

Se você é um usuário com dois aplicativos RAG diferentes, como decidir qual é o melhor? Para desenvolvedores, como melhorar quantitativa e iterativamente o desempenho de sua aplicação RAG?
Claramente, é importante que tanto os usuários quanto os desenvolvedores avaliem com precisão o desempenho dos aplicativos RAG. No entanto, uma simples comparação de alguns exemplos não pode medir completamente a qualidade da resposta das aplicações RAG. É necessário utilizar indicadores credíveis e reprodutíveis para avaliar quantitativamente as aplicações RAG.
Este artigo discutirá como avaliar quantitativamente uma aplicação RAG tanto da perspectiva da caixa preta quanto da caixa branca.
01. Método de caixa preta VS método de caixa branca
Comparamos a avaliação de aplicativos RAG com o teste de um sistema de software. Existem duas maneiras de avaliar a qualidade do sistema RAG, uma é o método da caixa preta e a outra é o método da caixa branca.
Ao avaliar um aplicativo RAG de maneira caixa preta, não podemos ver o interior do aplicativo RAG e só podemos avaliar o efeito do RAG a partir da entrada de informações no aplicativo RAG e das informações que ele retorna. Para um sistema RAG geral, só podemos acessar estas três informações: consulta do usuário, contextos recuperados recuperados pelo sistema RAG e resposta do RAG. Usamos essas três informações para avaliar o efeito dos aplicativos RAG. O método da caixa preta é um método de avaliação ponta a ponta e também é mais adequado para avaliar aplicativos RAG de código fechado.
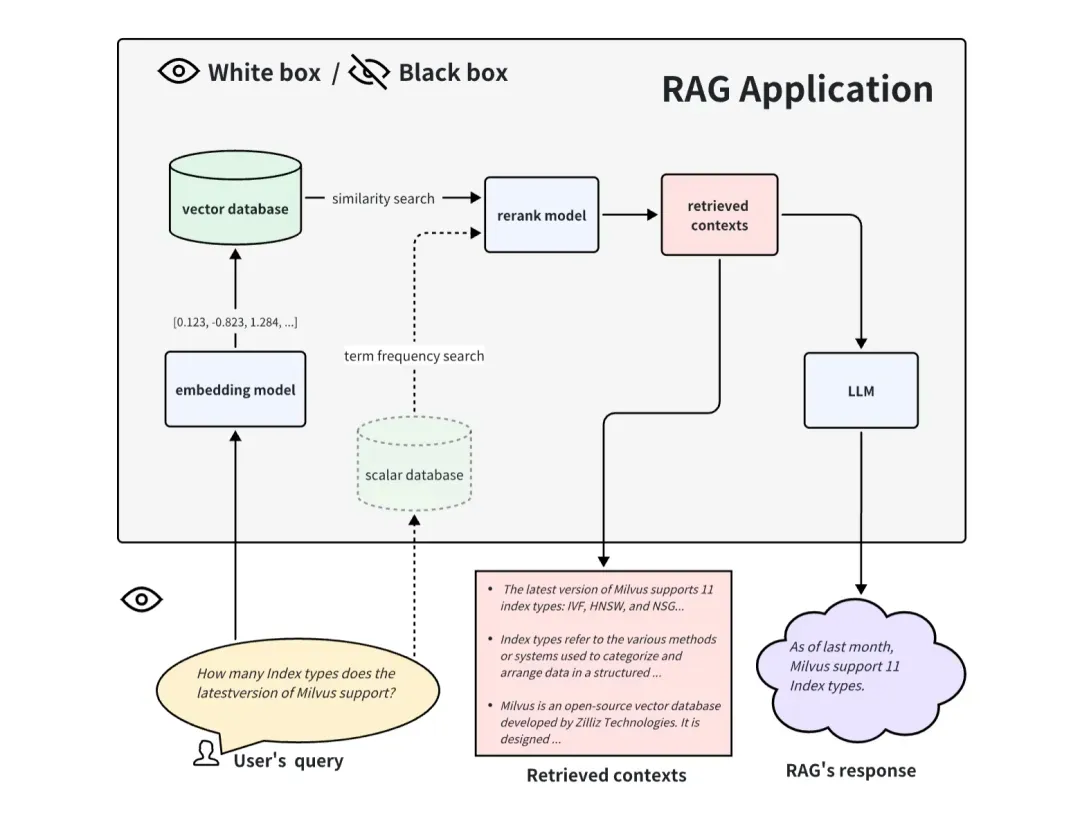
Ao avaliar uma aplicação RAG de forma caixa branca, podemos ver todos os processos internos da aplicação RAG. Portanto, alguns componentes internos importantes podem determinar o desempenho desta aplicação RAG. Tomando o processo de aplicação RAG comum como exemplo, alguns componentes principais incluem modelo de incorporação, modelo de reclassificação e LLM. Alguns RAGs possuem recursos de recuperação multicanal e também podem ter algoritmos de busca de frequência de termo. A substituição e atualização desses componentes principais também pode trazer melhores resultados para aplicações RAG. A abordagem de caixa branca pode ser usada para avaliar aplicações RAG de código aberto ou melhorar aplicações RAG autodesenvolvidas.
