
Autor: Vivo Internet Big Data Team-Wu Yonggang, Li Xiong
Este artigo é o quarto artigo da série de artigos "Prática do Modelo de Análise do Comportamento do Usuário" da equipe de big data da Internet da vivo - Modelo de Análise de Retenção.
Este artigo apresenta detalhadamente o conceito e os princípios básicos do modelo de análise de retenção e explica sua implementação específica no produto. Tendo em vista os problemas no próprio processo de utilização, foi explorada uma solução prática baseada no modelo de análise de retenção ClickHouse.
1. Requisitos de antecedentes
De acordo com estatísticas da CNNIC, os usuários da Internet na China atingiram 1,079 bilhão e a taxa de penetração da Internet atingiu 79,4%. Embora a Internet ainda esteja crescendo rapidamente, o número de usuários está gradualmente saturado. A Internet entrou na era dos usuários existentes. A competição geral de tráfego está se tornando cada vez mais acirrada e a retenção de usuários está se tornando cada vez mais importante do que atrair novos. Usuários. Portanto, como identificar usuários fiéis e compreender o desempenho de retenção do grupo de usuários-alvo? Como analisar a rotatividade de usuários e otimizar produtos? Como analisar se os usuários-alvo completaram o comportamento desejado e assim por diante são tópicos importantes em nossa análise de dados, e o modelo de análise de retenção é uma ferramenta importante para resolvermos esses problemas.
2. Visão geral
2.1 Introdução ao conceito
O modelo de análise de retenção é usado principalmente para analisar a proporção de usuários que acionaram o evento inicial para acionar eventos subsequentes (ou seja, eventos de visita de retorno) em períodos de tempo subsequentes. Este modelo pode refletir melhor a lealdade ou a adesão do usuário. Existem vários conceitos importantes para entender sobre o modelo de análise de retenção:

A análise de retenção geralmente requer a especificação do evento inicial e do evento de retorno, mas o evento de início e o evento de retorno podem ser iguais ou diferentes:
1. Você pode escolher o mesmo evento para o evento inicial e o evento de visita de retorno. Isso pode ver intuitivamente o número de usuários fiéis que acionaram o evento.
Por exemplo: durante o processo de login, o evento inicial é o sucesso de login e o evento de visita de retorno é o sucesso de login. Dentro de um período de tempo, o número de usuários que acionam continuamente esse evento pode ser o número de. usuários fiéis.
2. Você pode escolher eventos diferentes para o evento inicial e o evento de visita de retorno. Esses são os dados de retenção do usuário em um processo relativamente normal.
Por exemplo: Em uma determinada atividade, desde a colocação do pedido até o pagamento bem-sucedido, o evento inicial é a colocação do pedido e o evento da visita de retorno é o sucesso do pagamento. Dentro de um período de tempo, o mesmo usuário que aciona esses dois eventos é o processo designado. dados de retenção de usuários.
2.2 Ideias de análise
A taxa de retenção é um dos principais indicadores de um produto. Melhoramos as capacidades do produto, melhoramos a experiência do usuário e analisamos em grande medida os usuários-alvo para melhorar esse indicador. Por exemplo, podemos avaliar se uma determinada iteração é positiva calculando a taxa de retenção em N dias. Conforme mostrado na Figura 1, se um aplicativo otimizar o layout da página inicial e lançar a nova versão A, ele poderá ser combinado com a versão antiga B para calcular a taxa diária de retenção de usuários. Geralmente formará uma curva de retenção decrescente. Quanto mais lentamente a curva decai, maior é a nossa taxa de retenção, o que também reflete que a modificação da nossa página inicial tem um efeito positivo. É claro que, às vezes, a melhoria na retenção pode ser de apenas alguns décimos de um por cento, mas na premissa de uma grande base de usuários, também pode produzir algumas mudanças qualitativas. Também podemos definir grupos específicos de pessoas como grupos de usuários, realizar análises de retenção em diferentes grupos de usuários e descobrir grupos de usuários mais fiéis.
