
Tanto o Alibaba Cloud quanto o Tencent Cloud passaram por situações em que todas as zonas de disponibilidade foram paralisadas ao mesmo tempo devido a uma falha de componente. Este artigo explorará como reduzir o domínio de falhas do ponto de vista do projeto arquitetônico e minimizar as perdas de negócios quando ocorrem falhas, e tomará a prática de estabilidade de Sealos como exemplo para compartilhar experiências e lições.
Abandone o mestre-escravo e adote a arquitetura ponto a ponto
Pode ser visto no relatório de falhas da Tencent Cloud que a falha de múltiplas zonas de disponibilidade ao mesmo tempo é basicamente causada por alguns componentes centralizados, como API unificada, autenticação unificada e outras falhas do sistema.
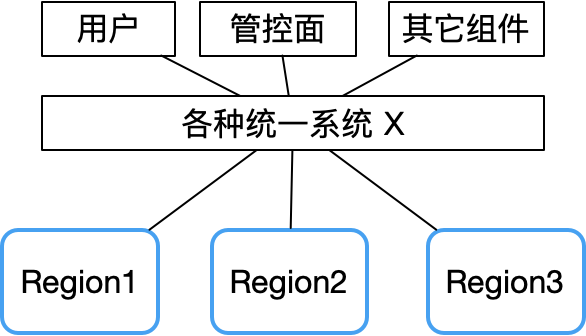
Portanto, uma vez que o sistema X falhe, o domínio de falha será muito grande.
Em contraste, uma arquitetura ponto a ponto descentralizada pode evitar bem esse risco. Tomemos como exemplo a rede Bitcoin, como não existe um nó central, sua estabilidade é muito maior do que a de um cluster mestre-escravo tradicional e é quase difícil de desligar.
Portanto, Sealos absorveu totalmente as lições do Alibaba Cloud e do Tencent Cloud ao projetar zonas de multidisponibilidade e adotou uma arquitetura sem proprietário. Todas as zonas de disponibilidade são autônomas. O principal problema é como os dados, como contas de usuário, são armazenados em múltiplas zonas de disponibilidade. problema. Tornou-se uma estrutura como esta:
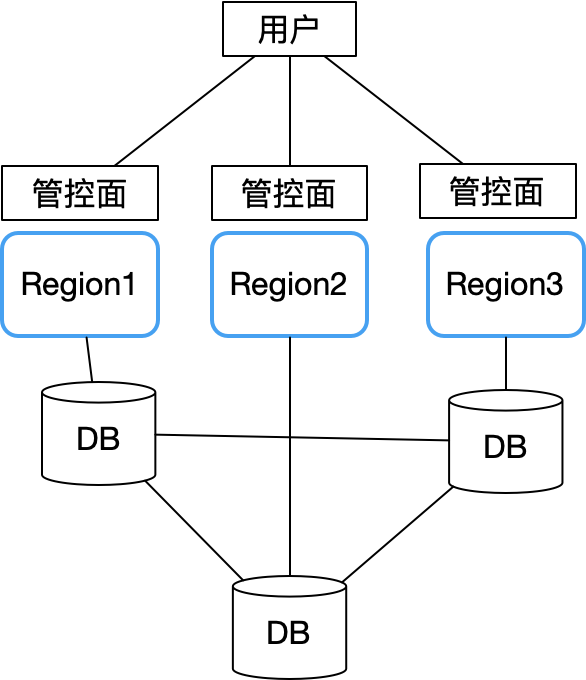
Cada zona de disponibilidade é completamente autônoma e sincroniza apenas os principais dados compartilhados (como informações de conta de usuário) por meio de um banco de dados distribuído entre regiões (usamos CockroachDB). Cada zona de disponibilidade está conectada ao nó local do banco de dados distribuído CockroachDB.
