


Há duas novidades recentes:
Sam Altman revelou os detalhes do GPT-5 e declarou publicamente que a melhoria do GPT-5 será enorme e qualquer empresa que o subestimar será esmagada. Ele também tuitou sugerindo que os produtos da OpenAI este ano mudarão a história da humanidade.
Em relação às notícias sobre o primeiro engenheiro de software de IA, o desempenho do engenheiro de software de IA já é notável. Ele tem capacidades de planejamento geral, DevOp e varredura completa de projetos. Ele não está longe de ser um verdadeiro programador.
Embora tudo fosse esperado, ainda parecia que veio um pouco mais rápido.
Pessoalmente, sinto que o progresso atual da tecnologia de IA tem pelo menos dois impactos:
Ao nível da competição nacional, com a bênção da IA, a anterior grande vantagem da China sobre os Estados Unidos – o número de excelentes licenciados – já não existe. Quem vencerá depois dependerá de quem cometer menos erros.
Ao nível dos empregos pessoais, espera-se que os métodos de produção mudem dentro de 2 a 5 anos. Se não acompanharmos, poderemos sofrer uma redução da dimensionalidade. Como programador, é fundamental aprender os princípios subjacentes da IA ou participar de práticas de aplicação relacionadas à IA.

-
Explica os princípios básicos das redes neurais e do aprendizado profundo por meio de uma rede muito simples. -
A seguir, darei a você alguma experiência por meio de uma operação real de rede neural. -
Finalmente, uma pergunta comum leva à complexa rede neural que será apresentada no artigo a seguir.

Dicas importantes neste capítulo:
As redes neurais resolvem problemas fora do conjunto de treinamento “aprendendo” e armazenando as regras gerais do conjunto de treinamento.
O armazenamento está ok. A rede neural é dividida em múltiplas camadas, cada camada possui vários neurônios e cada neurônio possui N+1 parâmetros (onde N é igual ao número de entradas conectadas ao neurônio). As regras gerais “aprendidas” são armazenadas nestes parâmetros (de todos os neurônios).
O processo também é certo. Como o processo de "aprendizado" começa em qualquer ponto do espaço de parâmetros de alta dimensão (parâmetros X de todos os neurônios) (os valores iniciais dos parâmetros são dados aleatoriamente) e retorna gradualmente ao ponto com a menor perda, é é um processo de ajuste passo a passo dos parâmetros. Portanto, se a fórmula para ajustar os parâmetros for determinada, o processo de “aprendizado” será determinado. Sim, a fórmula de ajuste dos parâmetros é determinada: quando o modelo é compilado, a fórmula de ajuste para cada parâmetro de cada neurônio em cada camada pode ser determinada antecipadamente com base na transitividade das derivadas parciais.
▐O que as redes neurais podem fazer
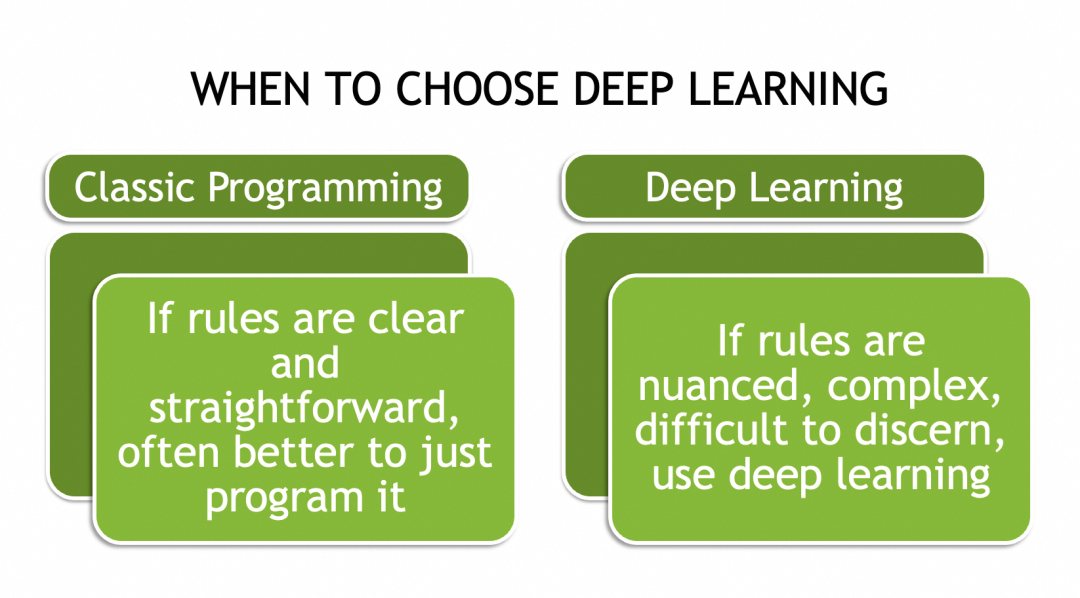
▐Por que as redes neurais podem resolver problemas complexos
Problemas complexos muitas vezes não são exaustivos (como diferentes imagens de gatos), portanto não existe um conjunto de regras que possa ser aplicado a todas as suas instâncias. A única maneira é abstrair suas leis gerais, ou características, ou padrões.
Por exemplo, a razão pela qual a incorporação de texto pode ser usada para processamento de linguagem natural é porque ela não registra (e não pode) registrar todas as combinações de texto, mas registra o padrão de um único texto ou token por meio de um vetor. abstração. Se os vetores de duas palavras forem parcialmente semelhantes, essa semelhança pode corresponder às suas características comuns num contexto específico. Não nos importamos com qual valor vetorial representa qual recurso. Eles são mais como metadados de idioma e texto.
Suponha que após o treinamento, a representação vetorial do rei seja [0,3, 0,5, ..., 0,9], da rainha seja [0,8, 0,5, ..., 0,2] e do príncipe seja [0,3, 0,7, ..., 0,5 ], Em um determinado contexto, como xx está governando o reino, xx pode ser preenchido com rei ou rainha, então eles podem ser determinados pelo segundo elemento do vetor, o comum 0,5. Em outro contexto, como xx é um. Homem, xx pode ser preenchido com rei ou príncipe, que pode ser determinado pelo primeiro elemento.