02.Método de avaliação ponta a ponta da caixa preta
Indicadores de avaliação em condições de caixa preta
No caso em que a aplicação RAG é uma caixa preta, só podemos acessar estas três informações: a consulta do usuário, os contextos recuperados pelo sistema RAG e a resposta do RAG. Eles são o trio mais importante em todo o processo do RAG, e dois deles se restringem. Podemos avaliar o efeito de uma aplicação RAG detectando a correlação entre dois elementos do trio.
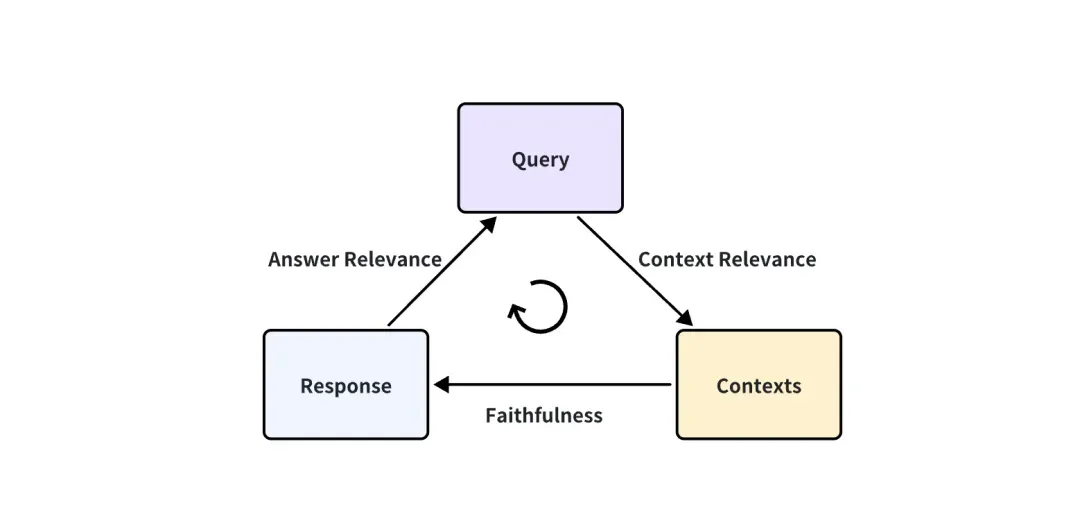
São propostas as seguintes três pontuações de indicadores correspondentes:
-
Relevância do Contexto: Mede até que ponto o Contexto recuperado pode suportar a Consulta. Se a pontuação for baixa, isso reflete que muito conteúdo irrelevante para a questão da consulta foi lembrado, e esse conhecimento errôneo lembrado terá um certo impacto na resposta final do LLM.
-
Fidelidade: Esta métrica mede a consistência factual das respostas geradas em um determinado contexto. É calculado com base na resposta e no contexto recuperado. Se esta pontuação for baixa, reflectindo o facto de a resposta do LLM não aderir ao conhecimento recordado, então a resposta é mais provável que seja ilusória.
-
Relevância da resposta: concentra-se na avaliação da relevância da resposta gerada para um determinado prompt de consulta. Notas mais baixas são atribuídas a respostas incompletas ou que contenham informações redundantes.
Tome a relevância da resposta como exemplo:
Question: Where is France and what is it’s capital?
Low relevance answer: France is in western Europe.
High relevance answer: France is in western Europe and Paris is its capital.
Como calcular quantitativamente esses indicadores?
