
Open-Sora foi atualizado discretamente na comunidade de código aberto! Uma única lente agora suporta geração de vídeo de até 16 segundos em resoluções de até 720p e pode lidar com qualquer proporção de aspecto de texto para imagem, texto para vídeo, imagem para vídeo, vídeo para vídeo e geração de vídeo de duração ilimitada precisa. Vamos tentar o efeito.
Gere uma cena de neve de Natal em tela horizontal e publique-a no site B

Crie uma tela vertical novamente e faça Douyin

Também pode gerar vídeos longos com uma única sequência de 16 segundos, agora todos podem ficar viciados em roteiros.

Como jogar? Instruções para GitHub: github.com/hpcaitech/Open-Sora
O que é ainda mais legal é que a versão mais recente do Open-Sora ainda é de código aberto e cheia de sinceridade. O warehouse contém a arquitetura de modelo mais recente, os pesos de modelo mais recentes, processos de treinamento multitempo/resolução/proporção/taxa de quadros, coleta de dados. e O processo completo de pré-processamento, todos os detalhes do treinamento, exemplos de demonstração e tutoriais detalhados de introdução .
1. Interpretação abrangente de relatórios técnicos
Recentemente, a equipe de autores do Open-Sora lançou oficialmente a versão mais recente do relatório técnico [1] no GitHub. Abaixo, usaremos o relatório técnico para interpretar as funções, arquitetura, métodos de treinamento, coleta de dados, pré-processamento e outros. aspectos um por um.
1.1 Visão geral dos recursos mais recentes
Esta atualização do Open-Sora inclui principalmente os seguintes recursos principais:
