
Recentemente, a Conferência Kangaroo Cloud Spring com o tema "Dados + IA, construindo nova produtividade" foi concluída com sucesso. A conferência trouxe uma série de produtos digitais " +AI " e as mais recentes precipitações da indústria, com o objetivo de integrar estreitamente os dados e. IA, quebrando os limites tradicionais da produtividade e capacitando as empresas para alcançar um desenvolvimento digital mais eficiente e de maior qualidade. Na reunião, Tou Tian, gerente de produto do Kangaroo Cloud Data Stack, trouxe uma nova versão do Data Stack V6.2 que integra recursos de IA . Esta não é apenas uma simples atualização de produto, mas também representa a ousada previsão do Kangaroo Cloud. futuro. .
Data Stack V6.2: Maximizando o valor dos dados
Na era orientada por dados, os dados tornaram-se a tábua de salvação das empresas. Como gerenciar e utilizar esses dados de maneira eficaz é uma questão que todas as empresas estão explorando. O lançamento do Data Stack V6.2 visa justamente resolver esse desafio e ajudar as empresas a navegar nas ondas do oceano de dados.
O conceito central do recém-lançado Data Stack V6.2 é Data+AI . A nova versão não apenas fornece as funções básicas da plataforma de big data, mas também fornece às empresas análises e aplicativos inteligentes de dados por meio de profunda integração com a tecnologia de IA . Isso significa que as empresas podem usar a plataforma de pilha de dados para obter integração de sistemas de conteúdo do setor, insights de dados flexíveis e convenientes, cálculos de mecanismo de análise extremamente rápidos e gerenciamento e controle abrangentes da segurança de dados. Além disso, as soluções de produtos Kangaroo Cloud também cobrem muitos aspectos, como leveza, governança de dados e criação de informações. Tudo isso foi projetado para ajudar as empresas a otimizar os custos de armazenamento computacional, melhorar a qualidade dos dados, promover padrões e especificações e, em última análise, maximizar o valor dos dados.
1. Solução leve de data center, o processamento de dados é mais eficiente
Ao introduzir motores de computação eficientes Doris e StarRocks , é alcançada uma reconstrução revolucionária do desempenho da plataforma. Este movimento inovador não só melhora significativamente a velocidade de processamento de dados, reduz os custos de armazenamento e de operação e manutenção, mas também otimiza a eficiência das consultas e traz às empresas uma experiência de operação de dados sem precedentes. Os recursos de consulta ad hoc e de processamento analítico de alto desempenho da Doris e da StarRocks constroem em conjunto uma plataforma de processamento de dados poderosa e flexível. Os usuários podem lidar facilmente com as necessidades de análise em tempo real de dados massivos e obter insights instantâneos de dados e suporte à decisão. Nesse processo, a precisão e a confiabilidade dos dados são totalmente garantidas, fornecendo sólido suporte de dados para os principais negócios da empresa, como previsão de falhas, marketing de precisão e otimização de processos.
e de processamento analítico de alto desempenho da Doris e da StarRocks constroem em conjunto uma plataforma de processamento de dados poderosa e flexível. Os usuários podem lidar facilmente com as necessidades de análise em tempo real de dados massivos e obter insights instantâneos de dados e suporte à decisão. Nesse processo, a precisão e a confiabilidade dos dados são totalmente garantidas, fornecendo sólido suporte de dados para os principais negócios da empresa, como previsão de falhas, marketing de precisão e otimização de processos.
2. Sistema abrangente de governança de dados para maximizar o valor corporativo
No Data Stack V6.2, atualizamos e redefinimos de forma abrangente a governança de dados para atender às crescentes necessidades das empresas em gerenciamento de dados. As cinco dimensões do centro de governação de dados : armazenamento, computação, qualidade, especificação e valor, constituem um sistema abrangente de governação de dados para garantir a integridade, precisão e disponibilidade dos dados empresariais.
