
Esta citação da Charity Majors provavelmente resume melhor o estado atual de observabilidade na indústria de tecnologia – um caos massivo e completo. Todo mundo está confuso. O que é rastreamento? O que é extensão? Uma linha de log é um intervalo? Se eu tiver registros, ainda preciso rastrear? Se eu tiver boas métricas, por que preciso de rastreamento? A lista continua e continua. Charity, juntamente com outras grandes mentes dos sistemas observáveis Honeycomb , tem trabalhado arduamente para resolver esses problemas. No entanto, com base na minha própria experiência, ainda é difícil explicar o que Charity quer dizer quando diz “logs são lixo”, muito menos que log e rastreamento são essencialmente a mesma coisa. Por que todos estão tão confusos?
Correndo um pequeno risco, vou culpar a Telemetria Aberta. Sim, é a força motriz da moderna pilha de observabilidade, mas eu a culpo pela bagunça. Não porque seja uma solução ruim – é brilhante! No entanto, a sua introdução e explicação dos conceitos e funções da Telemetria Aberta fazem com que a observabilidade pareça complicada e complicada.
Primeiro, a Open Telemetry distingue claramente entre rastreamentos, métricas e logs desde o início:
OpenTelemetry é uma coleção de APIs, SDKs e ferramentas que podem ser usados para instrumentar, gerar, coletar e exportar dados de telemetria (métricas, logs e rastreamentos) para ajudá-lo a analisar o desempenho e a coleta de comportamento do seu software.
Em seguida, explique cada uma dessas três questões com mais detalhes.
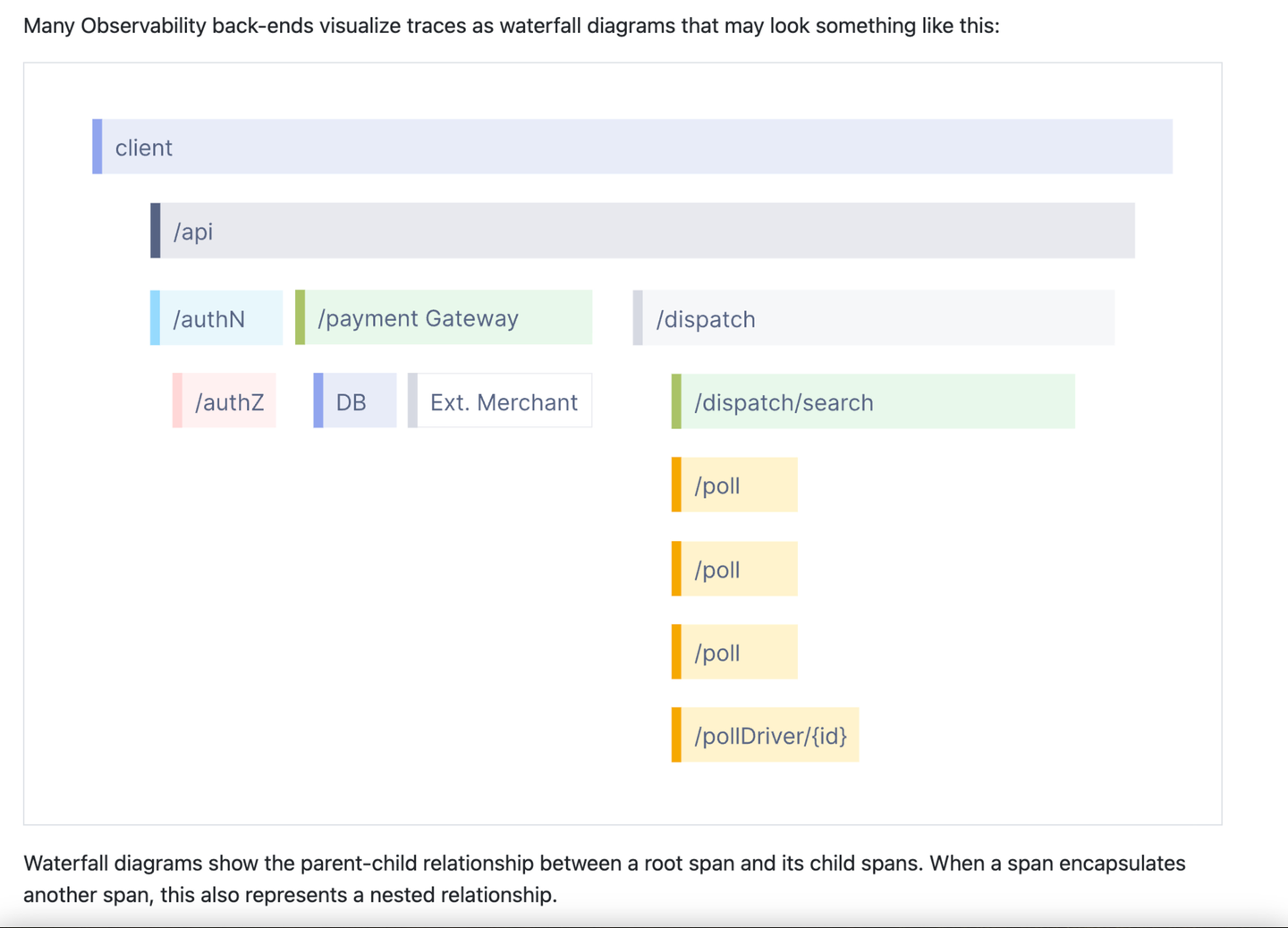
Esta é uma captura de tela parcial da introdução do trace no site OpenTelemetry. Na minha experiência conversando com a equipe da OpenTelemetry, esta apresentação realmente se tornou uma das principais imagens relacionadas à observabilidade. Para alguns, isso é observabilidade. Também distingue o traço de qualquer outra coisa. Obviamente, isso não é um registro, certo? Isso também não parece um indicador, certo? Isso é algo especial, talvez um pouco incrível, e requer dedicação ao aprendizado. Na minha experiência, uma vez que as pessoas entendem os traços, elas só pensam neles no contexto desta imagem e em termos relacionados como extensão, extensão raiz, extensão aninhada, etc. O site OpenTelemetry possui uma página de glossário com mais de 60 termos ! É tudo extremamente complicado!