- Suporta geração de vídeos longos;
- A resolução de geração de vídeo pode chegar até 720p;
- Um único modelo suporta qualquer proporção de aspecto, diferentes resoluções e durações de texto para imagem, texto para vídeo, imagem para vídeo, vídeo para vídeo e necessidades ilimitadas de geração de vídeo;
- Propôs um design de arquitetura de modelo mais estável que suporta treinamento multitempo/resolução/proporção/taxa de quadros;
- O mais recente processo de processamento automático de dados é de código aberto;
1.2 Modelo de difusão espaço-tempo
Esta atualização do Open-Sora trouxe melhorias importantes à arquitetura STDiT na versão 1.0, com o objetivo de melhorar a estabilidade do treinamento e o desempenho geral do modelo. Para a tarefa atual de previsão de sequência, a equipe adotou as melhores práticas de modelos de linguagem grande (LLM) e substituiu a codificação posicional senoidal na atenção temporal pela codificação posicional rotacional mais eficiente (incorporação RoPE).
Além disso, a fim de melhorar a estabilidade do treino, referiram-se à arquitectura do modelo SD3 e introduziram ainda a tecnologia de normalização QK para melhorar a estabilidade do treino de meia precisão. A fim de suportar os requisitos de treinamento de múltiplas resoluções, diferentes proporções e taxas de quadros, a arquitetura ST-DiT-2 proposta pela equipe do autor pode dimensionar automaticamente a codificação de posição e lidar com entradas de diferentes tamanhos.
1.3 Treinamento em vários estágios