O ambiente de trabalho de governança fornece uma interface de operação intuitiva, tornando simples e eficiente iniciar, registrar, atribuir e processar tarefas de governança de dados. Através desta plataforma, as empresas podem exibir o estado de governação de dados a partir de uma perspectiva pessoal, de uma perspectiva de projecto a uma perspectiva panorâmica, garantindo assim que a qualidade dos dados de cada link seja eficazmente monitorizada e gerida. A função de inspeção de código padroniza o código SQL por meio de regras de inspeção SQL para evitar antecipadamente possíveis problemas de gerenciamento. O gerenciamento de arquivos pequenos visa resolver o problema de arquivos pequenos em clusters Hadoop, otimizando o desempenho e a escalabilidade do cluster por meio de fusão única ou regular e melhorando a eficiência do processamento de dados .
A governança de dados do DataStack V6.2 não é apenas uma atualização de tecnologia, mas também uma formação da cultura de dados corporativos. Através de tal sistema de governança, as empresas podem estabelecer uma estrutura completa de governança de dados , promover a padronização e padronização de dados e, em última análise, maximizar o valor dos ativos de dados.
3. A adaptação de link completo Xinchhuang suporta localização abrangente
Nesta era de informatização e inovação da informação, estamos bem conscientes das necessidades das empresas em termos de segurança de dados e controlabilidade independente. Portanto, nossa plataforma não apenas alcança cobertura completa de inovação de informações em termos de servidores, sistemas operacionais, chips, middleware, bancos de dados de metadados, mecanismos de computação, etc., mas também faz adaptações profundas na na proteção de segurança de todo o processo.eimplantação privatizada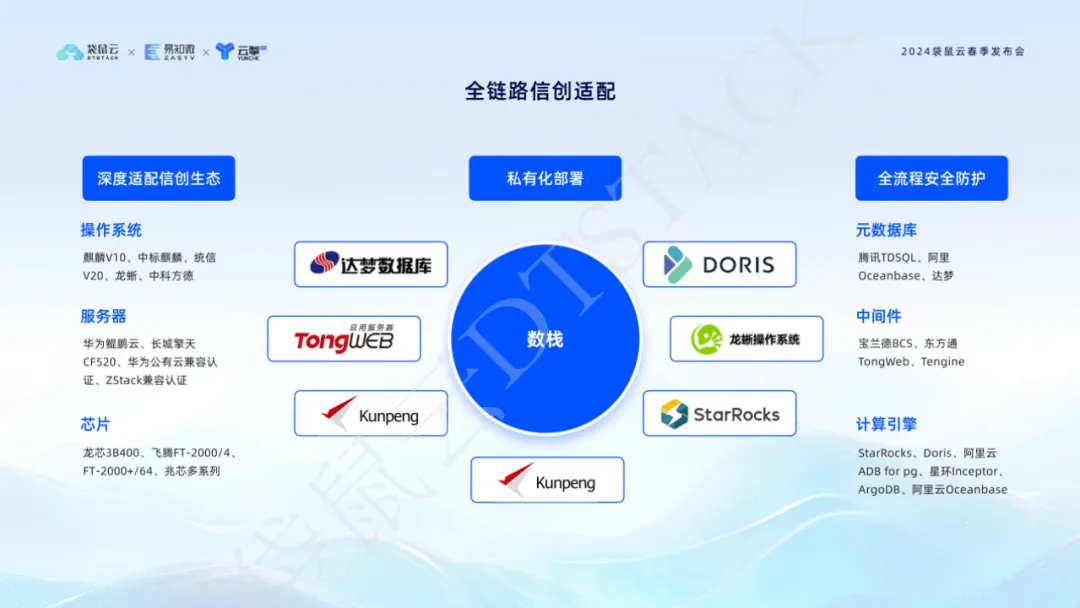