Mas o mais importante é que esse foco em “logs, métricas e rastreamentos de links” representa o verdadeiro poder da observabilidade? Claro, cobre alguns cenários, mas quando se trata de sistemas distribuídos de grande escala, é mais importante ser capaz de se aprofundar nos dados - "cortá-los e cortá-los", construir e analisar várias visualizações, fazer correlações Análise sexual, procurando anomalias... e existem sistemas que fornecem todas essas capacidades.
Mergulho: Paraíso da Observabilidade
Quando trabalhei na Meta, não percebi que tive a sorte de trabalhar com o melhor sistema de observabilidade já criado. Esse sistema se chama Scuba e é a coisa que as pessoas mais sentem falta depois de deixar a Meta Corporation.
A ideia básica do Scuba é simples o suficiente para que não seja necessário ler páginas de terminologia para entendê-la. Ele usa eventos amplos. Um evento generalizado é apenas uma coleção de campos com nomes e valores, assim como um documento JSON. Se você precisar registrar alguma informação - seja o estado atual do sistema ou causado por uma chamada de API, trabalho em segundo plano ou outro evento - basta escrever alguns eventos generalizados no Scuba. Por exemplo, se um sistema veicula publicidade, ele naturalmente desejará registrar as impressões do anúncio – ou seja, o fato de um anúncio ter sido visto por um usuário. O evento generalizado correspondente pode ser assim:
{
"Timestamp": "1707951423",
"AdId": "542508c92f6f47c2916691d6e8551279”,
"UserCountry": "US",
"Placement": "mobile_feed",
"CampaingType": "direct_ads",
"UserOS": "Android",
"OSVersion": "14",
"AppVersion": "798de3c28b074df9a24a479ce98302b6",
"...": ""
}Tais eventos são chamados de eventos generalizados porque todas as informações concebíveis são encorajadas a serem armazenadas neles. Qualquer coisa que possa ser relevante no contexto desses dados específicos - basta divulgá-los e poderá ser útil mais tarde. Esta abordagem estabelece as bases para lidar com o desconhecido - coisas que não podem ser pensadas agora e que podem ser reveladas durante uma investigação de acidente.