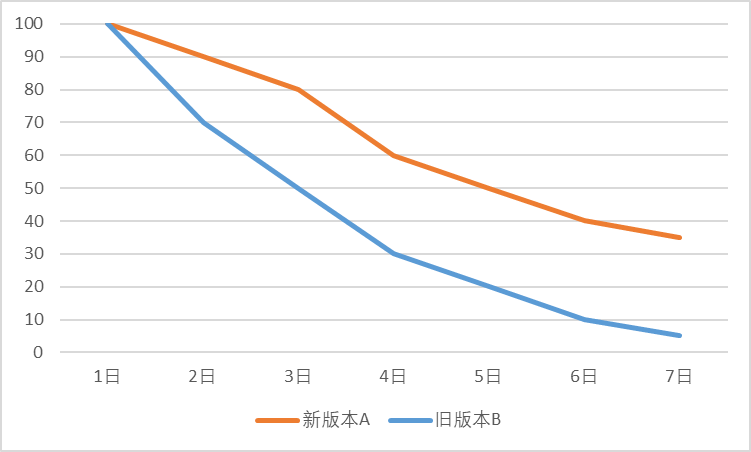
Figura 1 Comparação de retenção entre a nova versão A e a antiga versão B
3. Análise de dados usando retenção
Agora que entendemos os conceitos básicos do modelo de retenção acima, vamos dar uma olhada em como criar um.
3.1 Selecione um evento inicial e um evento de retorno
Iniciando evento: Abra o navegador.
Evento de visita de retorno: Saia do navegador.
3.2 Definir dias de retenção
Defina um período de retenção de 3 dias.
3.3 Determine o intervalo de tempo de retenção
O conceito de intervalo de tempo aqui se refere ao intervalo de datas que você precisa visualizar. Por exemplo, se você selecionar o intervalo de tempo como 2023-01-06~2023-01-08, então apenas os três dias de 2023-01-06 a. 2023-01-08 será calculado, cada dia é retido no mesmo dia, retido no 1º dia, retido no 2º dia e retido no 3º dia.
3.4 Lógica de exibição e cálculo dos dados retidos
Número de usuários iniciais = Número de usuários que acionaram o evento inicial na data calculada.
O número de usuários retidos no dia = a interseção de usuários que acionaram o evento de retorno no dia e usuários que acionaram o evento inicial no dia.
O número de usuários retidos no primeiro dia = a interseção dos usuários que acionaram o evento de retorno no dia seguinte e os usuários que acionaram o evento inicial na data calculada.
O número de usuários retidos no 2º dia = a intersecção dos usuários que acionaram o evento de retorno após 2 dias e os usuários que acionaram o evento inicial na data calculada.
O número de usuários retidos no 3º dia = a intersecção dos usuários que acionaram o evento de retorno após 3 dias e os usuários que acionaram o evento inicial na data calculada.
A taxa de retenção do dia = número de usuários retidos no dia / número inicial de usuários * 100%.
A taxa de retenção no primeiro dia = número de usuários retidos no primeiro dia / número de usuários iniciais * 100%.
A taxa de retenção no segundo dia = o número de usuários retidos no segundo dia/o número inicial de usuários*100%.
Taxa de retenção no 3º dia = número de usuários retidos no 3º dia/número inicial de usuários*100%.
A tabela de número de retenção de usuários (ou seja, Tabela 1) indica que quando o evento inicial é "navegador aberto" e o evento de visita de retorno é "saída do navegador", ele corresponde aos usuários retidos nos últimos 3 dias de 06/01/2023 a Dados de 09/01/2023.
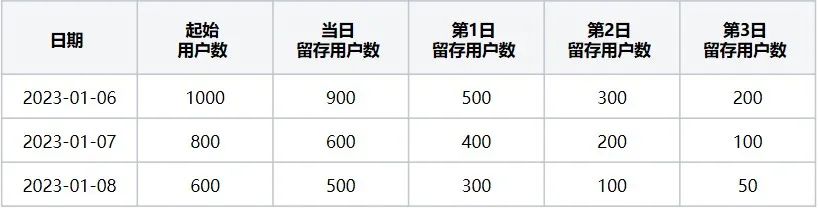
Tabela 1 Tabela de números de retenção de usuários
A tabela de taxa de retenção de usuários (ou seja, Tabela 2) indica que quando o evento inicial é "navegador aberto" e o evento de visita de retorno é "saída do navegador", ele corresponde aos usuários retidos nos últimos 3 dias de 06/01/2023 a 2023-01-08.