4. Inovar e aprimorar os recursos do data lake Paimon para realizar um modelo de processamento de dados integrado em fluxo em lote
No modelo tradicional de processamento de dados, as empresas muitas vezes enfrentam o dilema de desenvolver e manter dois conjuntos de lógica de código: um para processamento em lote e outro para processamento de fluxo em tempo real. Isto não significa apenas duplicar a carga de trabalho de desenvolvimento e manutenção, mas também requer o processamento da lógica de fusão de dados entre os dois para garantir que os dois sistemas fiquem online simultaneamente. Tal modelo não só aumenta o consumo de recursos, mas também pode levar à ambiguidade dos dados, dificultando a garantia da precisão dos dados e reduzindo a confiança do pessoal empresarial nos resultados dos dados.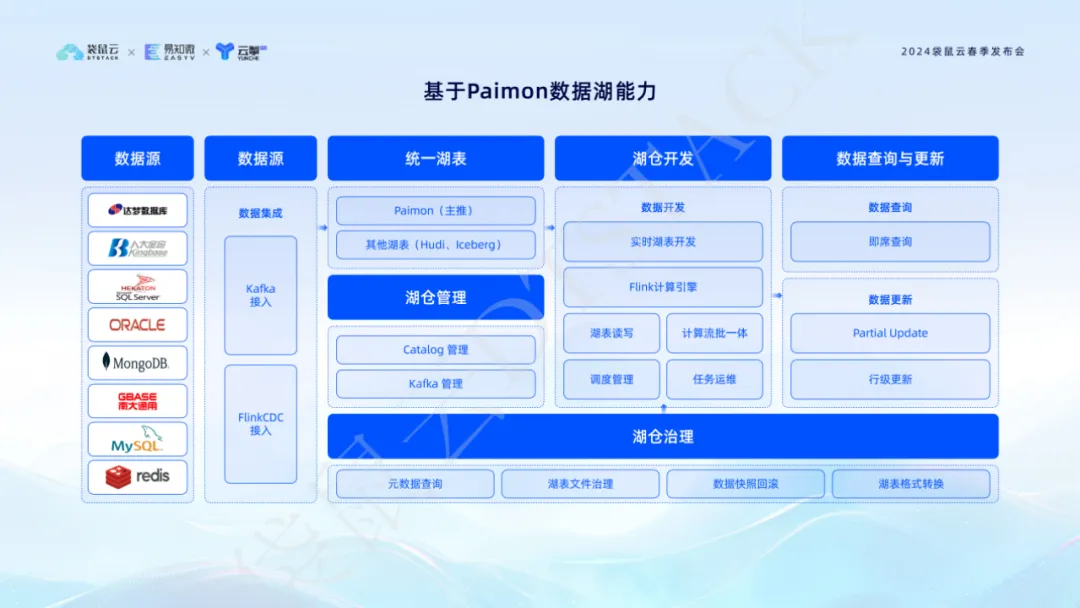
O avanço inovador da pilha de dados realiza o modelo de processamento de dados integrado em fluxo em lote por meio dos recursos do Paimon Data Lake , resolvendo efetivamente os problemas acima. A plataforma fornece desenvolvimento de tabelas lake em tempo real e funções de consulta ad hoc , permitindo que os desenvolvedores de dados processem dados em tempo real e em lote simultaneamente em uma única plataforma, sem a necessidade de investimento adicional em recursos e processos complexos de sincronização de dados. Essa solução integrada não apenas reduz o uso de recursos de computação e armazenamento, mas também garante a consistência e a precisão dos dados, melhorando assim o reconhecimento dos resultados da análise de dados pelo pessoal de negócios. Esta inovação proporcionará um forte apoio à transformação digital e à atualização inteligente das empresas.
5. As quatro funções principais do EasyMR são profundamente otimizadas para desbloquear uma nova experiência de computação e processamento de big data.
