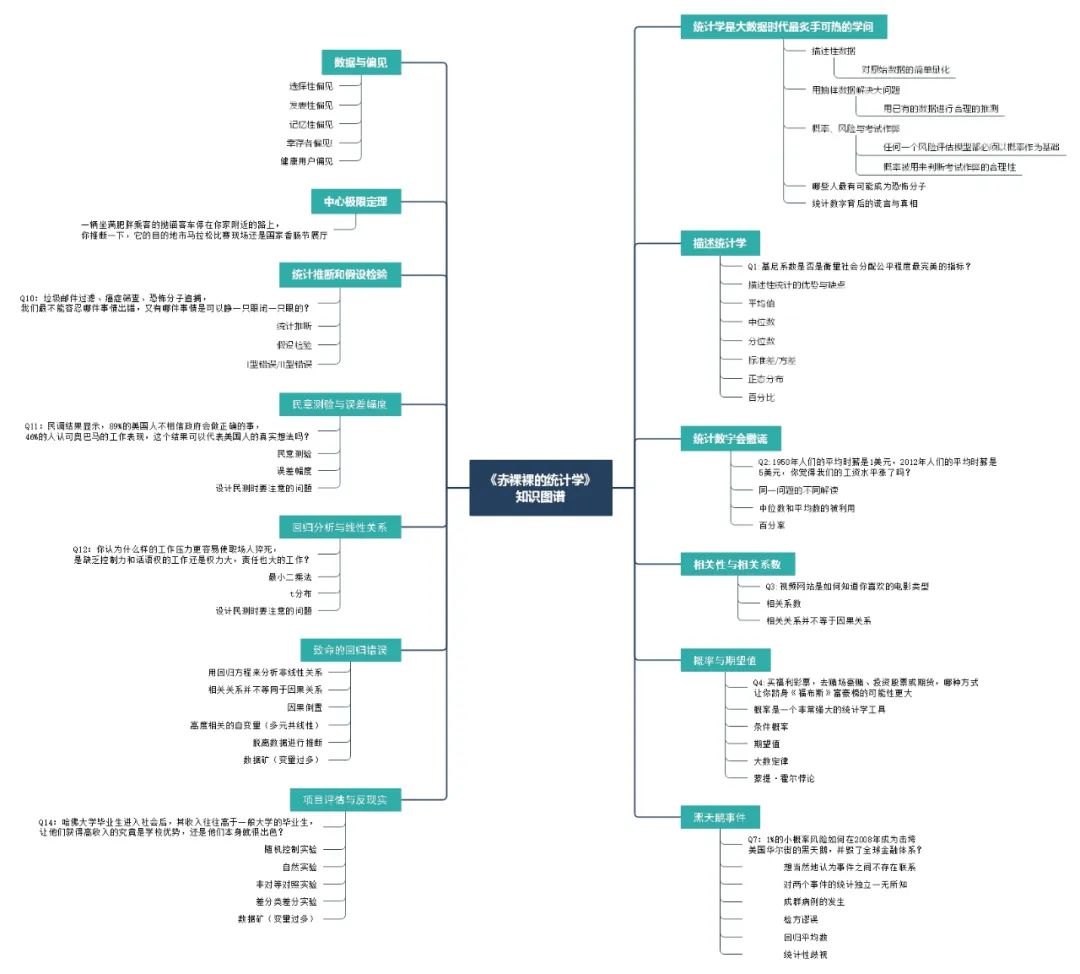
«Обнаженная статистика», автор [Америка] Чарльз Вэйланд, опубликованная в 2013 году, оценка Дубана 8,1 балла, может использоваться как хорошая книга для вводной статистики, точки знаний легко понять, очень дружелюбны к Сяобаю, Те, у кого есть статистический опыт, могут почувствовать, что сухих товаров меньше. В общем, стоит прочитать, индекс рекомендаций 4 звезды. В конце статьи приводится таблица знаний об этой книге .