Para a pergunta “Onde está a França e qual é o seu capital?”, uma resposta de baixa relevância é “A França está na Europa Ocidental”. Esta é uma conclusão tirada da análise do conhecimento humano prévio. Pontuação, esta resposta é 0,2 pontos e a outra resposta é 0,4 pontos? E objectivamente, temos de garantir que o efeito de 0,4 pontos é de facto melhor do que 0,2 pontos.
Além disso, se cada resposta exige que os humanos pontuem, então uma grande quantidade de trabalho deve ser organizada e certos padrões de orientação devem ser formulados para que eles possam aprender esta diretriz e cumpri-la para pontuar. Este método é demorado e obviamente irreal. Existe uma maneira de pontuar automaticamente?
Felizmente, LLMs avançados como o GPT-4 podem agora atingir um nível semelhante aos anotadores humanos. Ele pode atender às duas necessidades mencionadas acima ao mesmo tempo. Uma é que pode pontuar de forma quantitativa, objetiva e justa, e a outra é que pode ser automatizado.
Neste artigo LLM-as-a-Judge ( https://arxiv.org/abs/2306.05685), o autor propôs a possibilidade do LLM como juiz e conduziu um grande número de experimentos com base nisso. Os resultados mostram que juízes LLM poderosos (como GPT-4) podem combinar bem o controle e as preferências humanas de crowdsourcing, alcançando mais de 80% de consistência, que é o mesmo nível de consistência entre humanos. Portanto, o LLM como juiz é um método escalável e interpretável para aproximar as preferências humanas, o que de outra forma seria muito caro para os humanos pontuarem.
Você pode pensar que a concordância de 80% entre o LLM e os avaliadores humanos não significa que o LLM e os humanos sejam muito consistentes. Mas você deve saber que duas pessoas diferentes que receberam orientação podem não conseguir chegar a 100% de concordância na pontuação de tais questões subjetivas. Portanto, o fato de o GPT-4 ser 80% consistente com os humanos mostra que o GPT-4 pode se tornar um juiz totalmente qualificado.
Em relação à pontuação do GPT-4, ainda tomamos a relevância da resposta como exemplo. Usamos o seguinte prompt para fazer perguntas ao GPT-4:
There is an existing knowledge base chatbot application. I asked it a question and got a reply. Do you think this reply is a good answer to the question? Please rate this reply. The score is an integer between 0 and 10. 0 means that the reply cannot answer the question at all, and 10 means that the reply can answer the question perfectly.
Question: Where is France and what is it’s capital?
Reply: France is in western Europe and Paris is its capital.
Resposta do GPT-4:
10
Pode-se observar que, desde que um prompt adequado seja projetado antecipadamente, como o prompt do exemplo acima, e a pergunta e a resposta sejam substituídas, todos os pares de controle de qualidade podem ser avaliados automaticamente. Portanto, como projetar o prompt também é muito importante. O prompt no exemplo acima é apenas um exemplo. O prompt real costuma ser muito longo para tornar a pontuação do GPT mais justa e robusta. Isso requer o uso de algumas técnicas avançadas de engenharia imediata, como técnicas de cadeia de pensamento multi-shot ou CoT (Chain-of-Thought). Ao projetar esses prompts, às vezes alguns preconceitos do LLM precisam ser considerados, como o viés de posição comum do LLM: quando o prompt é relativamente longo, o LLM tende a notar parte do conteúdo na frente do prompt e ignorar parte do conteúdo em o meio.
Felizmente, não precisamos nos preocupar muito com o design imediato. As ferramentas de avaliação para essas aplicações RAG já foram projetadas e integradas. A comunidade e o tempo podem ajudar a testar o quão bem eles projetam os prompts. Precisamos nos preocupar mais com o fato de que o acesso a LLMs como GPT-4 em grandes quantidades requer o consumo de muitas chaves de API. No futuro, espero que haja um LLM mais barato ou um LLM local que possa atingir o nível de ser um bom juiz.
Preciso marcar a verdade básica?
Você deve ter notado que a verdade básica não é usada no exemplo acima. É uma resposta padrão escrita por humanos para responder às perguntas correspondentes. Por exemplo, pode ser definido um indicador entre a verdade básica e a resposta, denominado correção de resposta, que é usado para medir a correção das respostas RAG. O princípio de pontuação é o mesmo que o Answer Relevance usa a pontuação LLM acima.