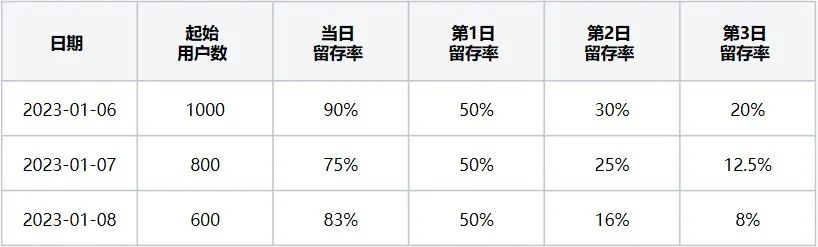
Tabela 2 Tabela de taxa de retenção de usuários
Tomando como exemplo os dados de 06/01/2023 na Tabela 1, o número de usuários iniciais em 6 de janeiro é 1.000: refere-se ao número de usuários que acionaram o evento inicial "navegador aberto" o número de usuários retidos naquele; dia: 900: refere-se ao número de usuários que acionaram o evento inicial “abrir navegador”. Quantidade de usuários que acionaram o evento de retorno “sair do navegador” no mesmo dia entre os usuários do evento inicial;
Número de usuários retidos no primeiro dia: 500: refere-se ao número de usuários que acionaram o evento de retorno em 7 de janeiro e cruzaram com o evento inicial em 6 de janeiro. Número de usuários retidos no segundo dia: 300: refere-se ao evento inicial em 6 de janeiro; o número de usuários que acionaram o evento de retorno em 8 de janeiro E o número de usuários de interseção que acionaram o evento inicial em 6 de janeiro é 300 e assim por diante até o terceiro dia. Neste momento, os três dias de dados retidos para o dia. 2023-01-06 são calculados!
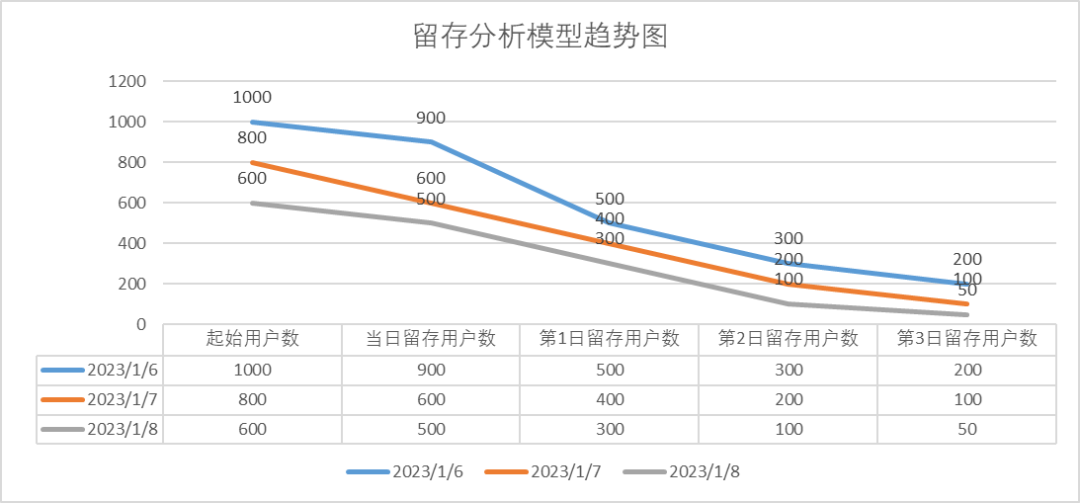
Figura 2: Gráfico de tendências de usuários retidos dentro de 3 dias, correspondente ao evento inicial acionador e ao evento de visita de retorno
4. Projeto funcional geral e implementação do modelo de análise de retenção
4.1 Função (off-line) Design geral de arquitetura
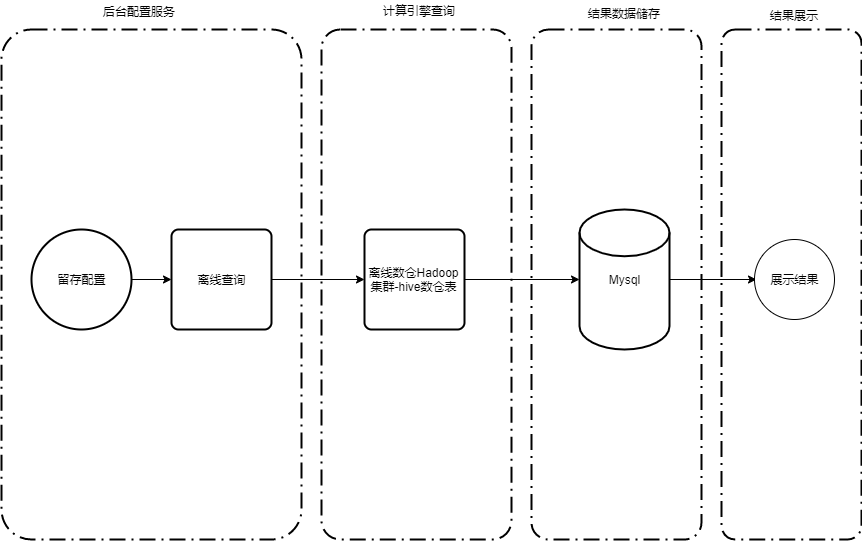
Figura 3 Diagrama da arquitetura Hive do modelo de análise de retenção
A arquitetura geral é dividida principalmente em quatro estágios: configuração, cálculo, armazenamento e exibição.
1. Configuração
Esta etapa trata principalmente da implementação de serviços de segundo plano do lado da engenharia. Os usuários podem definir eventos de início e de retorno, condições de filtragem, filtragem de grupos de usuários, filtragem de dimensões e outras configurações de acordo com suas próprias necessidades na plataforma. Após receber a solicitação de configuração, o serviço em segundo plano seleciona diferentes montadores de tarefas de acordo com o tipo de análise de retenção para montar as tarefas SQL.