O relatório técnico afirma que o Open-Sora utiliza um método de treinamento em vários estágios, onde cada estágio continua o treinamento com base nos pesos do estágio anterior. Comparado com o treinamento de estágio único, este treinamento de vários estágios atinge o objetivo de geração de vídeo de alta qualidade de forma mais eficiente, introduzindo dados passo a passo.
- Estágio inicial: A maioria dos vídeos usa resolução 144p, e são misturados com fotos e vídeos 240p e 480p para treinamento. O treinamento dura cerca de 1 semana e o tamanho total da etapa é de 81k.
- A segunda etapa: aumentar a resolução da maioria dos dados de vídeo para 240p e 480p, com tempo de treinamento de 1 dia e tamanho de passo de 22k.
- A terceira etapa: aprimorada para 480p e 720p, a duração do treinamento é de 1 dia e o treinamento de 4k etapas é concluído. Todo o processo de treinamento em várias etapas foi concluído em aproximadamente 9 dias.
Comparada com a 1.0, a versão mais recente melhora a qualidade da geração de vídeo em múltiplas dimensões.
1.4 Estrutura unificada de geração de vídeo/geração de vídeo
A equipe do autor afirmou que, com base nas características do Transformer, a arquitetura DiT pode ser facilmente estendida para suportar tarefas de imagem para imagem e vídeo para vídeo. Eles propuseram uma estratégia de mascaramento para apoiar o processamento condicional de imagens e vídeos. Ao definir máscaras diferentes, várias tarefas de geração podem ser suportadas, incluindo: vídeo gráfico, vídeo em loop, extensão de vídeo, geração autoregressiva de vídeo, conexão de vídeo, edição de vídeo, inserção de quadros, etc.