Como será mencionado a seguir, as redes neurais também possuem um mecanismo para calcular e armazenar esses padrões abstratos, portanto as redes neurais são muito adequadas para resolver problemas complexos que envolvem conceitos abstratos.
▐Como implementar rede neural
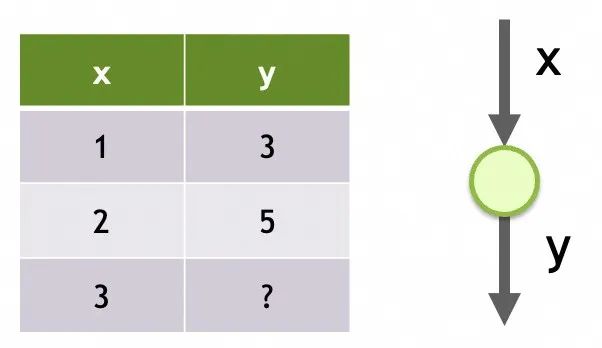
Rede 1
Estrutura de armazenamento de rede neural
Sua estrutura é uma única entrada, apenas uma camada e apenas um neurônio nesta camada.
Seus parâmetros são os dados treinados em cada neurônio. Há apenas um neurônio aqui e ele possui dois parâmetros, m e b.
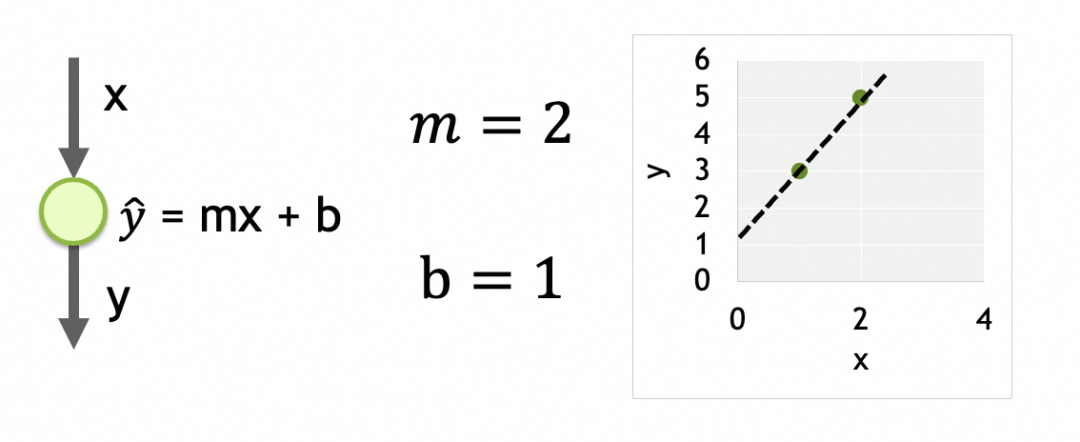
Uma rede na qual cada camada está densamente conectada, cada nó está conectado a todos os nós da camada superior e todos os nós da camada superior são entradas para cada nó da camada inferior. A saída de cada nó é a soma ponderada de suas entradas, o resultado após o processamento pela função de ativação:, output = activation_function(W * X + b)onde X é o vetor de entrada [x1, x2, ..., xn], W é o vetor de pesos de cada entrada [w1, w2, ..., wn], b é a constante de polarização e função_de_ativação é a função de ativação . Quando a função de ativação é linear, output = W * X + b. Quando um nó possui n entradas, o nó possui [w1, w2, ..., wn, b]um total de n+1 parâmetros. Existe uma relação em cadeia entre as diferentes camadas da rede e os resultados são transmitidos para baixo até a última camada de saída. Qualquer parâmetro de qualquer neurônio em qualquer camada afetará o resultado final. Portanto, esses parâmetros são as unidades de armazenamento da rede neural, usadas para armazenar padrões abstratos.
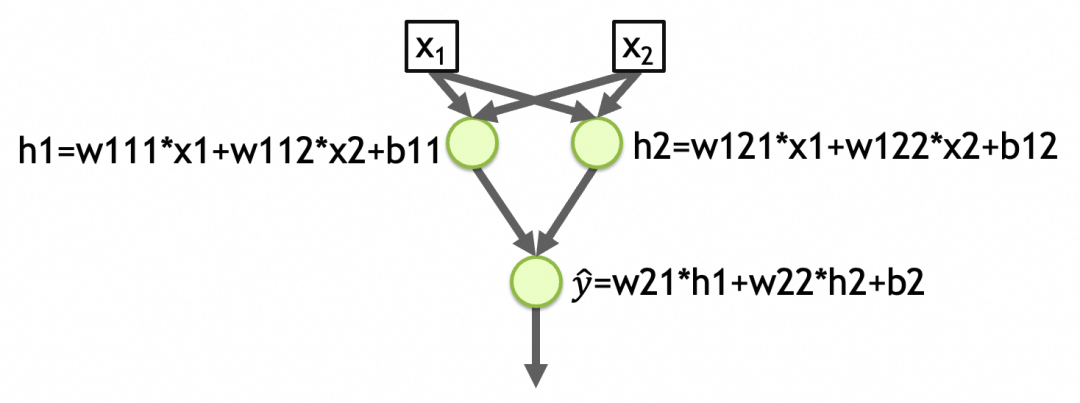
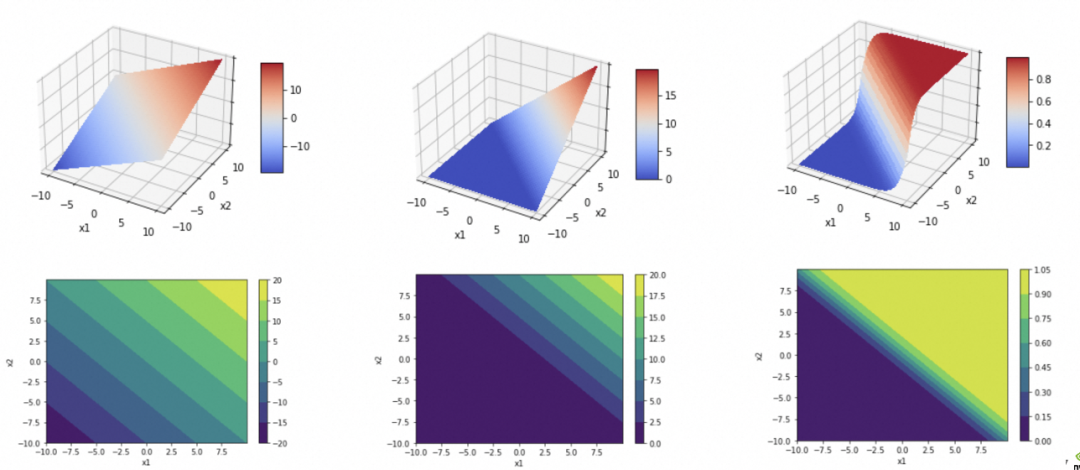
Para dar outro exemplo, [Rede 2] na figura abaixo é uma rede com duas entradas, duas camadas, 2 elementos na primeira camada, 1 elemento na segunda camada, e a função de ativação de cada camada é linear. O número total de parâmetros na primeira camada da rede = (número de entradas + 1) o número de nós = (2 + 1) 2 = 6, o número total de parâmetros na segunda camada = (2 + 1) * 1 = 3, o número total de parâmetros de rede = 6 + 3 = 9, o padrão abstraído é armazenado nesses parâmetros. (w111,w112,b11,w121,w122,b12,w21,w22,b2 na imagem abaixo)
função de ativação
y_hat=w21*h1+w22*h2+b2=w21*(w111*x1+w112*x2+b11)+w22*(w121*x1+w122*x2+b12)+b2
最终可以化简为
y_hat=w1'*x1+w2'*x2+b'
。而一个线性函数(直线、平面、…)是没法拟合/抽象现实问题的复杂度的。
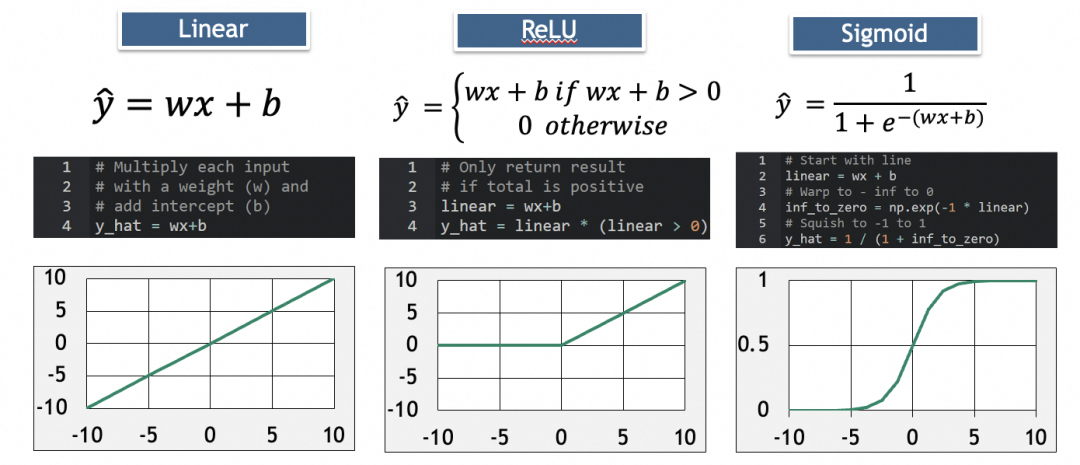
其中,ReLU用于消除负值,Sigmoid用于增加弧度。
深度学习过程
y_hat
。因为多层网络的计算是从上往下,所以称为前向传播:
第4步、通过反向传播算法计算各参数的梯度(gradient)。
各参数的梯度,即单个参数的变化会多大程度影响损失结果的变化。计算各参数的梯度,再将参数往损失结果变小的方向调整,即可在高维参数空间中找到损失最小值点。
为了计算梯度,我们需要先了解损失曲面。
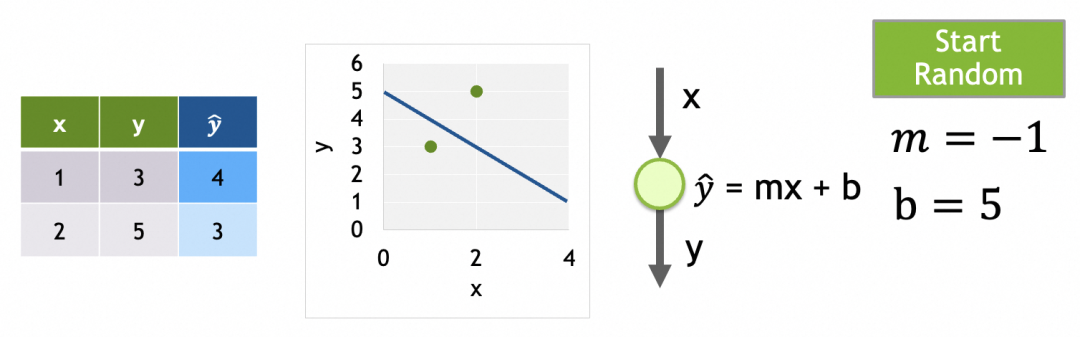
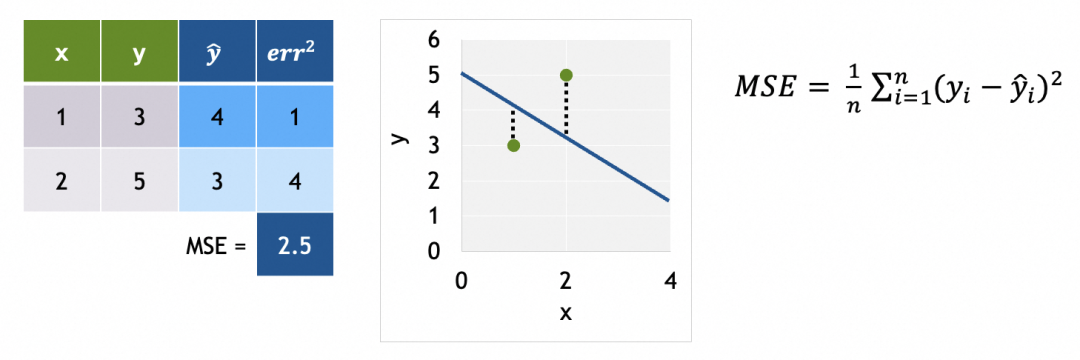
例子中只有m和b两个参数,如果将m和b作为x和y轴,损失函数结果作为z轴,可以得出损失曲面。(如果存在更多参数,形成高维参数空间,道理类似)
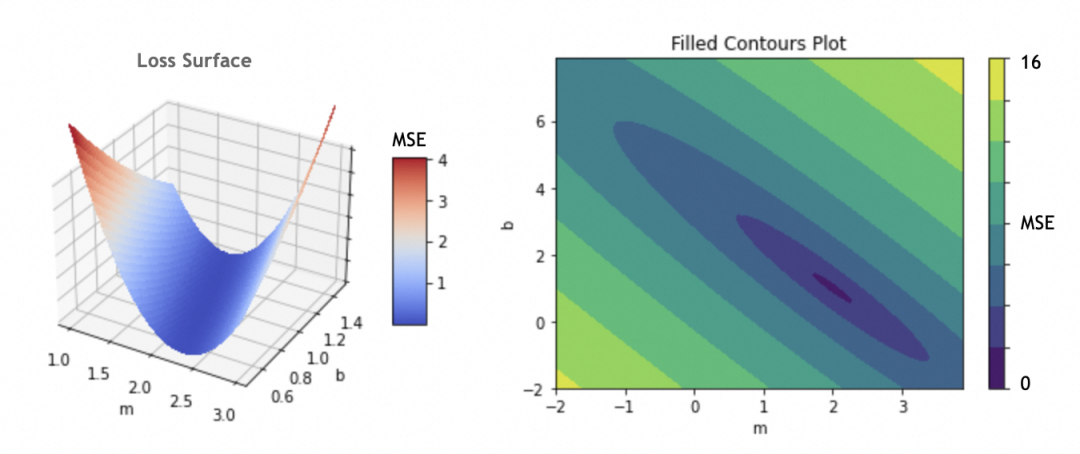
我们的目标是找出损失函数结果最小的m和b,这里即m=2,b=1。具体做法是将参数的当前值m=-1,b=5分次进行一定偏移,往m=2,b=1靠拢。
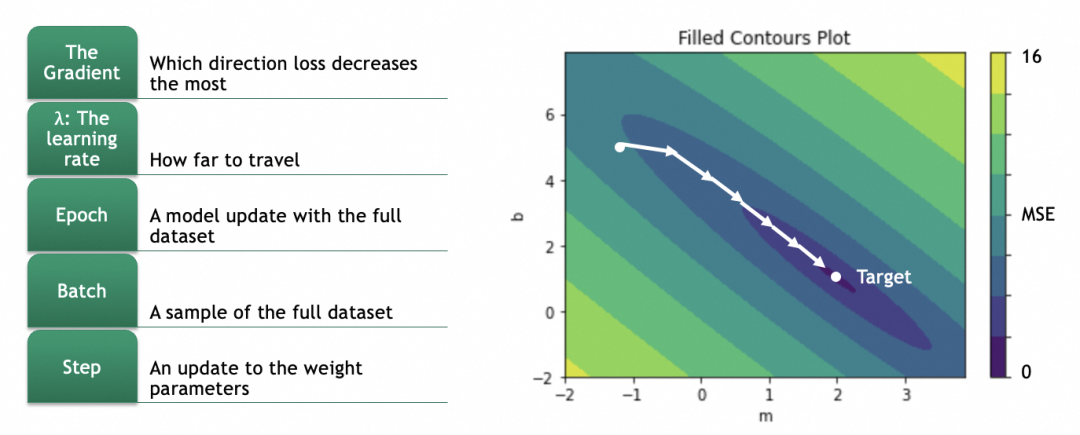
偏移具体怎么算呢?这就涉及到计算梯度,数学上就是计算偏导数。