2. Cálculo
Com base no método de consulta recebido, a plataforma seleciona o mecanismo Spark de consulta offline para análise e cálculo. Os resultados dos cálculos offline são sincronizados com o MySQL.
3. Armazenamento
O conjunto de resultados offline é persistido no banco de dados MySQL e pode ser exibido ao usuário por meio do serviço em segundo plano.
4. Exibição
Os resultados offline são exibidos de acordo com o ID de configuração do gráfico, consultando os dados da tabela de resultados do MySQL. A consulta instantânea é consultada diretamente e exibida após a configuração.
4.2 (Offline) Implementar SQL sob diferentes condições de retenção
Execução universal offline de SQL de tarefa Hive
SQL de execução do hive de retenção offline
Os significados dos campos em SQL são:
[origin_day]: data inicial do cálculo da retenção
[dia]: Data final do cálculo da retenção
[diff]: Em que dia salvar
[usuário]: Número de usuários iniciais
【retenção】:número de retenção
O significado SQL acima: Consultar os dados de retenção detalhados de cada dia no intervalo desde a data de início do cálculo da retenção até a hora de início e de término. Os dados de retenção completos no intervalo de tempo não podem ser calculados de uma só vez. vários dias, e O resultado desta execução SQL é exibido como um triângulo invertido preenchendo a tabela de resultados retidos.
Por exemplo: depois de definirmos o evento de início e o evento de retorno, calculamos a retenção de 3 dias para cada dia de 01/05/2022 a 05/05/2022. Neste momento, o horário de início é 01/05/2022. e o horário de término é 2022-05-05, o período de retenção é de 3 dias.
Para este caso, a data inicial de cálculo da retenção deve ser 2022-05-01~2022-05-08, para que a retenção de 3 dias possa ser calculada para cada dia de 2022-05-01~2022-05-05.