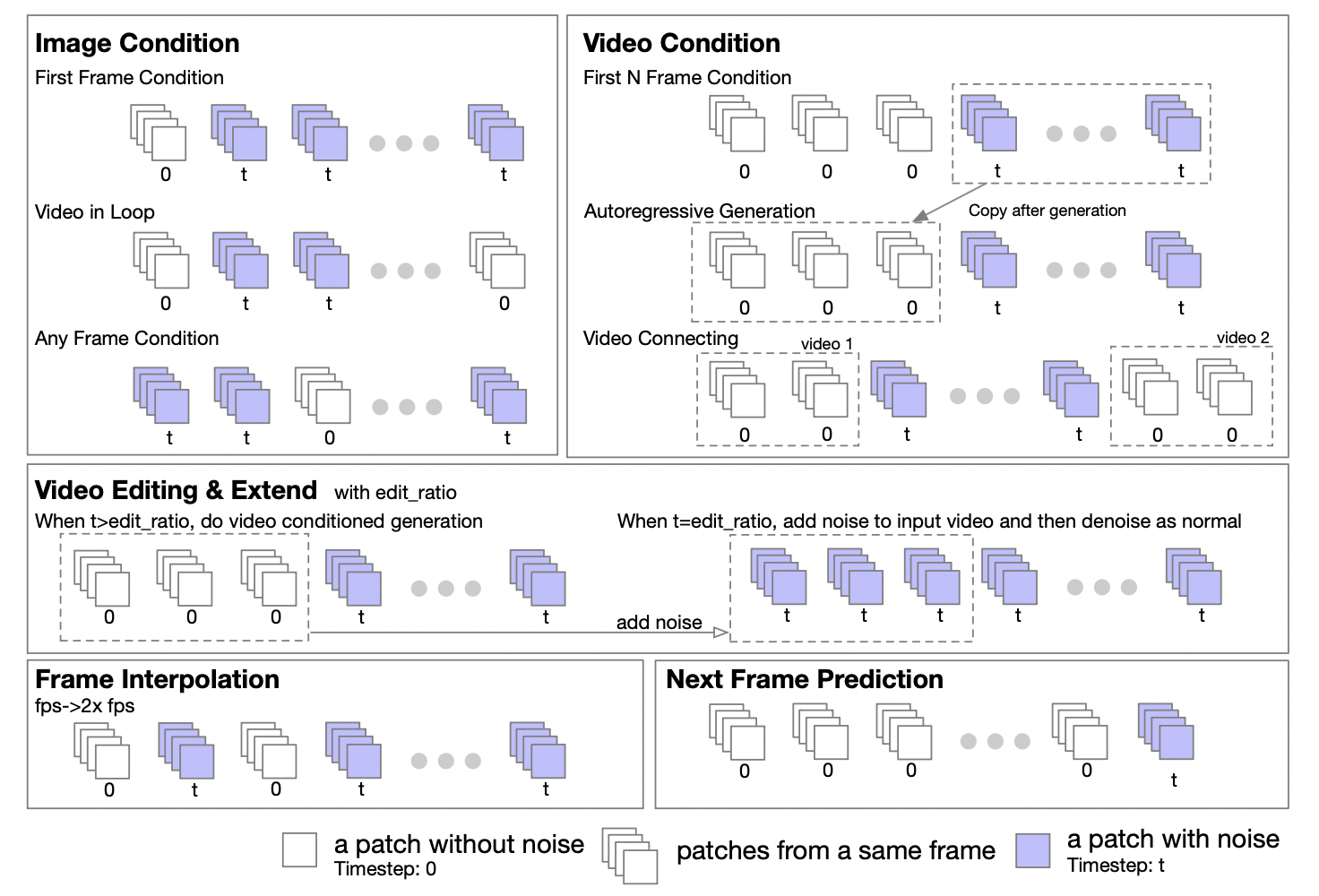
Inspirados no método UL2[2], eles introduziram uma estratégia de mascaramento aleatório no estágio de treinamento do modelo. Especificamente, trata-se de selecionar e desmascarar quadros aleatoriamente durante o processo de treinamento, incluindo, mas não se limitando a, desmascarar o primeiro quadro, os primeiros k quadros, os próximos k quadros, quaisquer k quadros, etc. O relatório também revelou que com base em experimentos no Open-Sora 1.0, ao aplicar a estratégia de mascaramento com 50% de probabilidade, o modelo pode aprender melhor a lidar com o condicionamento de imagem com apenas algumas etapas. Na versão mais recente do Open-Sora, eles adotaram um método de pré-treinamento do zero usando uma estratégia de mascaramento.
Além disso, a equipe de autores também fornece orientações detalhadas para a configuração da política de mascaramento para o estágio de inferência. A forma de tupla de cinco números fornece grande flexibilidade e controle ao definir a política de mascaramento.
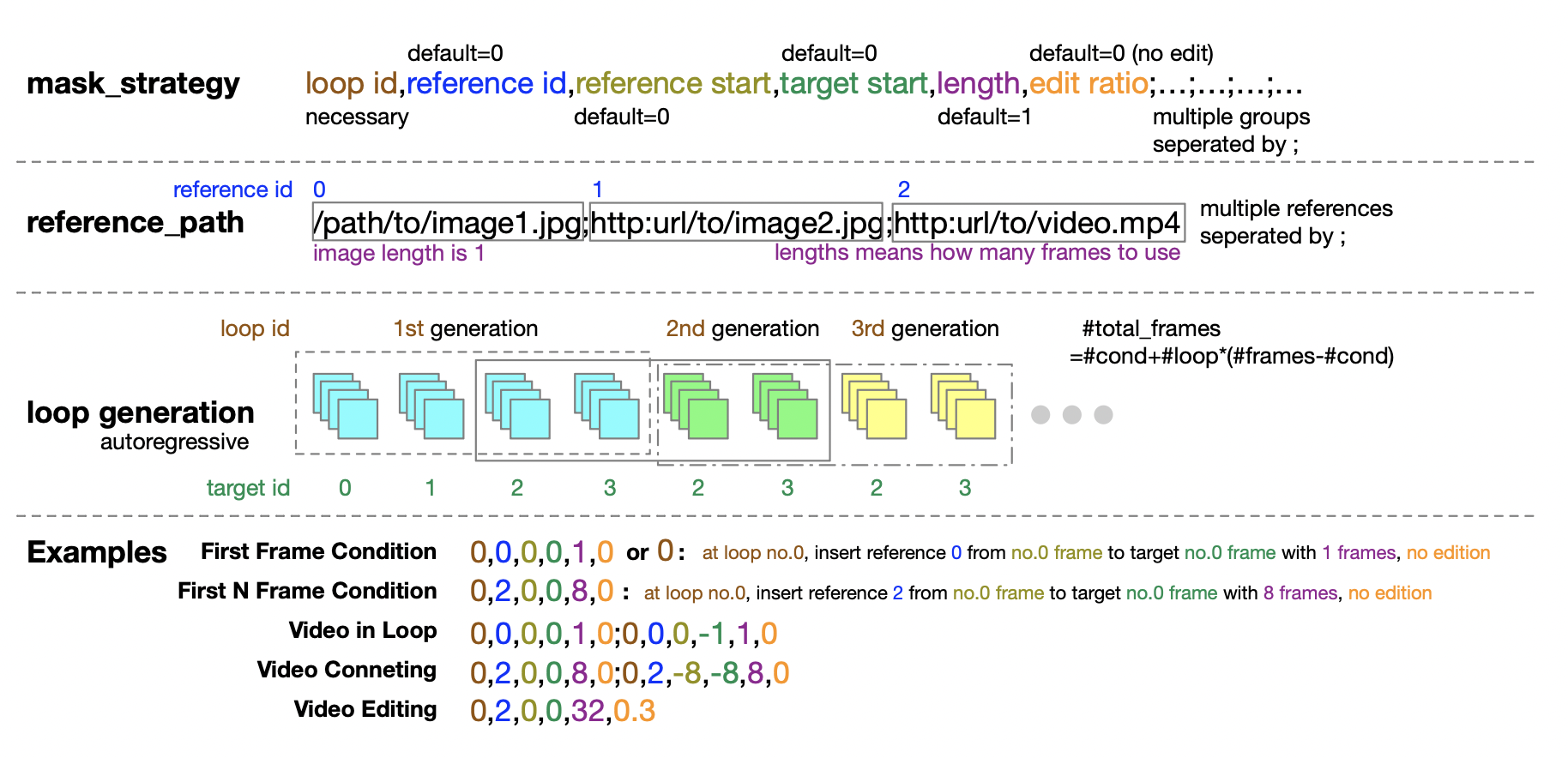
1.5 Suporta treinamento multitempo/resolução/proporção/taxa de quadros
O relatório técnico do OpenAI Sora [3] aponta que o treinamento usando a resolução, proporção e duração do vídeo original pode aumentar a flexibilidade de amostragem e melhorar os quadros e a composição. Nesse sentido, a equipe de autores propôs uma estratégia de agrupamento.