1. Статистика - это самая актуальная информация в эпоху больших данных.
В начале первой главы было поднято несколько интересных вопросов:
Является ли коэффициент Джини наиболее совершенным показателем для измерения справедливости социального распределения? (Описательная статистика)
Откуда видеосайт узнает, какой фильм вам нравится (актуальность)
Может ли молитва действительно улучшить послеоперационное восстановление пациента (рандомизированный контролируемый эксперимент)
Что вызывает рост заболеваемости аутизмом (корреляция)
За этими вопросами стоит точка статистических знаний, я считаю, что, прочитав эту книгу, вы также сможете получить ответ.
2. Описательная статистика
Вторая глава фактически отвечает на вопрос первой главы в начале:
Является ли коэффициент Джини наиболее совершенным показателем для измерения справедливости социального распределения?
Позвольте мне начать с ответа: нет. Статистика редко предоставляет единственно правильный метод. Коэффициент Джини - это описательный индикатор данных, который объединяет ряд сложных данных в единый цифровой инструмент. Это не идеальный индикатор для измерения справедливости социального распределения, но он позволяет Он предоставляет некоторую информацию о справедливости социального распределения в удобной и простой для понимания форме. В то же время следует отметить, что любые упрощенные данные могут быть использованы не по назначению. В этом заключается преимущество и недостаток описательной статистики.
Говоря об описательной статистике, нельзя не упомянуть среднее, медианное значение, квантиль, стандартное отклонение и дисперсию.В этой главе есть подробное описание и глубокое понимание этих понятий.
В начале этой главы также была поднята математическая задача для начальной школы:
Платье, которое вы всегда хотели купить, продается в торговом центре по цене 4999 юаней. Цена снижается на 25%, а затем увеличивается на 25%. Какова окончательная цена?
Ответ - 93,75, верно? Для детской обуви, которая забыла, как рассчитывать, вы можете использовать Baidu.Это очень простой вопрос расчета процента и скорости роста.
3. Статистика будет врать
Q3: В 1950 году средняя почасовая зарплата людей составляла 1 доллар. В 2012 году средняя почасовая оплата людей составляла 5 долларов. Как вы думаете, у нас повысилась заработная плата?
 Этот вопрос поднимается первым. Что касается того, что статистика будет лгать, я считаю, что все глубоко чувствуют. Данные верны. Это не ложь. Просто угол интерпретации и единица анализа разные . Еще раз следует упомянуть плохой пример, а именно медиана и среднее значение. Среднее значение (3,4,5,6,102) равно 24, а медиана - 5. Разница между этими двумя числами Она по-прежнему очень большая, поэтому зарплата средняя. Необходимо различать единицы анализа, описываемые объекты и есть ли различия в том, кто или что среди разных популяций. Суждение важнее математики
Этот вопрос поднимается первым. Что касается того, что статистика будет лгать, я считаю, что все глубоко чувствуют. Данные верны. Это не ложь. Просто угол интерпретации и единица анализа разные . Еще раз следует упомянуть плохой пример, а именно медиана и среднее значение. Среднее значение (3,4,5,6,102) равно 24, а медиана - 5. Разница между этими двумя числами Она по-прежнему очень большая, поэтому зарплата средняя. Необходимо различать единицы анализа, описываемые объекты и есть ли различия в том, кто или что среди разных популяций. Суждение важнее математики
Возвращаясь к вопросу в начале, повысился ли уровень заработной платы? Фактически, все знают, что вы не можете просто обращать внимание на увеличение чисел, поскольку существует инфляция, вы должны преобразовать два значения в одну и ту же единицу, например, все, конвертировать в доллары 2011 года, а затем сравнить их.
