
Autor: Jin Xuefeng
fundo
A execução de grandes modelos de linguagem em gráficos estáticos traz muitos benefícios, incluindo:
-
Melhoria de desempenho trazida pela otimização de fusão do operador/execução de gráfico inteiro; se for Ascend, você também pode usar toda a execução de afundamento do gráfico para melhorar ainda mais o desempenho, e toda a execução de afundamento do gráfico não é afetada pela execução do processamento de dados no lado do host, e o desempenho é estável e bom;
-
A orquestração de memória estática permite alta utilização de memória, sem fragmentação, aumenta o tamanho do lote e, assim, melhora o desempenho do treinamento;
-
Otimize automaticamente a sequência de execução e obtenha boa comunicação e simultaneidade de cálculo;
-
......
No entanto, também existem desafios na execução de grandes modelos de linguagem em imagens estáticas. O mais importante deles é o desempenho de compilação.
O processo de compilação do modelo de rede neural na verdade converte o código nn expresso em Python em um gráfico de cálculo de fluxo de dados:
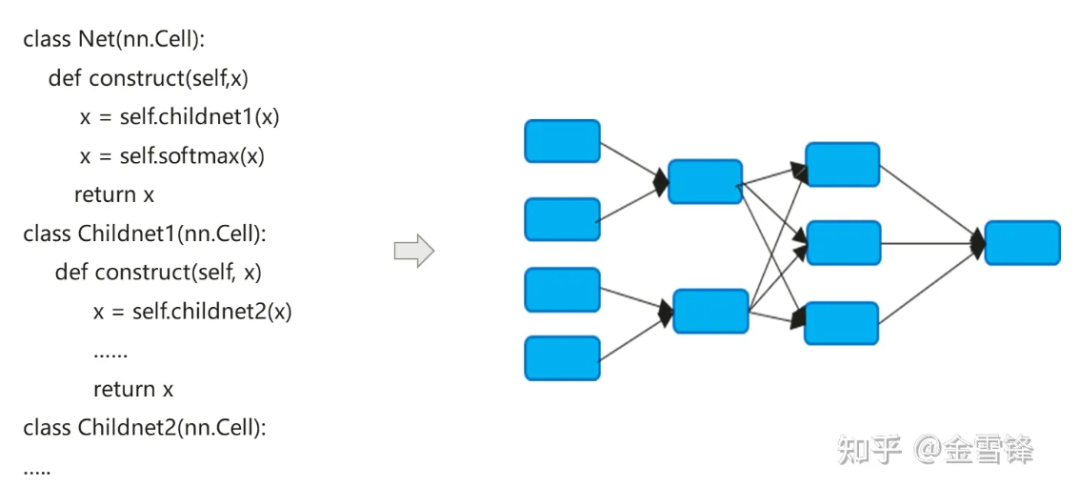
O processo de compilação de modelos de redes neurais é um pouco diferente dos compiladores tradicionais. O método Inline padrão é frequentemente usado para finalmente expandir a expressão do código hierárquico em um gráfico de cálculo plano. Por um lado, ele busca maximizar as oportunidades de otimização de compilação. por outro lado, também pode simplificar a diferenciação automática e a lógica de execução.
Por padrão, o gráfico de cálculo formado após o Inline inclui todos os nós de cálculo e os nós não possuem mais partições de gráfico de subcálculo. Portanto, a otimização no processo pode ser realizada em uma escala maior, como dobramento constante, fusão de nós, análise paralela. , etc., e pode realizar melhor a alocação de memória e reduzir a aplicação de memória e a sobrecarga de desempenho ao chamar entre procedimentos. Mesmo para unidades de computação que são chamadas repetidamente, os compiladores no campo de IA ainda usam a mesma estratégia inline. Ao pagar o preço da expansão do tamanho do programa e do crescimento do código executável, eles podem maximizar o uso de métodos de otimização de compilação para melhorar o desempenho do tempo de execução.
