
Com o rápido avanço da tecnologia de inteligência artificial, a OpenAI emergiu como uma das líderes na área. Ele funciona bem em uma variedade de tarefas de processamento de linguagem, incluindo tradução automática, classificação de texto e geração de texto. Com a ascensão do OpenAI, surgiram muitos outros modelos de linguagem grande de código aberto de alta qualidade, como Llama, ChatGLM, Qwen, etc. Esses excelentes modelos de código aberto também podem ajudar as equipes a construir rapidamente um excelente aplicativo LLM.
Mas diante de tantas opções, como podemos usar as interfaces OpenAI de maneira uniforme e, ao mesmo tempo, reduzir os custos de desenvolvimento? Como monitorar de forma eficiente e contínua o desempenho de execução de aplicativos LLM sem adicionar complexidade adicional ao desenvolvimento? GreptimeAI e Xinference fornecem soluções práticas para esses problemas.
O que é Greptime AI
GreptimeAI é construído no banco de dados de série temporal de código aberto GreptimeDB. É um conjunto de soluções de observabilidade para aplicativos de modelo de linguagem grande (LLM). Atualmente, oferece suporte aos ecossistemas LangChain e OpenAI. GreptimeAI permite que você obtenha uma compreensão abrangente de custos, desempenho, tráfego e segurança em tempo real, ajudando as equipes a melhorar a confiabilidade dos aplicativos LLM.
O que é Xinferência
Xinference é uma plataforma de inferência de modelo de código aberto projetada para grandes modelos de linguagem (LLM), modelos de reconhecimento de fala e modelos multimodais, e oferece suporte à implantação privatizada. Xinference fornece uma API RESTful compatível com a API OpenAI e integra ferramentas de desenvolvedores de terceiros, como LangChain, LlamaIndex e Dify.AI para facilitar a integração e o desenvolvimento de modelos. Xinference integra vários mecanismos de inferência LLM (como Transformers, vLLM e GGML), é adequado para diferentes ambientes de hardware e oferece suporte à implantação distribuída de várias máquinas. Ele pode alocar com eficiência tarefas de inferência de modelo entre vários dispositivos ou máquinas para atender às necessidades de várias máquinas. modelo e necessidades de implantação disponíveis.
GreptimeAI + Xinference implantar/monitorar aplicativos LLM
A seguir, tomaremos o modelo Qwen-14B como exemplo para apresentar em detalhes como usar o Xinference para implantar e executar o modelo localmente. Um exemplo será mostrado aqui, que usa um método semelhante à chamada de função OpenAI (Function Calling) para realizar consultas meteorológicas e demonstra como usar GreptimeAI para monitorar o uso de aplicativos LLM.
Registre-se e obtenha informações de configuração do GreptimeAI
Visite https://console.greptime.cloud para registrar o serviço e criar o serviço AI. Depois de acessar o AI Dashboard, clique na página Configuração para obter as informações de configuração do OpenAI.
Inicie o serviço do modelo Xinference
É muito simples iniciar o serviço do modelo Xinference localmente. Basta inserir o seguinte comando:
xinference-local -H 0.0.0.0
O Xinference iniciará o serviço localmente por padrão e a porta padrão é 9997. O processo de instalação local do Xinference é omitido aqui. Você pode consultar este artigo para instalação.
Iniciando o modelo via Web UI
Depois que o Xinference for iniciado, digite http://localhost:9997 no navegador para acessar a UI da Web.

Inicie o modelo a partir da linha de comando
Também podemos usar a ferramenta de linha de comando do Xinference para iniciar o modelo. O UID do modelo padrão é qwen-chat (o modelo será acessado por meio deste ID posteriormente).
xinference launch -n qwen-chat -s 14 -f pytorch
Obtenha informações meteorológicas por meio da interface estilo OpenAI
Suponha que possamos get_current_weatherobter informações meteorológicas para uma cidade específica chamando a função, com parâmetros locatione format.