Lidar com situações desconhecidas e desconhecidas pode ser melhor ilustrado com um exemplo. O Scuba possui uma interface intuitiva e fácil de usar que facilita a exploração e operação. Possui uma seção para selecionar quais métricas visualizar e seções para filtragem e agrupamento - o Scuba traçará um belo gráfico de série temporal. Uma primeira olhada no conjunto de dados de impressões de anúncios simplesmente traçará um gráfico contendo o número de impressões:
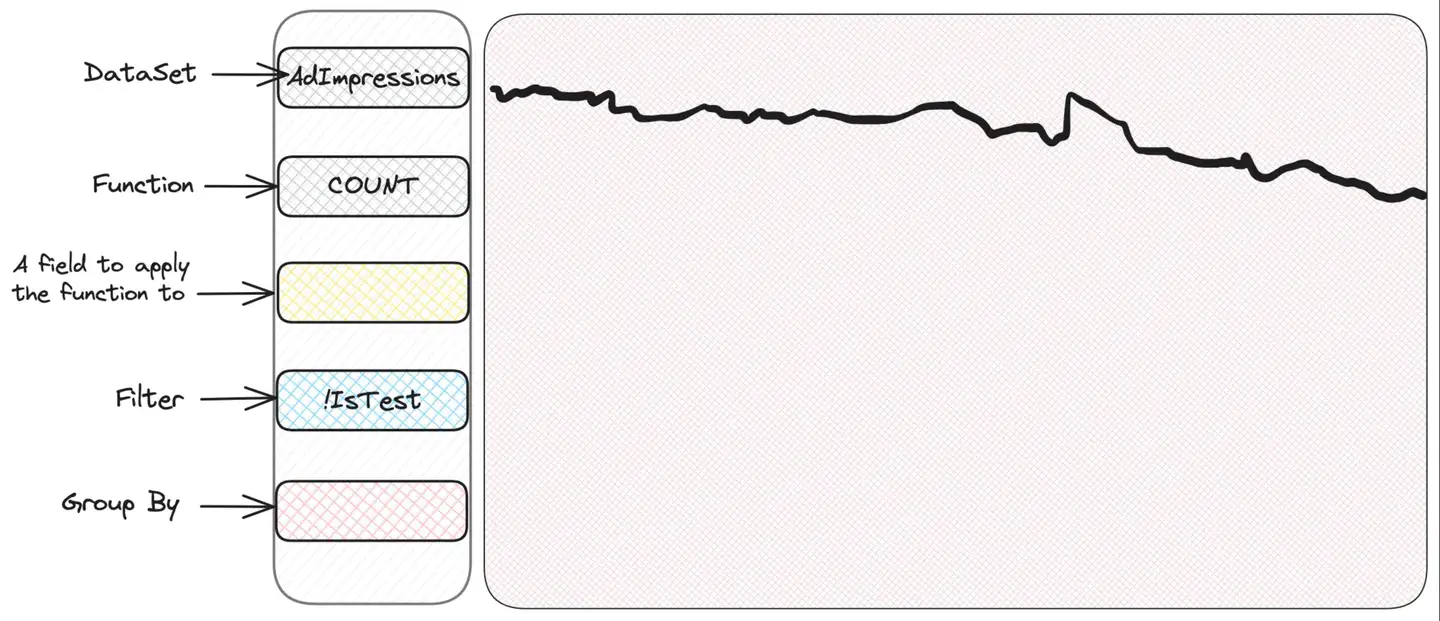
Se expressássemos em SQL o que exatamente está selecionado aqui, seria assim:
SELECT COUNT(*) FROM AdImpressions
WHERE IsTest = FalseEste não é inteiramente o caso. O Scuba também apresenta o conceito de amostragem nativa. Quando um evento é escrito no Scuba, um campo chamado , que representa a taxa de amostragem deste evento específico, também deve ser escrito. O Scuba usa essas informações para "ampliar" corretamente os resultados exibidos no gráfico, portanto, não há necessidade de fazer essa ampliação mentalmente. Este é um ótimo conceito porque permite amostragem dinâmica - por exemplo, um determinado tipo de apresentação pode ser amostrado com mais frequência do que outro tipo de apresentação, preservando os valores "reais" na IU. Portanto, a consulta real abaixo é: samplingRate