Como um importante módulo de produto na pilha de dados, o EasyMR representa nosso profundo conhecimento e inovação contínua do ecossistema de big data. Ele é baseado em Hadoop de código aberto e itera de forma síncrona com a comunidade de código aberto. É desenvolvido de forma independente por nossa equipe de mecanismo de computação e otimizou e aprimorou recursos de componentes principais, como Spark, Flink e Paimon. Essas otimizações não apenas melhoram o desempenho e a estabilidade do processamento de dados, mas também retribuem à comunidade e promovem a construção conjunta do ecossistema Hadoop.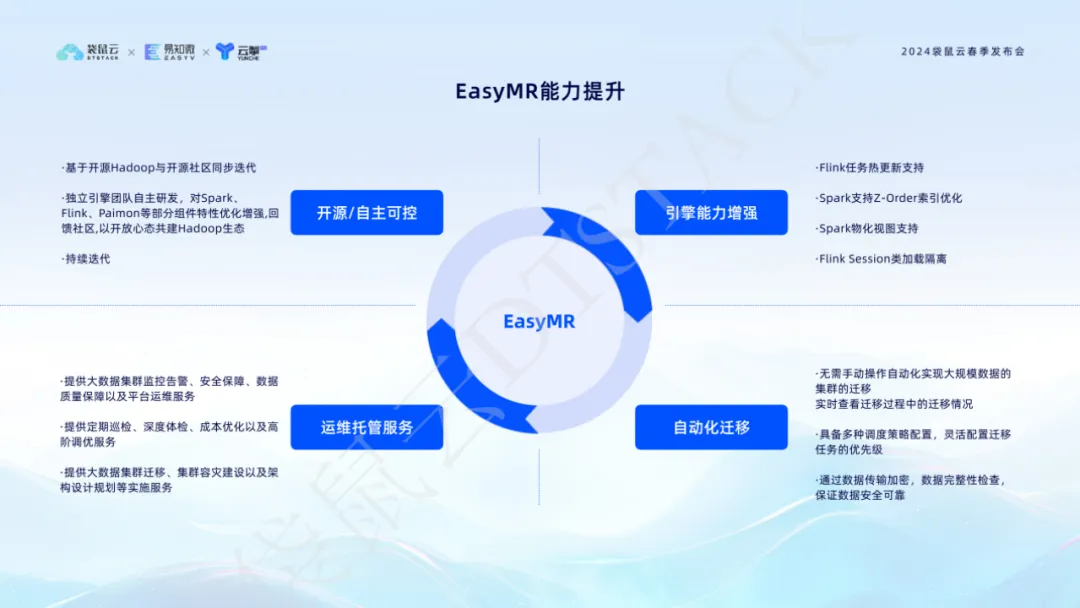
Os recursos aprimorados do EasyMR são refletidos em muitos aspectos: ele suporta atualizações dinâmicas de tarefas do Flink , garantindo a continuidade e flexibilidade dos negócios, a otimização do índice Z-Order do Spark e o suporte à visualização materializada melhoram a eficiência do processamento de dados e a velocidade de resposta do Flink ; confiabilidade do ambiente operacional. Além disso, a função de migração automatizada do EasyMR torna a migração de clusters de dados em grande escala fácil e simples e monitora o status durante o processo de migração em tempo real para garantir a segurança e a confiabilidade dos dados. Por meio dessas inovações e otimizações, a EasyMR oferece aos usuários uma plataforma de big data eficiente, inteligente e de fácil manutenção, ajudando as empresas a alcançar um salto qualitativo no gerenciamento e análise de dados.