Etapa 1 : Calcule a data de retenção inicial = 01/05/2022, e o intervalo de datas de cálculo de retenção final são os dados de retenção diários de 01/05/2022 a 05/05/2022 De uma perspectiva de tempo, a data de cálculo de retenção inicial. Só pode calcular a retenção em 01/05/2022. Os resultados após a execução são os seguintes (Tabela 3):

Tabela 3
起始留存计算日期2022-05-01在2022-05-01~2022-05-05区间内留存详情数据
此时转换后留存数据表格为(表4):
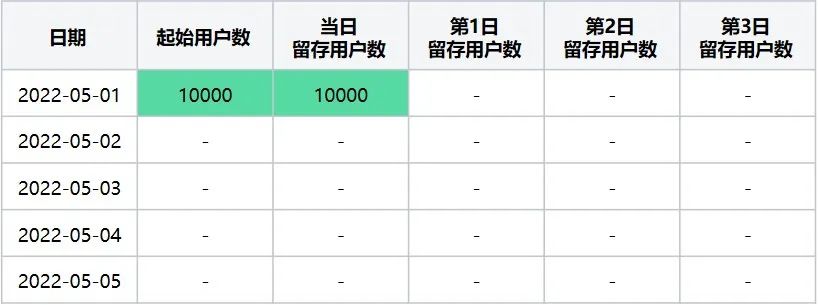
表4
起始留存计算日期2022-05-01在2022-05-01~2022-05-05区间内转换后留存数据表
第二步:计算起始留存日期 = 2022-05-02时,最终留存计算日期区间2022-05-01~2022-05-05日每天的留存数据,该起始留存计算日期可计算2022-05-01日的第1日留存用户数及2022-05-02日当日留存用户数据,执行后结果如下(表5):

表5
起始留存计算日期2022-05-02在2022-05-01~2022-05-05区间内留存详情数据
此时转换后留存数据表格为(表6):
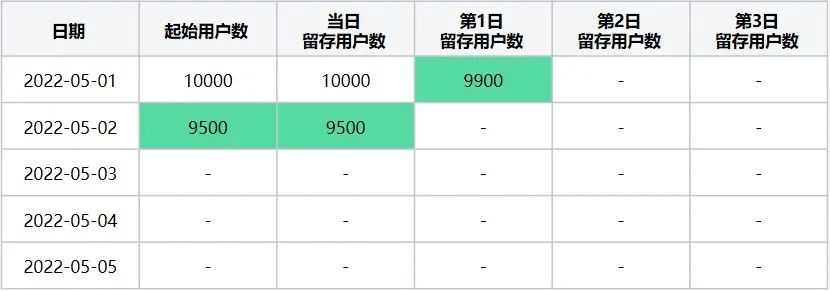
表6
起始留存计算日期2022-05-02在2022-05-01~2022-05-05区间内转换后留存数据表
第三步:计算起始留存日期 = 2022-05-03时,最终留存计算日期区间2022-05-01~2022-05-05日每天的留存数据,该起始留存计算日期可计算2022-05-01日的第2日留存用户数、2022-05-02日第1日留存用户数据、2022-05-03日当日留存用户数据,执行后结果如下(表7):
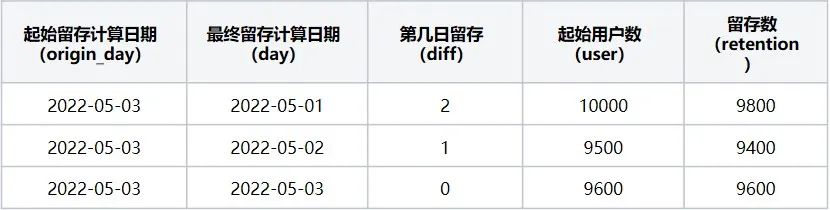
表7
起始留存计算日期2022-05-03在2022-05-01~2022-05-05区间内留存详情数据