对于一个曲面,当前在高处,要往低处移动,可以分别计算x、y两个方向(即m和b两个参数),在当前位置的梯度,即偏导数(partial derivative),即几何上的切线斜率,即单个参数的变化会多大程度影响损失结果的变化(注意梯度是向上的,用的话要取反)。
幸运的是,对于任何损失函数,都有对应公式算出对于某个参数的偏导数。例如,激活函数是y_hat = m * x + b,损失函数是L = (1/N) * Σ(y - y_hat)^2,则对于m的偏导数是∂L/∂w = (1/N) * Σ -2x(y - y_hat) = (1/N) * Σ -2x(y - (m * x + b))。这里仅仅是说明能解,因为模型会提供这个能力,所以我们一般不人为关注。
不仅如此,神经网络还有传导性,拿[网络2]举例,如果我们希望算出第一层参数w111的梯度,则可以按∂L/∂w111 = ∂L/∂y_hat * ∂y_hat/∂h1 * ∂h1/∂w111一层一层反向传播算回去,得到w111梯度具体的公式。
第5步、按梯度更新各参数:
因为偏导数是向上的,往低处走、梯度下降要取反。
拿m举例,m的新值m = m - learning_rate * ∂L/∂m。
注意learning_rate的选择,过大会导致越过最低点,过小会导致单次变化太小,训练时间太长。不过一般模型会提供自动渐进式的算法,我们无需人为关注。
第6步、网络的训练过程是迭代的,在每个训练周期(epoch)中,网络将通过梯度下降的方式逐步调整其参数。整个过程会重复多个epoch,直到模型的表现不再显著提高或满足特定的停止条件。
每个训练周期,即会用训练集进行训练,也会用验证集进行验证。通过对比训练集和验证集的结果,能发现是否存在过拟合现象。
关于全局最优解和局部最优解:
如果损失曲面比较复杂,比如有多个低洼,从某个点渐进式移动不一定能找到最低的那个,这种情况会拿到局部最优解而不是全局最优解。
关于训练batch:如果训练集非常大,每个训练周期不一定会拿全部训练集进行训练,而是会随机选一批数据进行。常见的方式有Stochastic Gradient Descent(SGD),一次选一个样例,这样的好处不仅计算量大大减少,还容易从局部最优解跳出,缺点是不太稳定。另一种方式是Mini-Batch Gradient Descent,这种一次选10-几百个样例。具有SGD的优点且比SGD稳定,比较常用。