Os recursos de dados + IA tornam o desenvolvimento de dados mais inteligente
A tecnologia de IA tornou-se a principal força motriz para a inovação empresarial e a melhoria da eficiência. Ao integrar a tecnologia generativa de IA , o DataStack V6.2 realizou seis funções principais: desenvolvimento inteligente, ajuste inteligente, diagnóstico inteligente, recuperação inteligente, análise inteligente e verificação inteligente, o que melhora muito a eficiência e a qualidade do processamento de dados.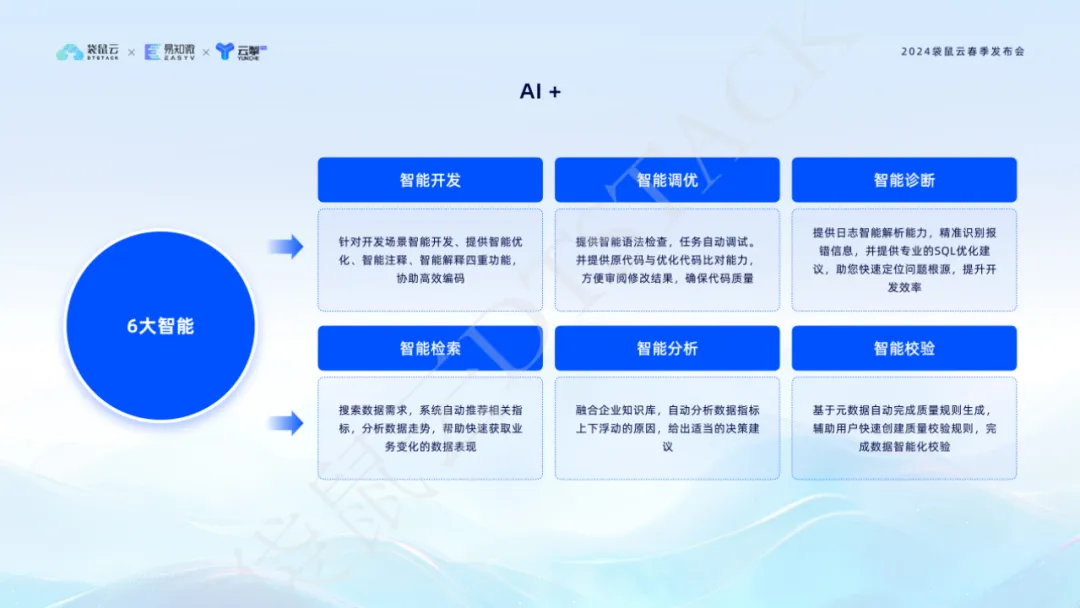
O ajuste inteligente pode otimizar automaticamente o código SQL e melhorar o desempenho da execução; o diagnóstico inteligente usa IA para analisar logs para localizar problemas rapidamente e fornecer sugestões de otimização profissional, ajudando a compreender profundamente as tendências dos dados e fornecer forte suporte para a tomada de decisões; Essas funções não apenas melhoram a eficiência do desenvolvimento, mas também garantem a qualidade do código e atingem as metas de negócios com mais precisão e com base em dados. A introdução do AI+ marca que estamos entrando em uma nova era de gerenciamento de dados mais inteligente e eficiente.