Como implementá-lo especificamente? Através da leitura aprofundada do relatório técnico divulgado pelo autor, ficamos sabendo que o chamado bucket é um trio de (resolução, número de frames, proporção). Eles predefinem uma variedade de proporções para vídeos em diferentes resoluções para cobrir os tipos de proporções de vídeo mais comuns. Antes do início de cada ciclo de treinamento epoch, eles reorganizam o conjunto de dados e atribuem amostras aos grupos correspondentes com base em suas características. Especificamente, eles colocam cada amostra em um balde cuja resolução e comprimento de quadro são menores ou iguais ao recurso de vídeo.
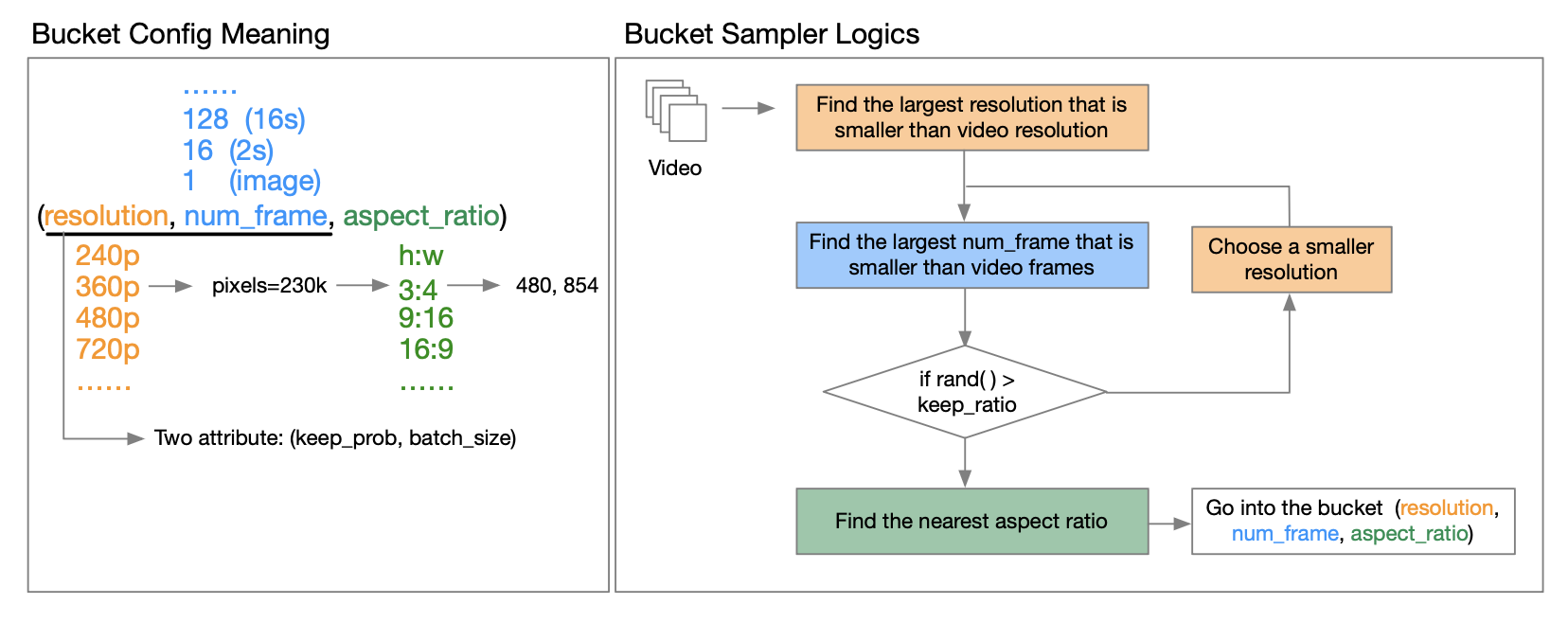
Para reduzir os requisitos de recursos computacionais, eles introduzem dois atributos (resolução, número de quadros) para cada um keep_probe para reduzir custos computacionais e permitir treinamento em vários estágios. batch_sizeIsso permite controlar o número de amostras em diferentes intervalos e equilibrar a carga da GPU procurando um bom tamanho de lote para cada intervalo. Isso é explicado em detalhes no relatório técnico. Amigos interessados podem ler o relatório técnico no GitHub para obter mais informações.
Endereço GitHub: github.com/hpcaitech/Open-Sora
1.6 Processo de coleta e pré-processamento de dados
A equipe de autores ainda fornece orientações detalhadas sobre coleta e processamento de dados. Segundo o relatório técnico, durante o processo de desenvolvimento do Open-Sora 1.0, eles perceberam que a quantidade e a qualidade dos dados são extremamente