MNIST数据集是深度学习领域的一个经典数据集,它包含了大量的手写数字图像,对于验证深度学习算法的有效性具有标志性意义。
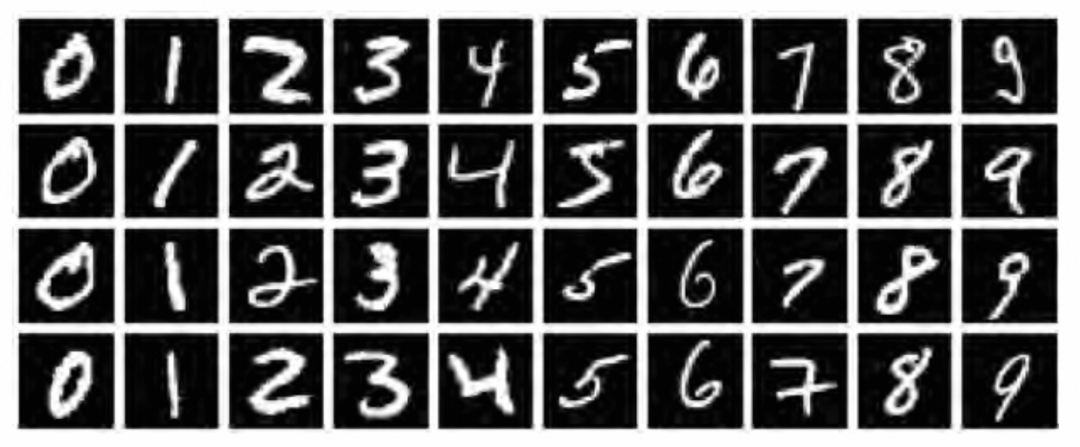
有了前面章节的理论,接下来,我们将通过一个实际案例来展示如何使用神经网络来解决图像分类问题。
下面的操作会用到jupyter平台和tensorflow2深度学习框架,但本文重点解释原理,平台和框架的使用就不多置笔墨了。
加载和观察数据集
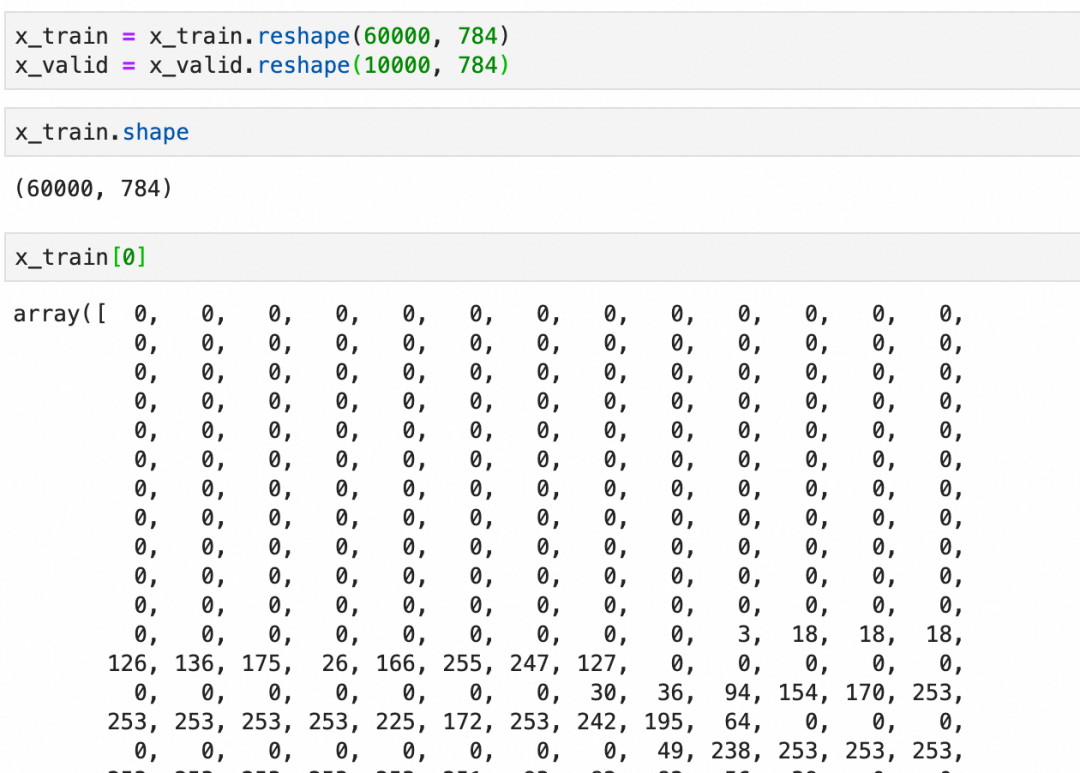
在使用图像进行深度学习时,我们既需要图像本身(通常表示为 "X"),也需要这些图像的正确标签(通常表示为 "Y")。此外,我们需要一组X和Y来训练模型,然后还需要一组单独的X和Y来验证训练后模型的表现。因此,MNIST数据集需要分成4份:
x_train:用于训练神经网络的图像y_train:x_train图像的正确标签,用于评估模型在训练过程中的预测结果x_valid:模型训练完成后用于验证模型表现的图像y_valid:x_valid图像的正确标签,用于评估模型训练后的预测结果

x_train
和验证图像集
x_valid
:可以看到是分别是60000张和10000张28x28 pixel的灰阶图像(灰度0-255):

每个图像是一个图像grid的二维数组,下图是二维数组的内容和可视化图像:

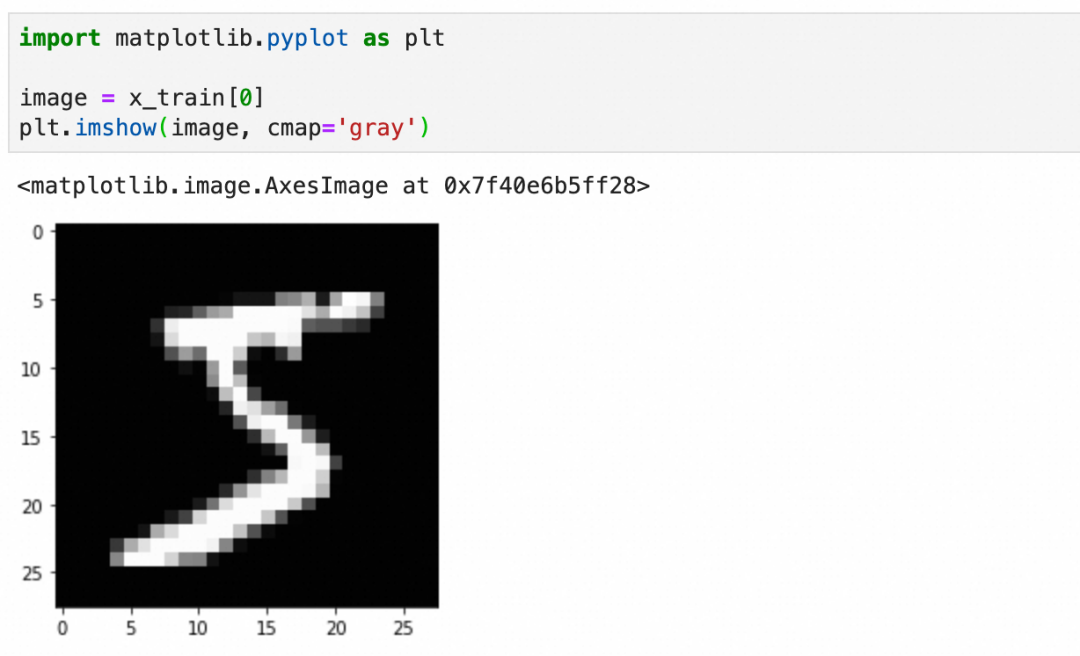
标签y_train比较简单,就是图像对应的数字:

预加工数据集
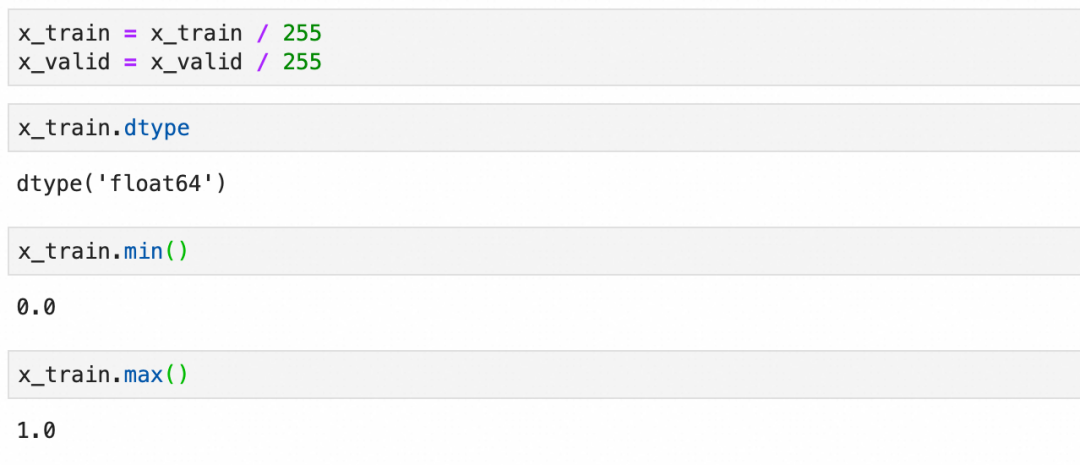
在将数据输入到神经网络之前,通常需要进行一些预处理。这包括将图像数据展平为一维向量,标准化像素值到0-1之间,并将标签转换为适合分类任务的格式,通常是one-hot编码。
展平:
标准化:
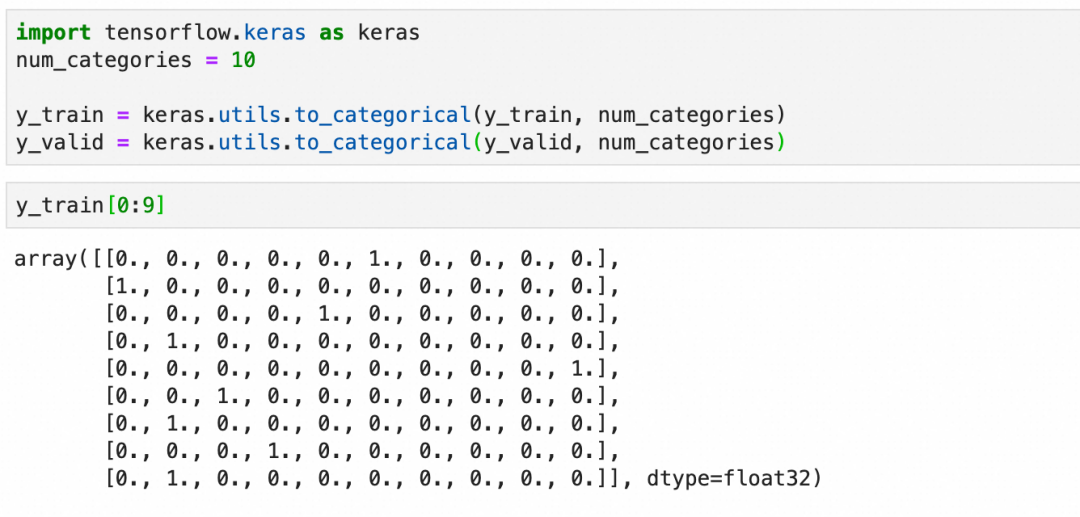
one-hot编码:
虽然这里的标签是0-9的连续整数,但不要把问题看作是一个数值问题(考虑一下这种情况,假设我们不是在识别手写0-9的图片,而是在识别各种动物的图片)。