A função de ajuste inteligente AI + pode fornecer sugestões de otimização inteligentes quando os desenvolvedores escrevem código no editor, permitindo que os alunos de desenvolvimento de dados revisem e comparem. Isso melhora a eficiência e a qualidade do código, permitindo que os alunos de desenvolvimento de dados se concentrem mais na implementação da lógica de negócios.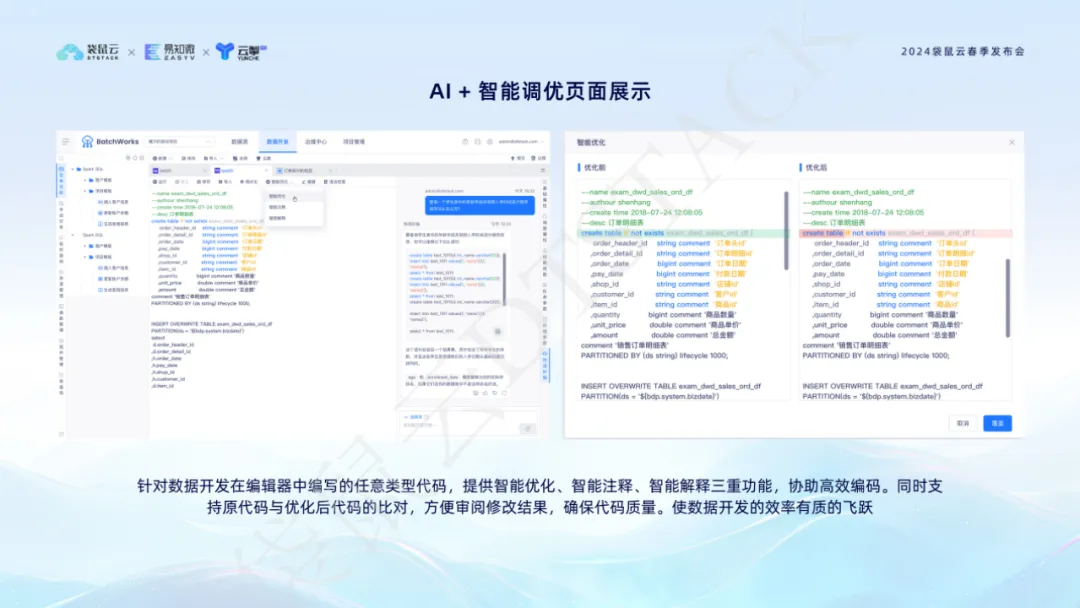
A função de diagnóstico inteligente AI + usa tecnologia AI para analisar de forma inteligente Spark SQL, Flink SQL e outros logs de tarefas, identificar mensagens de erro e fornecer sugestões profissionais de otimização de SQL para ajudar a localizar rapidamente a causa raiz do problema e melhorar a eficiência do desenvolvimento de código. 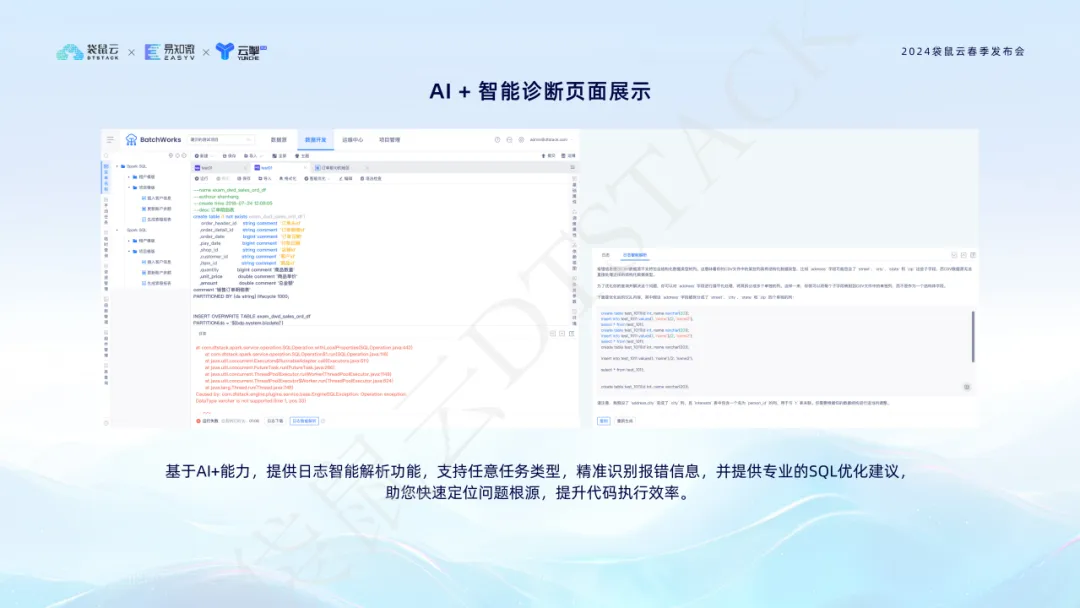 Através da integração com AI+, a pilha de dados não apenas simplifica o processo de desenvolvimento de dados, mas também melhora a precisão e a confiabilidade do processamento de dados, fornecendo suporte técnico sólido para a tomada de decisões das empresas orientada por dados.
Através da integração com AI+, a pilha de dados não apenas simplifica o processo de desenvolvimento de dados, mas também melhora a precisão e a confiabilidade do processamento de dados, fornecendo suporte técnico sólido para a tomada de decisões das empresas orientada por dados.