Como pode ser visto na descrição acima, a otimização in-line é muito útil para melhorar o desempenho do tempo de execução, mas correspondentemente, in-line excessivo também traz sobrecarga no tempo de compilação; À medida que o gráfico de subcomputação é integrado ao gráfico inteiro, de uma perspectiva global, o número de nós do gráfico de computação que o compilador precisa processar está se expandindo rapidamente. Os compiladores geralmente usam o mecanismo Pass para organizar e organizar métodos de otimização. Diferentes métodos de otimização são conectados em série na forma de Pass, e um processo de processamento passará por cada nó do gráfico de cálculo. O número de passagens de processamento depende do processo de correspondência e conversão do nó e da passagem. Às vezes, são necessárias várias passagens para concluir o processamento. De modo geral, se o número de passes for M e o número de nós do gráfico computacional for N, o tempo de todo o processo de compilação e otimização está diretamente relacionado ao valor de M * N. Na era dos grandes modelos de linguagem, esse problema tornou-se mais proeminente. Há duas razões principais: primeiro, a estrutura do modelo de grandes modelos de linguagem é profunda e possui um grande número de nós, em segundo lugar, ao treinar modelos de linguagem grandes, devido a; a habilitação do paralelismo do pipeline, a escala do modelo e os nós são reduzidos. O número aumenta ainda mais. Se o tamanho do gráfico original for O, habilite o paralelismo do pipeline e o tamanho do gráfico de nó único se tornará (O/X)*Y. , onde X é o número de estágios no pipeline e Y é o número de microlotes reais. Durante o processo de configuração, Y é muito maior que X. Por exemplo, X é 16 e Y geralmente é definido como 64-192. Dessa forma, depois que a paralelização do pipeline for habilitada, a escala de compilação do gráfico aumentará ainda mais para 4 a 12 vezes o tamanho original.

Tomando como exemplo uma certa rede 13B de dezenas de bilhões de modelos de linguagem, o número de nós de computação no gráfico de cálculo chega a 135.000, e um único tempo de compilação pode ser próximo a 3 horas.
**1.** Ideias de otimização
Observamos que a estrutura da rede neural de aprendizagem profunda é composta por múltiplas camadas. No modelo de linguagem de modelo grande, essas camadas são pilhas de blocos Transformer. Especialmente quando o paralelismo de pipeline está ativado, as camadas de cada microlote são exatamente as mesmas. . Portanto, nos perguntamos se podemos reter essas estruturas de camada sem Inline ou Inline antecipadamente, para que o desempenho da compilação possa ser melhorado exponencialmente. Por exemplo, se seguirmos o microlote como limite e retermos a estrutura do subgráfico do microlote, então, teoricamente, o tempo de compilação pode ser igual ao Y original (Y é o número de microlotes).
Específico para o código escrito no modelo, podemos ver que a forma de reutilizar a mesma camada é geralmente um loop ou chamada iterativa. A camada geralmente corresponde a um item da estrutura sequencial no processo iterativo, geralmente um subgráfico; usando um loop Ou iterar para chamar a mesma unidade de computação várias vezes, conforme mostrado no código abaixo, o bloco corresponde a um subgráfico de camada ou microlote.
class Block(nn.Cell):
def __init__(self, config):
.......
def construct(self, x, attention_mask, layer_past):
......
class GPT_Model(nn.Cell):
def __init__(self, config):
......
for i in range(config.num_layers):
self.blocks.append(Block)
......
self.num_layers = config.num_layers
def construct(self, input_ids, input_mask, layer_past):
......
present_layer = ()
for i in range(self.num_layers):
hidden_states, present = self.blocks[i](...)
present_layer = present_layer + (present,)
......
Portanto, se considerarmos o corpo do loop como um subgrafo frequentemente chamado e dissermos ao compilador para adiar o processamento inline marcando-o como Lazy Inline, então ganhos de desempenho poderão ser obtidos na maioria dos estágios de compilação. Por exemplo, quando a rede neural chama a mesma estrutura de subgráfico ciclicamente, não expandimos o subgráfico durante a fase de compilação, então, no final da compilação, a otimização Inline é acionada para realizar a otimização necessária e o processamento de conversão. Dessa forma, para o compilador, na maioria das vezes é um código de menor escala em vez de um código que foi expandido em linha, melhorando muito o desempenho da compilação.