SELECT SUM(samplingRate) FROM AdImpressions
WHERE IsTest = False Observe que todo o “zoom in” é feito de forma transparente pela UI e o usuário não precisa pensar nisso durante a consulta. Então, digamos que algum alerta ocorra e nosso precioso gráfico de impressões de anúncios pareça estranho:
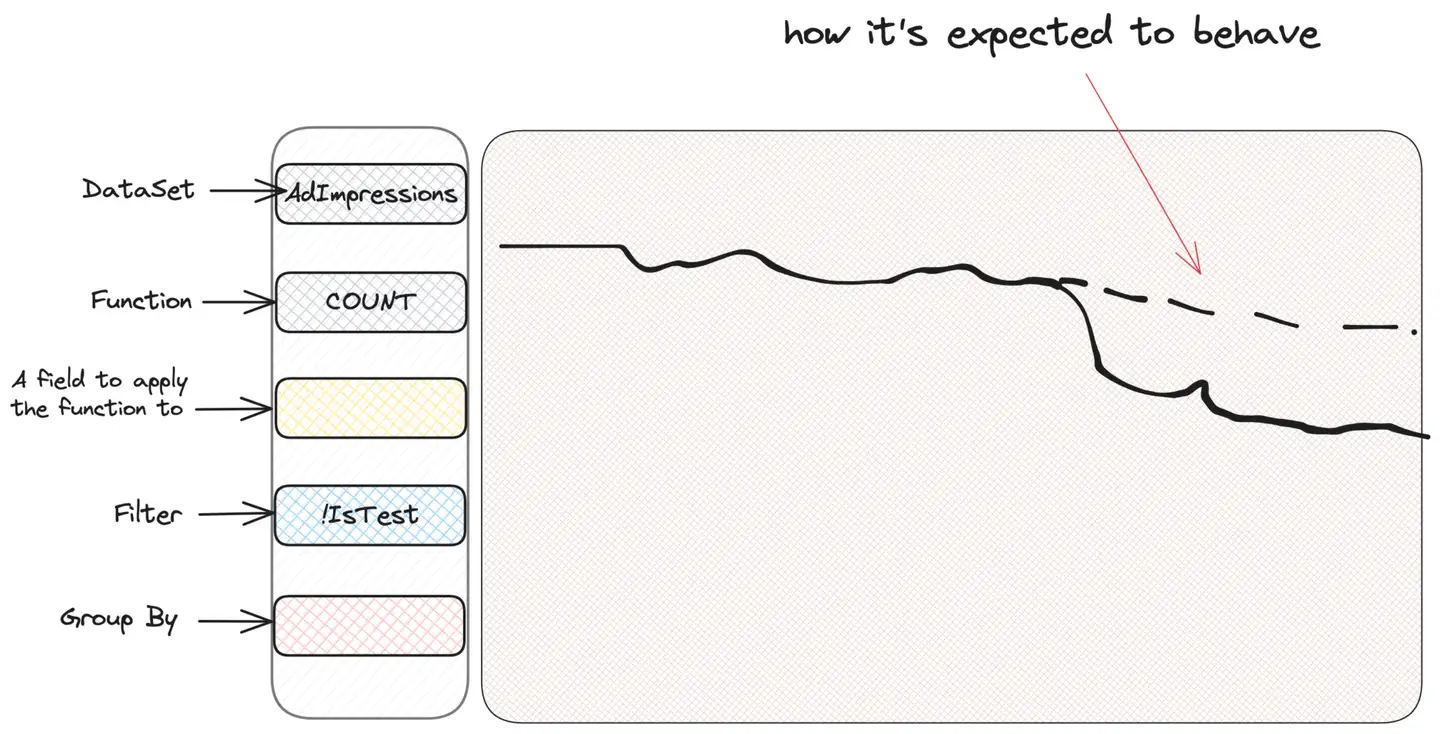
O primeiro instinto de quem usa o Scuba para investigar é “fatiar e picar”, ou seja, filtrar ou agrupar com base em critérios, para ver se conseguem obter alguma informação. Não sabemos o que procuramos, mas acreditamos que encontraremos. Portanto, agrupamos por tipo de impressão, país do usuário ou local do anúncio até encontrarmos algo suspeito. Vamos supor o agrupamento por tipo de campanha (CampaignType):
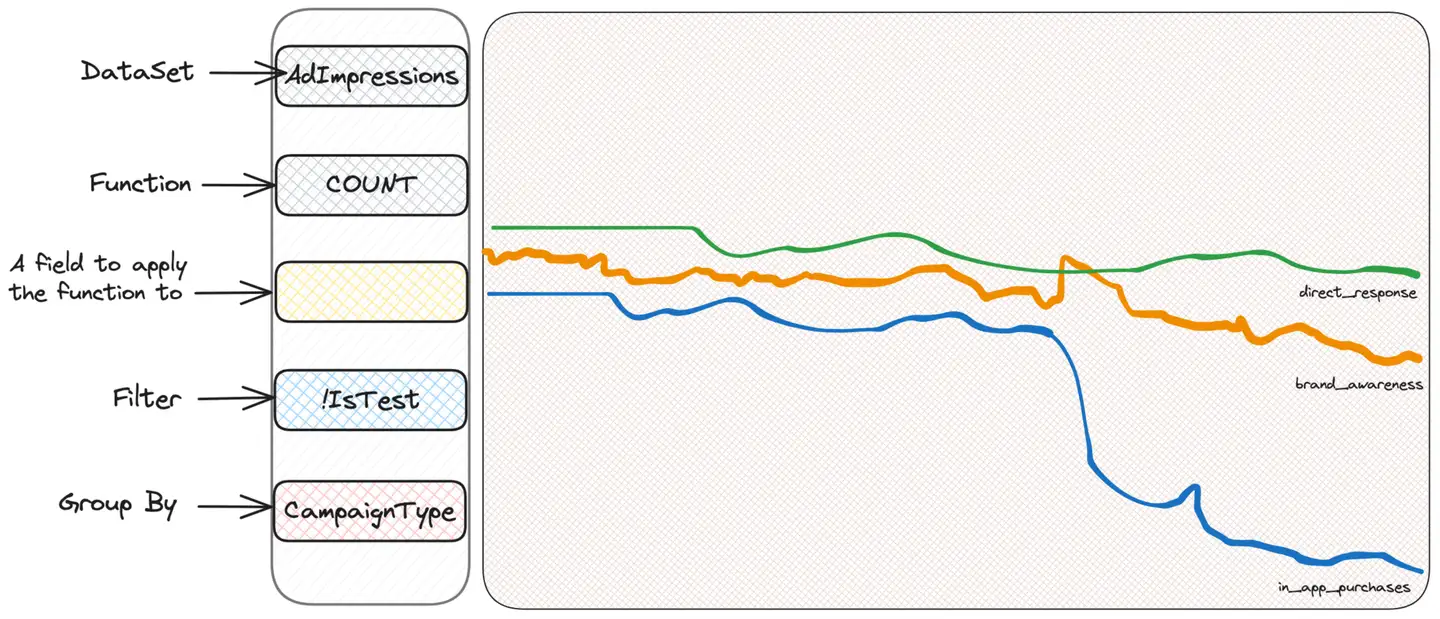
Descobrimos que um tipo de campanha chamado in_app_purchases (observe que eu inventei isso) parece ser diferente dos outros tipos. Não sabemos realmente o que isso significa – e não precisamos saber! - Só temos que continuar cavando. Ok, agora podemos filtrar apenas essas campanhas e continuar agrupando com base em outros critérios que pudermos imaginar. Por exemplo, o sistema operacional do usuário faz sentido.