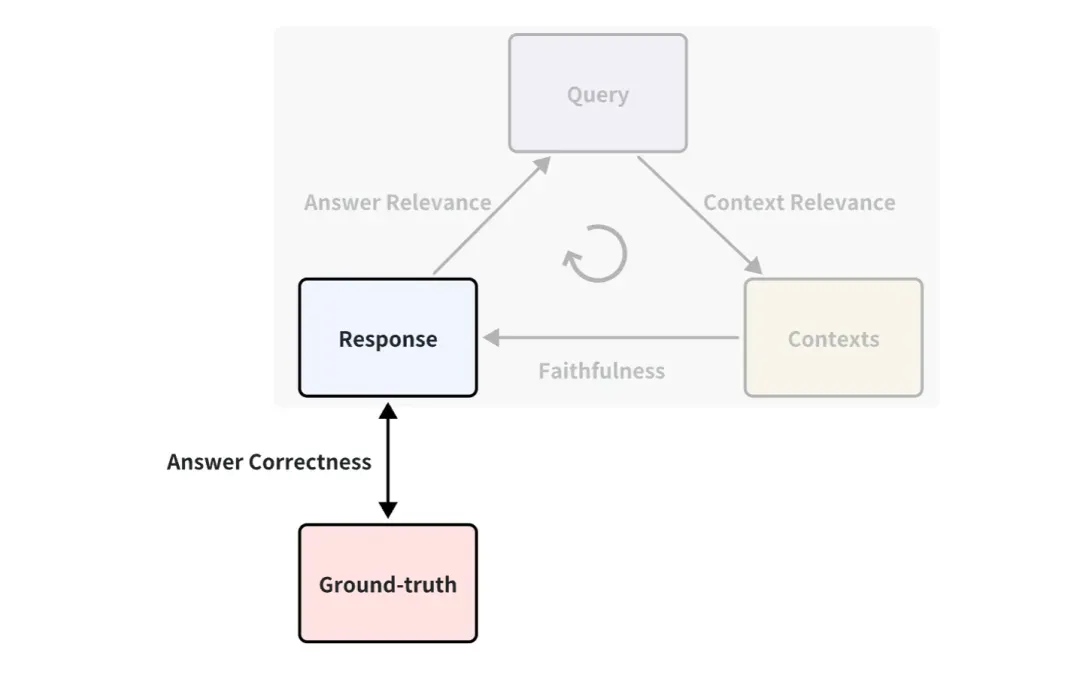
Portanto, se houver verdade, os indicadores de avaliação serão mais ricos, ou seja, o efeito da aplicação do RAG poderá ser medido sob mais ângulos. Mas, na maioria dos casos, obter um bom conjunto padrão de dados verdadeiros é caro e pode exigir muita mão de obra e tempo para anotar. Existe alguma maneira de conseguir anotações rápidas?
Como o LLM pode gerar tudo, é viável permitir que o LLM gere consultas e informações verdadeiras com base em documentos de conhecimento. Por exemplo, existem alguns métodos integrados na geração de dados de teste sintéticos do ragas e no QuestionGeneration do índice lhama, que podem ser usados de forma direta e conveniente.
Vamos dar uma olhada no efeito gerado com base em documentos de conhecimento em ragas:

Perguntas e respostas geradas com base em documentos de conhecimento ( https://docs.ragas.io/en/latest/concepts/testset_generation.html)
Como você pode ver, a figura acima gera muitas perguntas de consulta e respostas correspondentes, incluindo as fontes de contexto correspondentes. Para garantir a diversidade das perguntas geradas, você também pode escolher a proporção dos vários question_types gerados, como a proporção de perguntas simples e perguntas de raciocínio.
Dessa forma, podemos usar de maneira fácil e direta essas perguntas geradas e a verdade básica para avaliar quantitativamente uma aplicação RAG. Não precisamos mais ficar on-line para encontrar vários conjuntos de dados de referência. Dessa forma, também podemos avaliar dados privados ou internos. dentro da empresa.
03. Método de avaliação de caixa branca
Pipeline RAG sob condições de caixa branca
Olhando para os aplicativos RAG de uma perspectiva de caixa branca, podemos ver o pipeline de implementação interno do RAG. Tomando o processo de aplicação RAG comum como exemplo, alguns componentes principais incluem modelo de incorporação, modelo de reclassificação e LLM. Alguns RAGs possuem capacidades de recuperação multicanal e também podem ter algoritmos de busca de frequência de termo. Obviamente, testar esses componentes-chave também pode refletir a eficácia do pipeline RAG em uma determinada etapa. A substituição e atualização desses componentes-chave também pode trazer melhor desempenho aos aplicativos RAG.