críticas para o cultivo de um modelo de alto desempenho, por isso trabalharam para expandir e otimizar o conjunto de dados. Eles estabeleceram um processo automatizado de processamento de dados que segue o princípio da decomposição de valor singular (SVD) e abrange segmentação de cena, processamento de legendas, pontuação e filtragem de diversidade, bem como o sistema de gerenciamento e especificação do conjunto de dados.
Da mesma forma, eles compartilham abnegadamente scripts relacionados ao processamento de dados com a comunidade de código aberto. Os desenvolvedores interessados agora podem usar esses recursos, combinados com relatórios técnicos e códigos, para processar e otimizar com eficiência seus próprios conjuntos de dados.
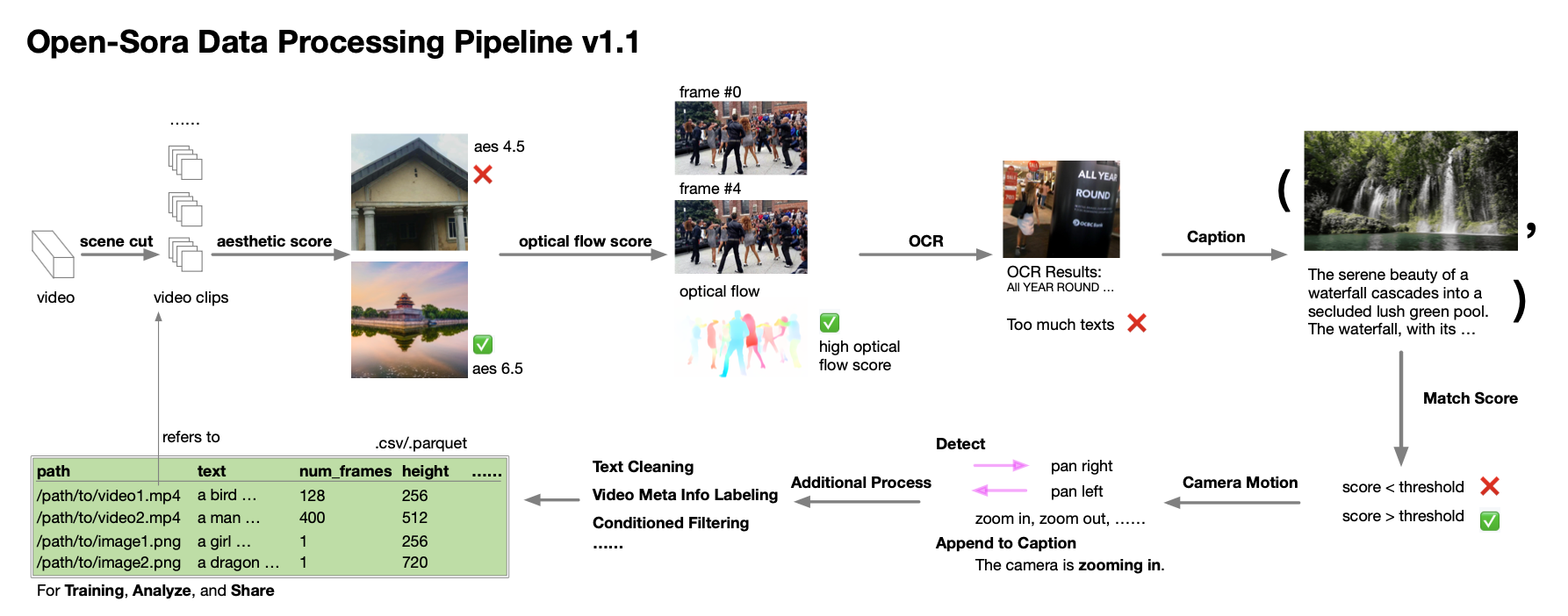
2. Avaliação abrangente de desempenho
Dito tantos detalhes técnicos, vamos aproveitar os efeitos de última geração de vídeo do Open-Sora e relaxar.
O destaque mais chamativo desta atualização do Open-Sora é que ele pode capturar e transformar a cena em sua mente em um vídeo em movimento por meio de uma descrição de texto. As imagens e imaginações que passam pela sua mente agora podem ser gravadas permanentemente e compartilhadas com outras pessoas. Aqui, o autor tentou vários prompts diferentes como ponto de partida.
2.1 Paisagem
Por exemplo, o autor tentou gerar um vídeo de um passeio em uma floresta de inverno. Não muito depois da neve cair, os pinheiros estavam cobertos de neve branca e flocos de neve brancos estavam espalhados em camadas claras.