Четыре, корреляция и коэффициент корреляции
Эта глава отвечает на вопрос, поставленный в главе 1:
Откуда видеосайт узнает, какой фильм вам нравится
Ответ - корреляция. Одним из показателей для описания корреляции является коэффициент корреляции . Я не буду вдаваться в подробности о том, как коэффициент корреляции объясняет корреляцию. Что касается корреляции, самое важное, что вам нужно знать, - это то, что корреляция не равна причинной связи . Оценки учащихся положительно коррелируют с количеством телевизоров в доме. Это не означает, что, если родители купят еще 5 телевизоров, оценки детей могут улучшиться.
Пять, вероятность и ожидаемое значение
Q5: Покупка билетов благотворительной лотереи, поход в казино, чтобы сыграть в азартные игры, инвестирование в акции или фьючерсы, что увеличивает вероятность того, что вы попадете в список богатых людей Forbes.
Это вопрос вероятности. Вероятность - это изучение неопределенных событий и результатов. Вероятность не говорит нам ясно, что произойдет, но мы можем знать, что может случиться, а что маловероятно, вычислив вероятность.
Ожидаемое значение - это сумма всех событий, не только число, но и показатель нашего суждения.
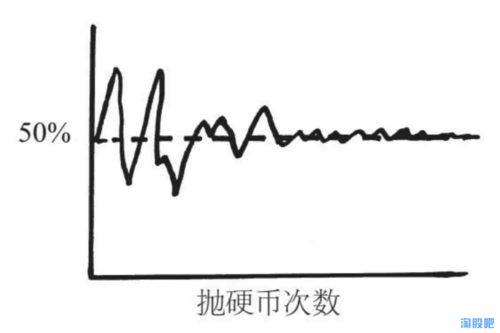
Закон больших чисел: по мере увеличения количества попыток средний результат будет приближаться к ожидаемому значению. Например, ожидаемая прибыль от лотерейного билета за 1 юань составляет 0,56 юаня. В долгосрочной перспективе это плохая инвестиция ниже стоимости, но мне посчастливилось выиграть 5 юаней сегодня, но по закону больших чисел, если я куплю его на много лет. Спад - это, несомненно, потеря денег.
6. Парадокс Монти Холла
В6: За дверью 3, которую открыл хозяин, находится овца. Среди оставшихся дверей 1 и 2 за дверью должна быть машина. Как вы решите выиграть джекпот?
Это известная вероятностная задача машин, козлов и дверей. Она называется Парадокс Монти Холла. В варьете 3 двери, одна за дверью - машина, а другая - овца. Участники выбирают одну. Дверь, ведущий откроет одну из двух оставшихся дверей с овцой, а затем спросит участников, менять ли первоначальный выбор?
Это все еще проблема вероятности. Из расчетов известно, что вероятность изменения первоначального выбора будет больше. Этот вопрос также привел к множеству различных объяснений и ответов, и заинтересованные друзья могут найти его сами.
Семь, инцидент с черным лебедем
Q7: Как риск с малой вероятностью 1% превратился в черного лебедя, победившего Уолл-стрит в 2008 году и разрушившего мировую финансовую систему?
Корень этой проблемы состоит в том, чтобы говорить о модели стоимости, подверженной риску. Проще говоря, это использование простого индикатора для обозначения максимального убытка, который вложение может вызвать у компании в определенный период. Вероятность этого результата составляет 1%, что означает , Эти вложения безопасны в 99% случаев, но только в оставшемся 1% дела облажались.
Некоторые вероятные недоразумения, если интересно, можете прочитать саму книгу:
Считайте само собой разумеющимся, что между событиями нет связи
Ничего не знать о статистической независимости двух событий: например, о заблуждении игрока.
Возникновение кластеров случаев: может быть просто совпадением
Ошибка прокурора
Среднее значение регрессии
Статистическая дискриминация
Главы 5, 6 и 7 посвящены вероятности.Хотя вероятность имеет много преимуществ простоты и точности, она не может заменить человека в качестве объекта вычислений и причин для вычислений.