Produtos + serviços, uma nova atualização da estratégia de comercialização de produtos de pilha de dados
Neste lançamento de produto, redefinimos nossa estratégia de comercialização de produtos, visando fornecer soluções de serviços flexíveis e diversificadas para empresas com diferentes necessidades.  A série de produtos inclui edição padrão, edição profissional e edição final, e oferece opções de implantação de aplicativos em nuvem para atender às necessidades de processamento de dados de empresas de diferentes tamanhos. Além disso, também fornecemos serviços de valor agregado, como adaptação de Xinchhuang e armazém lacustre em tempo real, bem como versões avançadas e superiores de serviços sistemáticos de operação e manutenção, garantindo que os clientes possam desfrutar de suporte completo, do básico ao avançado.
A série de produtos inclui edição padrão, edição profissional e edição final, e oferece opções de implantação de aplicativos em nuvem para atender às necessidades de processamento de dados de empresas de diferentes tamanhos. Além disso, também fornecemos serviços de valor agregado, como adaptação de Xinchhuang e armazém lacustre em tempo real, bem como versões avançadas e superiores de serviços sistemáticos de operação e manutenção, garantindo que os clientes possam desfrutar de suporte completo, do básico ao avançado.
A estratégia de comercialização de produtos da Datastack não se concentra apenas na venda de produtos, mas também na otimização e atualização contínua de serviços. Ao fornecer dois caminhos de atualização de produto e atualização de versão, ajuda as empresas a garantir a adaptabilidade contínua e a natureza voltada para o futuro da plataforma de dados. Tal estratégia não só melhora a experiência do cliente, mas também estabelece uma base sólida para o desenvolvimento a longo prazo de produtos de pilha de dados.
Três principais casos práticos de produtos para ajudar a transformação digital das empresas
1. Um banco: implementação de avaliação de desempenho baseada em IA
Com base nos indicadores acumulados de avaliação de desempenho, combinados com a base de conhecimento da própria empresa, o banco utiliza análises inteligentes de IA e capacidades de processamento de dados para melhorar significativamente a eficiência da gestão e o nível de governança da avaliação de desempenho.
Nossa solução ajudou o banco a realizar a transformação de relatórios de indicadores em painéis de indicadores e, em seguida, para BI conversacional de indicadores, o que reduziu bastante o custo para os funcionários obterem e usarem dados, tornou os padrões de avaliação mais científicos e rigorosos e o conteúdo da avaliação mais completo , garantindo que o banco Existe uma estreita ligação entre o desempenho geral e o desempenho individual dos funcionários. Através da atribuição inteligente e sugestões inteligentes de IA, os bancos podem acompanhar os resultados do desempenho dos colaboradores em tempo real, identificar problemas em tempo útil e fazer ajustes, promovendo assim a consistência dos colaboradores e dos objetivos organizacionais e a melhoria contínua do desempenho. Esta transformação não só otimiza a gestão de recursos humanos do banco, mas também traz maior eficiência operacional e resultados de negócio para toda a organização.
2. Uma marca de bebidas alcoólicas chinesa: data center leve
Por meio do Data Stack, a marca estabeleceu uma plataforma de marketing unificada, ajudando as empresas a realizar recursos de análise multidimensionais, como compartilhamento de dados , tags inteligentes e gerenciamento de indicadores, e fornecendo forte suporte de dados para marketing de precisão das empresas, otimização de processos, etc.  A plataforma adota uma solução intermediária de dados leve e a combina com os recursos de computação de alto desempenho da StarRocks para permitir que as empresas de bebidas alcoólicas obtenham gerenciamento eficiente de dados e análise instantânea. Os recursos de consulta de baixa latência e carregamento rápido de dados da StarRocks permitem que as empresas respondam rapidamente às mudanças do mercado e obtenham previsão de falhas e marketing de precisão. Em comparação com o ecossistema Hadoop tradicional, essa solução intermediária de dados leve tem excelente desempenho de consulta, processamento de dados em tempo real, alta simultaneidade e fácil manutenção em cenários onde o volume de dados é pequeno, tornando-a uma solução ideal para rápida. análise de dados, promove a transformação digital das empresas de bebidas alcoólicas.