此时转换后留存数据表格为(表8):
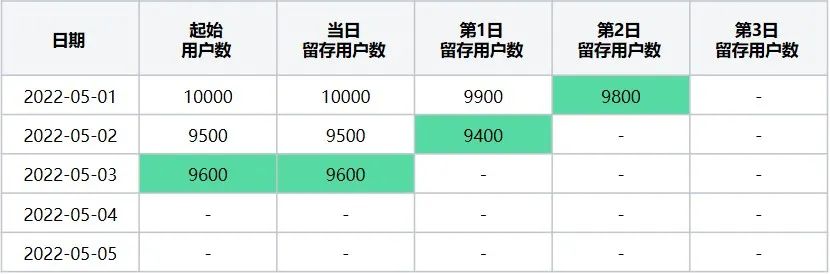
表8
起始留存计算日期2022-05-03在2022-05-01~2022-05-05区间内转换后留存数据表
第四步:以此类推,计算起始留存日期 = 2022-05-08时,最终留存计算日期区间2022-05-01~2022-05-05日每天的留存数据,该起始留存计算日期可计算2022-05-05日的第3日留存用户数,执行后结果如下(表9):

表9
起始留存计算日期2022-05-08在2022-05-01~2022-05-05区间内留存详情数据
最终数据展示完全后会是一个完整的表格(可得如下结果表10):
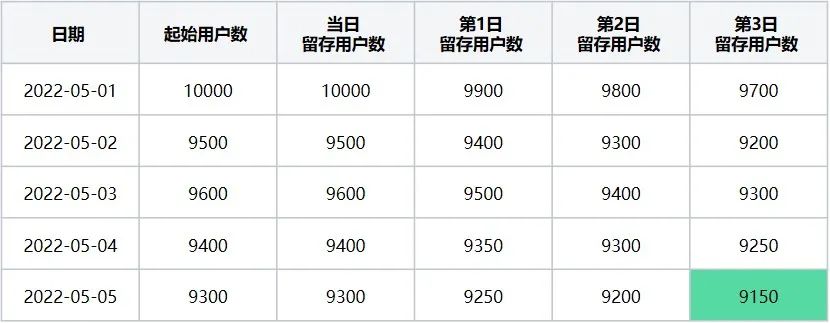
表10
2022-05-01~2022-05-05的每一天的3日留存数据表
4.3 存在的问题与下一步优化的方向
存在的问题:
用户在平台上进行报表创建后,在产出报表结果上耗时较长;当配置报表查询周期长,数据量大的情况下,存在计算资源消耗过大的情况。
优化方向:
为了优化报表生成过程,可以考虑使用ClickHouse来处理数据。ClickHouse是一个高性能、分布式、列式存储的数据库系统,特别适合处理大规模数据和复杂查询。
具体而言,可以采用以下ClickHouse特性:
将数据导入ClickHouse中,以便更快地查询和计算。ClickHouse支持高效的数据导入和压缩方式,可以大大减少数据的存储空间和查询时间。
利用ClickHouse的列式存储和分布式计算能力,实现增量计算和数据预处理。通过使用ClickHouse的分布式计算能力,可以将计算任务分配给多个节点并行处理,从而加快计算速度。同时,通过使用ClickHouse的列式存储能力,可以避免不必要的数据读取和计算,提高计算效率。
利用ClickHouse的缓存机制,提高查询效率。ClickHouse支持高效的缓存机制,可以将查询结果缓存在内存中,以便更快地响应查询请求。
利用ClickHouse的SQL查询语言,实现灵活的数据分析和报表生成。ClickHouse支持SQL查询语言,可以方便地进行数据分析和报表生成,同时也支持复杂查询和聚合操作,可以满足各种数据分析需求。
通过利用ClickHouse上述特性,进一步提高整个数据分析过程的效率和准确性。
五、基于ClickHouse的留存分析模型