8. Данные и предвзятость
Если вы хотите точно отразить характеристики всего населения, выборка , несомненно, является наиболее удобным и справедливым способом. Однако, если есть проблема с самим составом населения, то есть так называемая "систематическая ошибка", то независимо от размера выборки эту "систематическую" ситуацию изменить нельзя. . Это говорит нам о том, что если есть проблема с самими данными, никакой тщательный анализ бесполезен.
Вот несколько примеров, когда статистические методы верны, а сами данные являются проблематичными:
ü Выборочная систематическая ошибка
ü Ошибка публикации
ü Ошибка памяти
ü Ошибка выжившего
ü Ошибка здорового пользователя

Девять, центральная предельная теорема
Q9: Сломанный автобус с тучными пассажирами припаркован на дороге рядом с вашим домом. Вы можете сделать вывод, что марафон в городе назначения по-прежнему является выставочным залом Национального фестиваля колбасы.
Этот вопрос, кажется, позволяет сделать вывод с первого взгляда. Это должен быть выставочный зал Национального фестиваля колбас. Эта общая способность часто является центральной предельной теоремой. Суть центральной предельной теоремы заключается в правильном отборе большой выборки и группы, которую она представляет. Есть похожие отношения. Это логика центральной предельной теоремы, которая говорит нам, что большинство марафонцев относительно худые, поэтому вероятность того, что так много спортсменов-тяжеловесов окажется в машине, очень мала, поэтому цель этой машины определена. Площадка - выставочный зал фестиваля колбас.
10. Статистический вывод и проверка гипотез.
Q10: Фильтрация спама, скрининг на рак, охота на террористов - какие вещи мы не можем допустить, если что-то пошло не так, и на что мы можем закрыть глаза?
Статистика не может ничего убедительно доказать, но вы можете сначала обнаружить некоторые законы и результаты, а затем использовать вероятность, чтобы доказать наиболее вероятные причины этих результатов, и наиболее часто используемым инструментом в этом процессе является проверка гипотез.
Идея проверки гипотез - это метод маловероятного противоречия , который можно понять следующим образом: сначала сделайте вывод (нулевая гипотеза), а затем подтвердите или опровергните его с помощью статистического анализа.
Дайте каштан:
Нулевая гипотеза: новый препарат не более эффективен, чем плацебо в профилактике малярии
Альтернативная гипотеза: новый препарат может предотвратить малярию
Процесс статистического вывода: заболеваемость малярией в группе, принимающей новое лекарство, намного ниже, чем в контрольной группе, принимающей плацебо. Если новое лекарство не оказывает лечебного действия, вероятность такого результата очень мала. Таким образом, нулевая гипотеза отклоняется.
Возвращаясь к вопросу о Q10, есть ошибки типа I и ошибка II типа в тесте гипотезы. Эти три случая этой проблемы представляет собой компромисс между этими двумя ошибками. Вы можете внимательно прочитать книгу \
11. Опросы общественного мнения и допустимая погрешность
Вопрос 11: Результаты опроса показывают, что 89% американцев не верят, что правительство поступит правильно, а 46% одобряют работу Обамы. Может ли этот результат отражать истинное американское мышление?
Опросы общественного мнения (опросы) основаны на центральной предельной теореме . Конечно, вы также можете рассчитать вероятность того, что результаты выборки будут отклоняться от целого на большой территории. Это предел погрешности. Существует 95% -ная вероятность того, что результаты опроса колеблются в пределах 3% от реальной ситуации.
Несколько моментов, которые следует учитывать при проведении опроса:
Правильно ли этот образец отражает истинные взгляды целевой группы? Чтобы не вызвать избирательной предвзятости
Может ли постановка вопроса во время интервью дать полезную информацию по теме исследования?
Должно ли быть правдой то, что сказал интервьюируемый?
12. Регрессионный анализ и линейная зависимость
В12: Как вы думаете, какое рабочее давление с большей вероятностью приведет к внезапной смерти на рабочем месте? Это работа, на которой не хватает контроля и голоса, или это работа с большой властью и ответственностью?