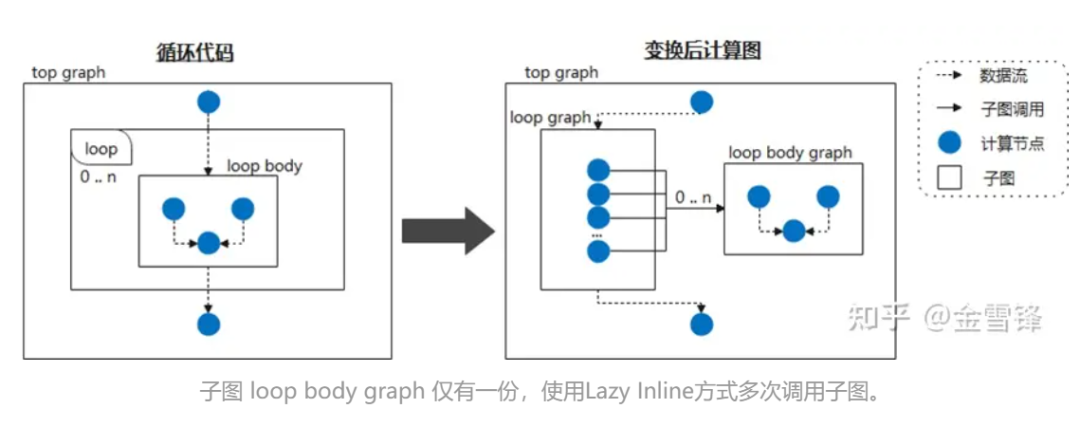
Durante a implementação específica, você pode colocar uma marca semelhante a @lazy-inline na classe Layer relevante para perguntar ao compilador se a camada marcada é chamada no corpo do loop ou de outras maneiras, ela não será incluída durante a expansão Inline. não é executado até antes da execução.
**2. ** Prática MindSpore
Parece que os princípios e ideias do Lazy Inline não são complicados, mas o mecanismo existente de compilação de gráficos de IA geralmente não é o tipo de compilador que suporta recursos completos de compilação, por isso ainda é muito desafiador realizar essa função.
Felizmente, o compilador gráfico do MindSpore considerou a versatilidade ao projetar IR, incluindo chamadas de subfunções, fechamentos e outros recursos.
① As instâncias de células são compiladas em gráficos de cálculo reutilizáveis
Cell é o bloco de construção básico da rede neural MindSpore e a classe base de todas as redes neurais. Cell pode ser uma única unidade de rede neural, como conv2d, relu, batch_norm, etc., ou pode ser uma combinação de unidades que constroem uma. rede. No GRAPH_MODE (modo gráfico estático), Cell será compilado em um gráfico de cálculo.
Quando precisar customizar a rede, você precisará herdar a classe Cell e substituir os métodos __init__ e construct. A classe Cell substitui o método __call__. Quando uma instância da classe Cell é chamada, o método construtor é executado. Defina a estrutura da rede no método de construção.
No exemplo a seguir, uma rede simples é construída para implementar a função de cálculo de convolução. Os operadores na rede são definidos em __init__ e usados no método de construção. A estrutura de rede do caso é: Conv2d -> BiasAdd.
No método de construção, x são os dados de entrada e a saída é o resultado obtido após o cálculo da estrutura da rede.
import mindspore.nn as nn
import mindspore.ops as ops
from mindspore import Parameter
from mindspore.common.initializer import initializer
from mindspore._extends import lazy_inline
class MyNet(nn.Cell):
@lazy_inline
def __init__(self, in_channels=10, out_channels=20, kernel_size=3):
super(Net, self).__init__()
self.conv2d = ops.Conv2D(out_channels, kernel_size)
self.bias_add = ops.BiasAdd()
self.weight = Parameter(initializer('normal', [out_channels, in_channels, kernel_size, kernel_size]))
def construct(self, x):
output = self.conv2d(x, self.weight)
output = self.bias_add(output, self.bias)
return output
@Lazy_Inline é o decorador de Cell::__init__ Sua função é gerar todos os parâmetros de __init__ no valor do atributo cell_init_args de Cell, self.cell_init_args = type(self).__name__ + str(arguments). O atributo cell_init_args serve como identificador exclusivo da instância Cell na compilação MindSpore. O mesmo valor cell_init_args indica que o nome da classe Cell e os valores dos parâmetros de inicialização são iguais.