5.1 利用ClickHouse查询速度快的特性改造离线留存图表产出方式
利用ClickHouse进行实时留存查询
传统的离线留存计算通常需要借助Hadoop、Spark等大数据处理框架,需要消耗大量计算资源和时间。而利用ClickHouse进行离线留存计算,可以大大提高计算速度和效率,可以实现秒级响应和高并发查询。
具体步骤如下:
将用户行为数据导入ClickHouse;
根据查询配置数据组装留存SQL用于查询;
利用ClickHouse的高速查询功能,实时查询留存率数据。
利用ClickHouse进行留存图表的产出
利用ClickHouse进行留存计算和查询后,可以通过数据可视化工具对留存数据进行图表化展示,从而更加直观地了解用户留存情况。例如:
利用数据可视化工具连接ClickHouse数据库,查看留存率数据或者通过http请求查询结果表数据;
通过数据可视化工具绘制留存图表,并进行定制化设计和样式调整。
结合hive、ClickHouse两者优点,可将架构做如下优化,对于历史较长时间日期的结果回溯进行hive查询处理,可在ClickHouse中存储的数据作为每天例行查询存储结果。
例行:是指创建一次图表每日例行执行报表任务,产出数据(例行可回溯ClickHouse中存储日期的留存数据)。
手动:是指在指定时间范围内执行,执行完成产出任务停止。
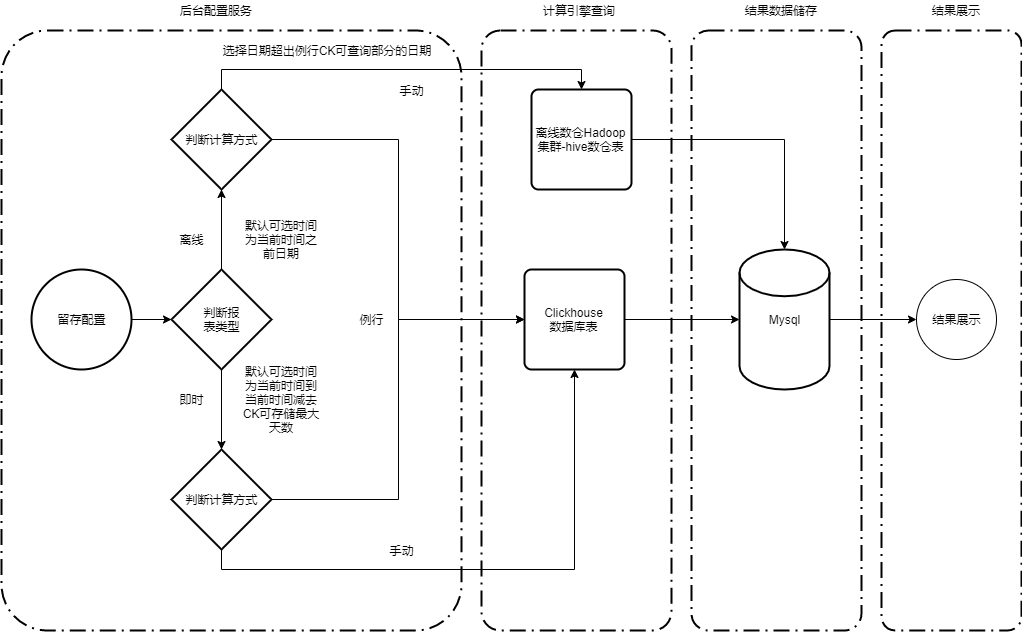
图4 结合ClickHouse、hive后留存分析模型架构图
5.2 主要函数介绍
Retention
该函数将一组条件作为参数,类型为1到32个 UInt8 类型的参数,用来表示事件是否满足特定条件。任何条件都可以指定为参数(如 WHERE)。
除了第一个以外,条件成对适用:如果第一个和第二个是真的,第二个结果将是真的,如果第一个和第三个是真的,第三个结果将是真的,等等。
① 语法
retention(cond1, cond2, ..., cond32);
② 参数
cond — 返回 UInt8 结果(1或0)的表达式。
③ 返回值
数组为1或0。
1 — 条件满足。
0 — 条件不满足。
④ 类型
UInt8
ClickHouse查询SQL
ClickHouse即时查询留存SQL
SQL 当中返回结果含义分别为:
retention_date:留存日期
user:起始用户数
retain0:当日留存用户数
retain1:第1日留存用户数
retain2:第2日留存用户数