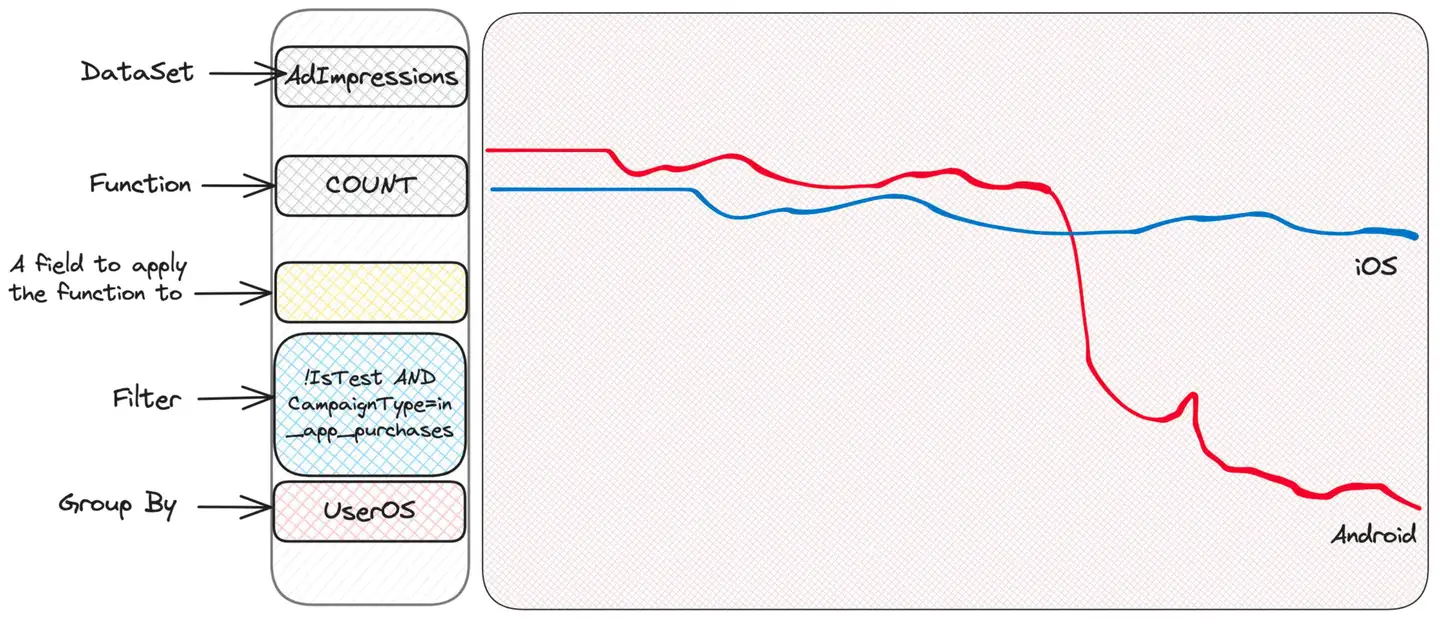
Bem, parece haver um problema com o Android. O iOS está ok, o que sugere que o problema pode estar no lado do cliente - talvez uma versão com bugs do aplicativo?