Abaixo apresentamos como avaliar esses três componentes principais típicos:
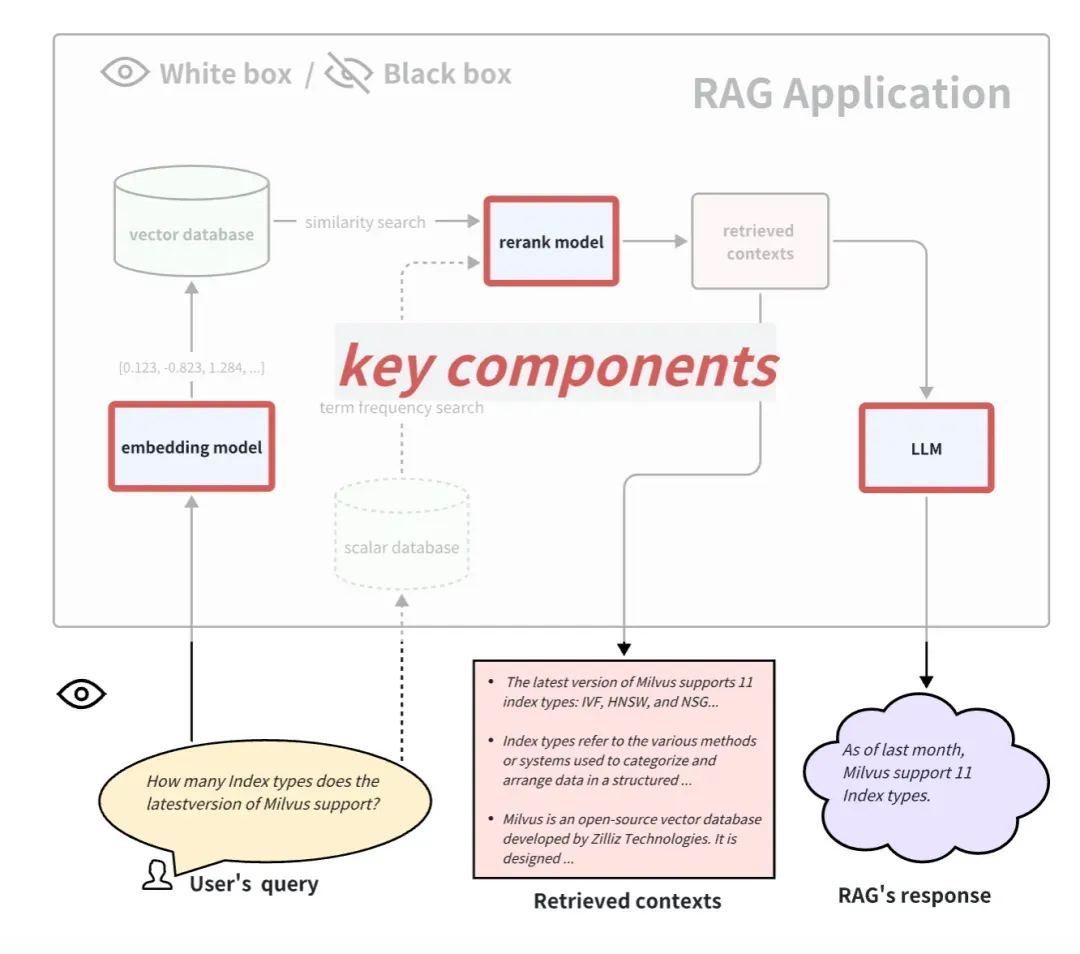
Como avaliar o modelo de incorporação e o modelo de reclassificação
O modelo de incorporação e o modelo de reclassificação trabalham juntos para completar a função de recuperação de documentos relacionados. Acima, introduzimos o indicador Relevância do Contexto, que pode ser usado para avaliar a relevância de documentos recuperados. Mas geralmente para conjuntos de dados com verdade fundamental, as pessoas usam mais comumente alguns indicadores determinísticos no campo da recuperação e recuperação de informações para medir o efeito da recuperação. Em comparação com os indicadores de Relevância do Contexto baseados em LLM, estes indicadores são mais rápidos, mais baratos e mais determinísticos de calcular (mas precisam de fornecer contextos verdadeiros).