retain3:第3日留存用户数
ratio0:当日留存率
ratio1:第1日留存率
ratio2:第2日留存率
ratio3:第3日留存率
以上SQL含义:计算出指定时间区间内3日留存信息,可一次性查询出指定区间内的所有3日留存数据,一个sql即可查询完全。
例如:我们定了起始事件和回访事件后,去计算2022-06-01~2022-06-04的每一天的3日留存,此时,起始时间是2022-06-01,结束2022-06-04,留存天数3天。
针对此案例,在不同的日期查询数据完整性不一致,我们拿2022-06-04日和2022-06-07日两日查询举例。
第一步:针对2022-06-04日进行计算2022-06-01~2022-06-04的每一天的3日留存,执行后留存数据展示结果如下(表11)。

表11
2022-06-04日计算2022-06-01~2022-06-04的每一天的3日留存数据表
第二步:针对2022-06-07日进行计算2022-06-01~2022-06-04的每一天的3日留存,执行后留存数据展示结果如下(表12)。

表12
2022-06-08日计算2022-06-01~2022-06-04的每一天的3日留存数据表
趋势结果展示(图5):
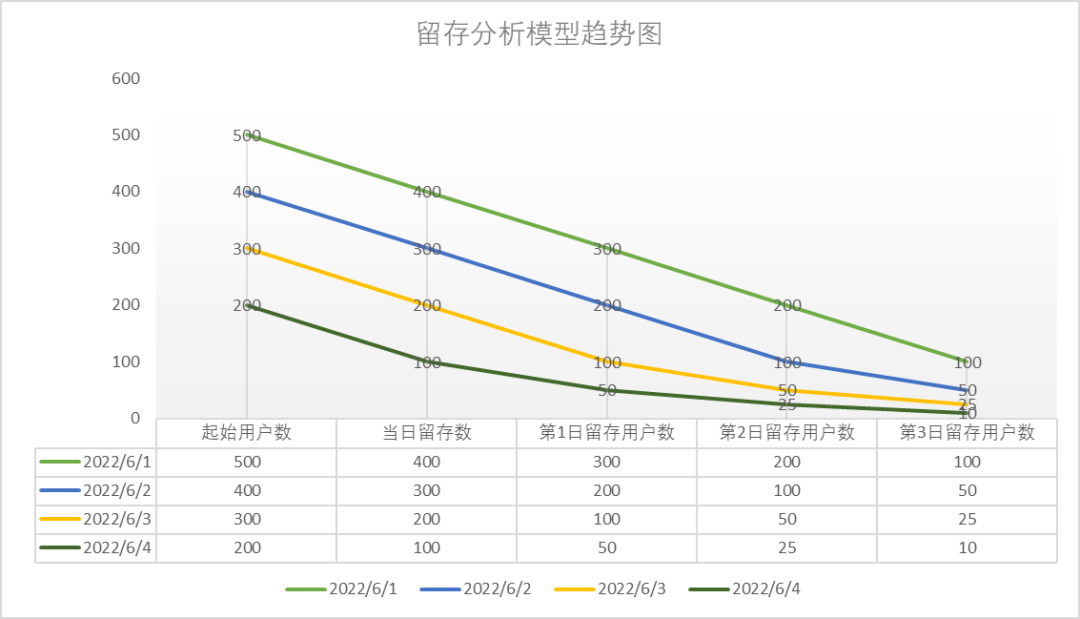
图5 留存分析模型趋势图
六、写在最后
本文介绍的留存模型就是数据分析工具箱的核心分析模型,使用的范围十分广泛。它通过计算用户在一段时间内的留存率,可以评估产品、服务或应用程序的用户体验和吸引力,提高用户留存率和活跃度。在实际的生产中,业务可根据自身具体需求和用户特征进行定制化设计,同时也可将通过留存分析得到的人群信息结合其他的数据分析方法进一步的深入分析。例如,从留存中得到的用户人群信息,我们可以进一步的使用路径分析的分析方法,分析用户的访问行为对于产品的影响。
数据分析的工具方法有很多,除了上面提到过得用于分析用户在应用上的访问行为的用户路径分析;也有衡量业务中关键事件之间转化效果的漏斗分析;还有事件分析、归因分析等等,他们共同组成的强大的数据分析工具箱,可以较为全面的分析用户行为的潜在特征与规律,帮助产品或者决策者作为更加可靠的决策。
END
猜你喜欢
本文分享自微信公众号 - vivo互联网技术(vivoVMIC)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。