На самом деле смертность у первых выше, но откуда такой вывод? регрессионный анализ! Исходя из предпосылки контроля других факторов, количественной оценки взаимосвязи между конкретной переменной и конкретным результатом, возвращение к самому вопросу означает анализ вреда низкоуровневой работы для здоровья определенной группы населения. Мощная способность регрессионного анализа заключается в выделении статистических ассоциаций, которые нас волнуют.
Мы сосредотачиваемся на регрессионном анализе, чтобы сосредоточиться на двух моментах: корреляции между переменными и статистической значимости результатов. Наконец, регрессионный анализ должен найти наиболее подходящую взаимосвязь между двумя переменными , например, взаимосвязь между ростом и весом. Хотя это не абсолютное значение, люди, которые выше ростом, обычно весят больше. Как определить «наиболее подходящие» отношения? Ответ - метод наименьших квадратов. Он не будет здесь расширяться. Вы можете использовать Baidu или прочитать книгу самостоятельно.
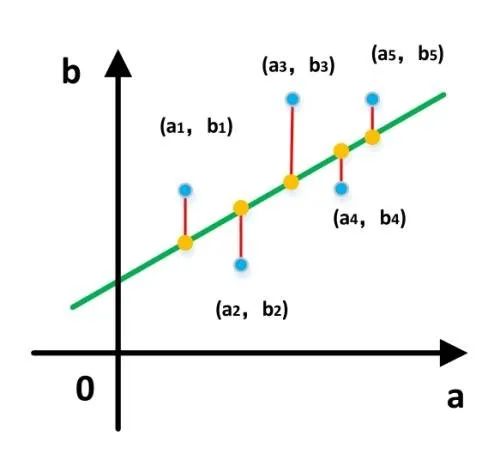
На самом деле сложность регрессионного анализа заключается не в самой технологии, а в том, какие переменные используются и как лучше всего использовать эти переменные. Этому также посвящена данная глава.
13. Неустранимые ошибки возврата
Регрессионный анализ дает точные ответы на сложные вопросы, но эти ответы не обязательно точны. В этой главе рассказывается о том, на что следует обратить внимание при применении регрессионного анализа. Существует несколько распространенных ошибок:
Используйте уравнения регрессии для анализа нелинейных отношений. Регрессионный анализ может пригодиться только тогда, когда взаимосвязь между переменными является линейной.
Корреляция - это не то же самое, что причинная связь.
Обращение причины и следствия. Убедитесь, что независимая переменная влияет на зависимую переменную, а не наоборот.
Переменное опущение отклонения. Если игра в гольф предрасположена к сердечным заболеваниям, этот вывод состоит в том, что возрастная переменная опускается, потому что может быть не то, что игра в гольф предрасположена к сердечным заболеваниям, а то, что пожилые люди склонны к сердечным заболеваниям.
Сильно коррелированные независимые переменные (множественная коллинеарность). Если две независимые переменные сильно коррелированы, то невозможно отличить истинную связь между ними и зависимой переменной.
Сделайте выводы из данных. Уравнение регрессии, используемое для объяснения этой выборки, не обязательно применимо к другой выборке.
Интеллектуальный анализ данных (слишком много переменных).
14. Оценка проекта и «контрреальность»
В14: Вступив в общество, выпускники Гарвардского университета часто имеют более высокие доходы, чем обычные выпускники университетов. Это преимущество школы или они выдающиеся?
Этот вопрос следует объяснить с помощью неэквивалентного контролируемого эксперимента: «По сравнению с названием школы в аттестате об окончании школы правильное понимание собственных интересов, амбиций и способностей может сделать жизнь человека лучше», - я считаю, что это лучший ответ на этот вопрос.
Выше были мои мысли после прочтения этой книги, и я также построил диаграмму знаний, как показано ниже (если вы не видите четко, вы можете добавить WeChat data_cola, чтобы попросить меня предоставить исходное изображение):