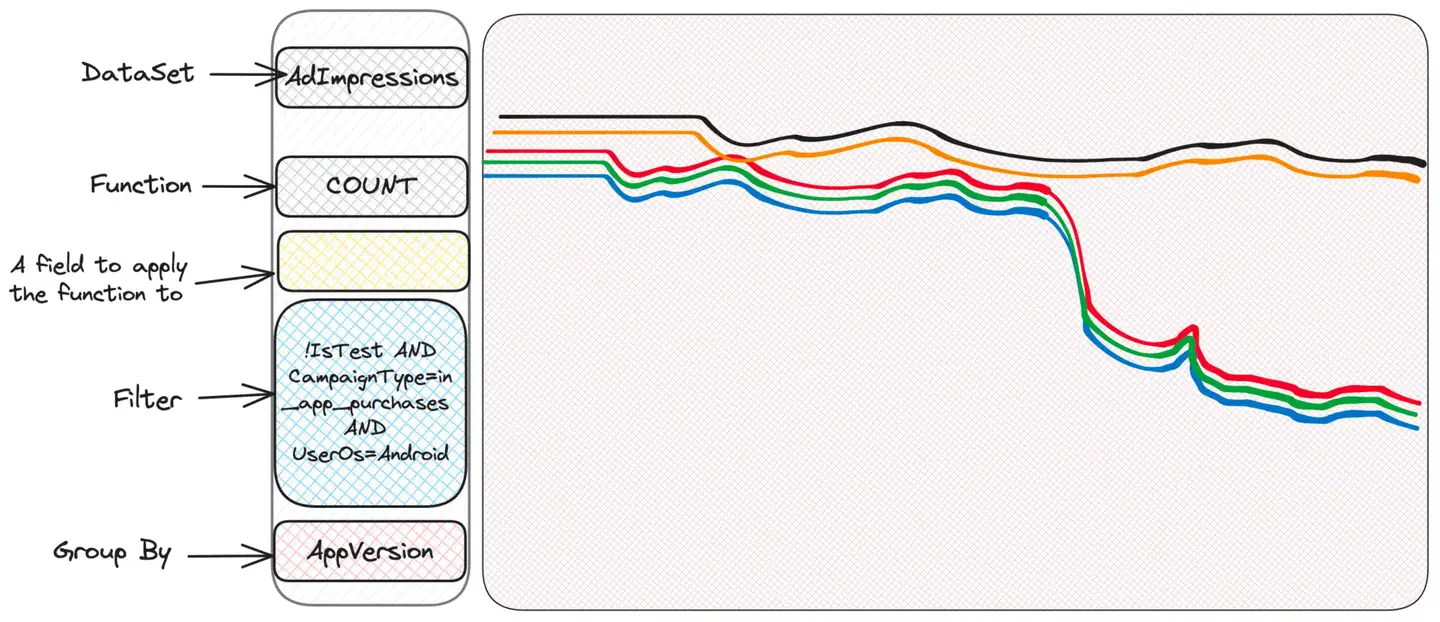
estranheza. Algumas pessoas têm problemas, outras não. Talvez verifique a versão do sistema operacional?
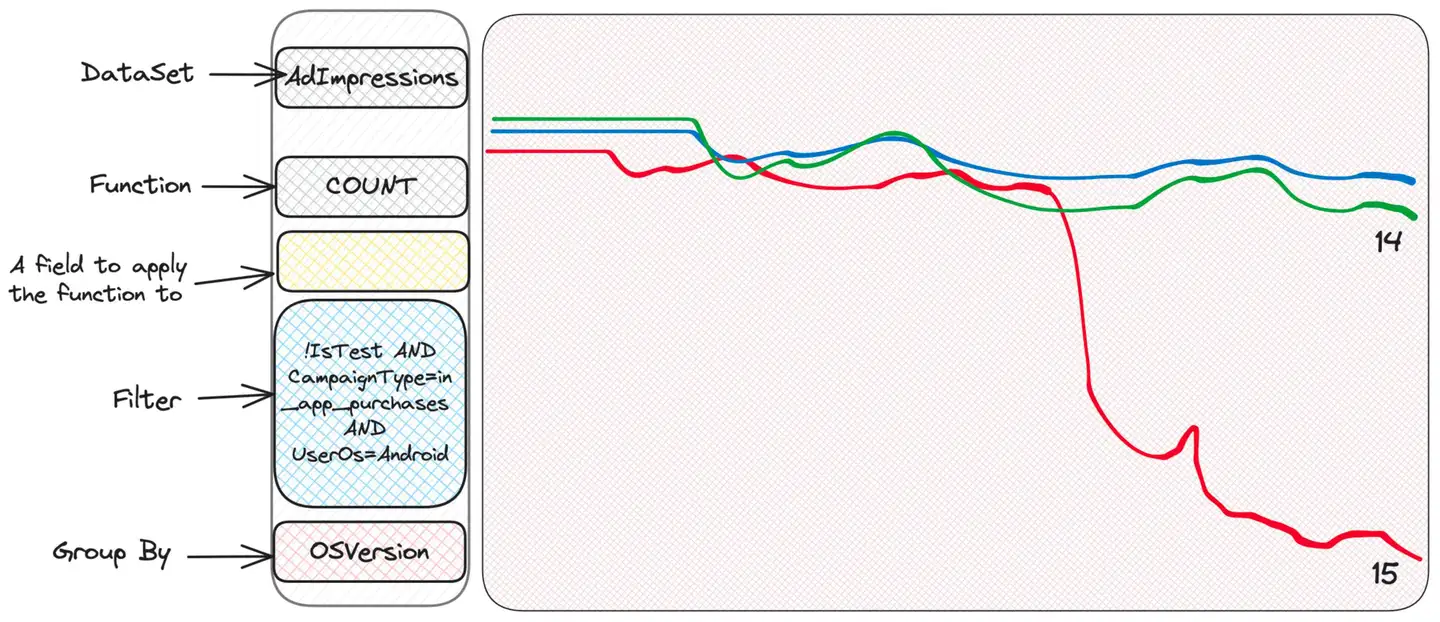
ah! Esta é a versão mais recente do sistema operacional e parece que algumas versões do aplicativo não funcionam bem para esse tipo de campanha nesta versão do sistema operacional. Dadas essas informações, a equipe dedicada agora pode se aprofundar.