Ou, numa noite tranquila, você está em uma floresta escura como aquela descrita em inúmeros contos de fadas, com o lago profundo brilhando sob as estrelas brilhantes por todo o céu.

A vista noturna da movimentada ilha vista do ar é ainda mais bonita. As luzes amarelas quentes e a água azul em forma de fita fazem com que as pessoas sejam instantaneamente atraídas para os momentos de lazer das férias.

A cidade está repleta de trânsito, e os arranha-céus e as lojas de rua com luzes ainda acesas tarde da noite têm um sabor diferente.

2.2 Organismos naturais
Além das paisagens, o Open-Sora também pode restaurar diversas criaturas naturais. Quer seja uma pequena flor vermelha,

Quer seja um camaleão virando lentamente a cabeça, o Open-Sora pode gerar vídeos mais realistas.

2.3 Diferentes resoluções/proporções/durações
O autor também tentou uma variedade de testes imediatos e forneceu muitos vídeos gerados para sua referência, incluindo conteúdo diferente, resoluções diferentes, proporções diferentes e durações diferentes.



O autor também descobriu que com apenas um comando simples, o Open-Sora pode gerar videoclipes em multi-resolução, quebrando completamente as limitações criativas.



2.4 Vídeo Tusheng
Também podemos alimentar o Open-Sora com uma imagem estática e fazer com que ele gere um pequeno vídeo.

Open-Sora também pode conectar habilmente duas imagens estáticas. Clique no vídeo abaixo e você experimentará as mudanças de luz e sombra da tarde ao anoitecer.

2.5 Edição de vídeo
Para outro exemplo, queremos editar o vídeo original. Com apenas um comando simples, a floresta originalmente brilhante deu início a uma forte nevasca.


2.6 Gere imagens de alta definição
Também podemos permitir que o Open-Sora gere imagens de alta definição:

É importante notar que os pesos dos modelos do Open-Sora foram disponibilizados publicamente gratuitamente em sua comunidade de código aberto. Como eles também suportam a função de emenda de vídeo, isso significa que você tem a oportunidade de criar um conto com uma história gratuitamente para dar vida à sua criatividade.
Endereço de download de peso: github.com/hpcaitech/Open-Sora
3. Limitações atuais e planos futuros
Embora o Open-Sora tenha feito bons progressos na reprodução de modelos de vídeo Vincent semelhantes ao Sora, a equipe do autor também apontou humildemente que os vídeos gerados atualmente ainda precisam ser melhorados em muitos aspectos, incluindo problemas de ruído durante o processo de geração, falta de tempo consistência, baixa qualidade de geração de personagens e baixas pontuações estéticas.
Em relação a estes desafios, a equipa de autores afirmou que dará prioridade à sua resolução no desenvolvimento da próxima versão, de forma a atingir padrões mais elevados de geração de vídeo. Os amigos interessados podem continuar a prestar atenção. Estamos ansiosos pela próxima surpresa que a comunidade Open-Sora nos trará.
Endereço GitHub: github.com/hpcaitech/Open-Sora
referências:
[1] https://github.com/hpcaitech/Open-Sora/blob/main/docs/report_02.md
[2] Tay, Yi, et al. "Ul2: Unificando paradigmas de aprendizagem de línguas." Pré-impressão arXiv arXiv:2205.05131 (2022).
[3] https://openai.com/research/video-generation-models-as-world-simulators
Decidi desistir do código aberto Hongmeng Wang Chenglu, o pai do código aberto Hongmeng: Hongmeng de código aberto é o único evento de software industrial de inovação arquitetônica na área de software básico na China - o OGG 1.0 é lançado, a Huawei contribui com todo o código-fonte. Google Reader é morto pela "montanha de merda de código" Fedora Linux 40 é lançado oficialmente Ex-desenvolvedor da Microsoft: o desempenho do Windows 11 é "ridiculamente ruim" Ma Huateng e Zhou Hongyi apertam as mãos para "eliminar rancores" Empresas de jogos conhecidas emitiram novos regulamentos : os presentes de casamento dos funcionários não devem exceder 100.000 yuans Ubuntu 24.04 LTS lançado oficialmente Pinduoduo foi condenado por concorrência desleal Compensação de 5 milhões de yuans