construct(self, x) define a estrutura da rede, que é a mesma da classe Cell. A estrutura da rede depende dos parâmetros de entrada self e x. Self contém parâmetros como pesos. Esses pesos são inicializados aleatoriamente ou os resultados do treinamento, portanto, esses pesos são diferentes para cada instância da célula. Outros atributos próprios são determinados pelo parâmetro __init__, e o parâmetro __init__ é calculado por @lazy_inline para obter a identificação da instância Cell cell_init_args. Portanto, o gráfico de cálculo de compilação da instância Cell construct(self, x) é transformado em construct(x, self. cell_init_args, self.trainable_parameters() ).
Se for a mesma classe Cell e os parâmetros cell_init_args forem os mesmos, chamamos essas instâncias de neurônios de instâncias de neurônios reutilizáveis, e o gráfico de cálculo correspondente a esta instância de neurônio é denominado gráfico de cálculo reutilizável reuse_construct (X, self. trainable_parameters ()). Pode-se deduzir que o gráfico de cálculo de cada instância de Cell pode ser convertido em:
def construct(self, x)
Reuse_construct(x, self.trainable_parameters())
Após a introdução dos gráficos de computação reutilizáveis, as células neuronais (gráficos de computação reutilizáveis) com os mesmos cell_init_args só precisam ser compostas e compiladas uma vez. Quanto mais células houver na rede, melhor será o desempenho. Mas tudo tem dois lados. Se o gráfico de cálculo dessas células for muito pequeno ou muito grande, isso levará a uma má compilação e otimização de certos recursos, como fusão de operadores, multiplexação de memória, afundamento de gráfico inteiro e chamada de múltiplos gráficos, etc. .
Portanto, a versão MindSpore atualmente suporta apenas a identificação manual de quais estágios de compilação do Cell geram gráficos de cálculo reutilizáveis. As versões subsequentes planejarão estratégias automáticas para gerar gráficos de cálculo reutilizáveis, como quantos operadores uma célula contém, quantas vezes uma célula é usada e outros fatores para avaliar se deve gerar um gráfico de cálculo reutilizável e dar sugestões de otimização.
O seguinte usa a estrutura GPT para uma explicação abstrata e simplificada:
class Block(nn.Cell):
@lazy_inline
def __init__(self, config):
.......
def construct(self, x, attention_mask, layer_past):
......
class GPT_Model(nn.Cell):
def __init__(self, config):
......
for i in range(config.num_layers):
self.blocks.append(Block(config, None))
......
self.num_layers = config.num_layers
def construct(self, input_ids, input_mask, layer_past):
......
present_layer = ()
for i in range(self.num_layers):
hidden_states, present = self.blocks[i](...)
present_layer = present_layer + (present,)
......
GPT é composto por múltiplas camadas de Blocos. Os parâmetros de inicialização desses Blocos são todos iguais Config, portanto as estruturas desses Blocos são as mesmas, e serão convertidas internamente pelo compilador na seguinte estrutura:
def Reuse_Block(x, attention_mask, layer_past,block_parameters) :
......
具体的Block 实例的计算图如下:
def construct(self, x, attention_mask, layer_past):
return Reuse_Block(x, attention_mask, layer_past,
self. trainable_parameters())
Com esta estrutura, na primeira metade do processo de compilação, é um gráfico de cálculo independente e não é incorporado no gráfico de cálculo geral. Apenas a pequena quantidade final de otimização de passagem é incorporada no gráfico de cálculo grande.
② A combinação de L****azy Inline e diferenciação/paralelo/recálculo automático e outros recursos
Após a adoção da solução da Lazy Inline, esta terá algum impacto no processo original e necessitará de adaptações relevantes, principalmente diferenciação automática, paralelismo e recálculo.