Indicadores comumente usados para recuperação de informações
No campo da recuperação e recuperação de informação, os indicadores comumente utilizados incluem indicadores que consideram a classificação e indicadores que não consideram a classificação.
O índice que considera a classificação é sensível à classificação dos documentos verdadeiros recuperados entre todos os documentos recuperados. Ou seja, a alteração da ordem de correlação entre todos os documentos recuperados fará com que a pontuação deste índice mude independentemente dos indicadores de classificação. são o oposto.
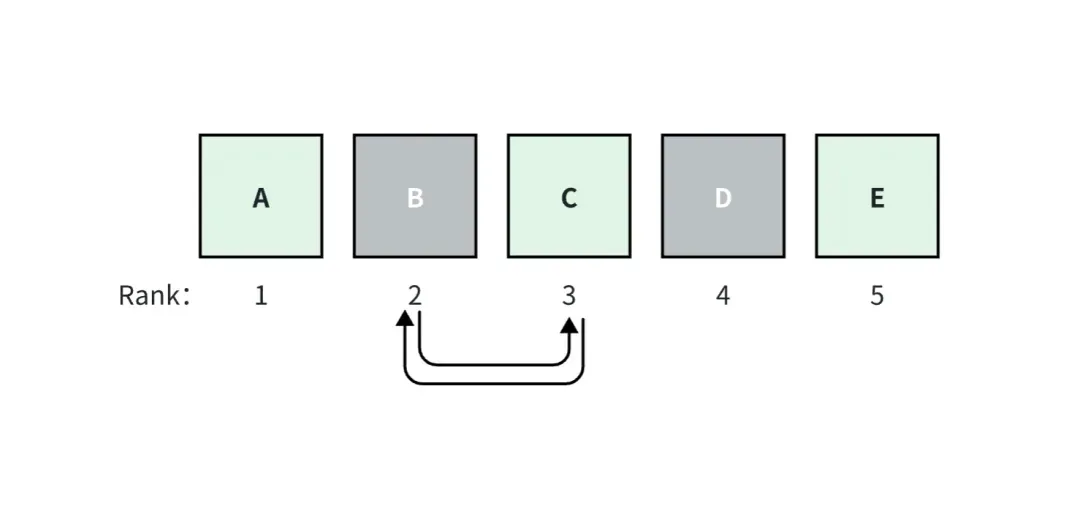
Por exemplo, na figura acima, assumimos que o aplicativo RAG recupera top_k=5 documentos, entre os quais os documentos A, C e E são verdadeiros. O documento A é classificado como 1, tem a pontuação de relevância mais alta e as pontuações diminuem para a direita.
Se os documentos B e C forem trocados, as pontuações das métricas consideradas para classificação serão alteradas, mas as pontuações das métricas não consideradas para classificação não serão alteradas.
Aqui estão alguns indicadores específicos comuns:
Indicadores que não levam em conta rankings
-
Recuperação de contexto: até que ponto o sistema recuperou completamente todos os documentos necessários.
-
Precisão do contexto: Quão bem o sistema recupera o sinal (em comparação com o ruído).
Métricas consideradas para classificação
-
A Precisão Média (AP) mede todos os blocos relevantes recuperados e calcula uma pontuação ponderada. A média de AP em um conjunto de dados costuma ser chamada de MAP.
-
A classificação recíproca (RR) mede onde o primeiro bloco relevante aparece em sua pesquisa. A média do RR em um conjunto de dados costuma ser chamada de MRR.
-
O Ganho Cumulativo Descontado Normalizado (NDCG) leva em consideração o caso em que sua classificação de correlação é não binária.
O referencial de avaliação mais popular: MTEB
O Massive Text Embedding Benchmark (MTEB) é um benchmark abrangente projetado para avaliar o desempenho de modelos de incorporação de texto em uma variedade de tarefas e conjuntos de dados. O MTEB cobre 8 tarefas de incorporação, incluindo mineração bilíngue (Bitext Mining), classificação, agrupamento, classificação pareada, reordenação, recuperação, similaridade de texto semântico (STS) e resumo. Abrange um total de 58 conjuntos de dados em 112 idiomas, tornando-o um dos benchmarks de incorporação de texto mais abrangentes até o momento.