o que aconteceu? Sem qualquer conhecimento do sistema, restringimos o problema e identificamos a equipe responsável por uma investigação mais aprofundada. Poderíamos saber com antecedência que essa estranha combinação de sistema operacional, versão do sistema operacional, tipo de campanha e versão do aplicativo poderia causar alguns problemas e ter as métricas prontas? Claro que é impossível. Este é um exemplo de como lidar com incógnitas desconhecidas. Apenas armazenamos todas as informações contextuais relevantes em eventos generalizados e as utilizamos quando necessário. O Scuba facilita a exploração porque é rápido e possui uma interface de usuário muito bonita e fácil de usar. Observe também que nunca mencionamos nada sobre cardinalidade. Porque não importa – qualquer campo pode ter qualquer cardinalidade. O Scuba opera com eventos brutos e não faz pré-agregação, portanto a cardinalidade não é um problema.
Às vezes, o aspecto da interface/visualização não recebe atenção suficiente e o sistema de monitoramento fornece alguma linguagem de consulta - talvez proprietária (uma experiência particularmente ruim) ou SQL (um pouco melhor, mas ainda não é boa). Tal interface tornaria quase impossível realizar uma pesquisa semelhante. Um aspecto importante do Scuba é que todos os campos (funções, filtros, agrupamentos, etc.) podem ser explorados. Dito isto, existe uma maneira fácil de ver os tipos de valores que podemos selecionar. Quando o responsável por um determinado campo de dados faz um esforço extra para melhorar os dados pelos quais é responsável, ele vai além da simples coleta dos dados. Ele ainda fornecerá uma descrição detalhada do campo em questão, incluindo links relacionados. Isto é muito importante. Muitas vezes conduzi a solução de problemas com êxito, sem compreender totalmente o sistema como um todo ou os dados disponíveis nesse conjunto de dados. E durante esses processos de solução de problemas, aprendi muito sobre o sistema simplesmente interagindo com o Scuba! Isso é incrível. Este é o paraíso da observabilidade.
A dor depois de deixar Meta
Agora imagine minha confusão e descrença quando deixei Meta e aprendi sobre o estado do sistema de observabilidade externa.

registro? acompanhar? índice? O que exatamente é isso? Alguém sabe sobre eventos generalizados? Não posso aprender o glossário de 60 termos e apenas... explorar coisas?
Passei algum tempo mapeando o modelo mental baseado em Scuba para o modelo mental de Telemetria Aberta. Percebi que o Span da Open Telemetry é na verdade um evento generalizado. Na verdade, ainda não tenho certeza se entendi corretamente:

Se tomarmos o exemplo de uma exibição publicitária, esta exibição não é realmente uma operação, são apenas alguns fatos que queremos registrar... Para ser justo, o conceito de eventos existe na Telemetria Aberta:

Mas se seguirmos o link e nos aprofundarmos, descobriremos novamente que o evento é na verdade um dos rastreamentos, métricas ou logs

Mas em qualquer caso, Span é o conceito mais próximo de um evento generalizado. O problema é que é difícil defender o modelo mental proposto pela Open Telemetry quando você está acostumado. Isso é realmente frustrante porque rastreamentos, métricas e logs são apenas casos especiais de eventos generalizados:
- Traces e spans (Spans): São apenas eventos generalizados com campos SpanId, TraceId e ParentSpanId. Assim, podemos filtrar todos os spans com um determinado TraceId, classificá-los topologicamente com base no relacionamento SpanId → ParentSpanId e desenhar a visualização de rastreamento distribuída favorita de todos.