Configurar OpenAI e interface de chamada
Acesse a porta local do Xinference por meio do Python SDK da OpenAI, use GreptimeAI para coletar dados, use chat.completionsa interface para criar uma conversa e use para toolsespecificar a lista de funções que acabamos de definir.
from greptimeai import openai_patcher
from openai improt OpenAI
client = OpenAI(
base_url="http://127.0.0.1:9997/v1",
)
openai_patcher.setup(client=client)
messages = [
{"role": "system", "content": "你是一个有用的助手。不要对要函数调用的值做出假设。"},
{"role": "user", "content": "上海现在的天气怎么样?"}
]
chat_completion = client.chat.completions.create(
model="qwen-chat",
messages=messages,
tools=tools,
temperature=0.7
)
print('func_name', chat_completion.choices[0].message.tool_calls[0].function.name)
print('func_args', chat_completion.choices[0].message.tool_calls[0].function.arguments)
detalhes das ferramentas
Chamada de função A lista de funções (ferramentas) é definida abaixo, com campos obrigatórios especificados.
tools = [
{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "获取当前天气",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "城市,例如北京",
},
"format": {
"type": "string",
"enum": ["celsius", "fahrenheit"],
"description": "使用的温度单位。从所在的城市进行推断。",
},
},
"required": ["location", "format"],
},
},
}
]
A saída é a seguinte, você pode ver que obtivemos chat_completiona chamada de função gerada pelo modelo Qwen por meio de:
func_name: get_current_weather
func_args: {"location": "上海", "format": "celsius"}
Obtenha o resultado da chamada de função e chame a interface novamente
Supõe-se aqui que chamamos a função com os parâmetros fornecidos get_current_weathere obtivemos o resultado, e reenviamos o resultado e o contexto para o modelo Qwen:
messages.append(chat_completion.choices[0].message.model_dump())
messages.append({
"role": "tool",
"tool_call_id": messages[-1]["tool_calls"][0]["id"],
"name": messages[-1]["tool_calls"][0]["function"]["name"],
"content": str({"temperature": "10", "temperature_unit": "celsius"})
})
chat_completion = client.chat.completions.create(
model="qwen-chat",
messages=messages,
tools=tools,
temperature=0.7
)
print(chat_completion.choices[0].message.content)
Resultados finais
O modelo Qwen eventualmente produzirá uma resposta como esta:
上海现在的温度是 10 摄氏度。
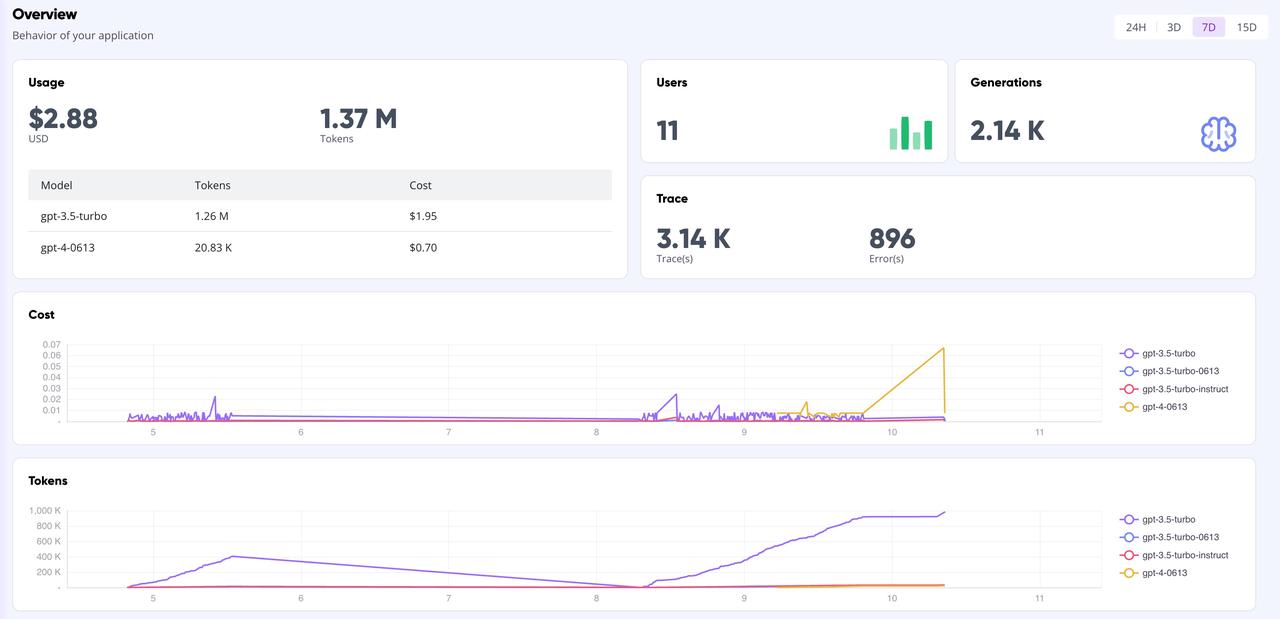
Painel publicitário GreptimeAI
Na página do painel GreptimeAI, você pode monitorar de forma abrangente e em tempo real todos os dados de chamadas com base na interface OpenAI, incluindo indicadores-chave como token, custo, latência, rastreamento, etc. Abaixo é mostrada a página de visão geral do painel.