Dessa forma, uma falha em uma única Zona de Disponibilidade não afetará a continuidade dos negócios em outras regiões. Somente quando ocorrer um problema geral no cluster de banco de dados distribuído o plano de controle de todas as zonas de disponibilidade ficará indisponível. Felizmente, o próprio CockroachDB tem excelente desempenho em tolerância a falhas, recuperação de desastres e resposta a partições de rede, o que reduz bastante a probabilidade dessa situação acontecer. Desta forma, a arquitetura geral é simples, concentrando-se apenas em melhorar a estabilidade do banco de dados, monitoramento e testes destrutivos.
Outro benefício disso é que oferece conveniência para liberação em escala de cinza e operações diferenciadas. Por exemplo, novas funções podem ser verificadas primeiro com pequeno tráfego em algumas áreas e, em seguida, totalmente lançadas após a estabilização, diferentes áreas também podem fornecer serviços personalizados com base nas características dos grupos de clientes, sem precisar ser completamente consistentes;
Não existe um sistema absolutamente estável
Todo mundo reclama muito da estabilidade da nuvem, mas todos os fornecedores de nuvem, sem exceção, sofreram falhas. O mais importante aqui é como convergir. Não é apenas uma questão técnica, mas também organizacional. Questões de gestão também são uma questão de custos. Compartilharei isso com vocês com base em exemplos específicos que encontramos durante o processo empreendedor.
Lições de Sealos aprendidas com os fracassos
Laf grande falha em 17 de março de 2023
Este foi o primeiro grande fracasso que encontramos ao iniciar um negócio. Recebemos um tapa na cara apenas dois dias após o lançamento do produto. A razão pela qual nos lembramos dessa época com tanta clareza é que aconteceu a comemoração do primeiro aniversário da empresa. , e nem tivemos tempo de cortar o bolo. Durou até cerca das três da tarde.
A causa final da falha foi muito estranha. Usamos servidores leves para serem baratos . A virtualização de rede de contêineres em servidores leves levaria à perda de pacotes. No final, migramos todo o cluster para um servidor VPC normal, muitas vezes o problema. era estável. Sexo e custo são inseparáveis.
Portanto, muitas pessoas pensam que a nuvem pública é cara. Em muitos casos, custa muitas vezes resolver os 10% restantes dos problemas.
Laf posteriormente encontrou uma série de problemas de estabilidade relacionados ao banco de dados, porque usou um modelo no qual vários locatários compartilham uma biblioteca MongoDB . A conclusão final foi que esse caminho não funcionaria e seria difícil para nós resolver o isolamento do banco de dados. problema, então agora todos adotaram o método de banco de dados independente e o problema foi finalmente resolvido.
Há também o problema de estabilidade no gateway. Escolhemos inicialmente um controlador Ingress não confiável , o que causava problemas frequentes, não vou citar o controlador específico. Por fim, substituímos por Higress, que atualmente resolveu completamente o problema. Consome menos recursos e é mais estável. Também sou muito grato à equipe do Alibaba Higress por seu apoio pessoal. Os problemas que expusemos também ajudaram melhor o Higress a se tornar mais maduro, uma situação em que todos ganham.
Em junho de 2023, nossa nuvem pública Sealos foi lançada oficialmente. Um dos maiores problemas que encontramos foi o ataque de CC com grande tráfego. Adicionar proteção pode resolvê-lo, mas também significa um aumento nos custos. os dois são É muito confuso. Se você não evitar a estabilidade, é difícil resolvê-la. Se você evitar, não conseguirá recuperar o custo vendendo-a. Mais tarde, depois de substituirmos o gateway, descobrimos que o Envoy era realmente poderoso e poderia realmente resistir ao tráfego de ataque. Antes disso, usamos o Nginx, que era completo. Além disso, a grande vantagem do K8s é sua forte capacidade de autocura. Mesmo que o gateway esteja inativo, ele pode se autocurar em 5 minutos, desde que não caia ao mesmo tempo, o negócio não será afetado.