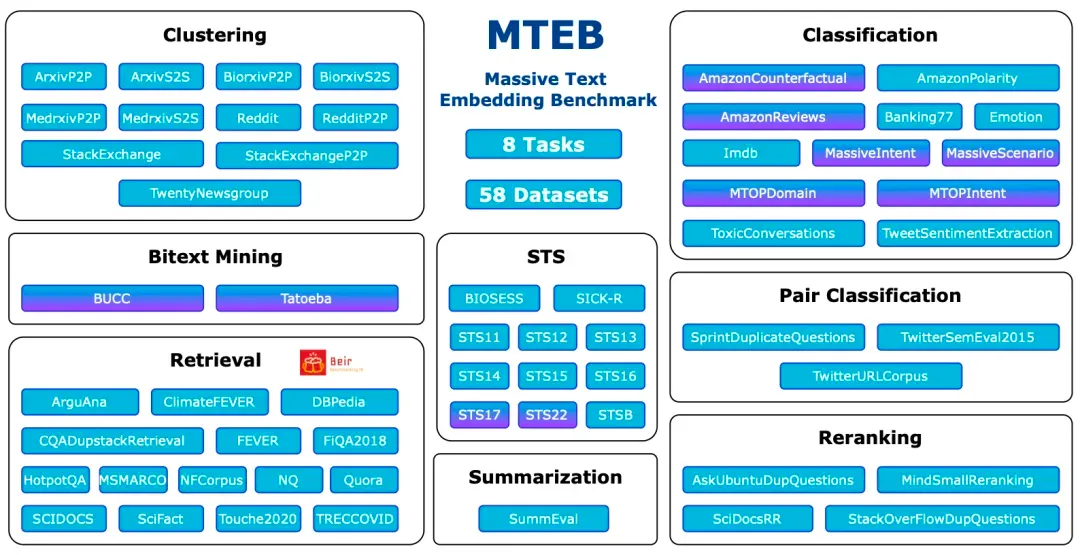
MTEB: referência de incorporação de texto massivo
https://arxiv.org/abs/2210.07316
Pode-se observar que o MTEB contém tarefas de recuperação e tarefas de reclassificação. Ao avaliar modelos de incorporação e reclassificação em aplicações RAG, concentre-se nos modelos com pontuações mais altas nessas duas tarefas. Nas recomendações do artigo MTEB ( https://arxiv.org/abs/2210.07316), para o modelo Embedding, o NDCG é o indicador mais importante para o modelo Rerank, o MAP é o indicador mais importante;
No HuggingFace, MTEB é a tabela de classificação à qual todos prestam muita atenção. No entanto, como o conjunto de dados é público, pode haver alguns modelos que tenham superajustado esse conjunto de dados até certo ponto, o que degradará o desempenho do conjunto de dados real. Portanto, ao avaliar o efeito recall, também é necessário prestar mais atenção ao desempenho da avaliação em conjuntos de dados personalizados tendenciosos para os negócios.
Como avaliar o LLM?
Em geral, o processo de geração pode ser avaliado diretamente usando o indicador baseado em LLM da etapa do Contexto à Resposta apresentado acima, nomeadamente Fidelidade.
Mas para alguns testes de consulta relativamente simples, como aqueles em que as respostas padrão possuem apenas algumas frases simples, alguns indicadores clássicos também podem ser usados. Por exemplo, Precisão ROUGE-L, Precisão de Sobreposição de Token. Esta avaliação determinística também requer um contexto de verdade anotado.
ROUGE-L Precision mede a maior subsequência comum entre a resposta gerada e o contexto recuperado.
Precisão de sobreposição de token Calcula a precisão da sobreposição de token entre a resposta gerada e o contexto recuperado.
Por exemplo, os seguintes problemas relativamente simples ainda podem ser avaliados usando indicadores como ROUGE-L Precision e Token Overlap Precision.
Question: How many Index types does the latest version of Milvus support?
Reply: As of last month, Milvus support 11 Index types.
Ground-truth Context: In this version, Milvus support 11 Index types.
No entanto, deve notar-se que estes indicadores não são adequados em cenários RAG com questões complexas. Neste caso, os indicadores baseados em LLM precisam de ser utilizados para avaliação. Por exemplo, perguntas abertas como as seguintes:
Question: Please design a text search application based on the features of the latest version of Milvus and list the application usage scenarios.