A plataforma adota uma solução intermediária de dados leve e a combina com os recursos de computação de alto desempenho da StarRocks para permitir que as empresas de bebidas alcoólicas obtenham gerenciamento eficiente de dados e análise instantânea. Os recursos de consulta de baixa latência e carregamento rápido de dados da StarRocks permitem que as empresas respondam rapidamente às mudanças do mercado e obtenham previsão de falhas e marketing de precisão. Em comparação com o ecossistema Hadoop tradicional, essa solução intermediária de dados leve tem excelente desempenho de consulta, processamento de dados em tempo real, alta simultaneidade e fácil manutenção em cenários onde o volume de dados é pequeno, tornando-a uma solução ideal para rápida. análise de dados, promove a transformação digital das empresas de bebidas alcoólicas.
3. Empresa do Grupo Estatal Municipal de Pequim: Full Link Xinchhuang
A fim de resolver os problemas de transformação digital empresarial e requisitos de inovação da informação, este cliente estabeleceu uma " plataforma de big data de inovação da informação full-link ".  A plataforma está profundamente adaptada ao ecossistema Xinchhuang e realiza proteção de segurança de processo completo e implantação privatizada de servidores, sistemas operacionais, chips, bancos de dados de metadados de aplicativos, middleware e mecanismos de computação. Através dessa adaptação da inovação da informação de link completo , o grupo não apenas resolveu o problema das ilhas de dados, mas também atendeu aos rigorosos requisitos do país para a inovação da informação e garantiu a segurança e a controlabilidade dos dados. Esta iniciativa melhorou significativamente as capacidades de governação de dados do grupo, estabeleceu uma base sólida de dados para o desenvolvimento a longo prazo da empresa e também proporcionou a outras empresas estatais uma valiosa experiência prática em inovação da informação.
A plataforma está profundamente adaptada ao ecossistema Xinchhuang e realiza proteção de segurança de processo completo e implantação privatizada de servidores, sistemas operacionais, chips, bancos de dados de metadados de aplicativos, middleware e mecanismos de computação. Através dessa adaptação da inovação da informação de link completo , o grupo não apenas resolveu o problema das ilhas de dados, mas também atendeu aos rigorosos requisitos do país para a inovação da informação e garantiu a segurança e a controlabilidade dos dados. Esta iniciativa melhorou significativamente as capacidades de governação de dados do grupo, estabeleceu uma base sólida de dados para o desenvolvimento a longo prazo da empresa e também proporcionou a outras empresas estatais uma valiosa experiência prática em inovação da informação.
O texto acima é uma introdução ao lançamento do DataStack V6.2. Não é apenas um produto, mas também um resumo de nosso profundo conhecimento e prática de governança de big data e análise inteligente. Acreditamos que o Data Stack V6.2 pode ajudar mais empresas a maximizar o valor dos dados e promover a sua transformação digital.
Endereço para download do "White Paper do Sistema de Indicadores da Indústria": https://www.dtstack.com/resources/1057?src=szsm
Endereço de download do "White Paper do produto Dutstack": https://www.dtstack.com/resources/1004?src=szsm
Endereço para download do "White Paper sobre práticas da indústria de governança de dados": https://www.dtstack.com/resources/1001?src=szsm
Para quem deseja conhecer ou consultar mais sobre produtos de big data, soluções industriais e cases de clientes, visite o site oficial da Kangaroo Cloud: https://www.dtstack.com/?src=szkyzg
Linus assumiu a responsabilidade de evitar que os desenvolvedores do kernel substituíssem tabulações por espaços. Seu pai é um dos poucos líderes que sabe escrever código, seu segundo filho é o diretor do departamento de tecnologia de código aberto e seu filho mais novo é um núcleo de código aberto. contribuidor Robin Li: A linguagem natural se tornará uma nova linguagem de programação universal. O modelo de código aberto ficará cada vez mais atrás da Huawei: levará 1 ano para migrar totalmente 5.000 aplicativos móveis comumente usados para Hongmeng. vulnerabilidades de terceiros. O editor de rich text Quill 2.0 foi lançado com recursos, confiabilidade e desenvolvedores. A experiência foi bastante melhorada. fonte de Laoxiangji não é o código, as razões por trás disso são muito comoventes. O Google anunciou uma reestruturação em grande escala.