Melhores práticas para convergência de estabilidade
Processo de solução de problemas
Para melhorar continuamente a estabilidade do sistema, a Sealos estabeleceu internamente um rigoroso processo de gestão de falhas:
Cada vez que ocorre uma falha, ela deve ser registrada detalhadamente e acompanhada continuamente. Muitas empresas encerram o processo de revisão de falhas, mas na verdade a revisão não é o objetivo. A chave é formular medidas corretivas práticas e implementá-las para evitar completamente que falhas semelhantes voltem a acontecer. Após a conclusão do tratamento da falha, você ainda precisará continuar a observá-lo por um período de tempo até que seja confirmado que o problema não ocorre mais.
Em termos de metas de gestão, definimos inicialmente a meta de estabilidade e convergência no OKR do 1º trimestre de 2024 da seguinte forma:

Mais tarde, descobri que este OKR geral em estilo de slogan não era confiável e que a convergência de estabilidade precisava ser mais específica. O resultado deste KR foi que não conseguimos alcançá-lo e quase não teve efeito. No processo de convergência, você não precisa florescer totalmente em alguns pontos centrais a cada trimestre e continuar a iterar por alguns trimestres e a convergência será muito boa.
Portanto, no segundo trimestre definimos metas mais específicas:

A definição da estabilidade não pode limitar-se apenas à definição de um indicador, nem pode ser demasiado geral. Requer medidas concretas e visíveis e métodos de medição específicos.
Por exemplo, se for definido 99,9%, como alcançá-lo? Então, qual é a disponibilidade atual? Quais são as questões centrais em questão? Como medir? O que precisa ser feito? Quem fará isso? As configurações não estão limitadas ao tempo disponível, mas devem ser listadas em detalhes, como nível de falha, número de falhas, duração da falha, observação de falhas de grandes clientes, etc.
É necessário separar categorias especiais e listar as prioridades, como: estabilidade do banco de dados, estabilidade do gateway, grandes indicadores de disponibilidade de atendimento ao cliente, falha de sobrecarga de recursos de CPU/memória.
Devemos também nos concentrar no monitoramento de grandes clientes, como Auto Chess, clientes comerciais FastGPT, Chongchunxue Studio, etc. (uso mensal de mais de 30 núcleos, escolha 5 típicos).
Existem tantos problemas de estabilidade. Uma vez que esses grandes clientes sejam bem atendidos, os pequenos clientes podem basicamente ser cobertos. Não busque muitos, concentre-se em resolver os principais problemas de estabilidade atuais e, em seguida, certifique-se de estabelecer um processo de rastreamento completo.
Os alunos que causarem mau funcionamento poderão ser punidos, ter seus bônus descontados ou até mesmo expulsos. Como empresa start-up, normalmente não utilizamos medidas punitivas , porque as partes envolvidas não querem causar avarias e todos estão realmente trabalhando duro para resolver o problema. Quem realmente pode lutar são aqueles que foram feridos. prefira incentivos positivos, como Se a frequência de falhas trimestrais diminuir, dê alguns incentivos de forma adequada .
Projeto arquitetônico simples
A arquitetura do sistema está relacionada à estabilidade desde o início do projeto. Quanto mais complexa a arquitetura, mais fácil é ter problemas, por isso muitas empresas não prestam atenção a isso. Frequentemente participo do projeto e revisão da arquitetura da empresa, e geralmente encontro. que o design é muito complexo para eu entender, sinto que algo está errado. A zona de multidisponibilidade do Sealos é um bom exemplo. Para transformar uma coisa complexa em um CRUD simples, você só precisa melhorar a estabilidade do banco de dados. O design da estrutura da tabela do banco de dados é simples e muitos problemas de estabilidade são resolvidos no berço.
O mesmo se aplica ao nosso sistema de medição. Originalmente, projetamos-o para ter mais de uma dúzia de CRDs, mas depois de lutar por mais de meio ano, a estabilidade não pôde ser estabilizada. Finalmente, redesenhamos e selecionamos o sistema. duas semanas para ser desenvolvido e estava online de forma estável em um mês.