04. Introdução às ferramentas de avaliação comumente utilizadas
Atualmente, surgiram ferramentas profissionais na comunidade de código aberto e os usuários podem usá-las para facilitar e conduzir rapidamente avaliações quantitativas. Abaixo apresentamos as ferramentas de avaliação RAG atualmente comuns e fáceis de usar e algumas de suas características.
Ragas ( https://docs.ragas.io/en/latest/getstarted/index.html ): Ragas é uma ferramenta focada na avaliação de aplicações RAG. A avaliação pode ser realizada por meio de uma interface simples. Os indicadores Ragas são ricos em variedade e não possuem requisitos na estrutura de aplicação do RAG. Você também pode monitorar o processo de cada avaliação através do langsmith ( https://www.langchain.com/langsmith) para ajudar a analisar os motivos de cada avaliação e observar o consumo de chaves API.
Avaliação contínua ( https://docs.relari.ai/v0.3) : Continuous-eval é um pacote de software de código aberto para avaliar pipelines de aplicativos LLM, com foco em pipelines de geração aumentada de recuperação (RAG). Ele fornece uma opção de avaliação mais barata e rápida. Além disso, permite a criação de pipelines confiáveis de avaliação de conjuntos com garantias matemáticas.
TruLens-Eval: Trulens-Eval é uma ferramenta usada especificamente para avaliar indicadores RAG. Possui integração relativamente boa com LangChain e Llama-Index e pode ser facilmente usada para avaliar aplicações RAG construídas por essas duas estruturas. Além disso, o Trulens-Eval também pode lançar uma página no navegador para monitoramento visual, auxiliando na análise dos motivos de cada avaliação e na observação do consumo de chaves API.
Llama-Index: Llama-Index é muito adequado para a construção de aplicações RAG, e sua ecologia atual é relativamente rica e está atualmente passando por um rápido desenvolvimento iterativo. Também inclui a função de avaliar RAG e gerar conjuntos de dados sintéticos. Os usuários podem avaliar facilmente aplicações RAG construídas pelo próprio Llama-Index.
Além disso, existem algumas ferramentas de avaliação cujas funções são semelhantes às mencionadas acima. Por exemplo, Phoenix ( https://docs.arize.com/phoenix ), DeepEval (https://github.com/confident-ai/deepeval), LangSmith, OpenAI Evals ( https://github.com/openai/ avaliações). O desenvolvimento iterativo destas ferramentas de avaliação também é muito rápido. Para funções e métodos de utilização específicos, você pode verificar os documentos oficiais correspondentes.
05. Resumo
Para usuários e desenvolvedores de aplicações RAG, é crucial na prática avaliar o desempenho das aplicações RAG. Este artigo apresentará o método de avaliação quantitativa de aplicações RAG tanto da perspectiva da caixa preta quanto da caixa branca, e apresentará algumas ferramentas práticas de avaliação, com o objetivo de ajudar os leitores a compreender rapidamente a tecnologia de avaliação e a começar rapidamente. Para obter mais informações sobre RAG, consulte outros artigos desta série "Manual de Cultivo RAG | Um artigo explicando a tecnologia por trás do RAG" "Manual de Cultivo RAG | RAG é a sentença de morte? O contexto longo do modelo grande significa que a recuperação de vetores não é mais importante?
Linus resolveu resolver o problema por conta própria para evitar que os desenvolvedores do kernel substituíssem tabulações por espaços. Seu pai é um dos poucos líderes que sabe escrever código, seu segundo filho é o diretor do departamento de tecnologia de código aberto e seu filho mais novo é um núcleo. contribuidor de código aberto Huawei: Demorou 1 ano para converter 5.000 aplicativos móveis comumente usados A migração abrangente para Hongmeng Java é a linguagem mais propensa a vulnerabilidades de terceiros Wang Chenglu, o pai de Hongmeng: Hongmeng de código aberto é a única inovação arquitetônica. no campo de software básico na China. Ma Huateng e Zhou Hongyi apertam as mãos para "remover rancores". Ex-desenvolvedor da Microsoft: o desempenho do Windows 11 é "ridiculamente ruim" " Embora o que Laoxiangji seja de código aberto não seja o código, as razões por trás disso são muito emocionantes. Meta Llama 3 é lançado oficialmente. Google anuncia uma reestruturação em grande escala.