Para diferenciação automática, aparece um nó de encaminhamento semelhante à função de chamada e é necessário fornecer processamento de diferenciação;
Para processos paralelos, o principal é que o processamento de passagem paralela do Pipeline precisa ser adaptado a cenários de imagem não completa, porque o corte anterior do Pipeline era baseado na imagem inteira, mas agora precisa ser cortado com base no subgráfico compartilhado. O plano específico é primeiro colorir de acordo com o Estágio, dividir os nós na Célula compartilhada de acordo com o Estágio, reter apenas os nós correspondentes ao Estágio do processo atual e inserir o operador Enviar/Receber e depois dividir os nós fora da célula compartilhada, retendo os nós correspondentes do processo atual. O nó de estágio também retira o operador Send/Recv na célula compartilhada;
Para o processo de recálculo, o antigo processo de recálculo processa operadores em todo o gráfico após Inline. Ao procurar blocos de operadores contínuos recalculados, os operadores que precisam ser recalculados e os parâmetros de recálculo são determinados de acordo com a configuração de recálculo do usuário. operador do qual depende a execução do operador calculado. Após o Lazy Inline, os operadores de recálculo consecutivos podem estar em subgráficos diferentes e nenhum relacionamento de conexão pode ser encontrado entre o nó direto e o nó reverso, portanto, a estratégia de pesquisa original baseada no operador do gráfico inteiro falha.
Nosso plano de adaptação é processar células ou operadores recalculados após diferenciação automática. O processo de diferenciação automática irá gerar um fechamento para o subgrafo ou operador único produzido por Cell, que retorna a saída direta e a função de retropropagação, e também obtemos o relacionamento entre cada fechamento e a parte direta original de um mapeamento. Através dessas informações, com base na configuração de recálculo do usuário, cada fechamento é usado como unidade básica, a célula e o operador são processados uniformemente, e a parte direta original é copiada de volta para o gráfico original, e o relacionamento de dependência pode ser passado. o fechamento no fechamento. A aquisição da função Backpropagation pode finalmente alcançar um esquema de recálculo que não depende do Inline de todo o gráfico.
③Processamento e impacto de back-end
O IR gerado após ativar o Lazy Inline no front-end é enviado para o back-end. O back-end precisa fatiar o IR antes que ele possa ser executado no dispositivo por meio do afundamento de subgráfico. Porém, após o Lazy Inline, ainda haverá alguns problemas na execução do afundamento de subgráficos, como a incapacidade de usar o método ideal para reutilização de memória e alocação de fluxo, a incapacidade de usar o cache interno do gráfico para aceleração de compilação durante a compilação , e a incapacidade de fazer otimização de gráficos cruzados (otimização de memória, fusão de comunicação, fusão de operadores, etc.) e outros problemas.
Para obter o desempenho ideal, o backend precisa processar o IR do Lazy Inline em um formato adequado para execução de afundamento de backend. A principal coisa a fazer é converter o operador Partial gerado pela diferenciação automática em uma chamada de subgráfico comum e alterar o. variáveis capturadas em Passe-as como parâmetros comuns, para que todo o gráfico possa ser afundado e toda a rede possa ser executada.
Em todo o processo de afundamento do gráfico, essas chamadas possuem dois métodos de processamento: Inline no gráfico e Inline na sequência de execução. Inline no gráfico fará com que o gráfico se expanda e a velocidade de compilação subsequente será mais lenta, no entanto, inline da sequência de execução fará com que o ciclo de vida da memória de parte da sequência de execução Inline seja particularmente longo durante a reutilização da memória e no acabar com a memória não será suficiente.
No final, o método de processamento que adotamos foi reutilizar a sequência de execução do processo Inline na passagem de otimização, seleção de operadores, compilação de operadores e outros processos para tornar o tamanho do gráfico o menor possível e evitar muitos nós do gráfico afetando o back-end compilação do gráfico de tempo. Antes de executar a otimização de sequência, alocação de fluxo, reutilização de memória e outros processos, essas chamadas são feitas em nós reais Inline para obter o efeito ideal de reutilização de memória. Além disso, por meio de alguma otimização de memória e comunicação, eliminação de cálculos redundantes e outros métodos após o grafo inline, é possível não degradar a memória e o desempenho.
Atualmente, não é possível obter todas as otimizações em nível de gráfico cruzado. A identificação de ponto único só pode ser colocada no estágio após o Inline, e é impossível economizar tempo na otimização da ordem de execução, alocação de fluxo e reutilização de memória.