Portanto: o design simples é crucial para a estabilidade!
Monitoramento moderado, direcionado
A vigilância é uma faca de dois gumes, demasiado não é suficiente. Muitas falhas do Sealos foram causadas pelo monitoramento do Prometheus que ocupava muitos recursos e o servidor API estava sobrecarregado, o que por sua vez causava novos problemas de estabilidade. Depois de aprender a lição, mudamos para uma solução de monitoramento mais leve, como o VictoriaMetrics, ao mesmo tempo em que controlamos rigorosamente o número de indicadores de monitoramento. Ferramentas como o Uptime Kuma são muito úteis. Elas podem testar umas às outras entre regiões e encontrar problemas a tempo.
O mesmo se aplica ao plantão. Existem milhares de alarmes todos os dias. Então aqui começamos basicamente do 0 e vamos somando as coisas aos poucos. Por exemplo, primeiro fazemos isso na perspectiva da "estabilidade final do negócio do grande cliente". , o telefone provavelmente tocará sem parar. Em seguida, adicione lentamente coisas como o host não está pronto. Teoricamente, o host não está pronto e não deve afetar o negócio. À medida que o sistema amadurece gradualmente, ele acabará por não estar pronto e nenhuma chamada será necessária.
Não tenha medo do constrangimento ao relatar falhas
O relatório de revisão da Tencent Cloud foi muito bom. Explicou com veracidade os motivos da falha, analisou objetivamente o que não era suficiente e prometeu retificá-lo ativamente. Esse tipo de atitude franca e responsável torna mais fácil conquistar a confiança dos usuários. Por outro lado, manter o assunto em segredo por medo da fermentação da opinião pública equivale a beber veneno para matar a sede. Em vez disso, faz com que os usuários sintam que se trata de uma caixa preta opaca e que não sabem o que acontecerá no futuro . Os clientes que realmente amam seus produtos e estão dispostos a crescer com você podem tolerar erros sem princípios. O segredo é mostrar sinceridade e ações para melhorias reais.
Resumir
O serviço de nuvem pública Sealos foi lançado há mais de um ano e acumulou mais de 100.000 usuários registrados. Com suas excelentes funções, experiência e economia, muitos desenvolvedores o favorecem, e alguns grandes clientes também começaram a tentar migrar seus negócios para nossa nuvem Sealos. Entre eles estão alguns produtos de Internet de grande escala. Por exemplo, o jogo "Happy Auto Chess" tem mais de 4 milhões de usuários ativos .
Olhando para o futuro, acreditamos que através do gerenciamento sistemático de falhas, continuaremos a convergir a estabilidade. Através de um design de arquitetura simples e eficiente, uma estratégia de monitoramento estável e constante, e complementada por uma atitude de comunicação aberta e honesta, Sealos, uma nuvem que foi. nutrido e desenvolvido por uma pequena empresa nacional de código aberto, com certeza se tornará uma nuvem muito avançada!
Linus resolveu resolver o problema por conta própria para evitar que os desenvolvedores do kernel substituíssem tabulações por espaços. Seu pai é um dos poucos líderes que sabe escrever código, seu segundo filho é o diretor do departamento de tecnologia de código aberto e seu filho mais novo é um núcleo. contribuidor de código aberto Huawei: Demorou 1 ano para converter 5.000 aplicativos móveis comumente usados A migração abrangente para Hongmeng Java é a linguagem mais propensa a vulnerabilidades de terceiros Wang Chenglu, o pai de Hongmeng: Hongmeng de código aberto é a única inovação arquitetônica. no campo de software básico na China. Ma Huateng e Zhou Hongyi apertam as mãos para "remover rancores". Ex-desenvolvedor da Microsoft: o desempenho do Windows 11 é "ridiculamente ruim" " Embora o que Laoxiangji seja de código aberto não seja o código, as razões por trás disso são muito emocionantes. Meta Llama 3 é lançado oficialmente. Google anuncia uma reestruturação em grande escala.