这里本质上是在处理分类,分类问题的输出在深度学习框架里适合用one-hot编码来表达(一个一维向量,长度为总分类数,所属分类的值为1,其它值为0)。

创建模型
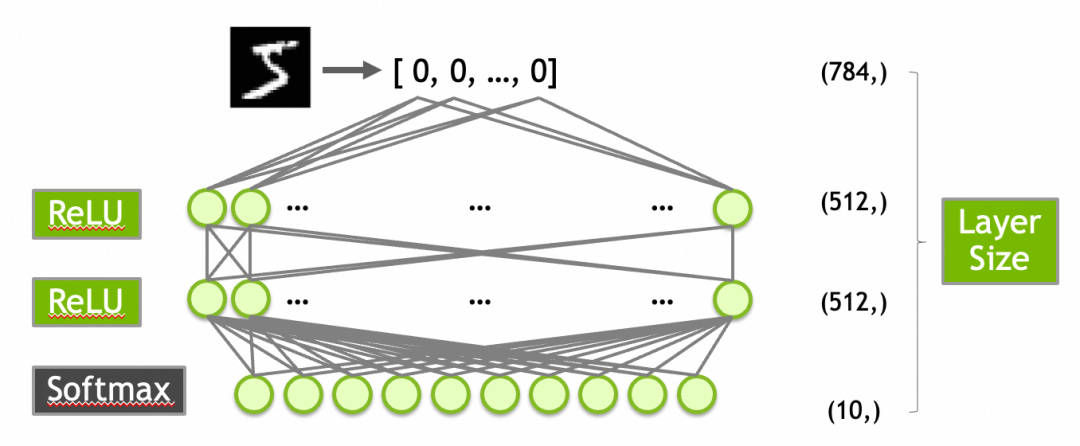
创建一个有效的模型通常需要一定的探索或者经验。对于MNIST数据集,一个常见的起点是构建一个包含以下层的网络:
784个输入(对应于28x28像素的输入图像)。
第一层是输入层,有512个神经元,激活函数是ReLU。
第二层隐藏层,使用512个神经元和ReLU激活函数。
第三层是输出层,10个神经元(对应于10个数字类别),使用Softmax激活函数以输出概率分布。
激活函数ReLU上面已经介绍过了,这里的Softmax需要介绍一下:Softmax函数确保输出层的输出值总和为1,从而可以被解释为概率分布。这对于多类分类问题非常有用。例如,输出层的10个输出值为[0.9, 0.0, 0.1, 0.0, ..., 0.0]可以解释为90%概率属于第1类,10%概率属于第3类。
按此创建模型并查看摘要:
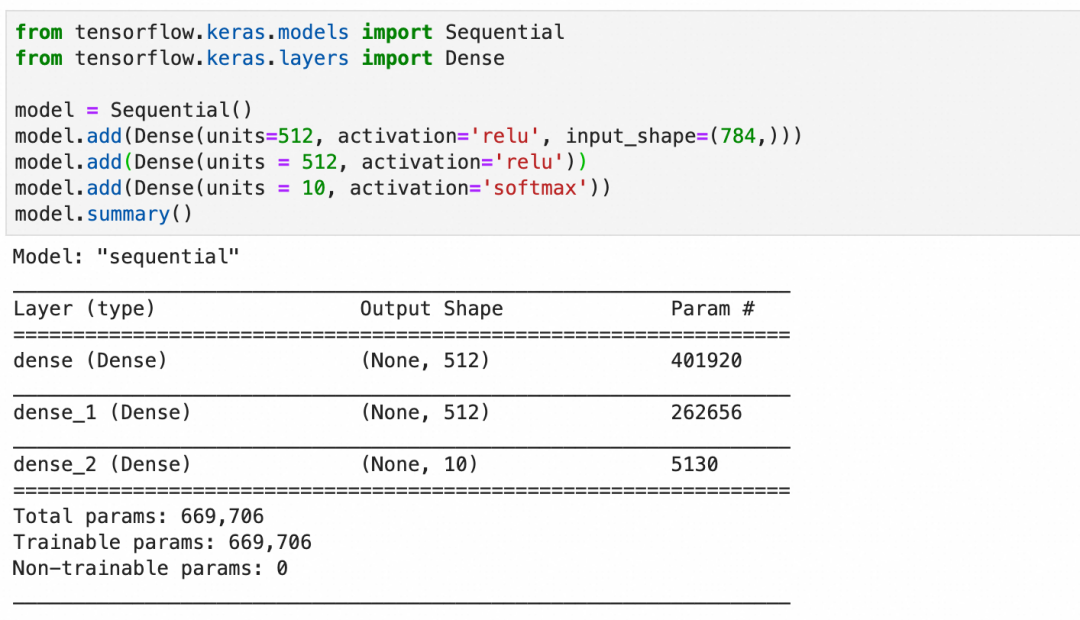
-
编译模型
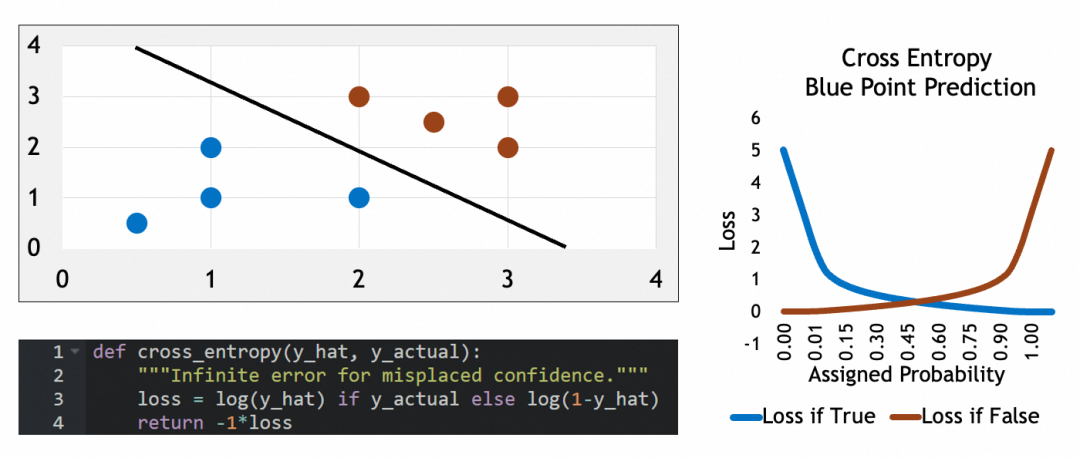
模型在编译时需要指定损失函数和优化器。对于多分类问题,损失函数通常选择交叉熵(Categorical Crossentropy),它的特征可以看参考公式:当实际属于某类(y_actual=1)时,损失等于log(y_hat),否则损失等于log(1-y_hat)。这个损失函数会惩罚错误猜测,使其损失接近∞,可以有效地量化预测概率分布与实际分布之间的差距。优化器则负责调整网络参数以最小化损失函数。

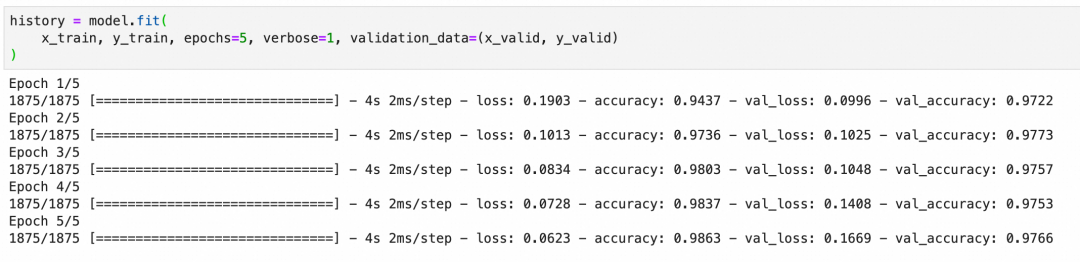
训练并观察准确率
训练模型时,我们会在多个训练周期内迭代更新参数,每个训练周期会经历一次完整的前向传递计算输出、损失函数评估结果和后向传递更新参数的过程。我们观察训练集和验证集上的准确率,以评估模型的表现和泛化能力。
注意损失曲面、梯度下降等概念和原理,如果不清楚可以回顾一下【深度学习过程】。