④Alcançar efeitos
A otimização do desempenho de compilação de modelos grandes usa a solução Lazy Inline para melhorar o desempenho de compilação em 3 a 8 vezes. Tomando como exemplo a rede 13B do modelo grande de 10 bilhões, após aplicar a solução Lazy Inline, a escala de compilação do gráfico de cálculo caiu de 130.000+. nós para mais de 20.000 nós Node, o tempo de compilação foi reduzido de 3 horas para 20 minutos e, combinado com o armazenamento em cache dos resultados da compilação, a eficiência geral foi bastante melhorada.
⑤Restrições de uso e próximas etapas
1. Cell O identificador da instância Cell é gerado com base no nome da classe Cell e no valor do parâmetro __init__. Isso se baseia na suposição de que os parâmetros do init determinam todas as propriedades da Cell e que as propriedades da Cell no início da composição da construção são consistentes com as propriedades após a execução do init. Portanto, as propriedades da Cell relacionadas à composição não podem ser alteradas. após o init ser executado.
2. Os parâmetros da função de construção não podem ter valores padrão. Se a versão existente do MindSpore tiver valores padrão para os parâmetros da função de construção, cada vez que for usada, ela será especializada em um novo gráfico de cálculo. As versões subsequentes otimizarão o mecanismo de especialização original;
3. A célula consiste em várias instâncias Cell_X compartilhadas e cada Cell_X consiste em várias instâncias Cell_Y compartilhadas. Se o init de Cell_X e Cell_Y for decorado como @lazy_inline, apenas o Cell_X mais externo poderá ser compilado em um gráfico de cálculo reutilizado, e o gráfico de cálculo do Cell_Y interno ainda será Inline. As versões subsequentes planejam suportar esse inline lento de vários níveis; mecanismo.
Como auxiliar os clientes a escrever código com alta coesão e baixo acoplamento também é um dos objetivos perseguidos pelo framework MindSpore. Por exemplo, existe este parâmetro Block:: __init__ em uso, que contém o índice da camada. outros parâmetros são os mesmos, já que o Índice de Camada é usado a cada camada. Cada camada é diferente, fazendo com que o Bloco não seja reutilizável devido a diferenças sutis. Por exemplo, o código a seguir existe em um determinado código de versão GTP:
class Block (nn.Cell):
"""
Self-Attention module for each layer
Args:
config(GPTConfig): the config of network
scale: scale factor for initialization
layer_idx: current layer index
"""
def __init__(self, config, scale=1.0, layer_idx=None):
......
if layer_idx is not None:
self.coeff = math.sqrt(layer_idx * math.sqrt(self.size_per_head))
self.coeff = Tensor(self.coeff)
......
def construct(self, x, attention_mask, layer_past=None):
......
Para tornar o Bloco reutilizável, podemos otimizá-lo, extrair os cálculos relacionados ao Índice de Camada, e então utilizá-los como parâmetros do Construct para inseri-los na composição original, para que os parâmetros de inicialização do Bloco sejam os mesmos.
Modifique o segmento de código acima para o segmento de código a seguir, exclua as partes relacionadas a Init e Layer Index e adicione o parâmetro coeff para construir.
class Block (nn.Cell):
def __init__(self, config, scale=1.0):
......
def construct(self, x, attention_mask, layer_past, coeff):
......
Nas versões subsequentes do Shengsi MindSpore, planejamos identificar esses blocos sutilmente diferentes e fornecer sugestões de otimização para esses blocos para otimização e melhoria.
Um programador nascido na década de 1990 desenvolveu um software de portabilidade de vídeo e faturou mais de 7 milhões em menos de um ano. O final foi muito punitivo! Google confirmou demissões, envolvendo a "maldição de 35 anos" dos programadores chineses nas equipes Flutter, Dart e . Python Arc Browser para Windows 1.0 em 3 meses oficialmente GA A participação de mercado do Windows 10 atinge 70%, Windows 11 GitHub continua a diminuir a ferramenta de desenvolvimento nativa de IA GitHub Copilot Workspace JAVA. é a única consulta de tipo forte que pode lidar com OLTP + OLAP. Este é o melhor ORM. Nos encontramos tarde demais.