Resumir
Se você estiver usando modelos de código aberto para construir aplicativos LLM e quiser usar o estilo OpenAI para fazer chamadas de API, usar Xinference para gerenciar o modelo de inferência e usar GreptimeAI para monitorar a operação do modelo é uma boa escolha. Esteja você conduzindo análises de dados complexas ou consultas diárias simples, o Xinference pode fornecer recursos de gerenciamento de modelos poderosos e flexíveis. Ao mesmo tempo, combinado com a função de monitoramento do GreptimeAI, você pode compreender e otimizar com mais eficiência o desempenho e o consumo de recursos do modelo.
Aguardamos suas tentativas e agradecemos o compartilhamento de experiências e insights usando GreptimeAI e Xinference. Vamos explorar juntos as infinitas possibilidades da inteligência artificial!
Pouco conhecimento sobre Greptime:
Greptime Greptime Technology foi fundada em 2022 e atualmente está melhorando e construindo três produtos: banco de dados de série temporal GreptimeDB, GreptimeCloud e ferramenta de observabilidade GreptimeAI.
GreptimeDB é um banco de dados de série temporal escrito em linguagem Rust. É distribuído, de código aberto, nativo da nuvem e altamente compatível. Ele ajuda as empresas a ler, escrever, processar e analisar dados de série temporal em tempo real, reduzindo os custos de armazenamento de longo prazo; fornecer aos usuários um serviço DBaaS totalmente gerenciado que pode ser altamente integrado com observabilidade, Internet das Coisas e outros campos. GreptimeAI é feito sob medida para LLM, fornecendo monitoramento completo de custos, desempenho e processos de geração;
GreptimeCloud e GreptimeAI foram oficialmente testados. Bem-vindo a seguir a conta oficial ou o site oficial para os últimos desenvolvimentos!

Site oficial: https://greptime.cn/
GitHub: https://github.com/GreptimeTeam/greptimedb
Documentação: https://docs.greptime.cn/
Twitter: https://twitter.com/Greptime
Folga: https://greptime.com/slack
LinkedIn: https://www.linkedin.com/company/greptime/
Um programador nascido na década de 1990 desenvolveu um software de portabilidade de vídeo e faturou mais de 7 milhões em menos de um ano. O final foi muito punitivo! Alunos do ensino médio criam sua própria linguagem de programação de código aberto como uma cerimônia de maioridade - comentários contundentes de internautas: Contando com RustDesk devido a fraude desenfreada, serviço doméstico Taobao (taobao.com) suspendeu serviços domésticos e reiniciou o trabalho de otimização de versão web Java 17 é a versão Java LTS mais comumente usada no mercado do Windows 10 Atingindo 70%, o Windows 11 continua a diminuir Open Source Daily | Google apoia Hongmeng para assumir o controle de telefones Android de código aberto apoiados pela ansiedade e ambição da Microsoft; Electric desliga a plataforma aberta Apple lança chip M4 Google exclui kernel universal do Android (ACK) Suporte para arquitetura RISC-V Yunfeng renunciou ao Alibaba e planeja produzir jogos independentes para plataformas Windows no futuro