下图中的accuracy是训练集的准确率,val_accuracy是验证集的准确率,准确率符合预期。

如果模型在训练集上准确率很高,但在验证集上准确率低,可能出现了过拟合现象(overfitting)。过拟合意味着模型过于复杂或训练过度,以至于学习了训练数据中的噪声而非潜在规律。
训练集,左边损失非常小:
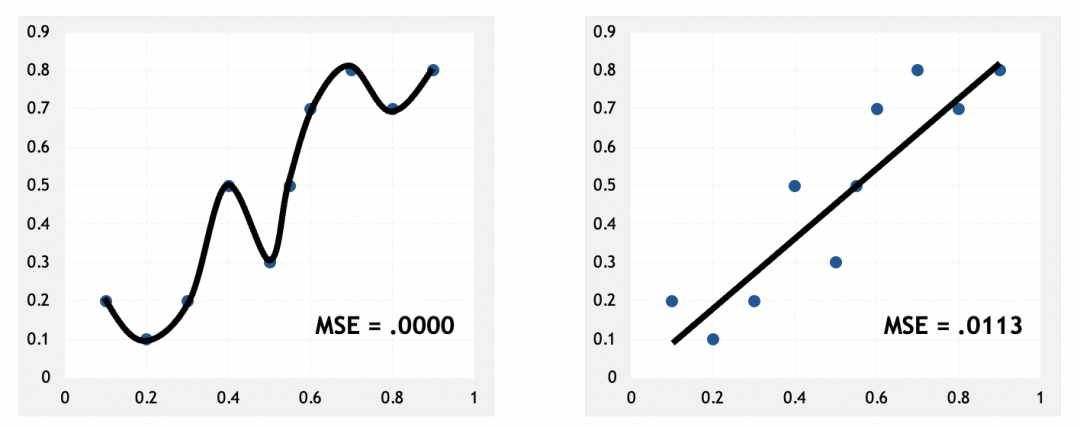
验证集,左边损失反而更大:
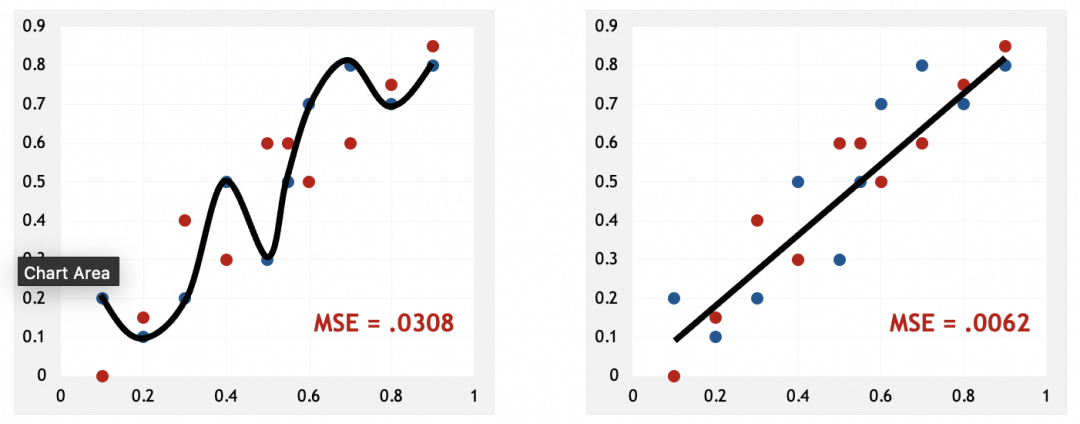
出现过拟合说明什么
左图可以看到,模型几乎硬套了训练集。和人脑类似,硬套部分实例,说明模型只是在记忆这些实例,只有找出它们的规律、特征、模式,才是真正的抽象。这也应证了我前面的说法,神经网络是在通过抽象解决问题。
为什么会出现过拟合
从被训练数据来看,过拟合说明训练集可能特征不明显,不容易抽象。比如被识别的图像模糊、亮度不高。
从模型来看,过拟合通常由于模型过于复杂或训练时间过长造成,走向了死记硬背。
如何解决过拟合
AI技术经过多年的发展,现在已经有比较成熟的方案来解决过拟合了,比如卷积神经网络、递归神经网络,这些我会在后面的文章里进行介绍。
本文大部分素材来自Nvidia在线课程Getting Started with Deep Learning。
(Getting Started with Deep Learning地址:https://learn.nvidia.com/courses/course-detail?course_id=course-v1:DLI+S-FX-01+V1)

团队介绍
天猫国际是中国领先的进口电商平台, 也是阿里巴巴-淘天集团电商技术体系中链路最完整且最为复杂的技术产品之一,也是淘天集团拥有最完整业务形态(平台+直营、跨境、大贸、免税等多业务模式)的业务。在这里我们参与到阿里电商体系的绝大部分核心系统(导购、商家、商品、交易、营销、履约等),同时借助区块链、大数据、AI算法等前沿技术助力业务高速增长。作为贴近业务前沿的技术团队,我们对于电商行业特性、跨境市场研究、未来交易趋势以及未来技术布局等都有着深度的理解。
本文分享自微信公众号 - 大淘宝技术(AlibabaMTT)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。