- Logs: Para ser honesto, estou realmente confuso com o que a Open Telemetry chama de logs. Parece que contém muitas coisas, uma das quais é o registro estruturado, que consiste basicamente em eventos amplos. Muito bom! O problema, porém, é que “log” é um conceito bastante bem definido e geralmente as pessoas querem dizer o que essas chamadas produzem. De qualquer forma, seja lá o que isso signifique, os logs certamente podem ser facilmente mapeados para eventos amplos. No caso mais simples, apenas pegamos a mensagem de log, colocamos no campo "log_message", adicionamos vários metadados e ficamos satisfeitos. Em um caso mais complexo, poderíamos tentar extrair automaticamente um modelo da mensagem de log removendo o token que se parece com um ID e obter o hash desse modelo. Isto permite-nos obter rapidamente os erros mais frequentes, por exemplo, agrupando por este hash. Meta tem um sistema como esse e é muito legal.
logger.info(…) - Métricas: As métricas também podem ser facilmente mapeadas. Precisamos apenas emitir um amplo evento contendo o status do sistema (como indicadores do sistema da CPU, vários contadores, etc.) dentro de um determinado intervalo. A propósito, o Prometheus faz exatamente isso através do método de raspagem - tirando um instantâneo ocasional do sistema. No entanto, ao contrário do Prometheus, usando a abordagem de eventos amplos não precisamos nos preocupar com questões de cardinalidade.
Mas o Wide Events pode fornecer muito mais do que esses “três pilares” (Traces, Logs, Metrics). A sessão de depuração mencionada já é (pelo menos não naturalmente) um caso coberto por Traces, Logs e Metrics. Pode haver outros casos de uso - por exemplo, dados de criação de perfil contínuo podem ser facilmente representados como um evento amplo e consultados para construir um gráfico em chamas. Não há necessidade de ter um sistema separado para isso - um único sistema que lida com eventos amplos pode fazer tudo. Imagine as possibilidades de correlação cruzada e análise de causa raiz quando tudo é armazenado junto, em um só lugar. Principalmente na era do surgimento das ferramentas de inteligência artificial, excelentes para descobrir relações entre dados.
Então?
Não sei... só queria expressar minha decepção e frustração pelo fato de a observabilidade ser tão confusa e confusa e focada no que são os "três pilares"...
Só espero que os fornecedores de observabilidade enfrentem o caos e forneçam uma maneira simples e natural de interagir com o sistema. O Honeycomb parece estar fazendo isso, e alguns outros sistemas como o Axiom também estão fazendo isso. é ótimo! Esperamos que outros fornecedores sigam o exemplo.
apegado
Este artigo é uma tradução, texto original: https://isburmistrov.substack.com /p/ all -you-need-is-wide-events-not-metrics
Permita-me inserir um pequeno anúncio no final do artigo. Estou começando um negócio há dois anos e nossa empresa também faz observabilidade, o que é um pouco semelhante à ideia deste artigo. Se você tiver necessidades nesta área, não hesite em nos contatar para trocas técnicas e de produtos.
Sobre a Nebulosa Kuaimao
Kuaimao Nebula é uma empresa de tecnologia de operação e manutenção inteligente nativa da nuvem. É composta pela equipe principal de desenvolvimento do conhecido projeto de código aberto "Nightingale". A equipe fundadora vem de empresas de Internet como Alibaba, Baidu e Didi. Nightingale é uma ferramenta de monitoramento nativa da nuvem de código aberto. É o primeiro projeto de código aberto doado e hospedado pela Sociedade de Computação da China. Possui mais de 8.000 estrelas no GitHub, lançou mais de 100 versões iterativas e tem centenas de comunidades. contribuidores. É a solução de observabilidade de código aberto líder na China.
A "Plataforma Flashcat" construída pela Kuaimao Nebula com o código aberto Nightingale como núcleo é a implementação do produto das práticas de observabilidade das principais empresas nacionais de Internet. Ela está comprometida em fazer com que a tecnologia de observabilidade atenda melhor às empresas e garanta a estabilidade do serviço. A plataforma Flashcat possui os seguintes recursos:
- Coleta unificada: Adotando o conceito de plug-in, centenas de plug-ins de coleta integrados são integrados. Servidores, equipamentos de rede, middleware, bancos de dados, aplicativos e negócios podem ser monitorados e usados imediatamente.
- Alarme unificado: suporta o acoplamento de dezenas de fontes de dados, coleta eventos de alarme de vários sistemas de monitoramento e realiza convergência de alarme unificada, redução de ruído, agendamento, reivindicação, atualização e colaboração, melhorando significativamente a eficiência do processamento de alarme.
- Observação unificada: integre vários dados de observabilidade, como métricas, logs, rastreamentos, eventos e criação de perfil, e predefinições das melhores práticas do setor. Ela não apenas fornece um cockpit de uma perspectiva de negócios global e técnica, mas também fornece detalhamento de falhas. Capacidade de posicionamento, reduzindo efetivamente o tempo de descoberta e posicionamento de falhas.
A Nebulosa Kuaimao torna os dados de observabilidade mais valiosos! https://flashcat.cloud/